




 本文深入探讨了SQL窗口函数的概念、分类和用法,包括聚合函数(如SUM、AVG、COUNT、MIN、MAX)以及排名函数(如ROW_NUMBER、RANK、DENSE_RANK)。通过案例展示了如何利用窗口函数进行数据去重、排名、计算环比和同比,以及处理连续登录等实际问题。此外,文章还讨论了窗口函数与聚合函数的区别和优化思想。
本文深入探讨了SQL窗口函数的概念、分类和用法,包括聚合函数(如SUM、AVG、COUNT、MIN、MAX)以及排名函数(如ROW_NUMBER、RANK、DENSE_RANK)。通过案例展示了如何利用窗口函数进行数据去重、排名、计算环比和同比,以及处理连续登录等实际问题。此外,文章还讨论了窗口函数与聚合函数的区别和优化思想。
窗口函数(Window Function)是 SQL2003 标准中定义的一项新特性,并在 SQL2011、SQL2016 中又加以完善,添加了若干拓展。
窗口函数不同于我们熟悉的常规函数及聚合函数,它为每行数据进行一次计算,特点是输入多行(一个窗口)、返回一个值。
在报表等数据分析场景中,你会发现窗口函数真的很强大,灵活运用窗口函数可以解决很多复杂问题,比如去重、排名、同比及环比、连续登录等等。
既然窗口函数这么强大,更要了解和灵活运用它了,本文将对窗口函数进行一个全面的整理,讲一讲窗口函数是什么,有哪些分类,用法是什么,以及窗口函数的案例加深大家的理解。
那什么是窗口函数呢?
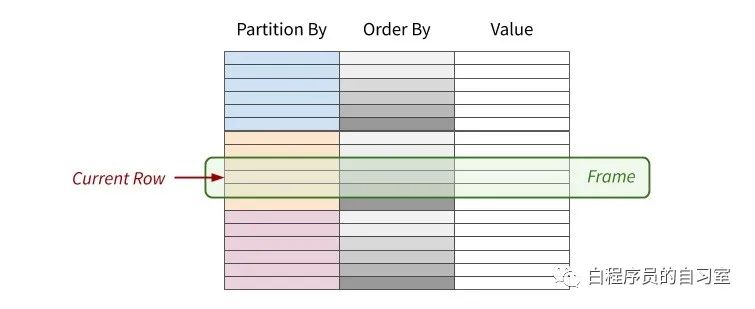
窗口函数出现在 SELECT 子句的表达式列表中,它最显著的特点就是 OVER 关键字。语法定义如下:
Function (arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>]
[<window_expression>])
Function (arg1,…, argn) 可以是下面的函数:
Aggregate Functions: 聚合函数,比如:sum(…)、 max(…)、min(…)、avg(…)等.
Sort Functions: 数据排序函数, 比如 :rank(…)、row_number(…)等.
Analytics Functions: 统计和比较函数, 比如:lead(…)、lag(…)、 first_value(…)等.
OVER ([PARTITION BY <…>] [ORDER BY <…>]
PARTITION BY 表示将数据先按 字段 进行分区
ORDER BY 表示将各个分区内的数据按 排序字段 进行排序
c1jWq8
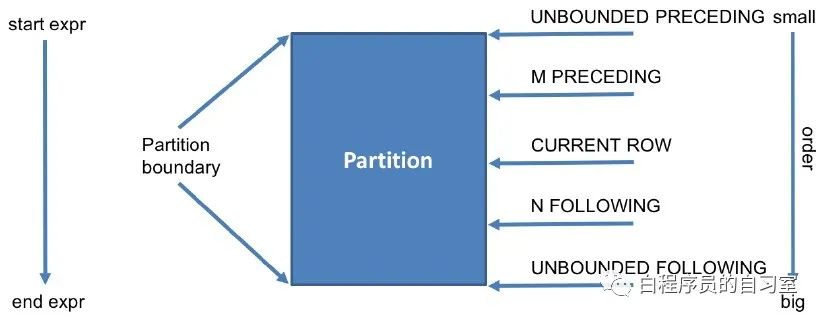
window_expression 用于确定窗边界
| 名词 | 含义 |
|---|---|
| preceding | 往前 |
| following | 往后 |
| current row | 当前行 |
| unbounded | 起点 |
| unbounded preceding | 从前面的起点 |
| unbounded following | 到后面的终点 |
窗口边界使用详解
-
如果不指定 PARTITION BY,则不对数据进行分区,换句话说,所有数据看作同一个分区;
-
如果不指定 ORDER BY,则不对各分区做排序,通常用于那些顺序无关的窗口函数,例如 SUM()
-
如果不指定窗口子句,则默认采用以下的窗口定义:
若不指定 ORDER BY,默认使用分区内所有行 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING;若指定了 ORDER BY,默认使用分区内第一行到当前值 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
窗口函数的计算过程(语法中每个部分都是可选的)
-
按窗口定义,将所有输入数据分区、再排序(如果需要的话)
-
对每一行数据,计算它的窗口范围
-
将窗口内的行集合输入窗口函数,计算结果填入当前行
数据准备
-- 创建表
CREATE TABLE IF NOT EXISTS q1_sales (
emp_name string,
emp_mgr string,
dealer_id int,
sales int,
stat_date string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED as TEXTFILE;
-- 插入测试数据
insert into table q1_sales (emp_name,emp_mgr,dealer_id,sales,stat_date)
values
('Beverly Lang','Mike Palomino',2,16233,'2020-01-01'),
('Kameko French','Mike Palomino',2,16233,'2020-01-03'),
('Ursa George','Rich Hernandez',3,15427,'2020-01-04'),
('Ferris Brown','Dan Brodi',1,19745,'2020-01-02'),
('Noel Meyer','Kari Phelps',1,19745,'2020-01-05'),
('Abel Kim','Rich Hernandez',1,12369,'2020-01-03'),
('Raphael Hull','Kari Phelps',1,8227,'2020-01-02'),
('Jack Salazar','Kari Phelps',1,9710,'2020-01-01'),
('May Stout','Rich Hernandez',3,9308,'2020-01-05'),
('Haviva Montoya','Mike Palomino',2,9308,'2020-01-03');
-- 查看测试数据信息
select * from q1_sales;
+--------------------+-------------------+---------------------+-----------------+---------------------+
| q1_sales.emp_name | q1_sales.emp_mgr | q1_sales.dealer_id | q1_sales.sales | q1_sales.stat_date |
+--------------------+-------------------+---------------------+-----------------+---------------------+
| Beverly Lang | Mike Palomino | 2 | 16233 | 2020-01-01 |
| Kameko French | Mike Palomino | 2 | 16233 | 2020-01-03 |
| Ursa George | Rich Hernandez | 3 | 15427 | 2020-01-04 |
| Ferris Brown | Dan Brodi | 1 | 19745 | 2020-01-02 |
| Noel Meyer | Kari Phelps | 1 | 19745 | 2020-01-05 |
| Abel Kim | Rich Hernandez | 1 | 12369 | 2020-01-03 |
| Raphael Hull | Kari Phelps | 1 | 8227 | 2020-01-02 |
| Jack Salazar | Kari Phelps | 1 | 9710 | 2020-01-01 |
| May Stout | Rich Hernandez | 3 | 9308 | 2020-01-05 |
| Haviva Montoya | Mike Palomino | 2 | 9308 | 2020-01-03 |
+--------------------+-------------------+---------------------+-----------------+---------------------+
10 rows selected (0.223 seconds)
窗口聚合函数有哪些?
| 窗口函数 | 返回类型 | 函数功能说明 |
|---|---|---|
| AVG() | 参数类型为DECIMAL的返回类型为DECIMAL,其他为DOUBLE | AVG 窗口函数返回输入表达式值的平均值,忽略 NULL 值。 |
| COUNT() | BIGINT | COUNT 窗口函数计算输入行数。COUNT(*) 计算目标表中的所有行,包括Null值;COUNT(expression) 计算特定列或表达式中具有非 NULL 值的行数。 |
| MAX() | 与传参类型一致 | MAX窗口函数返回表达式在所有输入值中的最大值,忽略 NULL 值。 |
| MIN() | 与传参类型一致 | MIN窗口函数返回表达式在所有输入值中的最小值,忽略 NULL 值。 |
| SUM() | 针对传参类型为DECIMAL的,返回类型一致;除此之外的浮点型为DOUBLE;传参类型为整数类型的,返回类型为BIGINT | SUM窗口函数返回所有输入值的表达式总和,忽略 NULL 值。 |
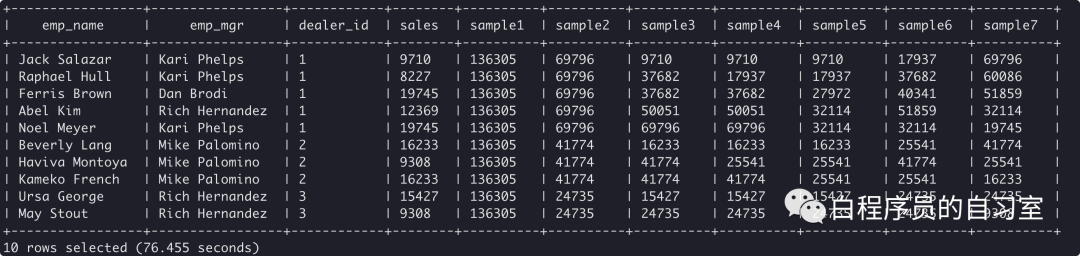
select emp_name,
emp_mgr,
dealer_id,
sales,
sum(sales) over () as sample1, -- 所有sales和
sum(sales) over (partition by dealer_id) as sample2, -- 按dealer_id分组,组内数据累加
sum(sales) over (partition by dealer_id ORDER BY stat_date) as sample3, -- 按dealer_id分组,时间排序,组内数据逐个相加
sum(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as sample4, -- 按dealer_id分组,时间排序,组内由起点到当前行的聚合
sum(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING and CURRENT ROW) as sample5, -- 按dealer_id分组,时间排序,组内当前行和前面一行做聚合
sum(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) as sample6, -- 按dealer_id分组,时间排序,组内当前行和前一行和后一行聚合
sum(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN CURRENT ROW and UNBOUNDED FOLLOWING) as sample7 -- 按dealer_id分组,时间排序,组内当前行和后面所有行
from q1_sales;
hive sum窗口函数
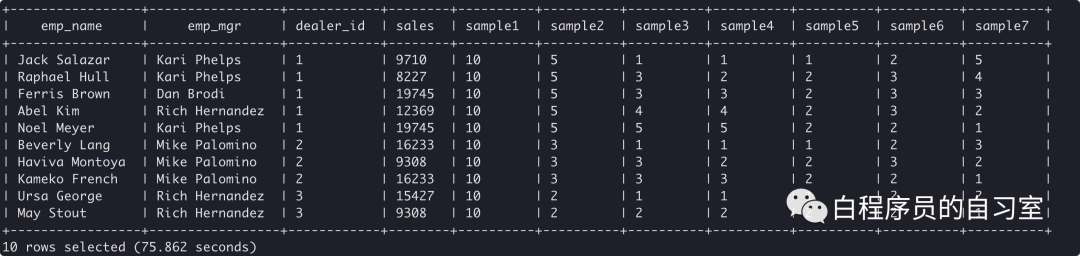
select emp_name,
emp_mgr,
dealer_id,
sales,
count(sales) over () as sample1, -- 所有条数
count(sales) over (partition by dealer_id) as sample2, -- 按dealer_id分组,组内数据数量
count(sales) over (partition by dealer_id ORDER BY stat_date) as sample3, -- 按dealer_id分组,时间排序,组内数据条数逐个相加
count(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as sample4, -- 按dealer_id分组,时间排序,组内由起点到当前行的聚合
count(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING and CURRENT ROW) as sample5, -- 按dealer_id分组,时间排序,组内当前行和前面一行做聚合
count(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) as sample6, -- 按dealer_id分组,时间排序,组内当前行和前一行和后一行聚合
count(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN CURRENT ROW and UNBOUNDED FOLLOWING) as sample7 -- 按dealer_id分组,时间排序,组内当前行和后面所有行
from q1_sales;
hive count窗口函数
select emp_name,
emp_mgr,
dealer_id,
sales,
avg(sales) over () as sample1, -- 所有sales聚合
avg(sales) over (partition by dealer_id) as sample2, -- 按dealer_id分组,组内数据累加
avg(sales) over (partition by dealer_id ORDER BY stat_date) as sample3, -- 按dealer_id分组,时间排序,组内数据逐个相加
avg(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as sample4, -- 按dealer_id分组,时间排序,组内由起点到当前行的聚合
avg(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING and CURRENT ROW) as sample5, -- 按dealer_id分组,时间排序,组内当前行和前面一行做聚合
avg(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) as sample6, -- 按dealer_id分组,时间排序,组内当前行和前一行和后一行聚合
avg(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN CURRENT ROW and UNBOUNDED FOLLOWING) as sample7 -- 按dealer_id分组,时间排序,组内当前行和后面所有行
from q1_sales;

hive avg窗口函数
select emp_name,
emp_mgr,
dealer_id,
sales,
max(sales) over () as sample1, -- 所有sales聚合
max(sales) over (partition by dealer_id) as sample2, -- 按dealer_id分组,组内数据累加
max(sales) over (partition by dealer_id ORDER BY stat_date) as sample3, -- 按dealer_id分组,时间排序,组内数据逐个相加
max(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as sample4, -- 按dealer_id分组,时间排序,组内由起点到当前行的聚合
max(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING and CURRENT ROW) as sample5, -- 按dealer_id分组,时间排序,组内当前行和前面一行做聚合
max(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) as sample6, -- 按dealer_id分组,时间排序,组内当前行和前一行和后一行聚合
max(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN CURRENT ROW and UNBOUNDED FOLLOWING) as sample7 -- 按dealer_id分组,时间排序,组内当前行和后面所有行
from q1_sales;
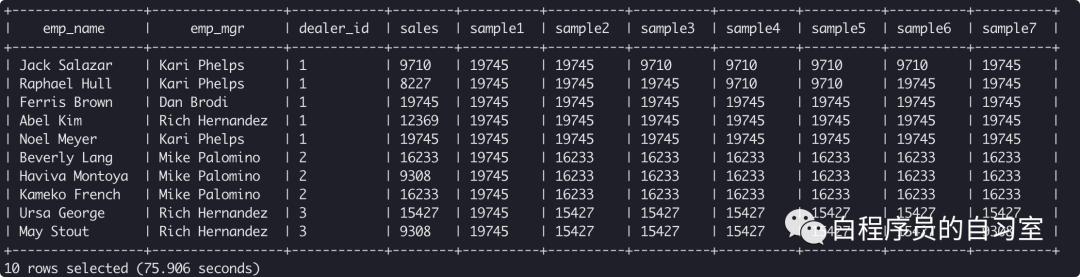
max
select emp_name,
emp_mgr,
dealer_id,
sales,
min(sales) over () as sample1, -- 所有sales聚合
min(sales) over (partition by dealer_id) as sample2, -- 按dealer_id分组,组内数据累加
min(sales) over (partition by dealer_id ORDER BY stat_date) as sample3, -- 按dealer_id分组,时间排序,组内数据逐个相加
min(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as sample4, -- 按dealer_id分组,时间排序,组内由起点到当前行的聚合
min(sales)
OVER (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING and CURRENT ROW) as sample5, -- 按dealer_id分组,时间排序,组内当前行和前面一行做聚合
min(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) as sample6, -- 按dealer_id分组,时间排序,组内当前行和前一行和后一行聚合
min(sales)
over (PARTITION BY dealer_id ORDER BY stat_date ROWS BETWEEN CURRENT ROW and UNBOUNDED FOLLOWING) as sample7 -- 按dealer_id分组,时间排序,组内当前行和后面所有行
from q1_sales;
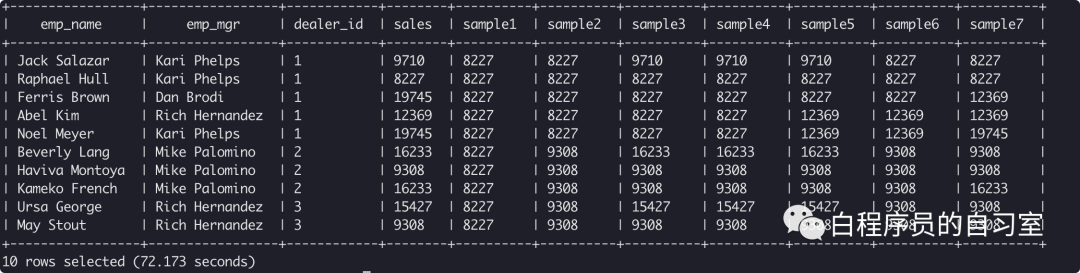
min
排名窗口函数
| 窗口函数 | 返回类型 | 函数功能说明 |
|---|---|---|
| ROW_NUMBER() | BIGINT | 根据具体的分组和排序,为每行数据生成一个起始值等于1的唯一序列数 |
| RANK() | BIGINT | 对组中的数据进行排名,如果名次相同,则排名也相同,但是下一个名次的排名序号会出现不连续。 |
| DENSE_RANK() dense是稠密的意思,可以引申记忆 | BIGINT | dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。当出现名次相同时,则排名序号也相同。而下一个排名的序号与上一个排名序号是连续的。 |
| PERCENT_RANK() | DOUBLE | 计算给定行的百分比排名。可以用来计算超过了百分之多少的人;排名计算公式为:(当前行的rank值-1)/(分组内的总行数-1) |
| CUME_DIST() | DOUBLE | 计算某个窗口或分区中某个值的累积分布。假定升序排序,则使用以下公式确定累积分布:小于等于当前值x的行数 / 窗口或partition分区内的总行数。其中,x 等于 order by 子句中指定的列的当前行中的值 |
| NTILE() | INT | 已排序的行划分为大小尽可能相等的指定数量的排名的组,并返回给定行所在的组的排名。如果切片不均匀,默认增加第一个切片的分布,不支持ROWS BETWEEN |
select *,
ROW_NUMBER() over(partition by dealer_id order by sales desc) rk01,
RANK() over(partition by dealer_id order by sales desc) rk02,
DENSE_RANK() over(partition by dealer_id order by sales desc) rk03,
PERCENT_RANK() over(partition by dealer_id order by sales desc) rk04
from q1_sales;
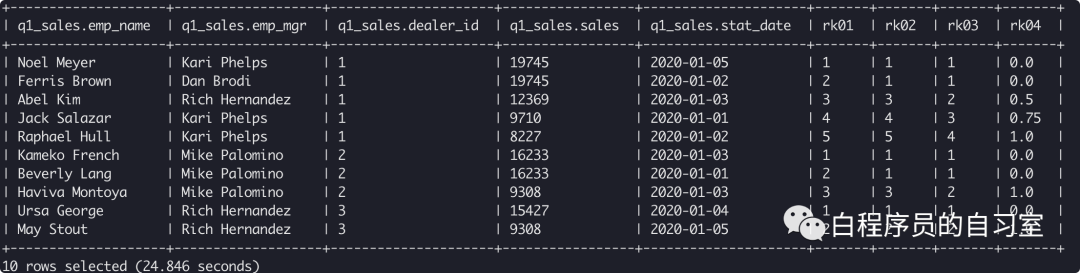
开窗排名函数
select *,
CUME_DIST() over(partition by dealer_id order by sales ) rk05,
CUME_DIST() over(partition by dealer_id order by sales desc) rk06
from q1_sales;
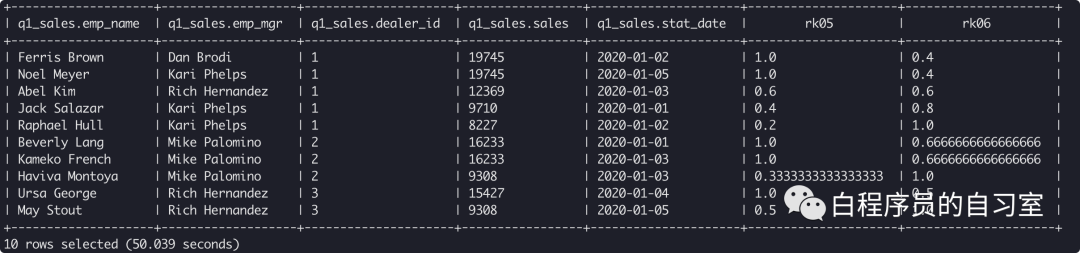
开窗函数CUME_DIST
select *,
NTILE(2) over(partition by dealer_id order by sales ) rk07,
NTILE(3) over(partition by dealer_id order by sales ) rk08,
NTILE(4) over(partition by dealer_id order by sales ) rk09
from q1_sales;
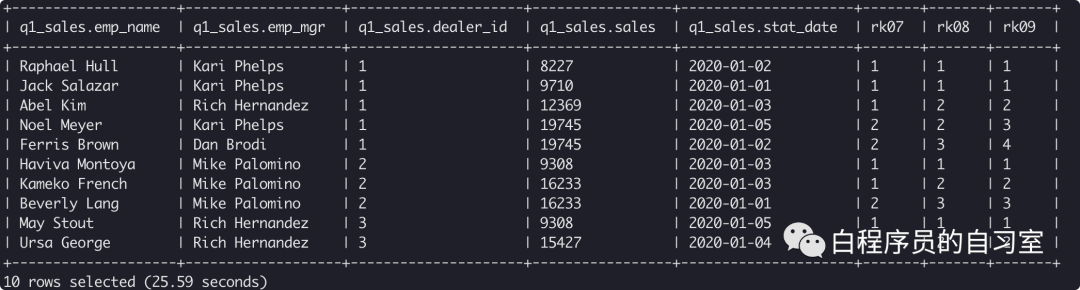
开窗函数NTILE
值窗口函数
| 窗口函数 | 返回类型 | 函数功能说明 |
|---|---|---|
| LAG() | ||
| 与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL. | ||
| LEAD() | ||
| 用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL. | ||
| FIRST_VALUE | ||
| 取分组内排序后,截止到当前行,第一个值 | ||
| LAST_VALUE | ||
| 取分组内排序后,截止到当前行,最后一个值 |
注意: last_value默认的窗口是 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,表示当前行永远是最后一个值,需改成RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING。
select emp_name, dealer_id, sales, first_value(sales) over (partition by dealer_id order by sales) as dealer_low from q1_sales;
|-----------------|------------|--------|-------------|
| emp_name | dealer_id | sales | dealer_low |
|-----------------|------------|--------|-------------|
| Raphael Hull | 1 | 8227 | 8227 |
| Jack Salazar | 1 | 9710 | 8227 |
| Ferris Brown | 1 | 19745 | 8227 |
| Noel Meyer | 1 | 19745 | 8227 |
| Haviva Montoya | 2 | 9308 | 9308 |
| Beverly Lang | 2 | 16233 | 9308 |
| Kameko French | 2 | 16233 | 9308 |
| May Stout | 3 | 9308 | 9308 |
| Abel Kim | 3 | 12369 | 9308 |
| Ursa George | 3 | 15427 | 9308 |
|-----------------|------------|--------|-------------|
10 rows selected (0.299 seconds)
select emp_name, dealer_id, sales, year, last_value(sales) over (partition by emp_name order by year) as last_sale from emp_sales where year = 2013;
|-----------------|------------|--------|-------|------------|
| emp_name | dealer_id | sales | year | last_sale |
|---|---|---|---|---|
| Beverly Lang | 2 | 5324 | 2013 | 5324 |
| Ferris Brown | 1 | 22003 | 2013 | 22003 |
| Haviva Montoya | 2 | 6345 | 2013 | 13100 |
| Haviva Montoya | 2 | 13100 | 2013 | 13100 |
| Kameko French | 2 | 7540 | 2013 | 7540 |
| May Stout | 2 | 4924 | 2013 | 15000 |
| May Stout | 2 | 8000 | 2013 | 15000 |
| May Stout | 2 | 15000 | 2013 | 15000 |
| Noel Meyer | 1 | 13314 | 2013 | 13314 |
| Raphael Hull | 1 | -4000 | 2013 | 14000 |
| Raphael Hull | 1 | 14000 | 2013 | 14000 |
| Ursa George | 1 | 10865 | 2013 | 10865 |
| ----------------- | ------------ | -------- | ------- | ------------ |
12 rows selected (0.284 seconds)
开窗案例举例
------
### 如何使用开窗函数去重
select * from (select *,row_number() over(partition by emp_mgr order by stat_date desc) rk from q1_sales) tmp where rk = 1;
±----------------±----------------±---------------±-----------±---------------±--------+
| tmp.emp_name | tmp.emp_mgr | tmp.dealer_id | tmp.sales | tmp.stat_date | tmp.rk |
±----------------±----------------±---------------±-----------±---------------±--------+
| Ferris Brown | Dan Brodi | 1 | 19745 | 2020-01-02 | 1 |
| Noel Meyer | Kari Phelps | 1 | 19745 | 2020-01-05 | 1 |
| Haviva Montoya | Mike Palomino | 2 | 9308 | 2020-01-03 | 1 |
| May Stout | Rich Hernandez | 3 | 9308 | 2020-01-05 | 1 |
±----------------±----------------±---------------±-----------±---------------±--------+
4 rows selected (25.707 seconds)
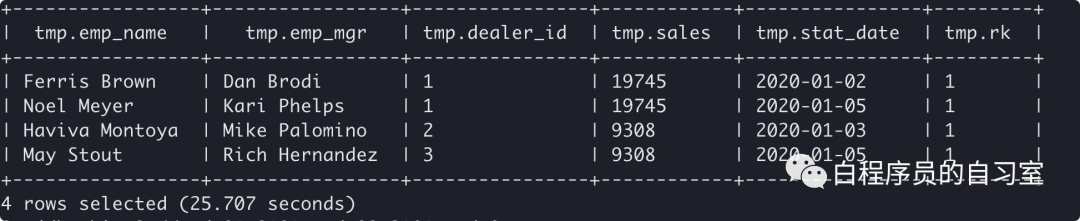
窗口函数去重
### 如何使用开窗函数进行排名
select *,row_number() over(partition by dealer_id order by sales desc) rk from q1_sales;
±-------------------±------------------±--------------------±----------------±--------------------±----+
| q1_sales.emp_name | q1_sales.emp_mgr | q1_sales.dealer_id | q1_sales.sales | q1_sales.stat_date | rk |
±-------------------±------------------±--------------------±----------------±--------------------±----+
| Noel Meyer | Kari Phelps | 1 | 19745 | 2020-01-05 | 1 |
| Ferris Brown | Dan Brodi | 1 | 19745 | 2020-01-02 | 2 |
| Abel Kim | Rich Hernandez | 1 | 12369 | 2020-01-03 | 3 |
| Jack Salazar | Kari Phelps | 1 | 9710 | 2020-01-01 | 4 |
| Raphael Hull | Kari Phelps | 1 | 8227 | 2020-01-02 | 5 |
| Kameko French | Mike Palomino | 2 | 16233 | 2020-01-03 | 1 |
| Beverly Lang | Mike Palomino | 2 | 16233 | 2020-01-01 | 2 |
| Haviva Montoya | Mike Palomino | 2 | 9308 | 2020-01-03 | 3 |
| Ursa George | Rich Hernandez | 3 | 15427 | 2020-01-04 | 1 |
| May Stout | Rich Hernandez | 3 | 9308 | 2020-01-05 | 2 |
±-------------------±------------------±--------------------±----------------±--------------------±----+
10 rows selected (23.38 seconds)
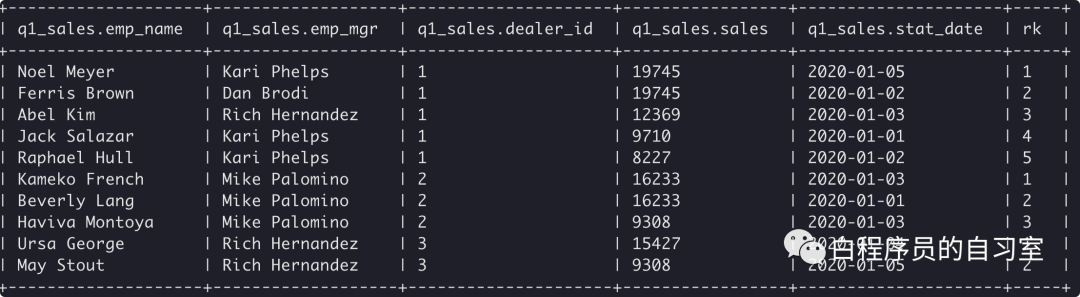
窗口函数排名
### 数仓增量数据合并
基于上述的排名和区中方法结合,可以实现数仓增量抽取的数据和历史数据合并去重。
你需要了解的全量表,增量表及拉链表
环比
--
### 数据准备
select * from temp_test12;
create table if not exists temp_test12 (
month string comment ‘月份’,
shop string comment ‘店铺’,
money string comment ‘营业额’
);
insert into table temp_test12 (month,shop,money)
values
(‘2019-01’,‘a’,1),
(‘2019-04’,‘a’,4),
(‘2019-02’,‘a’,2),
(‘2019-03’,‘a’,3),
(‘2019-06’,‘a’,6),
(‘2019-05’,‘a’,5),
(‘2019-01’,‘b’,2),
(‘2019-02’,‘b’,4),
(‘2019-03’,‘b’,6),
(‘2019-04’,‘b’,8),
(‘2019-05’,‘b’,10),
(‘2019-06’,‘b’,12);
select * from temp_test12;
±-------------------±------------------±--------------------+
| temp_test12.month | temp_test12.shop | temp_test12.money |
±-------------------±------------------±--------------------+
| 2019-01 | a | 1 |
| 2019-04 | a | 4 |
| 2019-02 | a | 3 |
| 2019-03 | a | 4 |
| 2019-06 | a | 6 |
| 2019-05 | a | 5 |
| 2019-01 | b | 2 |
| 2019-02 | b | 4 |
| 2019-03 | b | 6 |
| 2019-04 | b | 8 |
| 2019-05 | b | 10 |
| 2019-06 | b | 12 |
±-------------------±------------------±-------------------+
10 rows selected (23.38 seconds)
### 需求描述
查询店铺上个月的营业额,结果字段如下:
| 月份 | 商铺 | 本月营业额 | 上月营业额|
### 不使用开窗函数实现方案
实现这个需求我们需要先使用row_number()over按商铺分组,按月份排序得出这样一个结果:
SELECT month
,shop
,money
,ROW_NUMBER() OVER (
PARTITION BY shop ORDER BY month
) AS rn
FROM temp_test12;
结果:
month shop money rn
2019-01 a 1 1
2019-02 a 2 2
2019-03 a 3 3
2019-04 a 4 4
2019-05 a 5 5
2019-06 a 6 6
2019-01 b 2 1
2019-02 b 4 2
2019-03 b 6 3
2019-04 b 8 4
2019-05 b 10 5
2019-06 b 12 6
然后进行偏移自关联,将每个商铺的每个月的营业额和上个月的关联在一起:
WITH a
AS (
SELECT month
,shop
,MONEY
,ROW_NUMBER() OVER (
PARTITION BY shop ORDER BY month
) AS rn
FROM temp_test12
)
SELECT a1.month
,a1.shop
,a1.MONEY
,nvl(a2.month, ‘2018-12’) before_month --为了便于理解,这里加入上月的月份。如果上月没有的月份取为2018-12
,nvl(a2.MONEY, 1) before_money --上月没有的营业额取为1
FROM a a1 --代表本月
LEFT JOIN a a2 --代表上月
ON a1.shop = a2.shop
AND a1.month = substr(add_months(CONCAT (
a2.month
,’-01’
), 1), 1, 7) --增加月份的函数add_months中至少要传入年月日
GROUP BY a1.month
,a1.shop
,a1.MONEY
,nvl(a2.month, ‘2018-12’)
,nvl(a2.MONEY, 1);
结果:
a1.month a1.shop a1.money before_month before_money
2019-01 a 1 2018-12 1
2019-02 a 2 2019-01 1
2019-03 a 3 2019-02 2
2019-04 a 4 2019-03 3
2019-05 a 5 2019-04 4
2019-06 a 6 2019-05 5
2019-01 b 2 2018-12 1
2019-02 b 4 2019-01 2
2019-03 b 6 2019-02 4
2019-04 b 8 2019-03 6
2019-05 b 10 2019-04 8
2019-06 b 12 2019-05 10
### lag 开窗函数实现环比
SELECT month
,shop
,MONEY
,LAG(MONEY, 1, 1) OVER ( --取分组内上一行的营业额,如果没有上一行则取1
PARTITION BY shop ORDER BY month --按商铺分组,按月份排序
) AS before_money
FROM temp_test12;
– 结果集如下
month shop money before_money
2019-01 a 1 1
2019-02 a 2 1
2019-03 a 3 2
2019-04 a 4 3
2019-05 a 5 4
2019-06 a 6 5
2019-01 b 2 1
2019-02 b 4 2
2019-03 b 6 4
2019-04 b 8 6
2019-05 b 10 8
2019-06 b 12 10
### lag 其他用法演示
SELECT month
,shop
,MONEY
,LAG(MONEY, 1, 1) OVER (
PARTITION BY shop ORDER BY month
) AS before_money
,LAG(MONEY, 1) OVER (
PARTITION BY shop ORDER BY month
) AS before_money --第三个参数不写的话,如果没有上一行值,默认取null
,LAG(MONEY) OVER (
PARTITION BY shop ORDER BY month
) AS before_money --第二个参数不写默认为1,第三个参数不写的话,如果没有上一行值,默认取null,结果与上一列相同
,LAG(MONEY, 2, 1) OVER (
PARTITION BY shop ORDER BY month
) AS before_2month_money --取两个月前的营业额
FROM temp_test12;
– 结果集
month shop money before_money before_money before_money before_2month_money
2019-01 a 1 1 NULL NULL 1
2019-02 a 2 1 1 1 1
2019-03 a 3 2 2 2 1
2019-04 a 4 3 3 3 2
2019-05 a 5 4 4 4 3
2019-06 a 6 5 5 5 4
2019-01 b 2 1 NULL NULL 1
2019-02 b 4 2 2 2 1
2019-03 b 6 4 4 4 2
2019-04 b 8 6 6 6 4
2019-05 b 10 8 8 8 6
2019-06 b 12 10 10 10 8
– 解释说明:
– shop为a时,before_money指定了往上第1行的值,如果没有上一行值,默认取null,这里指定为1。
– a的第1行,往上1行值为NULL,指定第三个参数取1,不指定取null 。
– a的第2行,往上1行值为第1行营业额值,1。
– a的第6行,往上1行值为为第5行营业额值,5
### lead 求下月营业额
lead(col,n,default)与lag相反,统计分组内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,不填默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)。
新添一列每个商铺下个月的营业额,结果字段如下: 月份 商铺 本月营业额 下月营业额
SELECT month
,shop
,MONEY
,LEAD(MONEY, 1, 7) OVER (
PARTITION BY shop ORDER BY month
) AS after_money
,LEAD(MONEY, 1) OVER (
PARTITION BY shop ORDER BY month
) AS after_money --第三个参数不写的话,如果没有下一行值,默认取null
,LEAD(MONEY, 2, 7) OVER (
PARTITION BY shop ORDER BY month
) AS after_2month_money --取两个月后的营业额
FROM temp_test12;
结果:
month shop money after_money after_money after_2month_money
2019-01 a 1 2 2 3
2019-02 a 2 3 3 4
2019-03 a 3 4 4 5
2019-04 a 4 5 5 6
2019-05 a 5 6 6 7
2019-06 a 6 7 NULL 7
2019-01 b 2 4 4 6
2019-02 b 4 6 6 8
2019-03 b 6 8 8 10
2019-04 b 8 10 10 12
2019-05 b 10 12 12 7
2019-06 b 12 7 NULL 7
解释说明:
shop为a时,after_money指定了往下第1行的值,如果没有下一行值,默认取null,这里指定为1。
a的第1行,往下1行值为第2行营业额值,2。
a的第2行,往下1行值为第3行营业额值,4。
a的第6行,往下1行值为NULL,指定第三个参数取7,不指定取null。
### first\_value(col)
用于取分组内排序后,截止到当前行,第一个col的值。
ELECT month
,shop
,MONEY
,first_value(MONEY) OVER (
PARTITION BY shop ORDER BY month
) AS first_money
FROM temp_test12;
结果:
month shop money first_money
2019-01 a 1 1
2019-02 a 2 1
2019-03 a 3 1
2019-04 a 4 1
2019-05 a 5 1
2019-06 a 6 1
2019-01 b 2 2
2019-02 b 4 2
2019-03 b 6 2
2019-04 b 8 2
2019-05 b 10 2
2019-06 b 12 2
解释说明:
shop为a时,截止到每一行时,分组内的第一行值都是1。
shop为b时,截止到每一行时,分组内的第一行值都是2。
### last\_value(col)
用于取分组内排序后,截止到当前行,最后一个col的值。
SELECT month
,shop
,MONEY
,last_value(MONEY) OVER (
PARTITION BY shop ORDER BY month
) AS last_money
FROM temp_test12;
结果:
month shop money last_money
2019-01 a 1 1
2019-02 a 2 2
2019-03 a 3 3
2019-04 a 4 4
2019-05 a 5 5
2019-06 a 6 6
2019-01 b 2 2
2019-02 b 4 4
2019-03 b 6 6
2019-04 b 8 8
2019-05 b 10 10
2019-06 b 12 12
解释说明:
shop为a时,截止到每一行时,分组内的最后一行值都是该行本身。
shop为b时,截止到每一行时,分组内的最后一行值都是该行本身。
连续登录
----
### 数据准备
源数据,文件中是以,号隔开的
id,date
A,2018-09-04
B,2018-09-04
C,2018-09-04
A,2018-09-05
A,2018-09-05
C,2018-09-05
A,2018-09-06
B,2018-09-06
C,2018-09-06
A,2018-09-04
B,2018-09-04
C,2018-09-04
A,2018-09-05
A,2018-09-05
C,2018-09-05
A,2018-09-06
B,2018-09-06
C,2018-09-06
### 展现连续登陆两天的用户信息
select
*
from
(
select
id ,
date,
lead(date,1,-1) over(partition by id order by date desc ) as date1 – 按照用户分组,登录时间降序排序,获取上一次登录日期
from tb_use a
group by id,date – 去重当日重复登录,
) as b
where date_sub(cast(b.date as date),1)=cast(b.date1 as date); – 判定当前登录日期的上一天是否与上一次登录日期一致,一致则判定为连续登录
结果:
b.id b.date b.date1
A 2018-09-06 2018-09-05
A 2018-09-05 2018-09-04
C 2018-09-06 2018-09-05
C 2018-09-05 2018-09-04
### 统计连续登陆两天的用户个数
(n天就只需要把lead(date,2,-1)中的2改成n-1并且把date\_sub(cast(b.date as date),2)中的2改成n-1)
select
count(distinct b.id) as c1
from
(
select id ,date,
lead(date,1,-1) over(partition by id order by date desc ) as date1
from tb_use a
group by id,date
) as b
where date_sub(cast(b.date as date),1)=cast(b.date1 as date);
结果:
c1
2
特说说明:上文指出了连续登录2天的场景,针对其他连续登录场景,假设连续登录n天,可将lead(date,1,-1)中的1改成n-1,date\_sub(cast(b.date as date),1)中的1改成n-1。
占比、同比、环比计算(lag函数,lead函数)
------------------------
### 数据准备
– 创建表并插入数据
CREATE TABLE saleorder (
order_id int ,
order_time date ,
order_num int
)
– 插入测试数据
INSERT INTO saleorder VALUES
(1, ‘2020-04-20’, 420),
(2, ‘2020-04-04’, 800),
(3, ‘2020-03-28’, 500),
(4, ‘2020-03-13’, 100),
(5, ‘2020-02-27’, 300),
(6, ‘2020-01-07’, 450),
(7, ‘2019-04-07’, 800),
(8, ‘2019-03-15’, 1200),
(9, ‘2019-02-17’, 200),
(10, ‘2019-02-07’, 600),
(11, ‘2019-01-13’, 300);
select * from saleorder;
±--------------------±----------------------±---------------------+
| saleorder.order_id | saleorder.order_time | saleorder.order_num |
±--------------------±----------------------±---------------------+
| 1 | 2020-04-20 | 420 |
| 2 | 2020-04-04 | 800 |
| 3 | 2020-03-28 | 500 |
| 4 | 2020-03-13 | 100 |
| 5 | 2020-02-27 | 300 |
| 6 | 2020-01-07 | 450 |
| 7 | 2019-04-07 | 800 |
| 8 | 2019-03-15 | 1200 |
| 9 | 2019-02-17 | 200 |
| 10 | 2019-02-07 | 600 |
| 11 | 2019-01-13 | 300 |
±--------------------±----------------------±---------------------+
11 rows selected (0.331 seconds)
### 使用窗口函数实现占比
SELECT
order_month,
num, – 月销量
total, – 年销量
round( num / total, 2 ) AS ratio – 月销量占年销量比
FROM
(
select
substr(order_time, 1, 7) as order_month, --查询月份
sum(order_num) over (partition by substr(order_time, 1, 7)) as num, --根据月份分组,统计月销量
sum( order_num ) over ( PARTITION BY substr( order_time, 1, 4 ) ) total, --根据年分组,统计年销量
row_number() over (partition by substr(order_time, 1, 7)) as rk
from saleorder
) temp
where rk = 1;
±-------------±------±-------±-------+
| order_month | num | total | ratio |
±-------------±------±-------±-------+
| 2019-04 | 800 | 3100 | 0.26 |
| 2019-03 | 1200 | 3100 | 0.39 |
| 2019-02 | 800 | 3100 | 0.26 |
| 2019-01 | 300 | 3100 | 0.1 |
| 2020-04 | 1220 | 2570 | 0.47 |
| 2020-03 | 600 | 2570 | 0.23 |
| 2020-02 | 300 | 2570 | 0.12 |
| 2020-01 | 450 | 2570 | 0.18 |
±-------------±------±-------±-------+
8 rows selected (49.433 seconds)
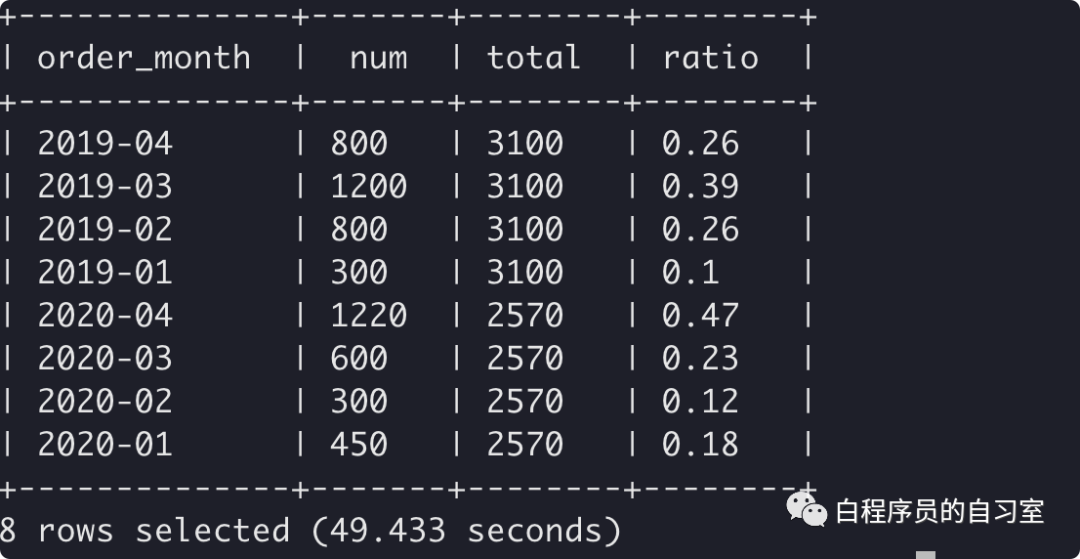
Hive窗口函数占比结算
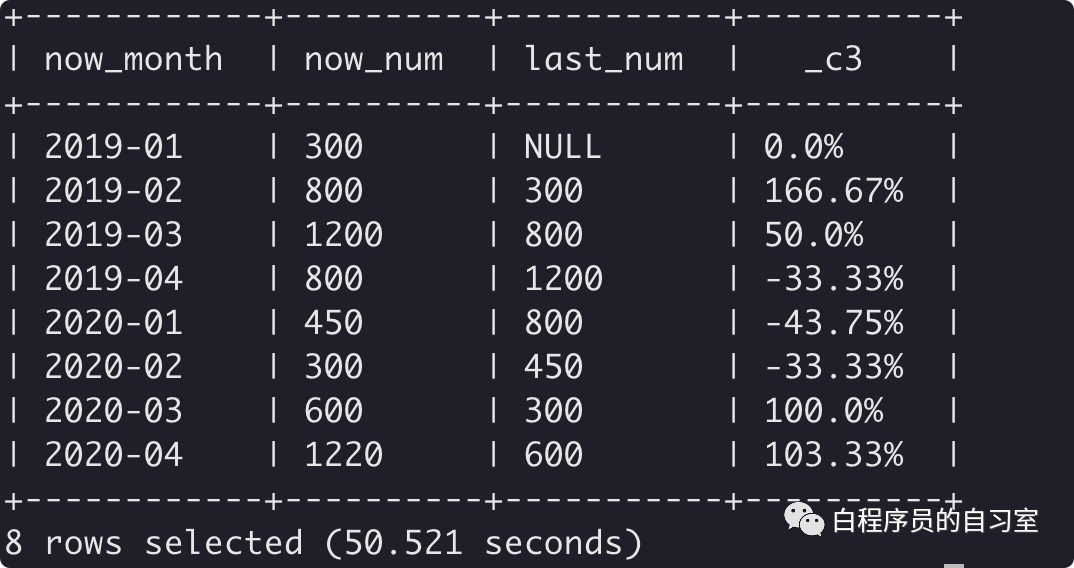
### 使用窗口函数实现环比计算
什么是环比、什么是同比?与上年度数据对比称"同比",与上月数据对比称"环比"。
相关公式如下: 同比增长率计算公式:(当年值-上年值)/上年值x100%
环比增长率计算公式:(当月值-上月值)/上月值x100%
– 环比增长率
select
now_month,
now_num,
last_num,
concat( nvl ( round( ( now_num - last_num ) / last_num * 100, 2 ), 0 ), “%” )
FROM
(
– 2、查询上月销量
select
now_month,
now_num,
lag( t1.now_num, 1 ) over (order by t1.now_month ) as last_num
from
(
– 1、按月统计销量
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from saleorder
group by
substr(order_time, 1, 7)
) t1
) t2;
±-----------±---------±----------±---------+
| now_month | now_num | last_num | _c3 |
±-----------±---------±----------±---------+
| 2019-01 | 300 | NULL | 0.0% |
| 2019-02 | 800 | 300 | 166.67% |
| 2019-03 | 1200 | 800 | 50.0% |
| 2019-04 | 800 | 1200 | -33.33% |
| 2020-01 | 450 | 800 | -43.75% |
| 2020-02 | 300 | 450 | -33.33% |
| 2020-03 | 600 | 300 | 100.0% |
| 2020-04 | 1220 | 600 | 103.33% |
±-----------±---------±----------±---------+
8 rows selected (50.521 seconds)
– 同比增长率计算公式
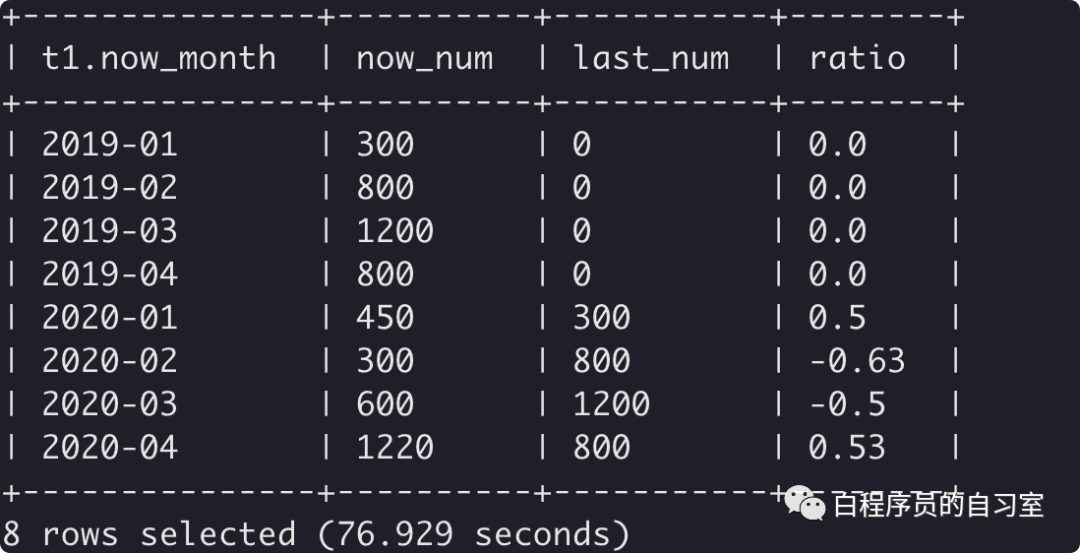
同比的话,如果每个月都齐全,都有数据lag(num,12)就ok.。我们的例子中只有19年和20年1-4月份的数据。这种特殊情况应该如何处理?
SELECT
t1.now_month,
nvl ( now_num, 0 ) AS now_num,
nvl ( last_num, 0 ) AS last_num,
nvl ( round( ( now_num - last_num ) / last_num, 2 ), 0 ) AS ratio
FROM
(
SELECT
DATE_FORMAT( order_time, ‘yyyy-MM’ ) AS now_month,
sum( order_num ) AS now_num
FROM
saleorder
GROUP BY
DATE_FORMAT( order_time, ‘yyyy-MM’ )
) t1
LEFT JOIN
(
SELECT
DATE_FORMAT( DATE_ADD( order_time, 365 ), ‘yyyy-MM’ ) AS now_month,
sum( order_num ) AS last_num
FROM
saleorder
GROUP BY
DATE_FORMAT( DATE_ADD( order_time, 365 ), ‘yyyy-MM’ )
) AS t2 ON t1.now_month = t2.now_month;
±--------------±---------±----------±-------+
| t1.now_month | now_num | last_num | ratio |
±--------------±---------±----------±-------+
| 2019-01 | 300 | 0 | 0.0 |
| 2019-02 | 800 | 0 | 0.0 |
| 2019-03 | 1200 | 0 | 0.0 |
| 2019-04 | 800 | 0 | 0.0 |
| 2020-01 | 450 | 300 | 0.5 |
| 2020-02 | 300 | 800 | -0.63 |
| 2020-03 | 600 | 1200 | -0.5 |
| 2020-04 | 1220 | 800 | 0.53 |
±--------------±---------±----------±-------+
8 rows selected (76.929 seconds)
### 其他案例
– 建表
CREATE TABLE order_info
(
name string,
orderdate string,
cost string
);
– 数据加载
INSERT INTO table order_info (name,orderdate,cost) VALUE (‘jack’,‘2020-01-01’,‘10’),
(‘tony’,‘2020-01-02’,‘15’),
(‘jack’,‘2020-02-03’,‘23’),
(‘tony’,‘2020-01-04’,‘29’),
(‘jack’,‘2020-01-05’,‘46’),
(‘jack’,‘2020-04-06’,‘42’),
(‘tony’,‘2020-01-07’,‘50’),
(‘jack’,‘2020-01-08’,‘55’),
(‘mart’,‘2020-04-08’,‘62’),
(‘mart’,‘2020-04-09’,‘68’),
(‘neil’,‘2020-05-10’,‘12’),
(‘mart’,‘2020-04-11’,‘75’),
(‘neil’,‘2020-06-12’,‘80’),
(‘mart’,‘2020-04-13’,‘94’);
SELECT name,
orderdate,
cost, --当前window内,当前行的前一行到后一行 金额总和
sum(cast(cost AS INT)) over(PARTITION BY name
ORDER BY orderdate DESC ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS precedingFollow, --当前window内,当前行到最后行的金额总和
sum(cast(cost AS INT)) over(PARTITION BY name
ORDER BY orderdate DESC ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS currentFollow, --当前window内,按照时间进行排序
row_number() OVER(PARTITION BY name
ORDER BY orderdate DESC) AS rank,–用户上次购买的时间
lag(orderdate,1,‘查无结果’) over(PARTITION BY name
ORDER BY orderdate) AS lastTime,–用户下一次购买的时间
lead(orderdate,1,‘查无结果’) over(PARTITION BY name
ORDER BY orderdate)AS nextTime,–用户上次购物金额
lag(cost,1,‘查无结果’)over(PARTITION BY name
ORDER BY orderdate) AS lastCost,–用户下次购物金额
lead(cost,1,‘查无结果’) OVER (PARTITION BY name
ORDER BY orderdate) AS nextCost,–用户上一次+这次的购物金额
sum(cast(cost AS INT)) over(PARTITION BY name
ORDER BY orderdate ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS lastCurrentCost,–用户每月购物金额
sum(cast(cost AS INT)) over(PARTITION BY name,month(orderdate)
ORDER BY month(orderdate)) AS monthCost,–用户当月单词消费最大值
max(cast(cost AS INT)) over(PARTITION BY name,month(orderdate)
ORDER BY orderdate) AS monthMaxCost,–用户当月单词消费最小值
min(cast(cost AS INT)) over(PARTITION BY name,month(orderdate)
ORDER BY orderdate) as monthMinCost
FROM TEST.COSTITEM
间隔,最近两次间隔,登录间隔,出院间隔等等
---------------------
select
user_name,
age,
in_hosp,
out_hosp,
datediff(in_hosp,LAG(out_hosp,1,in_hosp) OVER(PARTITION BY user_name ORDER BY out_hosp asc)) as days
from t_hosp;
扩展
--
### 一些优化思想
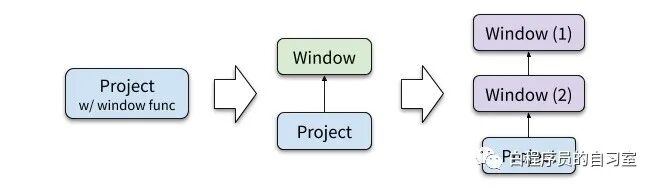
有时候,一个 SELECT 语句中包含多个窗口函数,它们的窗口定义(OVER 子句)可能相同、也可能不同。显然,对于相同的窗口,完全没必要再做一次分区和排序,我们可以将它们合并成一个 Window 算子。
那如何利用一次排序计算多个窗口函数呢?某些情况下,这是可能的。下面的例子如下:
ROW_NUMBER() OVER (PARTITION BY dealer_id ORDER BY sales) AS rank,
AVG(sales) OVER (PARTITION BY dealer_id) AS avgsales …
虽然这 2 个窗口并非完全一致,但是 AVG(sales) 不关心分区内的顺序,完全可以复用 ROW\_NUMBER() 的窗口,这里提供了一种方式,尽一切可能利用能够复用的机会。
### 窗口函数 VS. 聚合函数
从聚合这个意义上出发,似乎窗口函数和 Group By 聚合函数都能做到同样的事情。但是,它们之间的相似点也仅限于此了!这其中的关键区别在于:窗口函数仅仅只会将结果附加到当前的结果上,它不会对已有的行或列做任何修改。而 Group By 的做法完全不同:对于各个 Group 它仅仅会保留一行聚合结果。
有的读者可能会问,加了窗口函数之后返回结果的顺序明显发生了变化,这不算一种修改吗?因为 SQL 及关系代数都是以 multi-set 为基础定义的,结果集本身并没有顺序可言,ORDER BY 仅仅是最终呈现结果的顺序。
另一方面,从逻辑语义上说,SELECT 语句的各个部分可以看作是按以下顺序“执行”的:

窗口函数执行
注意到窗口函数的求值仅仅位于 ORDER BY 之前,而位于 SQL 的绝大部分之后。这也和窗口函数只附加、不修改的语义是呼应的,结果集在此时已经确定好了,再依次计算窗口函数。



















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











