



定义 遍历 常用方法
运行机制
由JVM将java文件编译为class字节码文件,此文件只有JVM能看懂。之后JVM会根据不同的操作系统将class文件解释为不同二进制文件。
(JVM在JRE里,JRE在JDK里)
更详细JVM原理看其他笔记篇。
数据类型
[Java]基本数据类型与引用类型赋值的底层分析_java引用数据类型的赋值-优快云博客
基本数据类型
(存栈中,没有地址这个概念!相互赋值给的就是值!如:int c=4;int b=c;b=5; //b是5,c仍是4。但要注意,引用对象中的基本数据类型是存在堆/方法区中的)
byte(1B) short(2B) char(2B)[在计算时会转为int] int(4字节 32位) long(8字节 64位) float(4B) double(8B) boolean
(boolean类型会被JVM编译为int或比byte类型。
如果boolean是单独使用:boolean占4个字节,JVM将其转为int类型。如果boolean是以“boolean数组”的形式使用:boolean占1个字节,Java 中的 boolean 数组被编码为 byte 数组,每个 boolean 元素使用 1 字节(8 bit)
不管它占多大的空间,只有 1 个 bit 的信息是有意义的)
int类型最大值 2^31-1 最小值 -2^31
long类型最大值 2^63-1 最小值 -2^63类型转换:
隐式类型转化:目标类型的范围大于源类型,int -> long , float -> double
强制类型转化:目标类型的范围小于源类型,long -> int,double -> float
为了避免精度丢失,可以使用
BigDecimal来进行浮点数的运算(在常用类中讲解)
引用数据类型
(地址存栈中,指向对象可能存在堆或者方法区的常量池中)
String:两种定义方法 1.str=new String("hello")放到堆中(若常量池中没有"hello"还会先创建一份在常量池中) 2.str="hello"放到常量池中
1.创建好的字符串,是不可变的,想修改就会创建一个新的字符串对象引用。
String类中包含一个数组, 储存数组的每一个字符: private final byte[] value;
- final数组, 地址不能改变, 导致长度不能改变
- private, 数组中的内容不能改变
由于其不可变性,所有我们在进行字符串拼接"+"计算时,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到 一个 String 对象 。 不过,在循环内使用“+”进行字符串的拼接的话,存在比较明显的缺 陷:编译器不会创建单个 StringBuilder 以复用,会导致创建过多的 StringBuilder 对象。 StringBuilder 对象是在循环内部被创建的,这意味着每循环一次就会创建一个 StringBuilder 对象。 所以需要把new StringBuilder() 放在循环外部.
2.也可以通过intern方法手动将字符串入池String s1=new String("abc").intern();
最终效果与直接使用字面量String s = "abc"相同。
(常量池中没有"abc"会先放一份在常量池,之后再堆中创建"abc"对象,加上intern后会把引用指向常量池中的地址,堆中的被回收)
3.其在编译期间可优化,但运行期间不可:
String str1="str"+"ing" --> 常量池"String"
final String str2="a";final String str3="b";
String str4=str2+str3 --> 常量池"ab"
但
String str5="a";String str6="b";
String str7=str5+str5 --> 这个就不能优化了,因为str5和str6只有在运行期间才知道值,不是fianl常量类型,所以不优化
包装类:
对于整数型包装类定义方式:
valueOf或自动装箱(底层为valueOf)Integer a=3; Integer b=Integer.valueOf(3); a==b;
Integer、Short、Byte、Long 都有一个常量池,常量池的范围是-128~127之间
Character也有常量池,范围是0~127
如果此方法定义的包装类的值在这个范围内,则会直接返回内部缓存池中已经存在的对象的引用(new的方式jdk9后就淘汰了)
这个常量池机制和String的类似,如果我们修改了a=4,那会在常量池中放入一个新的值为4的Integer,a此时指向这个对象,而b仍指向3这个对象。区别就是:
String常量池包含所有编译期字符串字面量和运行期intern的字符串。String常量池由JVM全局维护,并且可以通过intern方法将字符串手动放入池中。
Integer的常量池只包含-128到127之间的整数。Integer的常量池是类级别的,在Integer类加载时创建,并且范围固定,不能动态增加。
对于浮点型包装类:
对于浮点型Float和Double这样的包装类,没有常量池机制,不管传入的值是多少,都会new一个新的对象,放入堆区。
数组
常用类
集合
数组
1.定义:【基本引用 一维二维】
不要沿用c++的想法。
java的数组分基本数据类型和引用类型
基本数据类型
如int[] s=new int[10]; 这里面创建了长度为10的整型数组,并且自动为每个元素创建了对象,即能找到相关地址
引用类型
如写了个class student(){}, 在student[] s=new student[10]中只是new了数组空间,我们还要对s[0]-s[9]每一个创建对象,否则数组为null 。指向堆区位置为null。
还需要遍历,给赋值。
for(int i=0;i<10;i++)
{
s[i]=new student();
}
一维数组:
int[] a=new int[5];
int[] a=new int[]{1,2}; --> 简写int[]a={1,2};注意:大小和初始值不可以兼得 int[] a=new int[2]{1,2};错误!
二维数组:
int[][] a=new int[n][]; //默认为null
int[][] a=new int[n][n]; //默认全为0
int[][] a=new int[][]{ {1,2},{},{}3}; --> 简写int[][] a={ {1,2},{},{}3};
注意:仍然大小和初始值不可以兼得 int[][] a=new int[n][]{ {1,2}}错误!!
在不初始化时,第一个参数必须写,指定有几个数组。
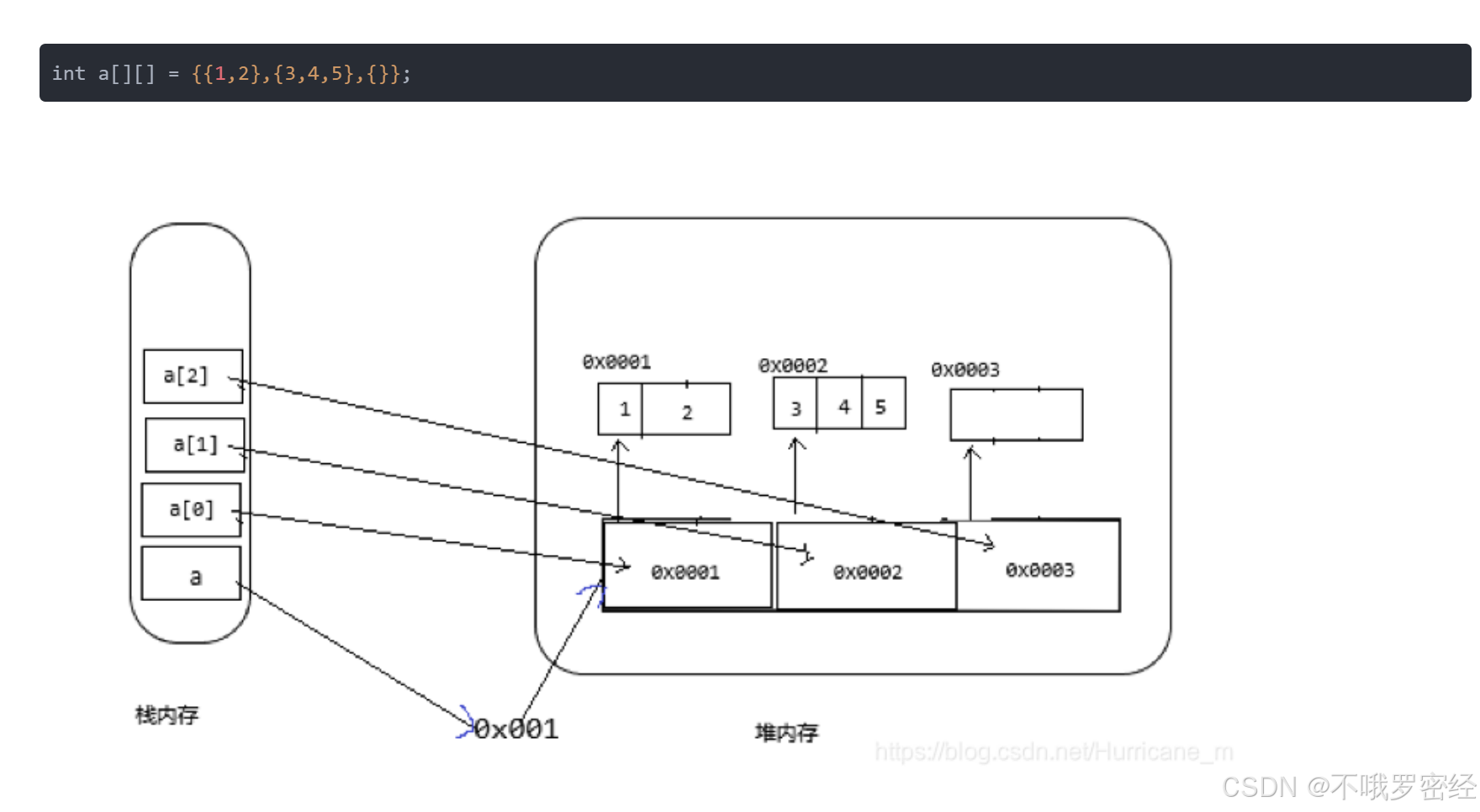

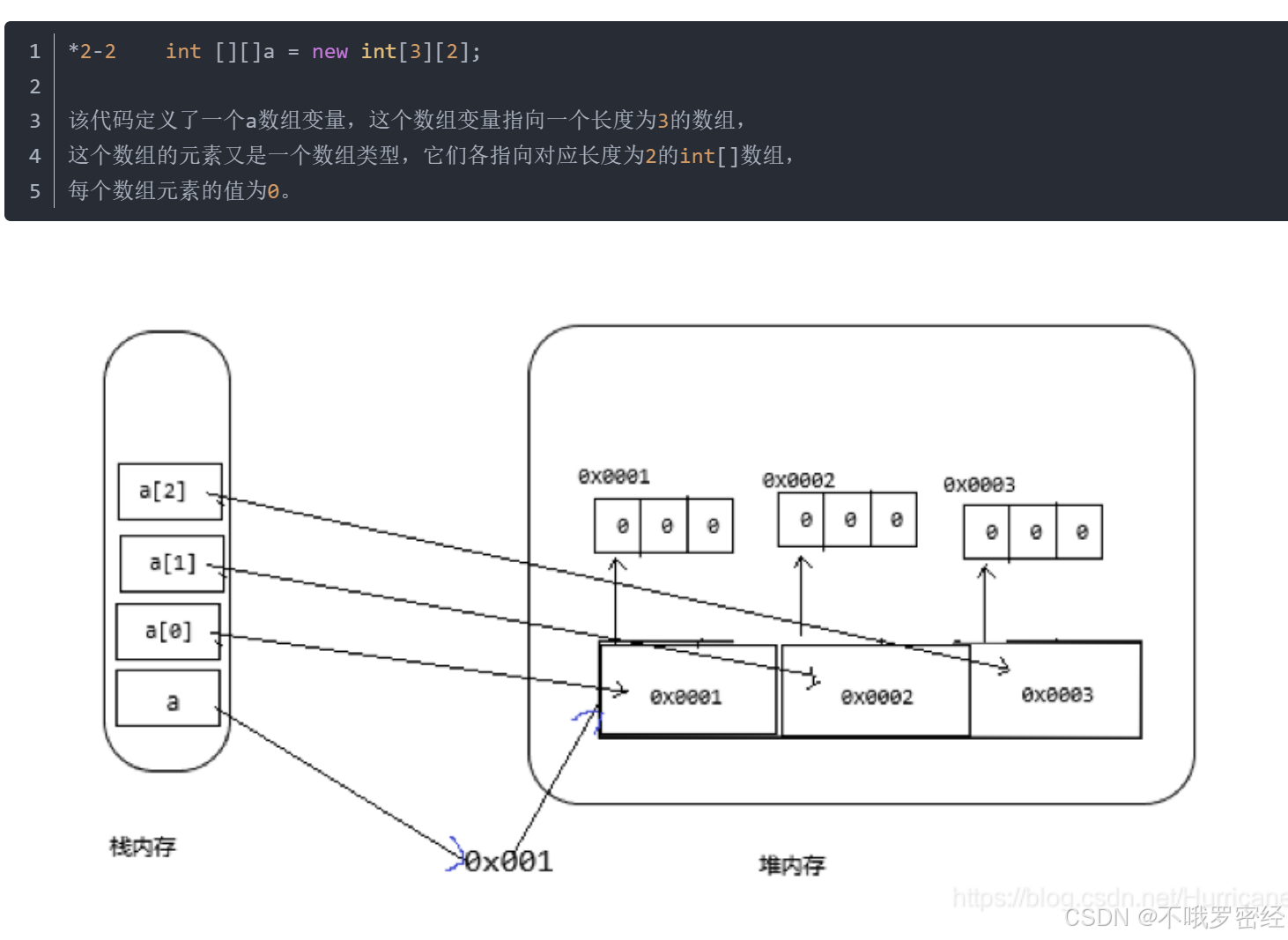
2.遍历:
内有属性length 可以修改数据元素【基本和引用均可以】
可以用增强for循环进行遍历,但是这个方法不可以修改数据元素,对于基本数据元素我们不可以对其重新赋值(会创建一个新的地址,新的元素);但是对于引用类型来说,里面的属性我们是可以改的。
管理数组的常用类Arrays 经常用的方法 Arra3344ys.sort(nums) 进行排序
ps:List<Integer>转为int[],除了遍历后赋值,还可以用Stream API
(使用 Stream API 转换集合时,可能会有一定的性能开销。如果数据量较大,可以考虑使用传统的循环方式。)
使用 mapToInt 方法将 Integer 转换为原始 int 类型,然后通过 toArray 方法生成数组
public class ListToIntArray {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 将 List 转换为 int[]
int[] intArray = numbers.stream()
.mapToInt(Integer::intValue) // 将 Integer 转换为 int
.toArray(); // 转换为 int[] 数组
// 打印结果
System.out.println(Arrays.toString(intArray)); // 输出:[1, 2, 3, 4, 5]
}字符串
1.定义 new String(); new String(char数组); str="hello"; new String(byte数组,从哪开始,长度):
new String(byte数组)
2.遍历:
方式一:
字符串的遍历方式
for(int i=0;i<s.length();i++) {
s.charAt(i);
}
字符串没有继承迭代器,不能用增强for循环
方式二:
通过s.toCharArray()转成字符数组,再通过增强for循环
for(char c:s.toCharArray()) { }
3.常用方法 【截取1个 查找2个 替换1个 格式化字符串1个】
- s.length()
- s.charAt()
- s.toCharArray()
- s.indexOf(String neddle) 查找s字符串第一次与neddle字符串匹配的位置,不匹配返回-1
- s.substring(beginIndex,endIndex) 左闭右开,可以省略endIndex默认截到最后
s.substring(start, start)两者相等返回的是一个空字符串 ("")。 - s.contains("") 看字符串中是否包含这个子串
- s.replace(str1,str2) 将s中的str1替换为str2,并返回一个新字符串
- String.valueOf(Object e) 将对象转为字符串
- String.format(format, arguments)是 Java 中用于创建格式化字符串的方法。
%s: 字符串
%d: 整数
%f: 浮点数 -> String result = String.format("Formatted number: %.2f", number); 四舍五入
%x: 十六进制整数
%t: 日期和时间
-->联想 System.out.printf(format, arguments)方法是 Java 中用于格式化输出字符串的一个非常方便的工具。
格式说明符与上面一致。可以进行位数限值(%.2f),宽度控制(右对齐%10d,左对齐%-10s)
System.out.printf("PI to four decimal places: %.4f\n", pi); // 输出: PI to four decimal places: 3.1416 四舍五入
System.out.printf("%-10s%-10d\n", "Bob", 80);
4.ascii码和java字符相互转换
'c'-0 --> ascii码
char(79) --> 字符
包装类
对于包装类 == equals 方法:
- ==(若是基本数据类型,比较的是值)比较地址
如果右边是常量,会拆包,比较值是否一致 - equals都进行了重写,比较值是否一致
Java基础数据类型之包装类equals和==详解_包装蕾==和equals-优快云博客
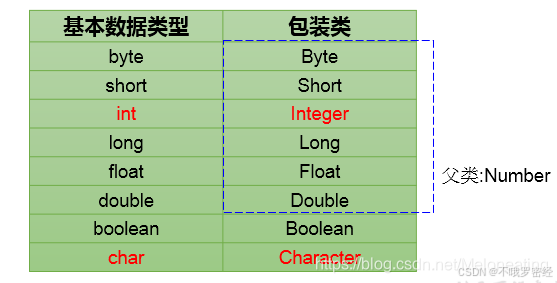
1.Integer
- Integer.MAX_VALUE
- Integer.valueOf
- Integer.parseInt()
- Integer.intValue()
- Integer.doubleValue()
- Integer.toString
2.Character
- Character.isLetter('2') //false 判断字符是否为字母
- Character.toUpperCase(c)
- Character.toLowerCase(c)
互相转换:
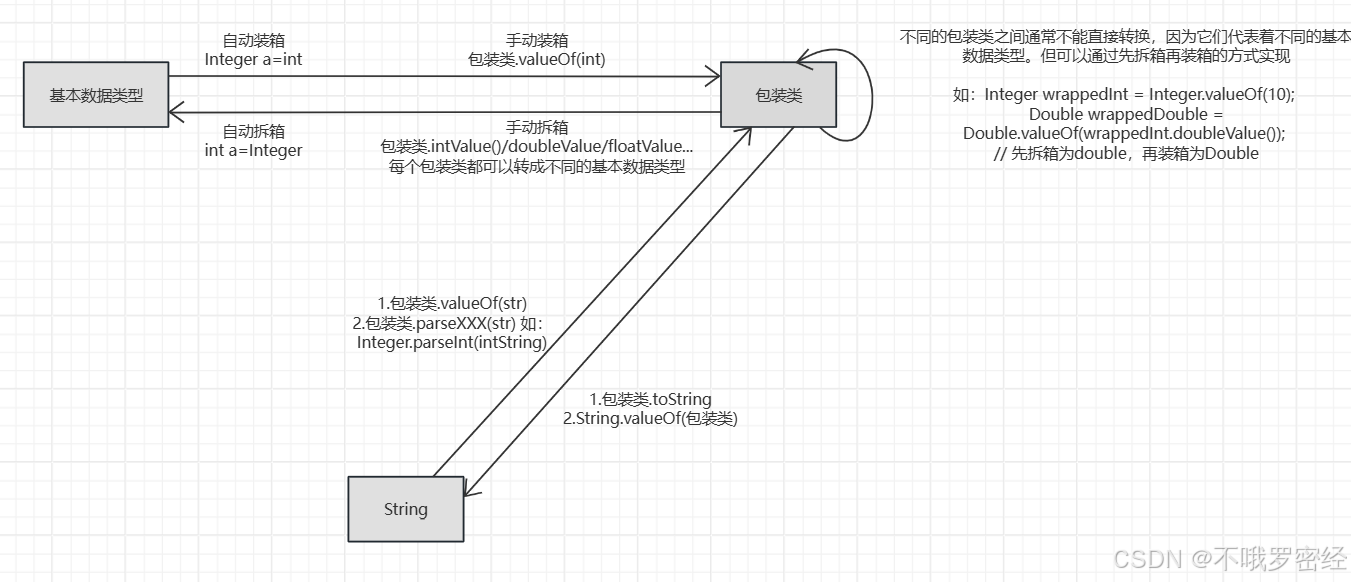
注意:
一. 在String转包装类时,有valueOf和parseInt两种方法,但区别是
valueOf --> 是String到Integer
parseInt --> 是String到int基本类型
所以这里图画的不太对哈哈,应该是画到String到基本数据类型上去。二.自动装箱的问题
Integer sum=0;
sum+=1; 那在执行这个的时候,会先进行拆包,即先转为int类型,之后再装为Integer,此时底层用的就是new Integer。所以每次我们加1,都会new一个新的对象。
其中用的比较多的有,String和Integer间的转化,字符和Integer间的转化
public static void main(String[] args) {
//字符串转int
String str = "23";
int num = Integer.parseInt(str); //23
Integer num1=Integer.valueOf(str); //23
System.out.println(num);
System.out.println(num1);
//字符char转int
char c = '2';
System.out.println(Integer.valueOf(c)); //50 是转为ASCII码
int num2 = c - '0';
System.out.println(num2); //2
}常用类
Arrays
- Arrays.sort
- Arrays.asList(i,j,k)
- Arrays.copyOf(要复制那个数组,复制数组的长度) Arrays.copyOf(ch,ch.length)
Math
- Math.min()
- Math.max()
- Math.round(浮点数) 四舍五入
- Math.floor(浮点数) 小于等于
- Math.ceil(浮点数) 大于等于
- Math.abs(x) 返回x的绝对值
- Math.sqrt(double x) x开方
- Math.pow(doble a,double b) a的b次方
BigDecimal
double和float会导致小数计算精度的丢失
如:System.out.println(0.1 + 0.2); // 输出:0.30000000000000004
这种精度的缺失,在类似于金融系统这样需要高精度运算的系统中可能是不能被接受的,那么float和double为什么会导致精度缺失呢?是因为计算机保存浮点数的机制,宽度有限,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生丢失的情况。(是2的负次方来加出来的,所以肯定精度上不够)
好在JDK为我们提供了BigDecimal,可以进行高精度运算,不会造成精度的丢失
BigDecimal底层是用字符串存储数字(故BigDecimal也是不可变的), 运算也是用字符串做加减乘除计算的, 所以它能做到精确计算. 所以一般牵扯到金钱等精确计算,都使用BigDecimal。
BigDecimal a = new BigDecimal("1.23");
BigDecimal b = new BigDecimal("4.56");
// 加法
BigDecimal sum = a.add(b); // 5.79
// 减法
BigDecimal difference = a.subtract(b); // -3.33
// 乘法
BigDecimal product = a.multiply(b); // 5.6088
// 除法(需要指定舍入模式)
BigDecimal quotient = a.divide(b, 2, RoundingMode.HALF_UP); // 0.27Date
new Date() 表示当前时间到毫秒 :Mon Feb 03 21:15:09 CST 2025
new Date(Long time) time是到1970年的毫秒数
new Date(System.currentTimeMillis()+1000 * 60 * 60 * 24):Tue Feb 04 21:38:13 CST 2025
如果想要显示我们可以轻易看懂的可以搭配SimpleDateFormat来做输出转化:
Date nowTime = new Date();
SimpleDateFormat matter = new SimpleDateFormat("现在时间:yyyy年MM月dd日E HH时mm分ss秒SSS毫秒");
logger.info(matter.format(nowTime));StringBuffer
- StringBuffer n=new StringBuffer(" ");
- n.append(" ")
- n.charAt()
- n.setCharAt(位置,要设置的字符)
- n.deleteCharAt
- n.delete(begin,end) 删除[begin,end)索引的字符串
- n.equals 这个方法没有重写,比较的是引用类型的地址 可以将stringBuffer先转为String再比较
- n.toString()转换成String类型
- n.reverse()反转字符串
StringBuilder

集合【重点】
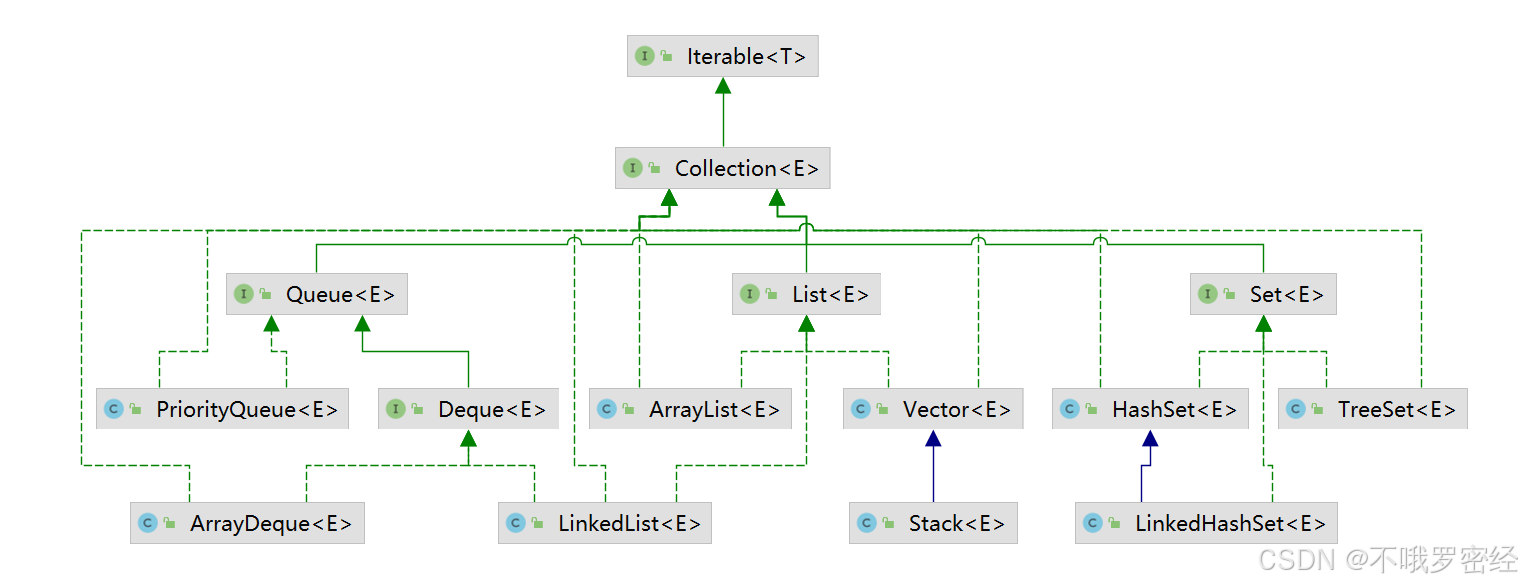
collection接口
实现类
collection接口 -> list set queue子接口 (继承迭代器可以用增强for循环)
- list(存取有序)实现类:ArrayList Vector(线程安全) LinkedList
- set(希望自动去掉重复元素)实现类:HashSet LinkedHashSet TreeSet
- queue实现类:PriorityQueue Deque子接口下有ArrayDeque LinkedList
List
1.ArrayList 底层是Object数组实现的(线程安全用CopyOnWriteArrayList)
扩容机制:
- 1. 当调用ArrayList的无参构造new对象时, ArrayList对象的初始容 量为0.
- 2. 当插入一个元素时, ArrayList会进行首次扩容(无参构造才会用首次扩容). 首次扩容, ArrayList会创建一个长度为10的新数组, 替换掉原来的旧数组. 此时ArrayList的长度就为10.
- 3. 当插入10个数据后, 要插入第11个数据时, 容量不足, 会触发第2次扩容. 第二次扩容会扩容原容量的1.5倍, 之后扩容都是原容量的1.5倍. ArrayList每次扩容都会创建新数组, 然后把数据转移到新数组中.更新引用(每次添加新的元素会size++,此处易出现线程不安全问题,size与实际放的大小不一致)
2.LinkedList 底层是双向链表,感觉插入删除比ArrayList快,但是其插入删除的性能其实很多场景比 ArrayList要差.
原因一:如果往某个位置插入数据, 需要从链表头部查找到对应的节点, 然后再插入. 找节点的时间复 杂度是O(n), 插入是O(1). 所以Java的 LinkedList插入性能很差. 只有往链表头部或者尾部插入性能会比较好.
原因二:是因为数组虽然插入需要移动元素, 但是由于CPU有三级缓存, 数组又是连续空间, 所以很容易就触发缓存, 缓存的操作速度又非常快. 所以这就导致, 即便要移动数据, 在缓存中移动数 据未必比链表插入要慢. 所以开发使用99%的场景都应该用 ArrayList.
3.Vector 线程安全版ArrayList, 底层用数组实现, 但是大量使用 synchronized加锁, 性能差, 已经不会使用
Set
Set不允许重复元素
1.HashSet底层HashMap(无序)key相同,后面的值直接被抛弃,不会覆盖
2.LinkedHashSet底层LinkedHashMap(插入和取出顺序一致)
3.TreeSet 底层红黑树(有序)
构造方法 这个接口下的在实例化时构造方法可以不填,也可以填Collection接口的实现eg.Set<Integer> set=new HashSet(); or Set<Integer> set=new HashSet(Collection);
Set<Integer> set=new HashSet(Arrays.asList(1,2,3));
collection遍历
1.迭代器遍历
Iterator iterator = collection.iterator();
while(iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
注意:
1)迭代器遍历是遍历的集合当前的快照。所以用集合的增加删除方法,迭代器不知道状态改变了,所以变出现异常。
迭代器遍历时,删除可以用iterator的remove方法。
2)但是增加就不行了,iterator是不会复位的。
3)NoSuchElementException(无索引所以不报指针越界)
可以用迭代器删除,增加修改不可以【可以修改引用类型的属性】2.增强for
底层就是迭代器,为简化迭代器出现
由于底层是迭代器,但是没拿到迭代器,所以不可以调用迭代器的remove方法,所以增强for在遍历时不可以修改删除添加元素【可以修改引用类型的属性】3.Lambda表达式(java 8开始)
可以使用 集合.forEach方法遍历
调用forEach要传入一个实现了Consumer接口的类,这个类必须要重写accept方法
forEach方法中把遍历的每个元素交给accept方法处理
也就是说accept(Object o)其中o就是集合中的每个对象
可以用Lambda表达式简化 集合.foreach(遍历的元素 -> 进行的操作)
底层也是迭代器,也不可以修改删除添加【可以修改引用类型的属性】
实现collection接口都可以用的方法
- add添加一个元素,如果添加的是引用类型,会将地址放入,如果之后的操作修改了添加的引用类型,那之前状态下添加的也会变,所以要创建一个新的副本报存当前状态的引用类型。如:ans.add(new ArrayList<>(temp));
- remove删除一个元素 set,remove("second")
- contains查看有没有这个元素 --> 调用equals方法来比较两者是否一致
- size看集合大小
- isEmpty()
list接口独有遍历和方法
遍历
List实现了collection接口,所以以下三种都可以用
- 迭代器遍历 --> 遍历时要删除用这个
- 增强for循环 --> 只是遍历
- Lambda表达式 --> 只是遍历
还有两个特有的
- 普通for循环 -->遍历时操作索引用这个(增删改)
- 列表迭代器 --> 遍历时删除添加修改元素用这个
普通for循环:
for(int i=0;i<list.size();i++) { System.out.println(list.get(i)); }列表迭代器:
修改:set()改变当前遍历的元素,也就是next()返回的元素
ListIterator<String> listIterator = list.listIterator(); // 遍历列表 while (listIterator.hasNext()) { String item = listIterator.next(); // 在遍历到"B"时修改为"NewB" if ("B".equals(item)) { listIterator.set("NewB"); // 修改当前元素 } } System.out.println(list); // 输出: [A, NewB, C] } }增加:add()在当前遍历元素的后面添加,也就是next()返回元素的后面
ListIterator<String> listIterator = list.listIterator(); // 遍历列表 while (listIterator.hasNext()) { String item = listIterator.next(); // 在遍历到"B"时插入新元素"newElement" if ("B".equals(item)) { listIterator.add("newElement"); // 安全添加元素 } } System.out.println(list); // 输出: [A, B, newElement, C] }
实现list接口都可以用的方法:
- add(index,ele) 如add(3,1);在坐标我3的位置插入1这个元素
- get(i) 得到坐标为i的元素
- remove(int index):移除指定index位置的元素,并返回此元素 当然也可以调用collection中的remove(object) 看哪个匹配
- 从 Java 8 开始,
List接口也提供了一个默认方法sort(Comparator<? super E> c)
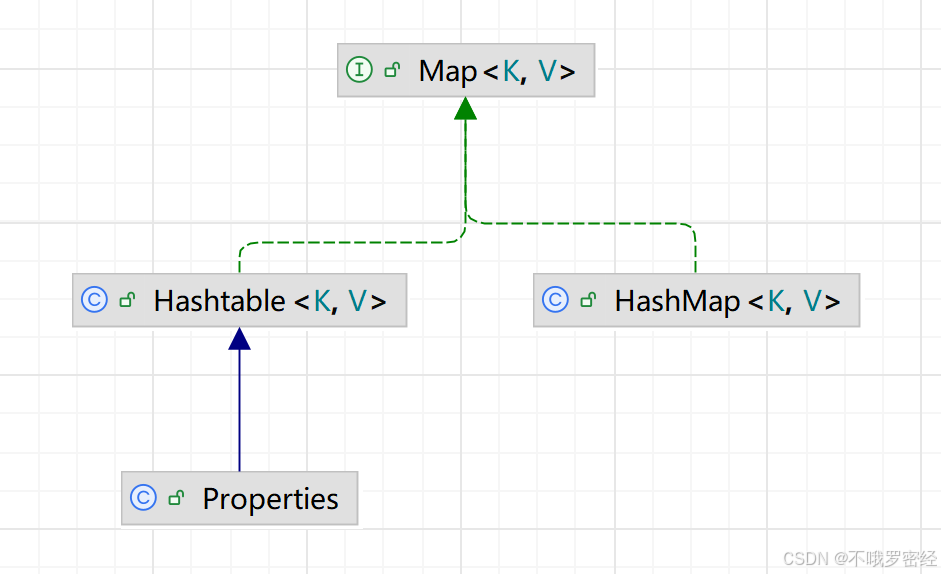
map接口
实现类
- HashMap 底层数组,链表/红黑树 键无序无重复
(key可为null,在插入计算hash值后不用hashcode方法直接为0)
key相同后来的值会覆盖新的值- LinkedHashMap 在HashMap的基础上,Node(存<key,value>的对象)加了一个指针指向下个元素 键插入和取出顺序一致
- TreeMap 底层红黑树,键排序
- HashTable HashMap的线程安全版, 但是大量使用 synchronized加锁, 性能差, 已经不会使用
- CurrentHashMap: HashMap的线程安全版, 没有大量加锁, jdk1.7使用分段锁设计, 1.8开始锁桶, 性能比Hashtable好很多, 经常使用.
HashMap底层
map接口成员:
- interface Entry -> getKey() getValue()
- Set<Map.Entry<k,v>> entrySet
- Set<K> keySet()
- Collection<String> values()
- object方法重写
- 特有方法
HashMap是Map的实现类,主要成员有以下:
- 内部类Node,实现了Map.Entry接口(非public)Node就是放键值对
- 内部类EntrySet extends AbstractSet<Map.Entry<K,V>>
- 内部类KeySet extends AbstractSet<K>
- 内部类Values extends AbstractCollection<V>
- 存放Node的数组,Node<K,V>[] table
实现了以上三个背景为蓝色的抽象方法,就是返回相应的内部类,这三个内部类都继承了AbstractXXX,这个AbstractXXX实现了set/collection接口,所以可以返回。
HashMap<K,V> map=new HashMap();
map.put("no1","hsp");
map.put("no2","张无忌");当我们调用put方法时,实际上是在调用下面的方法,
putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)
我们传入参数putVal(hash(key), key, value, false, true)
参数hash:根据key算出hash值,也就是在数组table的索引
参数onlyIfAbsent:如果为
true,只有在键不存在时才插入新的值。(set中填true)参数evict:如果为
true,可能会触发清除老旧的数据大致流程:
- 首先检查
table是否为 null 或者长度为 0。如果是,则需要调用resize()方法扩大 HashMap 的容量,第一次默认大小为16的数组table- 计算索引(也叫桶下标),用key对象的HashCode()方法计算,之后此hash值再调用HashMap的hash方法进行二次hash, 获取到二次hash值.之后hash&(n-1)为索引
(二次hash是为了让hash值分布更加均匀, 减少hash冲突, 从而使链表更短, 因此也就提升了查找效率.
n为数组长度,要求n必须为2^x次,因为本应该是hash%n,为了提高效率只有当n为2^x次时才可以与hash&(n-1)等价计算)- 若数组索引处为空插入Node(Node就是Map.Entry的实现类)
- 如果计算后的索引不为空,处理冲突(通过链表和红黑树一起处理)
1. 在插入前会先遍历链表或红黑树,查看该Node的key是否被插入过(查找是否存在相同的键(key),HashMap会通过equals()方法比较键的相等性,而不仅仅是通过引用比较)
2. 如果找到了相同的键,会更新该键对应的值(即用新的值覆盖旧值)。(Ps:如果onlyIfAbsent参数为true,则不会更新值,所以set就不会覆盖旧值。)
3. 没有就插入链表上或红黑树上
如果链表长度小于 8,将新节点插入到链表中。
如果链表长度大于等于 8且数组长度大于等于64,链表转换为红黑树,新节点会插入到红黑树中,并可能需要进行红黑树的调整(如旋转、重新着色等)
4.若数组长度小于64会先进行数组扩容。扩容机制是创建一个新的两倍大小的数组,将旧数组中的键值对重新计算hash算分配位置,更新HashMap数组引用地址。
5.之后加完后size++,会看是否要扩容,当hashmap中的元素个数超过数组大小*负载因子(0.75) 时,就会进行数组扩容.【HashSet的底层就是维护了一个HashMap,其中set中add的值就是Node的key,value就是一个空的Object,然后调用putVal方法,传入时onlyIfAbsent为true,有冲突的话就不插入值了,保证值唯一;同理计算索引为Key的HashCode()方法,比较Key的方法也是
equals()方法 】
所以在用自定义对象时一定要注意equals()和hashcode()方法的重写遍历
对应以上三个方法,下面详细怎么用
这三种方法本质上都是遍历table或者链表或者红黑树,并将数据封装成不同的对象放入相应的集合视图中。
那为什么用set呢?首先set语义上就是无序唯一的,所以用set语义上清晰符合map数据的特点;并且set存放数据的唯一性也给了二次保障。为什么
values()返回的是Collection而不是Set?虽然
values()也可以返回一个Set,但HashMap的值是可以重复的。因此,返回一个Collection更为合适,因为Collection是一个更通用的接口,允许重复元素。如果返回一个Set,则可能会丢失重复值的信息。Map<String,String> map = new HashMap<>(); map.put("no1","hsp"); map.put("no2","张无忌"); Set<Map.Entry<String, String>> entries = map.entrySet(); System.out.println(entries.getClass()); //class java.util.HashMap$EntrySet for(Map.Entry<String,String> entry:entries) { System.out.println(entry.getClass()); //class java.util.HashMap$Node System.out.println(entry.getKey()+" "+entry.getValue()); }
一些八股:




ConcurrentHashMap
map的遍历
遍历map的key或value
for(int key:map.keySet()) {
int value=map.get(key);
}
for(String s:map.values()) {
System.out.println(s);
}
遍历map的键值对Entry
for(Map.Entry<Integer,Integer> entry:map.entrySet()) {
entry.getKey(); entry.getVaule();
}
map接口方法
- put (key,value) 添加键值对
- containsKey查看有没有这个建
- get通过键值得到值
- getOrDefault (key,默认值)
- size看map大小
经典用法:(以下两种均可用Stream API实现)
1.map按值排序
Java中实现Map按值排序的多种方法-优快云博客2.map按键排序
Collections
是一个操作Set,List,Map等集合的工具。提供了一系列静态方法对集合排序,查询,修改等。
常用方法:
- Collections.sort(List,Comparator) 修改原List,不是返回新列表
- Collections.reverse(List) 修改原List,不是返回新列表
栈和队列
队列先进先出用Queue LinkedList: 他也实现了Queue接口, 可以先进先出 ArrayDeque: 基于动态数组的双端队列。底层使用循环数组实 现. 栈后进先出用Stack Stack: 继承Vector, 大量使用synchronized加锁, 性能差, 已经不 会使用了. ArrayDeque: 基于动态数组的双端队列。底层使用循环数组实 现. 因为是双端队列, 故可以当栈用.
1.栈
stack栈继承了vector (故也线程安全)
常用方法:
- push
- pop 将栈顶元素弹出并且返回栈顶元素
- peek
- size
- empty
2.队列
queue接口 下有 deque接口
单端队列PriorityQueue(优先级队列)
(堆实现,会排序将优先级最小的每次出队,也可以构造时传入比较器,规定排序方式。
优先队列的头是最小的元素。检索到该元素后,下一个最小的元素将成为队列的头。
需要注意的是,优先队列的元素可能没有排序。但是,元素总是按排序顺序检索的。)
常用方法:
- offer / add (区别add时队列满会引发异常,offer时队列满会返回false)
- poll
- peek
- size
- isEmpty
可以自定义排序规则传入一个Comparator接口实现类,实现唯一一个抽象方法int compare(T o1, T o2);即可,正因为它是一个函数式接口,所以可以直接写一个lambda表达式即可。
eg:PriorityQueue<int[]> que=new PriorityQueue<int[]>((o1,o2)->o2[1]-o1[1]);
ps:这个泛型右边必须写上,左边写了那用que时编译知道泛型,右边没写那o1,o2还是被认成object,写了才是int[]
双端队列LinkedList,ArrayDeque 【也可以作为单端队列】
常用方法:【其中XXXFirst指的就是单端队列对应方法】
- offerFirst / addFirst
- offerLast / addLast
- pollFirst
- pollLast
- peekFirst
- peekLast
- size
- isEmpty
Java三大特征:封装 继承 多态
封装
类定义 class Person{} [类可被public final(代表不可被继承)修饰]
类成员
- 属性[public protected private static final(代表为为常量,不可被重新赋值)修饰]
(final修饰基本类型变量, 无法修改
inal修饰引用类型, 这个引用无法指向其他对象, 也就是地址 无法修改, 但是对象属性可修改.)- 方法[public protected private static final(代表不可被重写,但是可以重载) 修饰]
- 代码块[static]
- 构造方法[public protected private修饰]
- 内部类
public:当前类+当前包+其他包(项目可见性)
protected:当前类+当前包+其他包中的子类(子类可见性)【子类访问父类属性,不可以通过父类对象来访问,用子类对象可以访问】
缺省:当前类+当前包(包可见性)
private:当前类(类可见性)
继承
class B extends A{}
继承父类的所有类成员(构造方法和代码块除外),包括私有,只是不能访问
方法的重写
重写继承的方法时要求方法名,参数完全相同,返回值类型小于父类的,访问权限不能小于父类方法权限,子类不能抛出比父类更多的异常,只能抛出比父类更小的异常,或者不抛出异常
子类的私有方法虽然是继承的,但是是不可见的,所以“重写”父类的私有方法是没有问题的
【重写和重载的区别】
重载发生在用一个类中或继承关系中,方法名相同,形参列表不同
重写发生在继承关系中,方法名相同,形参列表相同,访问权限子类大于等于父类 返回值类型和异常类型子类小于等于父类
调用父类super
所有类和接口默认继承java.lang.Object
其中有方法
1.toString:
- 当我们打印一个对象的引用时,实际是默认调用这个对象的toString()方法
- 当打印的对象所在类没有重写Object中的toString()方法时,默认调用的是Object类中toString()方法。
- 返回对象的类型+@+哈希表
- 当我们打印对象所 在类重写了toString(),调用的就是已经重写了的toString()方法,一般重写是将类对象的属性信息返回。包装类和String都重写了toString所以才是返回字符串形式的值
2.equals
3.hashCode
简单地说,hashCode() 方法通过哈希算法生成一个整数值。
相对的对象(通过equals方法判断)返回相同哈希值,不同对象返回不同哈希值不是必须的。重写了equals也要重写hashCode,让equals相同的对象返回的hashCode也是一样的。因为在hashset,hashmap中我们使用hashcode()和 equals()判断是否为同一个对象的。
为了让hashCode尽量独一无二,可以调用Object.hash(sex,age,name)会根据sex,age,name来产生hashCode,如果这三者一样,会产生一样的hashCode
Java用 hashcode()和 equals()判断是否为同一个对象
- 如果两个对象的 hashCode 值相等,那这两个对象不一定相等 (哈希碰撞)。
- 如果两个对象的 hashCode 值相等并且 true,我们才认为这两个对象相等 equals()方法也返回
- 如果两个对象的 hashCode 值不相等,我们就可以直接认为这两 个对象不相等
多态
把⼀个子类对象直接 赋给⼀个父类引用变量,无须任何类型转换, 或者被称为向上转型,向上转型由系统自动完成。
当把⼀个子类对象直接赋给父类引用变量时,例如 FatherObj o = new SonObj(), 这个编译时类型是 FatherObj,而运行时类型是 SonObj,当运行时调其方法时,其方法行为实际是子类 的行为, 也就是SonObj的行为. 这就可能出现:相同类型的变量、调用同一个方法时出现不同的行为,这就是所谓的多态
抽象类:(名词)
权限修饰符 abstract class 类名{}
抽象类就是一个类,普通类有的它都有,多一个抽象方法,如:public abstract void test(参数列表); 只有声明没有实现
也可有构造方法,但是有也无法实例化,抽象类是无法实例化的,这个构造方法只是子列实例化时可调用父类构造器,方便赋值。接口:(动词)
interface 接口名 [extends 父接口1,父接口2,...] {
//常量定义 都属于全局静态常量,默认由public static final来修饰
//方法定义
抽象方法 void fly();默认前面用public abstract修饰
普通的静态方法 public static void showInfo1(){}
default修饰的成员变量 default void showInfo2(){}}
没有构造方法,没有需要其赋值的属性class 实现类 [extends 父类] implements 接口{}
接口可以多个实现,弥补了java只能单继承的缺点。


拷贝
引用拷贝
引用拷贝就是复制一个对象的引用,使得两个引用指向同一个对象。任何一个引用对对象的修改都会影响到另一个引用。
浅拷贝浅拷贝会创建一个新对象,然后将原对象的非静态字段复制到新对象。如果字段是值类型(基本类型),则复制该字段的值;如果字段是引用类型,则复制引用而不复制引用的对象。因此,原对象和拷贝对象会共享引用类型的字段。
在Java中,通常通过实现
Cloneable接口并重写clone()方法来实现浅拷贝。深拷贝
深拷贝会创建一个新对象,并递归地复制原对象的所有字段,包括引用类型字段所引用的对象。因此,深拷贝得到的对象和原对象完全独立,互不影响。
实现深拷贝有两种方式:
重写
clone()方法,并对每个引用类型字段进行克隆。通过序列化和反序列化实现。
JVM基础
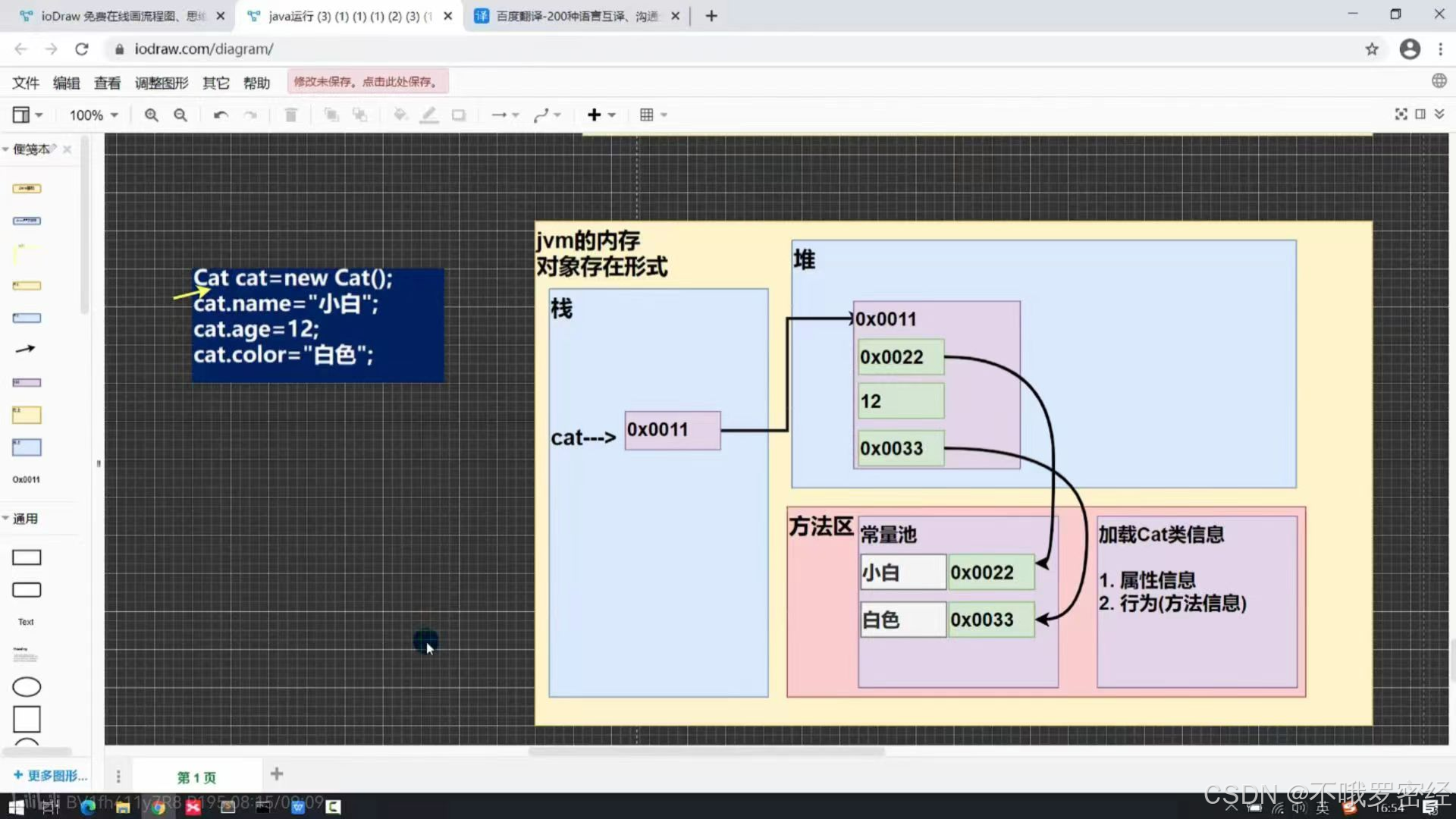
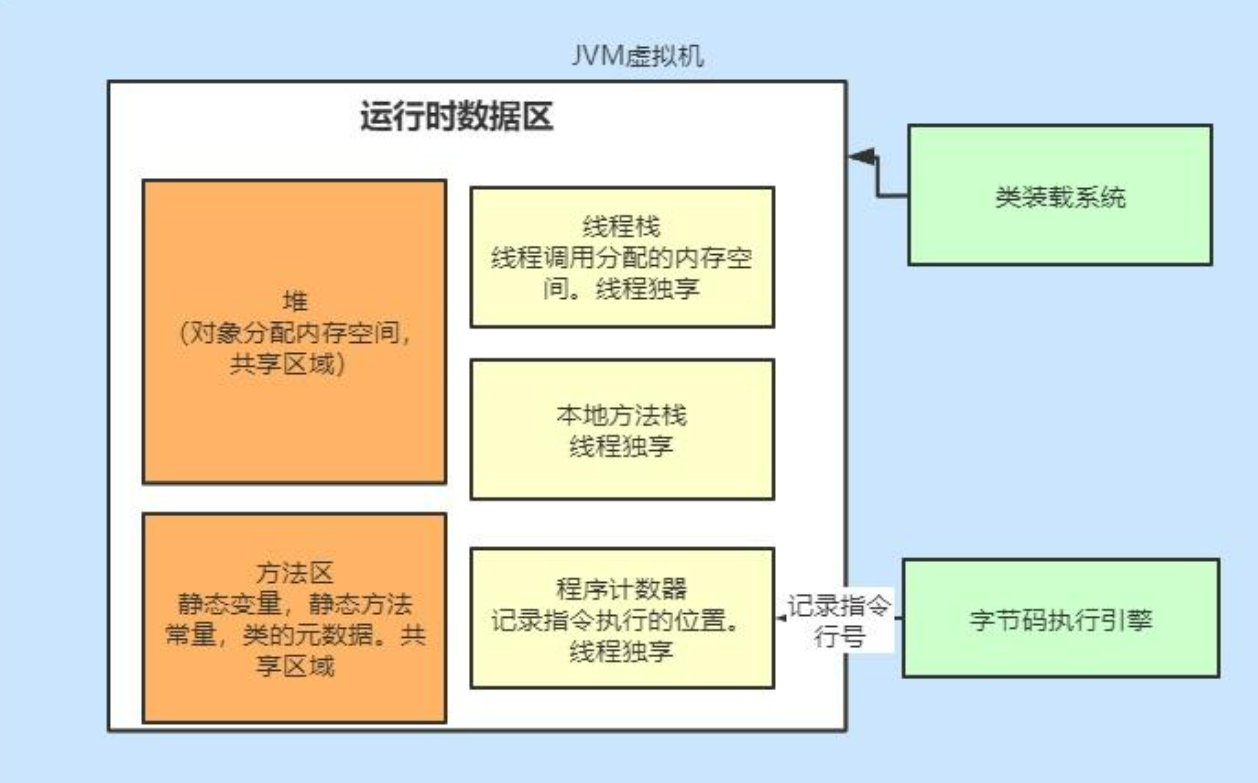
jvm内存分布
JVM内存模型主要是指运行时数据区。JVM主要包含三块:运行时数据区,类装载子系统,字节码执行引擎。
我们知道java是多线程的,其中堆和方法区是线程共享的。栈是线程私有数据区。
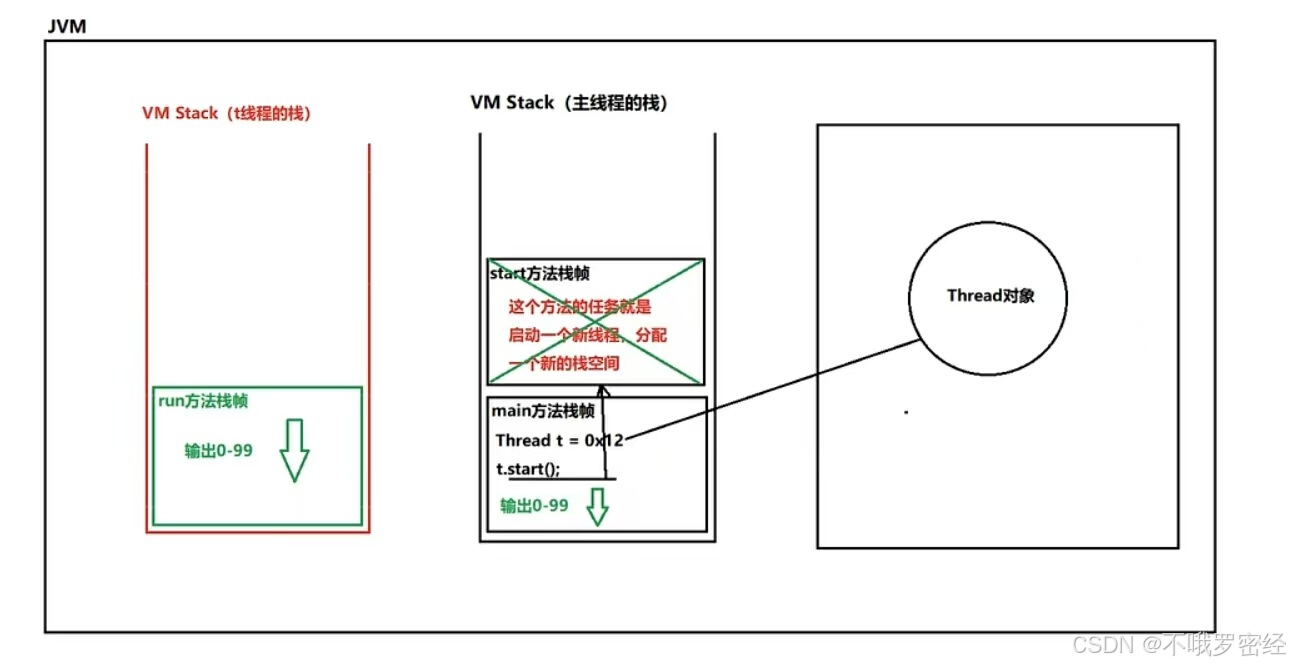
线程栈(JVM栈):每个方法的调用都会创建一个栈帧,方法执行完毕后,栈帧会被销毁。(下面有例子讲解)
本地方法栈:执行C++写的native方法
程序计数器:用于存储当前线程执行的字节码指令的地址
tips:下面例子说明了每个方法运行都会创建一个栈帧,如main方法内有自己的栈帧,在main的栈帧中基本数据类型int a是10,就存在此栈帧中。当执行func后其会有自己的栈,在这个栈帧中存了一个a为10,后来赋值为11,之后运行完毕,此栈帧销毁,所有存的a也没了。
public class Main{ public static void main(String[] args) { int a=10; new Main().func(a); //输出a仍为10 } public void func(int a) { a=11; } }类的加载
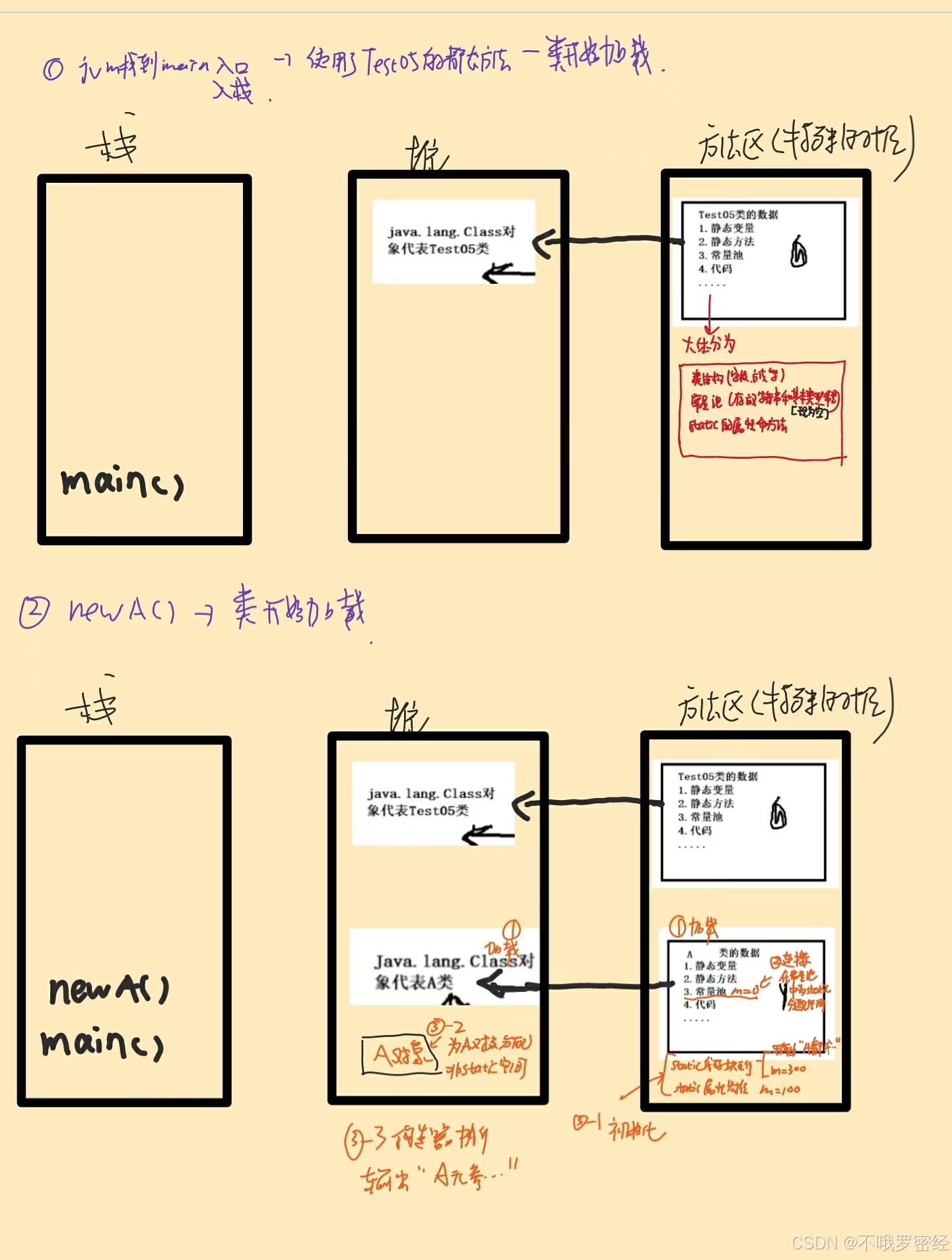
写好的java文件最后jvm要编译为class字节码文件
最后的字节码文件需要放在jvm内存模型上来运行。那这些字节码文件最后是怎么到jvm平台的呢?是通过类加载器(ClassLoader)将其放入jvm平台的,以下即为其过程。
类的加载 [加载 连接 初始化] (也就是编译好的class文件jvm是怎么将其运行起来的)
何时被加载:
- 第一次new创建对象实例时
- 第一次创建子类对象实例,父类也会被加载(但是不会实例化,仅加载)
- 第一次使用类的静态成员时(静态属性,静态方法)
- 反射获取class对象
1.加载:
- 指将类的字节码从
.class文件读取到方法区变成可以跑起来的数据结构,有存放类的结果信息,包括所有字段、所以方法等描述信息(就是类型,访问权限等)之外,还有个常量池(不同class中的常量池是共享的),包含了在编译期生成的字面量(量本身-也就是值)和符号引用(在解析过程变成直接引用)(现在是空的)
(ps:现在是所有结构都有,但是字段没有初始化不可用,静态方法直接可以用了,但是非静态方法需要有对象上下文才可以用,所以也不可用,只有当非静态属性初始化后才可以用)- 所有放到方法区的class文件都会生成一个Class类的实例,代表这个加载的类
【 反射的基础 ! 我们所有的类,其实都是Class类的实例,他们都拥有相同的结构----- Field数组、Method数组。而各个类中的属性都是Field属性的一个具体属性值,
方法都是Method属性的一个具体属性值 】【简述:jvm将编译好的class文件放到方法区,并根据此文件生成class实例,开辟此类的常量池空间】
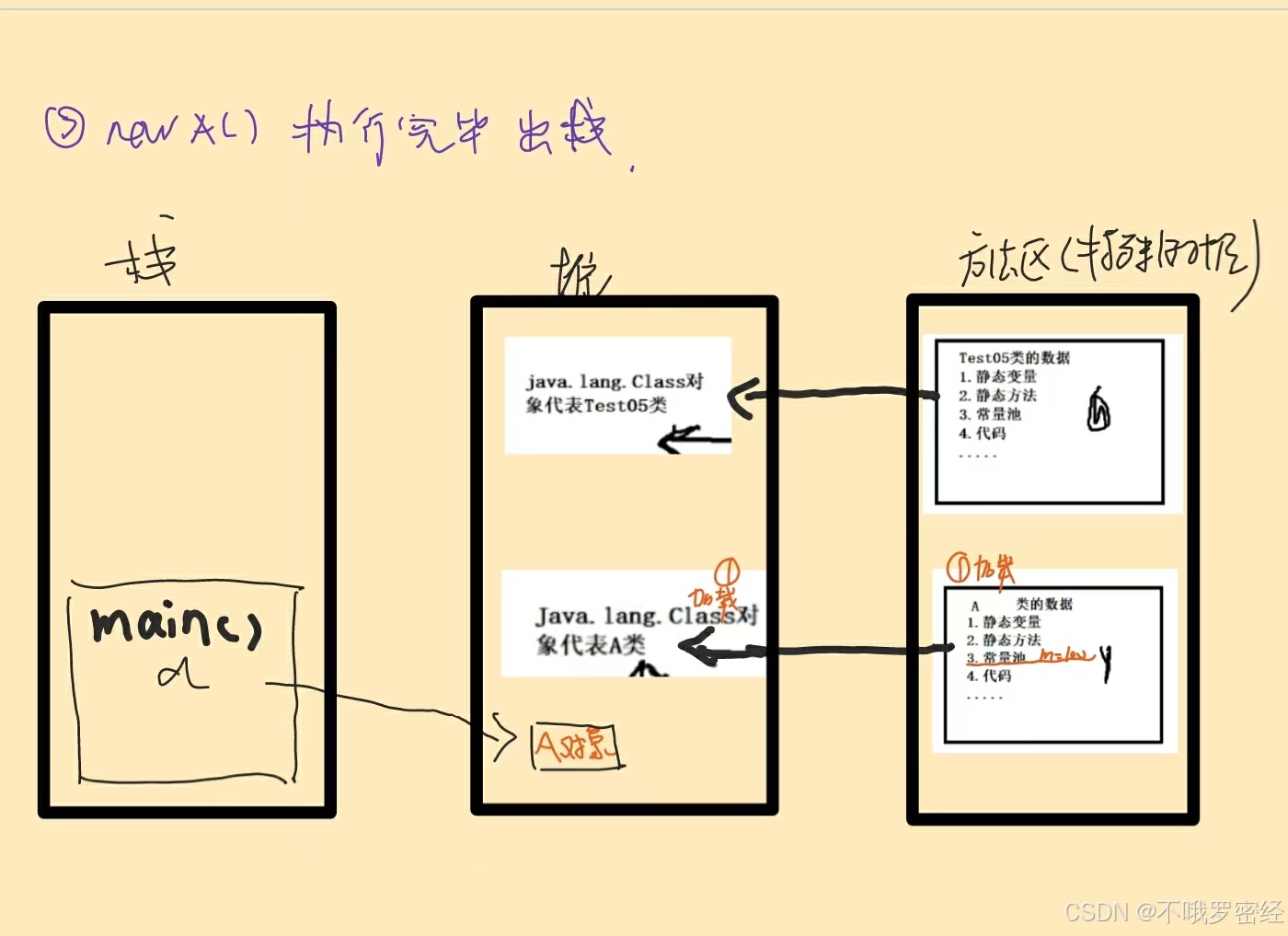
2.连接[验证 准备 解析]
- 验证:class文件有没有,class对象生成没有
- 准备:为static变量在方法区中分配空间,并默认初始值
【int为0,boolean为false ,final的就为其值,如果是static对象属性,存的是其符号引用 如:static Myclass instance; 存是Myclass这个类名,初始值为null (之后再在初始化阶段创建实例后再改为其地址)
静态常量 static final 放入常量池
】- 解析:常量池符号引用变为直接引用(也就是将类名变为此类的class实例,就是getClass返回的对象)
3.初始化
- 先static代码块 static属性(无优先级,看顺序)
4.实例化
- (先在堆区分配对象空间)再非static代码块 非static属性(无优先级,看顺序)
- 构造器
有继承关系的,先父类子类的静态部分执行完即全部初始化后,再父类非static构造器,子类非staitc构造器,在这个期间,如果调用的方法在子类父类中都有,会遵循就近原则
- 会先将父类的静态属性代码块执行
- 再子类的静态属性代码块执行
- 之后实例化父类非static代码块 非static属性构造器(与子类中super(参数)的调用一致,要没有默认super();)
- 再实例化子类非static代码块 非static属性构造器
例子:
注意:常量池共享
public class A {
public static final String a = "hello"; // 在 class A 的常量池中
}public class B {
public static final String b = "hello"; // 在 class B 的常量池中
}public class Main {
public static void main(String[] args) {
System.out.println(A.a == B.b); // 输出 true,表明它们指向同一个对象
System.out.println(A.a.equals(B.b)); // 输出 true,表明内容相同
}
}
当类已经加载过一遍了,new对象执行什么?
1.在堆区分配空间
2.非static属性默认初始化
3.执行非静态初始化快执行非静态属性赋值(无优先级按顺序)
4.执行构造函数
(保证了static是只有一份共享的!)
类加载器补充:
生命周期:
加载(Loading)
链接(Linking)
初始化(Initialization)
使用(Using):类被使用,创建对象、调用方法等。
卸载(Unloading):当类加载器被垃圾回收时,类也会被卸载。
层次:
启动类加载器(Bootstrap ClassLoader)
负责加载Java的核心类库(如
rt.jar中的类)。由本地代码实现,无法通过Java代码直接访问。
扩展类加载器(Extension ClassLoader)
负责加载Java的扩展类库(位于
lib/ext目录下的类)。由Java代码实现,通常是
sun.misc.Launcher$ExtClassLoader。应用类加载器(Application ClassLoader)
负责加载应用程序的类路径(
classpath)中的类。由Java代码实现,通常是
sun.misc.Launcher$AppClassLoader。自定义类加载器
开发者可以根据需要创建自定义的类加载器,用于加载特定路径下的类文件或实现特殊的加载逻辑。
自定义类加载器需要继承
java.lang.ClassLoader类,并重写findClass方法。模式:
Java的类加载器采用 双亲委派模型,确保类加载的顺序性和安全性。
双亲委派模型是Java类加载器的核心机制,其工作原理如下:
加载请求:当一个类加载器收到类加载请求时,它不会直接加载这个类,而是先将请求委派给它的父类加载器。
递归委派:父类加载器会继续将请求委派给它的父类加载器,直到最顶层的启动类加载器。
加载类:如果父类加载器无法加载该类(即在它的加载路径中找不到该类),则子类加载器才会尝试自己加载该类。
反射与注解
在运行时动态的操作类中的成员,如;运行时根据数据库提供的类名或方法名,或者基于字符串变量来动态实例化对象或调用方法 -->反射来提供此需求
1.获得类的class对象(3种)
1.<类名>.class
在编译时就确定好获得的类,属于静态引用 Class<User> userClass=User.class;
用此方法获得类对象时,不会立即触发初始化,只有创建实例或访问静态成员时才会被触发
(也就是只会进行类加载的前两步:1.加载 2.连接)2.实例对象.getClass()
已经有实例对象,Class<?> clazz=user.getClass();
这里泛型用通配符,改为User会报错,原因就是user对象实际的运行类型是什么只能在运行时获取,在编译时确定会报错。
new对象时就把所有的加载都执行了,getClass只是拿到这个class对象3.Class.forName("完整类名") 静态方法
Class<?> aClass = Class.forName("com.yang.pojo.Car"); 这里泛型也是统配符原因同上
运行时动态的加载指定的类,把加载全部执行了4.ClassLoader
直接调用类加载器,loader.loadClass(" ")可指定加载路径除classpath下的也可以加载。执行加载和连接后返回Class对象
2.class对象的属性
1.带Declared
一个类中声明的所有成员,不管其访问权限如何,不包含父类成员2.不带Declared
仅用于获取公共成员,包括从父类继承的公共成员eg. 获得当前类的所有属性:Field[] declaredFields = aClass.getDeclaredFields();
获得指定的属性: Field name = aClass.getDeclaredField("name");
获的指定的方法:(后面可以加指定参数)Method function = aClass.getDeclaredMethod("function");
Method function = aClass.getDeclaredMethod("function", String.class);
获得指定的构造器:(后面可以加指定参数)
Constructor<?>declaredConstructor=aClass.getDeclaredConstructor();
aClass.getDeclaredConstructor(String.class,Integer.class);
获得所有的注解(这里得到的注解时在类上的)
3.得到的成员的属性
得到的字段或方法或构造器对象的属性有什么
1.getName
2.getType
注意:有泛型的属性在获得type时,获得的是将泛型擦除的类型;想要得到具体的类型需调用方法getGenericType()3.getAnnotation() 字段or方法等上面也可加注解,在这里获取
4.设置权限 setAccessible(true); fina都可以修改了 超级强
类中静态成员的访问和修改
1.静态属性
对于public的静态属性,可以直接访问和修改Field field = aClass.getDeclaredField("publicStaticField");
field.set(null,12);
System.out.println(field.get(null));
对于非public的静态属性,要先设置权限为true,才可以访问和修改Field field = aClass.getDeclaredField("privateStaticField");
field.setAccessible(true);
field.set(null,100);
System.out.println(field.get(null));2.静态方法
对于public的静态方法,可以直接执行
Method function = aClass.getDeclaredMethod("function", String.class);
function.invoke(null,"yeah");对于非public的静态方法,要先设置权限为true,才可以执行
Method function = aClass.getDeclaredMethod("function", String.class);
function.setAccessible(true);
function.invoke(null,"yeah");类中非静态成员的访问和修改
1.创建类的实例
得到构造器->执行newInstance2.访问和修改与静态方法一致,只不过将null换为创建的实例
注解:注解就是打了一个标记,在框架中常用,打上标记然后通过反射判断是否为空或者值是否为我想要的,对不同成员进行不同操作。
public @interface anno{} 注解就是一个特殊的接口(也叫声明式接口),继承了java.lang.annotation.Annotation接口。JVM编译时将其转换为一个继承Annotation的接口,并生成相应class文件包括注解元数据其成员变量以及默认值。
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.FIELD) public @interface Desensitization { int startInclude() default 0; int endExclude() default 0; }有两个元注解(注解的注解)
@Retention表示注解的作用范围:
- @Retention(RetentionPolicy.SOURCE) 注解仅存于源码中,即根本不会生成在class文件中
- @Retention(RetentionPolicy.CLASS) 注解保留在class文件中,但运行时不可见,即在class文件中可以看到该注解,但是这个注解不会被加载到内存中
- @Retention(RetentionPolicy.RUNTIME) 注解会保留在class文件中,也会加载到内存,可以通过反射在运行时访问
@Target表示注解的作用域:
- @Target({ElementType.TYPE}) 可放在类上
- @Target({ElementType.METHOD}) 可放在方法上
- @Target({ ElementType.FIELD}) 可放在字段上
也可以组合写@Target({ElementType.METHOD, ElementType.FIELD})
异常
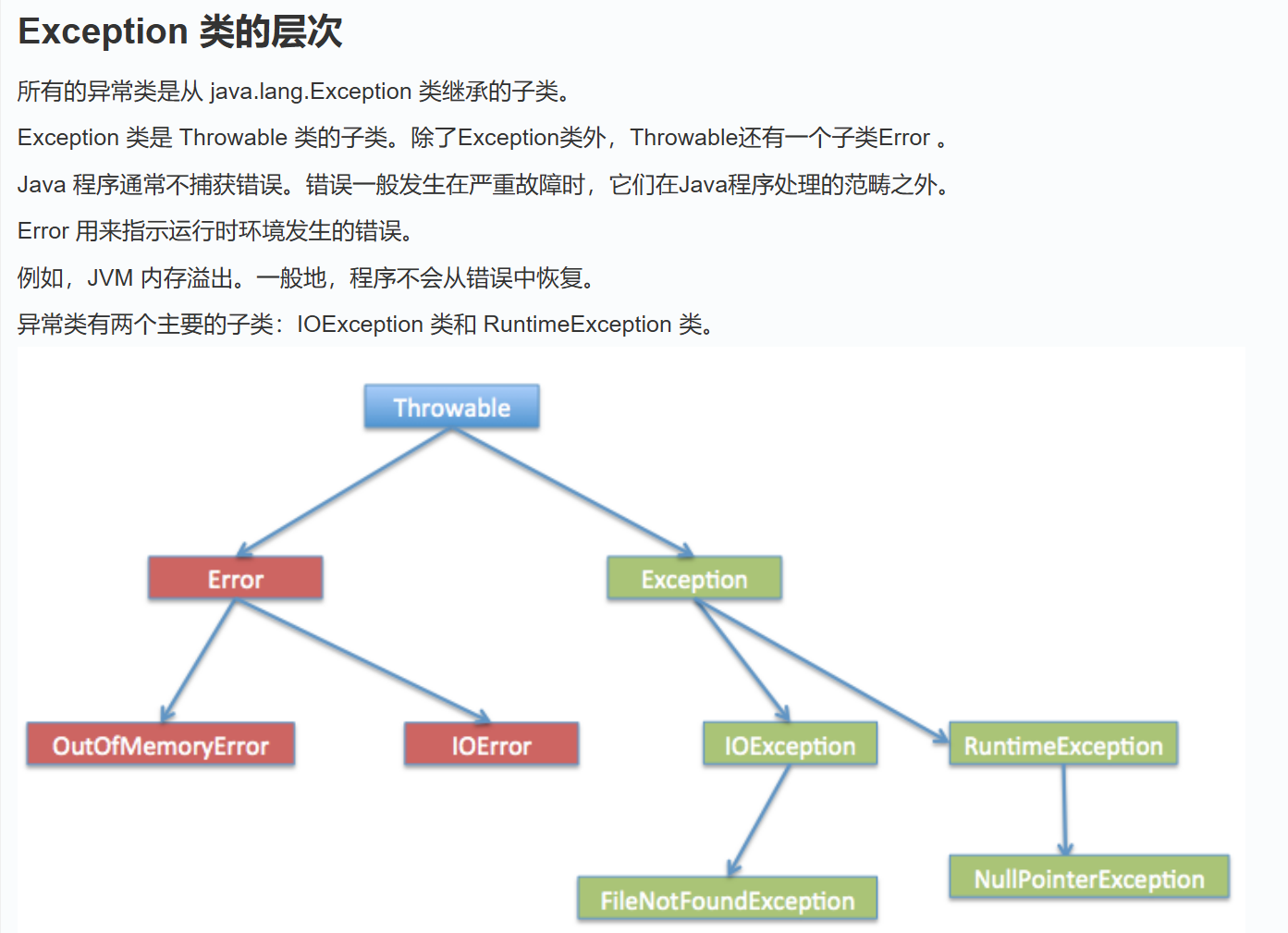
直接看菜鸟就可以了,这里只讲一些注意点:
异常类型:
- 编译时异常,比如我们写代码的时候就会让我们处理的异常
- 运行时异常,就是我们运行起来才知道会出的异常。例如 NullPointerException、ArrayIndexOutOfBoundsException 等,这类异常可以选择处理,但并非强制要求。
Java 提供了以下关键字和类来支持异常处理:
- try:用于包裹可能会抛出异常的代码块。
- catch:用于捕获异常并处理异常的代码块。
- finally:用于包含无论是否发生异常都需要执行的代码块。
- throw:用于手动抛出异常。
- throws:用于在方法声明中指定方法可能抛出的异常。
- Exception类:是所有异常类的父类,它提供了一些方法来获取异常信息,如 getMessage()、printStackTrace() 等。
处理方案:
可以直接抛出异常用throws关键字,不论是编译异常还是运行期间可能出现的错误,都可以抛给上层方法。当然抛出后,后续代码不会继续运行。比如下面代码只会打印"开始执行"。
public void execute() throws InterruptedException {
log.info("开始执行");
Thread.sleep(1000*60*2);
log.info("继续执行");
}而用try-catch-fianlly处理的后续代码就会执行,就是try中抛出异常,那就会跑到catch中继续运行代码。
上面的两种都是被动执行过程中的异常,但是如果try-catch中主动throw异常,哪里会执行呢?
详细:Java抛出异常后,后续代码是否还会执行?_java抛出异常后会不会执行程序-优快云博客
有 try-catch 语句块,并且 throw 在 catch 语句块里,那么 try 语句块中引发异常(报错)的那一行代码的后续代码都不执行并且 catch 语句块后的代码也都不执行(遇到 finally 除外)。
比如:我们这里假如其他线程调用了执行该方法线程的interrupt方法给该方法设置了终止标志,当执行到sleep方法后就会看到这个终止标志,将标志清楚并抛出InterruptedException异常,之后进入到catch方法,之后将这个异常抛出,如果有finally还会执行下finally,之后方法运行结束,我们这个方法接收到异常后继续throws,抛给上一层。所以看到我们这里抛出一个异常就可以终止整个方法了,之后这个异常抛给谁无所谓,反正这里停止了。
@XxlJob("demoJobHandler")
public ReturnT<String> demoJobHandler(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
try {
XxlJobLogger.log("beat at:" + i);
System.out.println("第"+i+"次");
TimeUnit.SECONDS.sleep(3);
}catch (Exception e){
if (e instanceof InterruptedException){
throw e;
}
}
}
return ReturnT.SUCCESS;
}
通用技巧【算法 架构 设计】
算法:
取数字哪几位:
//a%(10的n次) --> 取a数字的最后n位
//a/(10的n次) --> 砍掉a数字的最后n位
//eg. 1234 得到2 1234/100%10 得到23 1234/10%100查找:二分法 (l+r)/2 --> 防止加法溢出 (r-l)>>1+l
保留思想:移除元素可以用此思想归并排序的思想:merge
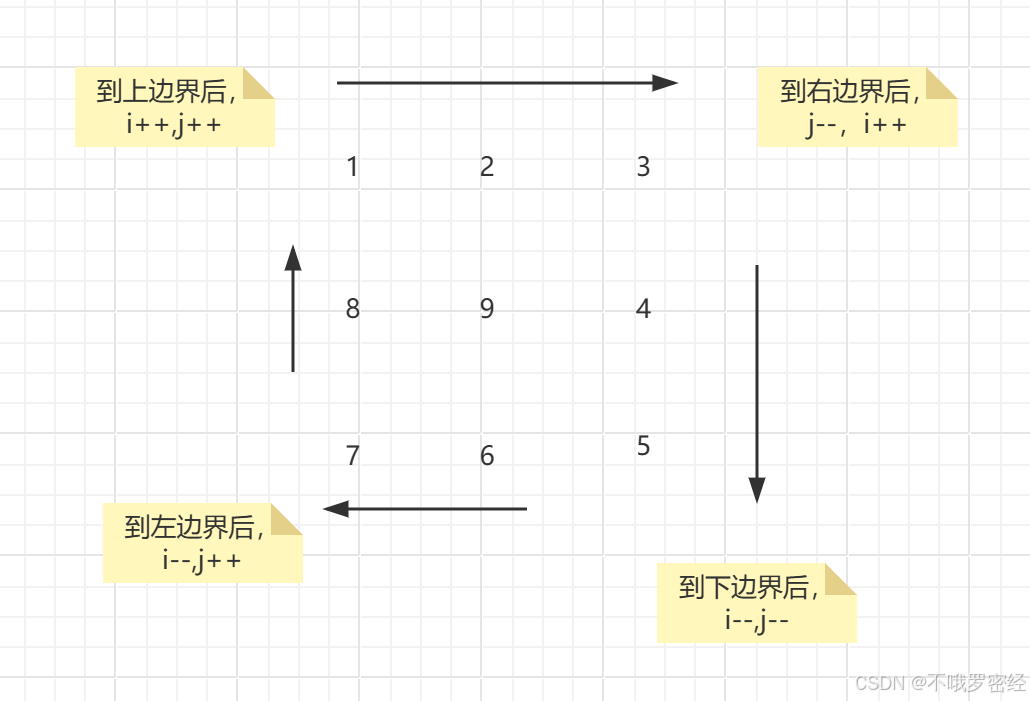
数组模拟:例题螺旋矩阵,一定要先确定好遍历边界!
前缀和:求区间和
KMP算法:详细看KMP算法详解:字符串匹配的高效优化,-优快云博客
暴力匹配:i指向文本串 j指向模版串 i和j一旦不相等,j退回0,i退回到下一位
优化思想:i一直往前走 一旦不匹配,模版串移动j移动到匹配的位置,让文本串原本当尾的部分当头
怎么移动?--> 用next数组
怎么构建?--> i指向后缀的尾部,j指向前缀的尾部;同样的,i要一直往前走,j要移动到与i匹配的地方滑动窗口:
1.窗口长度不固定 --> 最大窗口最小窗口
本质就是确定好窗口的尾位置,然后调整首位置 ,保证尾位置加进来一定合法2.窗口长度固定:--> 获得窗口的最大或最小值 --> 单调队列
注意单调队列和优先级队列是不一样的
单调队列是一种特殊的队列,它具有单调性质。通常,单调队列维护一个递增或递减的顺序,以便在常数时间内获取队列中的最大或最小元素。
而优先队列是用堆实现的,照优先级排序元素的队列。它的特点是每次取出队列中优先级最高的元素,并且可以支持动态插入和删除操作。优先队列就是PriorityQueue
而单调队列是要自己实现的一种数据结构,大体机构如下,不同题目实现不同
class MyQueue {
public void poll(int value) {
}
public void add(int value) {
}
public int peek() {
return que.peek();
}
};区别:
时间复杂度:单调队列和优先队列的时间复杂度在不同的操作上有所差异。对于单调队列来说,插入和删除操作的时间复杂度通常为O(1),获取最大或最小元素的时间复杂度为O(1)。而优先队列使用堆实现,插入和删除操作的时间复杂度为O(log n),获取最高优先级元素的时间复杂度为O(1)。
功能:
单调队列主要用于获取滑动窗口中的最大或最小元素,而优先队列则用于按照优先级处理元素,可以灵活地定义不同的优先级规则。递归:
方法论:
1.确定方法参数和返回值
2.确定终止条件
3.确定单层逻辑
本质就是用栈来操作,所以如果用迭代来实现递归可以使用栈结构
二叉树:(新的数据结构)
分类:满二叉树 完全二叉树 二叉搜索树 平衡二叉搜索树
遍历:前中后序遍历 层序遍历 --> 实现:递归,迭代
(迭代实现前中后序,使用栈结构,注意两个方面1.访问节点顺序 2.处理节点顺序
如果两者一致如前序遍历,那代码就会简洁,但是如果两者不一致,则需要指针来辅助完成访问,使访问顺序和处理顺序保持一致)
对于所有二叉树问题
1.确定遍历顺序
2.用递归3部曲
树的深度和高度二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数或者节点数(取决于深度从0开始还是从1开始)
二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数或者节点数(取决于高度从0开始还是从1开始)
什么是叶子节点,左右孩子都为空的节点才是叶子节点
二叉搜索树的验证:中序遍历为严格递增序列 或者 在中序遍历时就判断出是否后一个大于前一个
寻找最近公共祖先(普通二叉树,二叉搜索树)
普通二叉树:找到两个节点后回溯(从下到上),回溯时遇到的第一个左树存在p,右树存在q的节点,就是p,q最近公共祖先(要遍历全树,因为要根据左树和右树来判断结果)
二叉搜索树:
方法一:可以和普通二叉树一样寻找
方法二:利用二叉搜索树的性质,我们可以发现,我们从上向下去递归遍历,第一次遇到 cur节点是数值在[q, p]区间中,那么cur就是 q和p的最近公共祖先。(反证)
二叉搜索树的插入和删除
插入是不会改变树结构的,找到对应位置插入即可;删除节点则会改变结构
对于删除节点不同,要考虑多种情况:(ps:无需写虚节点,因为返回的话直接返回左或右树即可)
- 删除的节点左右节点均为null,直接返回null(返回给上层的节点是什么)
- 删除的节点左/右为null且右/左不为null,返回非null树
- 删除的节点的左,右节点均不为null,将左树插入右树的左树的最左边,返回右节点
删除不在某区间的节点们:
若 root.val 小于边界值 low,则 root 的左子树必然均小于边界值,我们递归处理 root.right 即可;
若 root.val 大于边界值 high,则 root 的右子树必然均大于边界值,我们递归处理 root.left 即可;
若 root.val 符合要求,则 root 可被保留,递归处理其左右节点并重新赋值即可。
问题由上一个问题可以得到 推理时都要想到
dp动态规划:
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
积累:
1.关于兔子繁殖问题
斐波那契数列: super家养了一对刚出生的兔子, 兔子出生第4月开始每月都会生一对小兔子, 小兔子出 生后同样第4月开始也会每月生一对兔子 super想知道 如果兔子不死 n月后家里会有多少对兔子
dp[i] 为第i月有多少对兔子
dp[i]=dp[i-1]+dp[i-3] 当月兔子为上个月兔子以及本月要繁殖多少只兔子,本月要繁殖的兔子就是上上个月的兔子数。
2.数字拆分
给定一个正整数
n,将其拆分为k个 正整数 的和(k >= 2),并使这些整数的乘积最大化。返回 你可以获得的最大乘积 。
dp[i]:分拆数字i,可以得到的最大乘积为dp[i]。
dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
3.背包问题
01背包:dp[i][j] 从[0-i]物品中选择,放到容量为j的背包中,价值最大为多少
dp[i][j]=max(dp[i-1][j],dp[i-1][j-w[i]]+v[i]) 选择物品i,不选物品i
先遍历物品或者背包都可以 根据左上方更新数据
bfs 【广度优先搜索 】
1.探索方向 四个方向int[][] dir={ {-1,0},{0,-1},{1,0},{0,1}}; 上下左右
2.标志已经探索过 boolean[][] visted=boolean[n][n];
3.不可以加入->地图边界 访问过 不能走
dfs(回溯) 【递归搜索树 把所有情况都列举一遍找到合法的】
回溯法解决的问题都可以抽象为树形结构
集合的大小就构成了树的宽度,递归的深度就构成了树的深度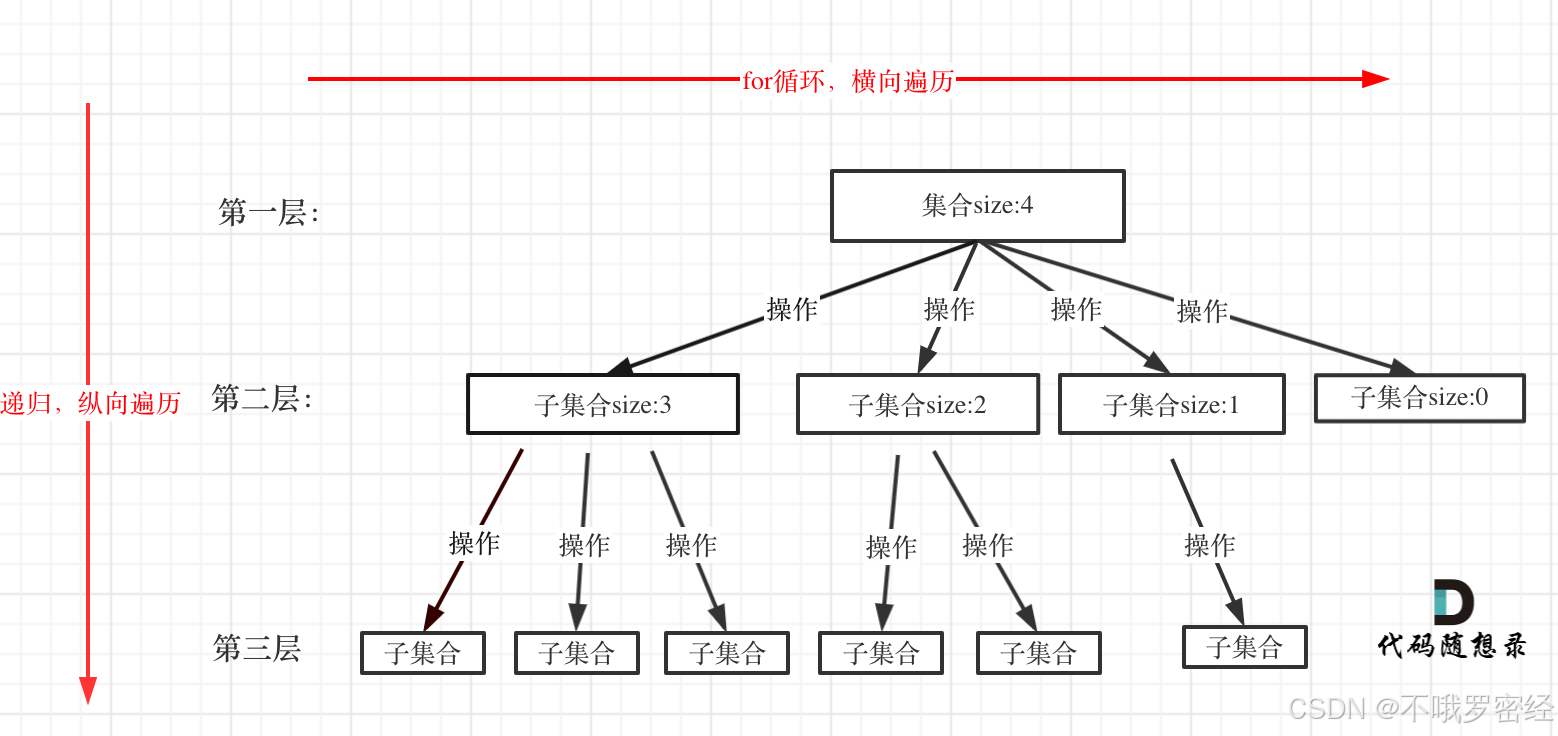
回溯三步曲:1.确定传入参数和返回类型 2.终止条件 3.单层逻辑
void backtracking(参数) { if (终止条件) { 存放结果; return; } for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) { 处理节点; backtracking(路径,选择列表); // 递归 回溯,撤销处理结果 } }回溯的经典剪枝
1.位数为k,可选数从1到n,但是可选数字不够了;i<=n-(k-path.size())+1
此数字开头后面的位数 n-i+1 >= 还需要写的位置 k-path.size()
2.总和超过了要的和targetsum,需要再加一个sum,在开头判断if(sum>n){return;}或者我们传入的额targetsum做减法每写一个都减去一个i,然后判断这个targetsum是不是<0也是同理
题型:
- 组合问题
回溯的树枝去重和树层去重
对于组合问题来说,有两种使用过,如上,要区分好
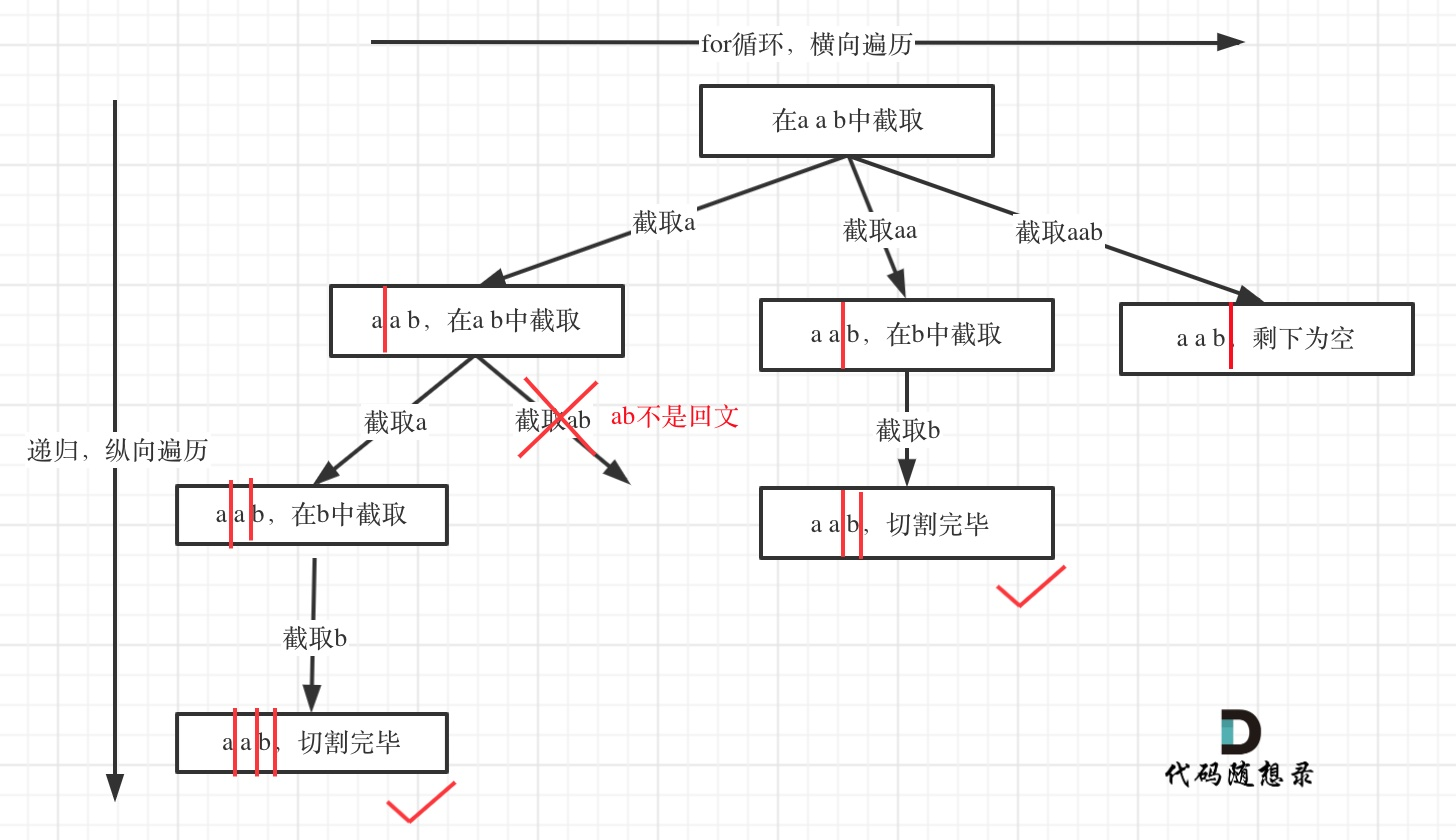
- 分割
列出如下几个难点:
- 切割问题可以抽象为组合问题
组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中再选取第三个.....。
切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中再切割第三段.....。- 子集
- 排列
- 棋盘
架构:
有两个计划表 1.项目计划表 2.项目开发任务表
项目流程:
1.立项【开会前通知大家花两天时间填写立项建议表,第二天晚上开会确定立项且安排可行性分析】
2.可行性分析【这里只分析技术上的可行性,包含1.核心功能2.数据结构3.核心功能实现逻辑 花费1天时间来完成 晚上开会定档并讨论所有功能安排需求文档】
3.项目设计阶段:需求文档 功能流程图 产品原型图
需求文档:【花费1天时间 当晚定档讨论具体细节问题 确定每个人都了解项目具体功能(抽查保证) 再安排功能流程图】
功能流程图:【花费两天时间 第二天晚上定档流程图 确定每个人知道流程是什么样的 安排产品原型图(美)和架构】
4.架构:【花费三天时间 第三天晚上确定架构 】
架构要写清晰!(用什么数据上层什么函数都写清晰!按他们不懂流程来写)
1.分层 dao service view utils pojo...(上层可以用下层的函数数据,下层不可以用上层的东西)
2.设计view层
根据需求文档和功能流程图,将view层设计好 调用service层什么方法...
2.设计service层
view用到的方法要实现,调用dao层,返回给view层数据
3.设计dao层
5.分工【编写代码 在答辩前写完】
填写项目开发任务表
设计:
工具类的编写思路
- 将构造方法私有化 将方法设计为静态方法
- 有些属性的初始化可以放到静态代码块中执行
java用法【我不熟练的】
1.Lambda表达式
Lambda 表达式的语法由以下几个部分组成:
- 参数列表,括在圆括号中(如果只有一个参数可以省略)。
- 箭头符号
->。 - 方法体,可以是一个单独的表达式或一个语句块。
(parameters) -> expression使用:
1.可以用Lambda表达式来定义函数式接口,比如比较器接口
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
Collections.sort(names, (a, b) -> a.compareTo(b)); // 按升序排序2. 与集合一起使用
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.forEach(name -> System.out.println(name));
//name就是List的元素,就是泛型里的内容在定义比较器时,为什么lambda表达式没有实现comparator接口就行?
因为comparator一个函数式接口,标注了@FunctionalInterface,是一个只有一个抽象方法的接口,编译器发现只有一个抽象方法,会生成一个实现了那个抽象方法的comparator实现类。那个抽象方法就是lambda表达式。
ps:comparator接口的静态方法和default方法不用实现,还有个boolean equals(Object obj);是来自继承的object的。详细:来自AI
编译器如何处理 Lambda 表达式
在 Java 中,当你使用 Lambda 表达式创建一个方法时,编译器会根据上下文推断出这个 Lambda 表达式应该实现哪个接口。在你的例子中,总结如下:
上下文推断:当你调用
Collections.sort(people, (p1, p2) -> Integer.compare(p1.age, p2.age));时,Collections.sort()方法接受一个Comparator类型的参数。编译器看到这个参数,便知道你要提供一个Comparator实例。函数式接口:由于
Comparator是一个函数式接口(即只有一个抽象方法),所以编译器可以将 Lambda 表达式(p1, p2) -> Integer.compare(p1.age, p2.age)视为Comparator的实现。生成的字节码:最后,编译器会生成相应的字节码,来替代这个 Lambda 表达式,而在运行时会用匿名类的方式完成的,与传统实现的
Comparator类的效果是一样的。简单示例
为了更好地理解,可以想象一下,Lambda 表达式
(p1, p2) -> Integer.compare(p1.age, p2.age)本质上是隐式地被编译成一个实现了Comparator<Person>接口的匿名内部类,类似于:Collections.sort(people, new Comparator<Person>() { @Override public int compare(Person p1, Person p2) { return Integer.compare(p1.age, p2.age); } });尽管我们在使用 Lambda 时看起来代码更加简洁,但在编译后,Java 实际上创建了一个匿名类来完成实际的工作。
所以:
总结来说,编译器能理解你使用 Lambda 表达式是在实现一个函数式接口(如
Comparator),这使得代码更加简洁、易读,而不需要显式地创建一个实现类。
2.比较器 Comparator
Comparator 接口中要实现的抽象方法
compare(T o1, T o2):比较两个对象,并返回一个整数:
- 如果返回负值,表示
o1小于o2。 - 如果返回零,表示
o1等于o2。 - 如果返回正值,表示
o1大于o2。那o1就会在o2后面,所以要倒序的话就o2-o1就好了
import java.util.*;
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name + ": " + age;
}
}
public class Main {
public static void main(String[] args) {
List<Person> people = new ArrayList<>();
people.add(new Person("Alice", 24));
people.add(new Person("Bob", 30));
people.add(new Person("Charlie", 20));
// 使用 Comparator 按年龄排序
Comparator<Person> ageComparator = new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return Integer.compare(p1.age, p2.age);
}
};
// 也可以用 Lambda 表达式定义 Comparator
Comparator<Person> ageComparatorLambda = (p1, p2) -> Integer.compare(p1.age, p2.age);
// 排序并打印
Collections.sort(people, ageComparatorLambda);
people.forEach(System.out::println);
}
}3.io流【掌握】
文件:File file=new File("1.txt"); file.createNewFile();//会创建在user.dir(当前项目路径)下面
- io流读取文件是在user.dir也就是当前项目路径下找到的,而不是classpath下文件。(System.getProperty("user.dir");
- ClassLoader是从classpath下找的,其中resources会直接放到target/classes下,不用加前面的路径。
io流是用来处理文件读写的,在创建流时,传入一个文件名【也就是文件的地址了】或者文件地址,其成员path会指向这个地址,这样这个流就有了可以对这个文件读或写的能力。
【输入in 输出out的主体是内存,输入是指输入到内存,也就是读;输出是内存输出,也就是写】
io流体系图:基于四个父类派生出来的
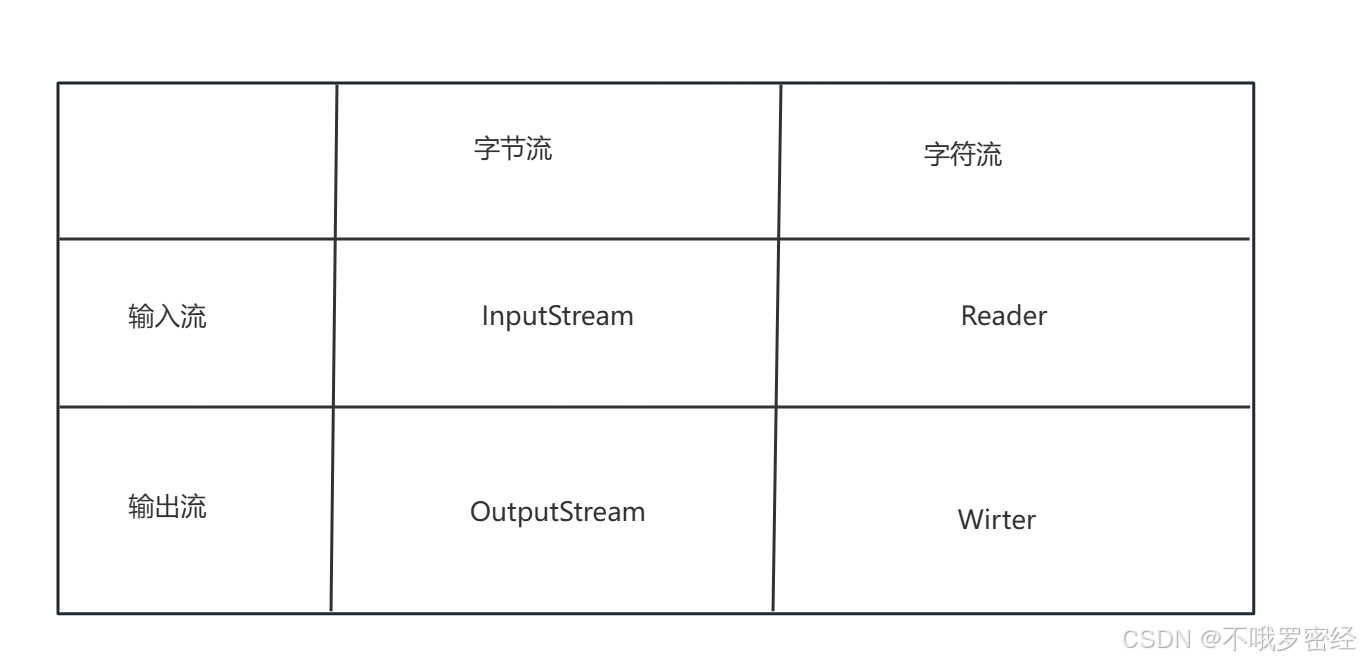
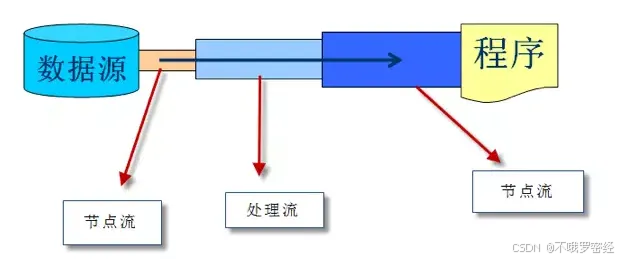
按照处理对象不同也可以分为:
节点流(普通流):可以直接从数据源或目的地读写数据。
处理流(包装流):不直接连接到数据源或目的地,是“处理流的流”。通过对其它流进行封装,目的主要是简化操作和提高程序的性能。
节点流处于IO操作的第一线,所有操作必须通过他们进行;处理流可以对节点流进行包装,提高性能或提高程序的灵活性。
1.定义
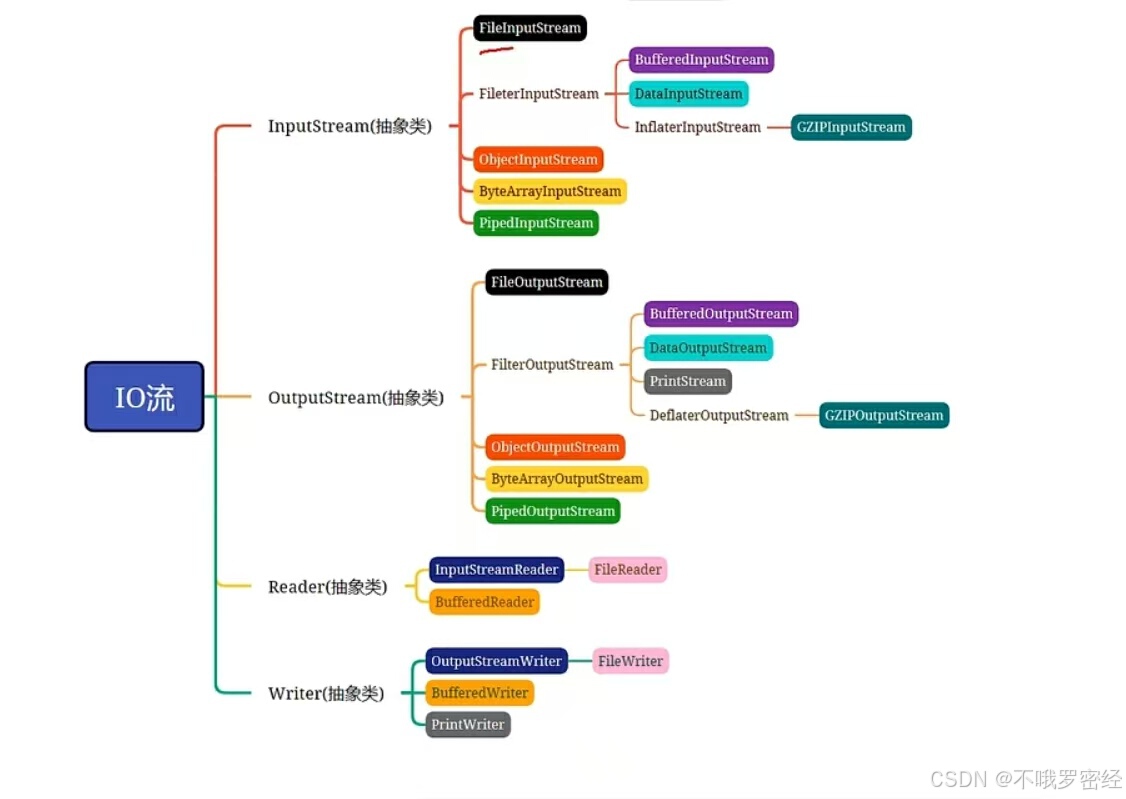
四大头领:
InputStream
OutputStream
Reader
Writer
File相关的:
FileInputStream
FileOutputStream
FileReader
FileWriter
缓冲流相关的:
BufferedInputStream
BufferedOutputStream
BufferedReader
BufferedWriter
转换流相关的:
InputStreamReader
OutputStreamWriter
打印流相关的:
PrintStream
PrintWriter
对象相关的:
ObjectInputStream
ObjectOutputStream
数据类型的:
DataInputStream
DataOutputStream
字节数组相关的:
ByteArrayInputStream
ByteArrayOutputStream
压缩和解压缩相关的:
GZIPInputStream
GZIPOutputStream
线程相关的:
PipedInputStream
PipedOutputStream
2.方法:
通用:每个流在用之后一定要关!!!try-catch-finally(关闭之前判空处理)
所有的输出流,都有flush方法,此方法就是把管道中的数据全部写到对应对象中。在最后一次写时进行flush就可以,之前写的时候会将数据往前推,写到对应对象中。
字节流:
字节:8bit 在文件中一个字母占1个字节,文字占3/4个字节
OutputStream(抽象类):
- write(int b) 用ascii码写一个字符
- write(byte[] b) 将多个ascii码存在数组中,转为String写到对象中
- write(byte[] b,int off,int len)
FileOutputStream:实现上述方法(节点流)
构造方法FileOutputStream(String path,是否续写); FileOutputStream(FIle file,是否续 写);
是否续写不填,默认为false,第一次写的时候会先清空之前内容。BufferedOutputStream:实现上述方法(包装流)
构造方法BufferedOutputStream(OutputStream out) out要传入一个字节流,对其进行 包装。
InputSteam(抽象类):
- int read(): 读取一个字节的数据。读取成功,则返回读取的字节对应的正整数(即Ascii码),将其转char即可;读取失败,则返回-1。
- int read(byte[]): 读取一定量的字节数,并存储到字节数组中。数组的每一位是把字节转成了数字(即Ascii码)将其转为String即可,读取成功,则返回读取的字节的个数;读取失败,则返回-1。(容易乱码,把汉字读一半)
FileInputStream:实现上述方法
构造方法FileInputStream(String path); FileInputStream(FIle file);BufferedInputStream:实现上述方法
构造方法BufferedInputStream(InputStream in) in要传入一个字节流,对其进行包装
字符流:
Writer(抽象类) :
- write(int b) 用ascii码写一个字符
- write(char[] b) / write(String s)
- write(char[] b,int off,int len) / write(String s,int off,int len)
FileWriter:实现上述方法
构造方法与FileOutputStream是一致的FileWriter类用于向文件中读取数据,并且每次操作的数据单元为“字符”,属于向文本 文件读取字符数据的便捷类。
BufferedWriter:实现上述方法,新增newLine方法 添加换行符
构造方法BufferedWirter(Writer out)
Reader(抽象类):
read(): 读取单个字符并返回。读取成功,则返回字符对应的正整数,读取失败,则返回-1。
read(char[]): 将数据读取到字符数组中。读取成功,则返回读取字符的个数,读取失败,则返回-1
FileReader:实现上述方法
BufferedReader:实现上述方法
新增readLine方法 读取成功,则返回读取的一行文本内容;读取失败,则返回null。
构造方法BufferedReader(Reader in)

对象流 ... 【待补充】
4.输入
Scanner scanner=new Scanner(System.in);//定义一个scanner System.in为键盘输入
scanner.next();//键盘输入的字符串
scanner.nextInt();键盘输入的整数
5.线程【重点】
【概念 定义 生命周期(Thread.sleep() t.join() 线程安全... ) 线程通信】
概念
打开一个java程序,开启一个jvm进程。
那进程是什么呢?
进程是程序的一次执行过程,是系统运行程序的基本单位,是操作系统分配资源的最小单位. 一个进程会有一个主线程。
在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程
线程是一个比进程更小的执行单位, 一个进程在其执行的过程中可以 产生多个线程
(将进程再细化成线程原因是进程间变量是不共享的,我们获取另一个进程的数据需要切换上下文,很耗费时间)
- 线程共享进程的堆和方法区资源
- 每个线程有自己的程序计数器、虚拟机栈和本地方法栈
- 线程切换的代码比进程小得多,线程也被称为轻量级进程
并发和并行
- 并发是一个cpu在不断切换干什么 微观上不是同时进行 宏观上是同时进行的
- 并行 是多个cpu同时在做不同线程 微观和宏观上都是同时进行的
你写的多线程是并发还是并行 都有可能 看cpu情况
线程的调度策略
分时调度模型(所有线程轮流使用cpu的执行权 并且平均的分配每个线程占用的cpu时间)
抢占式调度模型(让优先级高的线程以较大概率得到cpu的执行权,如果优先级一致,就随机选一个线程)
Java采用的是抢占式调度方式,优先级越高的线程,优先使用CPU资源
定义线程
- 继承Thread 重写run方法 创建线程对象 线程对象.start()开启线程
- 实现Runnable接口
重写run方法
创建接口实现对象 MyThread myThread = new MyThread();
创建线程对象Thread thread = new Thread(myThread);
线程对象.start()开启线程- 实现Callable接口和FutureTask
实现Callable接口之后实现call方法,call会返回一个对象
创建接口实现对象NumThread numThread = new NumThread();
将此对象交给FutureTask包装FutureTask<Integer> futureTask = new FutureTask<>(numThread);
再把FutureTask交给Thread之后运行new Thread(futureTask).start();底层是用FutureTask的run方法,而该run方法用的又是call方法
在main线程中可以调用Integer sum = futureTask.get();获得call方法返回的对象,此方法会造成main线程阻塞,直到这个get()方法返回结果。我们也可以设置超时等待,get(long timeout, TimeUnit unit)。该方法会阻塞main线程,直到计算完成,或者超时抛出TimeoutException。当然这个不会让futuretask这个线程终止,只是单纯的停止调用线程的阻塞而已。
(调用futureTask.get()的线程和执行futureTask.run()的线程共享的是 同一个 FutureTask 对象实例,锁的就是这个对象,当我们有多个线程,其中一个线程执行FutureTask的run方法(或者callable的call方法),其他线程调用FutureTask的get方法时,这些线程实际上是在竞争同一个FutureTask实例的对象锁。)
这个方法创建线程的使用上,还有很多要注意的点:
1. FutureTask 会 “吞掉“ 异常:
当我们在运行开启线程start时,运行的是futuretask的run方法,run方法去调用call方法,当收到call方法的运行结果或者异常后会通过try-catch保存。然后get方法此时去拿run方法的存放结果,如果是异常就抛出,不是就正常返回结果。
所以这就会导致,call方法通过throws将异常抛出,那么该异常会被Future所接收到,只有调用Future的get方法才会抛出。也就是说,如果你不调用get方法,这个异常就没有去抛出给上层。简单示例原理:public class FutureTask<V> { private Object outcome; // 存储结果或异常 public void run() { try { V result = callable.call(); set(result); // 存储正常结果 } catch (Throwable ex) { setException(ex); // 存储异常 } } public V get() throws ExecutionException { // 如果存储的是异常,就抛出 if (状态 == 异常) { throw new ExecutionException((Throwable)outcome); } return (V)outcome; } }详细:
FutureTask 会 “吞掉“ 异常是怎么回事?需要注意些什么?_异常被吞了-优快云博客
2.其他
并发编程之FutureTask.get()阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方案_线程阻塞比如 future.get(),会导致cpu飙升吗-优快云博客- 通过线程池创建
核心:
- Java创建线程有且只有一种方式, 就是继承Thread类重写run方法, 调用Thread类的start方法
- 实现Runnable和Callable的还是要把实现类对象传入Thread类中, 调用Thread类的start方法. 所以本质创建线程还是依靠Thread类中的start方法.
- 实现Runnable和Callable实际上是创建了一个线程任务. 然后调用Thread类中的start方法, start方法调用start0方法, start0是一 个本地方法【private native void start0()】, 由C/C++编写, 用来进行系统调用创建新线程, 然后用新线程来执行线程任务.
- 这也说明了为何实现Runnable或者Callable后调用run方法不能开启新线程, 是因为开启新线程本质上需要调用Thread的start0方法.
线程对象.start开启线程-> 这个方法就是开辟一个新栈然后将run方法压入栈底。
直接调用run就是跑run方法而已。
用户线程和守护线程
用户线程就是当前我们创建的都是,守护线程是当用户线程全部结束后,自动结束,如jvm垃圾回收线程。
将用户线程设置为守护线程 myThread.setDaemon(true)
线程生命周期
操作系统中的5大状态
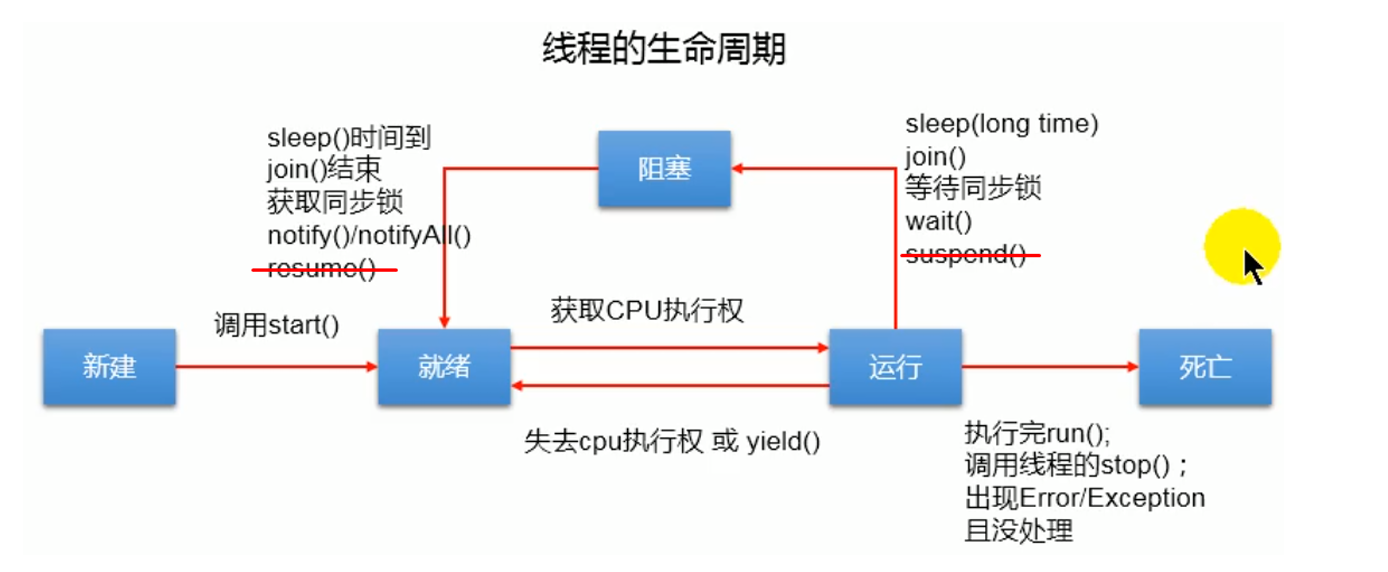
java中Thread.state枚举类定义的6状态
介绍状态
public enum State {
NEW, // 新建
RUNNABLE, // 可运行 对应就绪或者运行状态
BLOCKED, // 阻塞
WAITING, // 等待
TIMED_WAITING, // 限时等待
TERMINATED; // 终止
}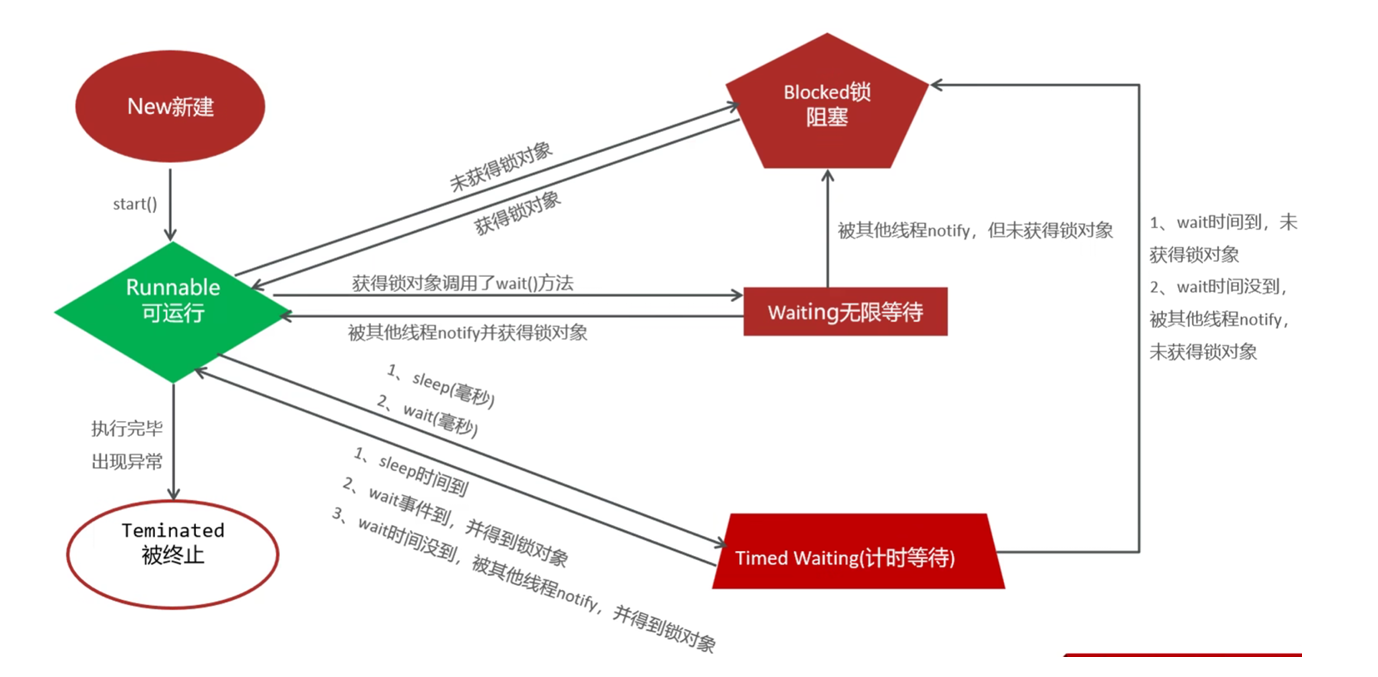
注意: sleep()不会释放锁, 所以sleep()结束后会可以直接进入就绪态 (runnable). wait()会释放锁, 所以wait()结束后要去抢锁, 抢到则进入就绪态(runnable), 没抢到则进入锁阻塞(Blocked).
详细流程
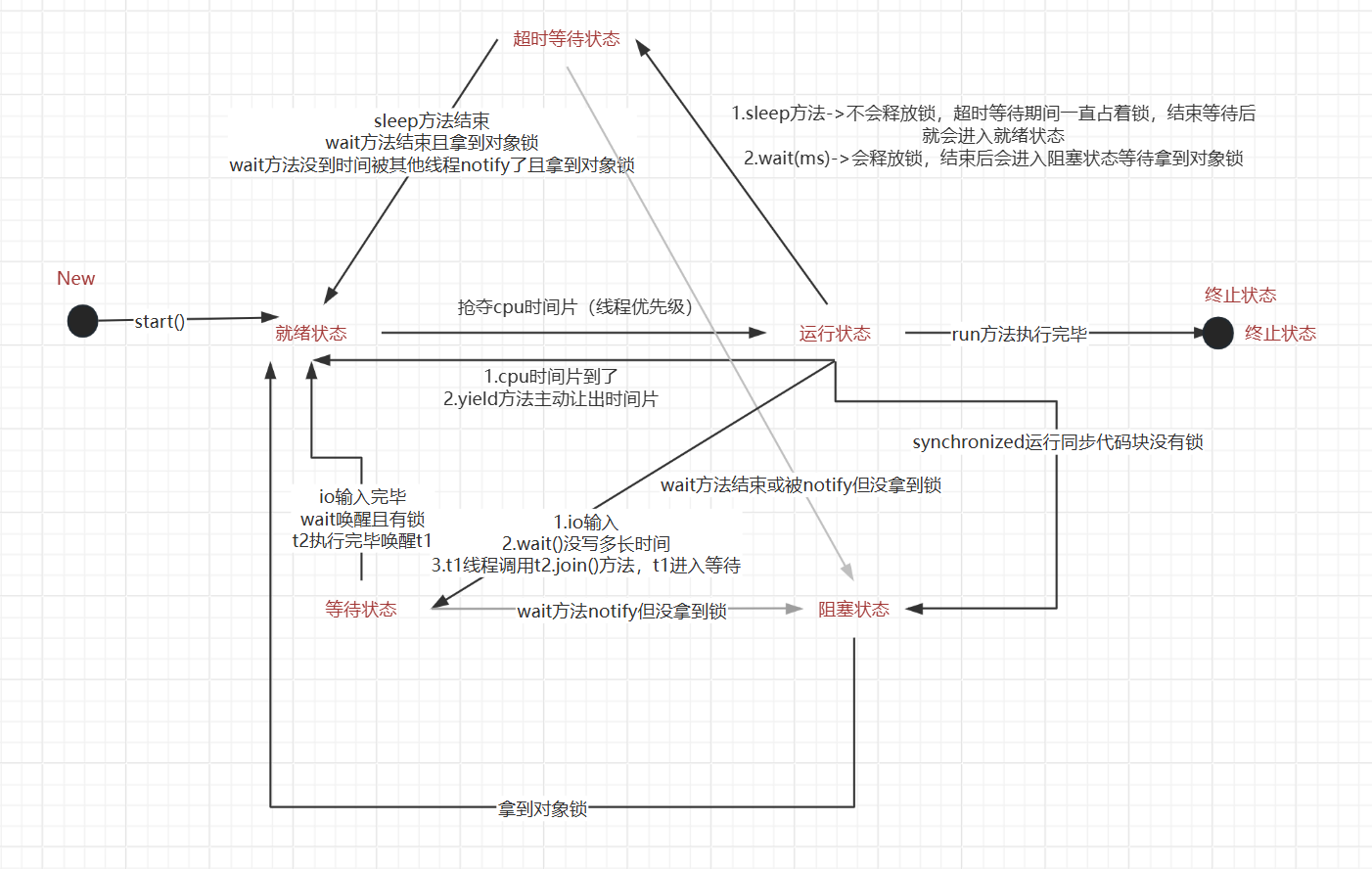
当然不管是超时等待,等待还是阻塞状态,线程都会释放cpu时间片的。
一.在线程准备状态时抢夺cpu使用权
抢夺时,cpu看线程优先级,或者线程主动将自己的时间片让出去。
1.优先级
默认情况下优先级是5,最低是1,最高是10
setPriority //更改线程的优先级;
getPriority //获取线程的优先级;
public class Demo {
public static void main(String[] args) {
System.out.println(Thread.MIN_PRIORITY); //1
System.out.println(Thread.MAX_PRIORITY); //10
System.out.println(Thread.NORM_PRIORITY); //5
Thread.currentThread().setPriority(Thread.MAX_PRIORITY);
int priority = Thread.currentThread().getPriority();
System.out.println(priority); //10
}
}2.yield
静态方法Thread.yield(),当前线程让位,当然也有可能一让位还是这个线程抢到了
public class Demo {
public static void main(String[] args) {
MyThread myThread = new MyThread();
Thread t1 = new Thread(myThread);
Thread t2 = new Thread(myThread);
t1.setName("t1");
t2.setName("t2");
t1.start();
t2.start();
}
}
class MyThread implements Runnable{
public void run() {
for(int i = 1; i <= 100; i++) {
if(Thread.currentThread().getName().equals("t1")&&i%10==0) {
System.out.println(Thread.currentThread().getName()+"让位"+i);
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
二.进入超时等待状态
1.Thread.sleep
Thread.sleep(ms)
注意:这是静态方法,如果用实例来调用,最后执行也会改为Thread.sleep是让当前线程(这个代码出现在哪个线程中,当前线程就是这个线程)睡眠,而不是实例对象的线程。
唤醒线程(实例方法):唤醒的线程.interrupt 本质是抛出异常 打断睡眠
注意这个异常不可以抛出,抛出就到jvm了,main让你抛,这里就不让抛了。
它是给要唤醒的线程设置一个标志,就是要终止的一个标志,只有方法wait、sleep、join会去看这个标志,然后清理标志,之后抛出InterruptedException异常
public class Demo {
public static void main(String[] args) {
MyThread myThread = new MyThread();
Thread thread = new Thread(myThread);
thread.start();
thread.interrupt(); //唤醒thread线程 抛出一个InterruptedException
}
}
class MyThread implements Runnable{
public void run() {
System.out.println(Thread.currentThread().getName()+"start");
try {
Thread.sleep(100*365*24);
} catch (InterruptedException e) { //catch此异常,继续往下执行
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"wake up");
}
}终止线程:打标志 不可以用stop早已弃用
2.wait(ms)方法 -> 在线程通信部分讲解
三.进入等待状态
1.wait()方法-> 在线程通信部分讲解
2.join方法
join方法完成线程合并 是一个实例方法 t.join
main中写 t.join,main方法会让释放cpu时间片进入等待状态,之后cpu时间片由其他线程抢夺,其中就有t线程,等t线程抢到后,全部执行完后会唤醒main线程,之后main线程就进入就绪状态了。
注意:
-
main进入 WAITING 后,CPU 时间片不会"专门"给 t
-
CPU 时间片由操作系统调度器分配给所有 就绪(RUNNABLE) 状态的线程
-
t只是众多竞争CPU的线程之一
也可以加时间,t.join(ms)
t.join(10) 代表t线程合并到当前线程10ms,当前线程会进入超时等待状态10ms,但不一定是这个时间,如果在指定的等待时间中,t线程结束了,其会唤醒当前线程,当前线程进入Runable状态。
public class Demo {
public static void main(String[] args) {
MyThread myThread = new MyThread();
Thread thread = new Thread(myThread);
thread.start();
try{
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName()+" "+i); //2.把main线程的0-9打印
}
}
}
class MyThread implements Runnable{
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName()+" "+i); //1.把线程thread的0-9打印
}
}
}
线程安全
【考虑线程安全:1.多线程环境 2.线程有共享数据 3.共享数据修改】
并发执行的多个线程在某个时间内只允许一个线程在执行并访问共享数据
线程排队 实现同步机制
语法格式
synchronized(必须是这几个线程共享的对象【堆或方法区】) {//同步代码块}
当t1执行同步代码块时,会拿到相对的对象锁,当t2相要执行这段同步代码块时,没有相应对象锁,排队等待t1执行完同步代码释放对象锁。
当t1执行同步代码块拿到锁,t2只是执行这个类的普通方法(没加synchronized)不用拿锁哈,直接运行就好。
可以直接加到方法上 同步代码块就是整个方法
如果直接加到实例方法上就是锁这个类实例this(保护实例变量的安全)
如果加到static方法上就是锁这个类(保护静态变量的安全)
1 锁不能为空,即用作锁的对象不能为空,这种错误很容易暴露,一般都能避免;
2 锁应该是final的,此处并非要求用作锁的对象的引用一定要声明为final,而是指一个对象要用作锁的话,其引用不应该存在被修改指向的可能,否则引用指向变了,对象锁也就变了,锁可能会失效。
针对第2点,我们可以将对象锁的引用声明为final以避开问题。除此之外,需要小心的便是,如果使用基本数据类型的封装类型,如Integer、Long等对象做锁时,一定要非常小心,对此类引用的赋值操作,在一些情况下(常量池的因素)其实是一次引用重指向的操作,会引起锁失效
例子:t1,t2两个线程同时取1000元,每次取1元,直到取完
import lombok.Data;
public class Demo {
public static void main(String[] args) throws InterruptedException {
GetMoney getMoney = new GetMoney();
getMoney.setName("t1");
GetMoney getMoney1 = new GetMoney();
getMoney1.setName("t2");
getMoney.start();
getMoney1.start();
}
}
class GetMoney extends Thread {
private static int money=1000;
@Override
public void run() {
while(money>0) {
synchronized (GetMoney.class) {
//双重检验是必要的
if(money>0) {
money--;
System.out.println(Thread.currentThread().getName()+": money left: "+money);
}
}
}
}
}
为什么需要双重检查?
场景模拟:
假设初始
money = 1,两个线程同时运行:时间线: t0: 线程A读取 money=1 到工作内存 → 条件为true t1: 线程B读取 money=1 到工作内存 → 条件为true t2: 线程A获取锁,进入同步块 t3: 线程A检查 money=1 > 0 → 取款,money=0 t4: 线程A释放锁 t5: 线程B获取锁,进入同步块 t6: 线程B检查 money=0 > 0 → 条件为false,不取款 如果没有双重检验,那当线程B得到锁后,由于直接读的money=1进入了循环了,所以直接取走,导致money=-1底层原因就是money是存在线程共享的区域(堆/方法区),t1,t2从这里读完后,会把其放入自己线程私有的区域(栈),这就导致二者的不同步,所以要双重检验更新私有区域的数据,保存数据一致性。
死锁
1.什么是死锁

public class Testt {
public static void main(String[] args) throws InterruptedException {
Object o1 = new Object();
Object o2 = new Object();
Thread t1 = new Thread(() -> {
synchronized (o1){
try {
Thread.sleep(1000);
synchronized (o2){
System.out.println("线程1");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t2 = new Thread(() -> {
synchronized (o2){
try {
Thread.sleep(1000);
synchronized (o1){
System.out.println("线程2");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
t2.start();
}
}线程A和线程B都需要对方的锁,但是又被对方牢牢把握,由于线程被无限期地阻塞,因此程序不可能正常终止。
2.死锁的4个必要条件

3.死锁检测, 预防

(jps是java的一个指令,查看所有运行的java进程,找到当前出现问题的进程,再此输入jstack 进程号,就可以看到该进程下线程的运行情况,其会显示死锁。jconsole就是可视化看java进程和线程的。)

线程通信
方法:wait(),notify(),notifyAll() 为Object方法,通过共享对象调用
使用前提:必须在同步代码块中使用,必须这个共享代码中锁的共享对象调用
obj.wait() ->处在obj对象上活跃的线程进入等待状态,且释放了对象锁,直到调用共享对象的notify方法进行了唤醒,唤醒后拿到时间片会接着上次调用wait()方法的地方继续执行。
obj.notify()是唤醒优先级最高的线程,如果优先级一致随机唤醒一个。
obj.notifyAll()是唤醒所有在共享对象上等待的对象。
注意:Thread.sleep()方法是一直占用对象锁,而obj.wait()方法会释放对象锁。
wait也可以有参数,进入超时等待状态,被唤醒了或者时间到了会自动进入阻塞状态。
例子:t1,t2线程交替取完1000元,每次取一元
public class Demo {
public static void main(String[] args) throws InterruptedException {
GetMoney getMoney = new GetMoney();
getMoney.setName("t1");
GetMoney getMoney1 = new GetMoney();
getMoney1.setName("t2");
getMoney.start();
getMoney1.start();
}
}
class GetMoney extends Thread {
private static int money=100;
private static Object lock = new Object();
@Override
public void run() {
while(money>0) {
synchronized (lock) {
//记得唤醒另一个线程
//此线程执行过程中把唤另一个唤醒了,但是由于此线程仍然占用对象锁,所以即使醒了,也不会往下执行。
lock.notify();
//双重检验是必要的
if(money>0) {
money--;
System.out.println(Thread.currentThread().getName()+": money left: "+money);
}
if(money>0) {
try {
lock.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}else {
break;
}
}
}
}
}
注意:
可以看到我们只有在money在该线程取完后还是大于0的,即下个线程还能取的情况下才等待。如果不进行这层判断,程序不会结束,我们假设以下情况。假设t1和t2交替执行,假设当前money=1。
t1进入同步块,执行notify(此时没有线程在等待,所以这个notify没有作用),然后执行money--,money变为0,打印信息。
然后t1执行wait,释放锁并进入等待状态。
现在t2被唤醒(或者之前就在竞争锁,现在获取到锁),进入同步块,但是while循环条件money>0为false,所以t2退出循环,线程结束。
而t1还在等待,没有线程来唤醒它,所以程序不会结束。因此,问题就是:当最后一个线程执行减操作后,它进入等待,没有其他线程来唤醒它
其他
1.定时器
public class Demo {
public static void main(String[] args) throws InterruptedException {
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("Hello World");
}
},1000,1000);
Thread.sleep(5000);
timer.cancel();
}
}2.并行流
数据很多的时候,如1000万以上,采用多线程分流工作会比多线程快。
public static void main(String[] args) {
int[] arr = new int[]{1, 4, 5, 2, 9, 3, 6, 0};
Arrays.parallelSort(arr); //使用多线程进行并行排序,效率更高
System.out.println(Arrays.toString(arr));
}6.ThreadLocal【掌握】
ThreadLoacl的使用非常简单,就是每个线程都有自己独立的空间放数据。
ThreadLocal<Object> objectThreadLocal = new ThreadLocal<>();
objectThreadLocal.set("hello");
System.out.println(objectThreadLocal.get());在线程中创建的子线程,无法获得父线程工作内存中的变量,我们可以使用InheritableThreadLocal来解决,在InheritableThreadLocal存放的内容,会自动向子线程传递。
InheritableThreadLocal<String> inheritableLocal = new InheritableThreadLocal<>();
inheritableLocal.set("parent value");
new Thread(() -> {
System.out.println(inheritableLocal.get()); // 输出:"parent value"
}).start();底层:
我们开一个线程后,会在堆中创建一个线程对象,之后运行其start()方法会开辟一个新的栈空间。
补充:这两个怎么绑定的呢?JVM在内部会维护一个映射表,将 Java 的 Thread 对象与操作系统线程及其栈空间关联。这种绑定对开发者透明。线程结束时,JVM 会释放其栈空间(操作系统回收内存),而 Thread 对象在堆中会被 GC 回收(如果没有其他引用)。
而每一个线程对象的内部都有一个ThreadLocalMap对象,其会在堆区创建一个ThreadLocalMap,key就是ThreadLocal,value就是Object。
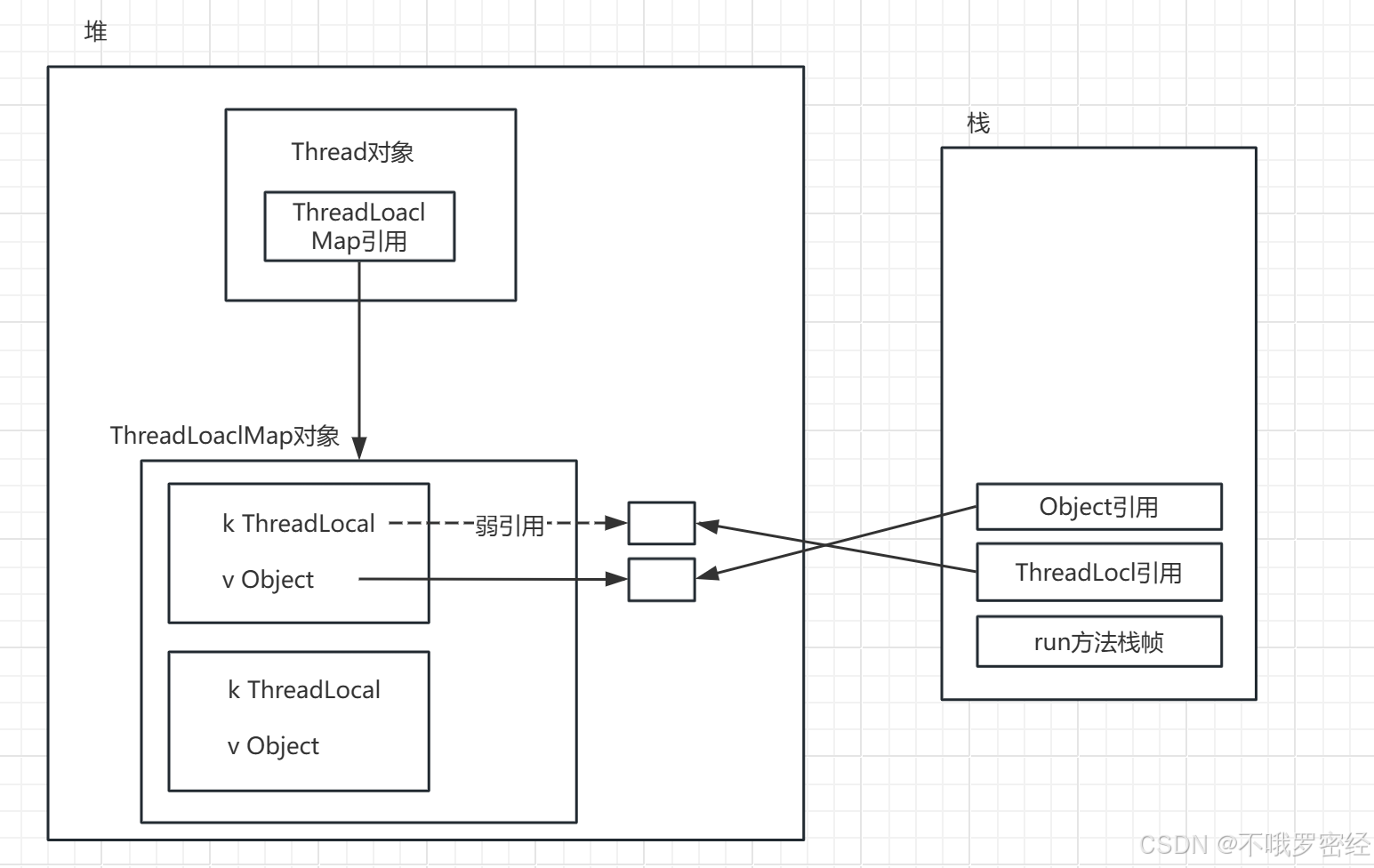
当创建一个ThreadLoacl对象时,会在堆区创建后返回地址,此时这是一个空对象,为null。当我们调用ThreadLoacl对象的set方法时,此对象会为我们set进去的内容。同时,会去找当前的Thread对象创建一个ThreadLoaclMap对象,然后在此map种添加一个Entry,将此Entry的key设为set后的ThreadLoacl对象。【懒加载,防止ThreadLoacl对象为空】
注意这个key引用ThreadLoacl对象是弱引用,即在栈中ThreadLoacl引用出栈,那这个对象就回收了,因为key是弱引用,不强制要求此对象补课回收。而vlaue的Object是强引用,即使栈中的Object引用出栈,此对象也不可回收。
所以我们使用时一定要遵守处理完请求后将vlaue的对象回收,即调用remove()方法
@Component
public class TokenInterceptor implements HandlerInterceptor {
private static final ThreadLocal<UserDTO> userThread = new ThreadLocal<>();
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//TODO 获得用户信息
userThread.set(currentUser);
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
userThread.remove();
}
public static UserDTO getUser() {
return userThread.get();
}
}在拦截器中配置这个ThreadLoacl找的Thread对象就是处理当前http请求的线程,我们提供一个静态方法使其他层都可以得到这个ThreadLoacl对象。
拦截器写好后注意注册哦,在这里注册千万别new TokenInterceptor(),而是用自动装配,如果TokenInterceptor中用到了其他自动装配类,这个TokenInterceptor加上@Component放入spring中了,如果我们new一个新的出来,那TokenInterceptor中的其他自动装配类都是空的。会发生错误。
@Configuration
public class InterceptorConfig implements WebMvcConfigurer {
@Autowired
TokenInterceptor tokenInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(tokenInterceptor)
.addPathPatterns("/**")
.excludePathPatterns(
"/", "/doc.html", "/swagger-resources/**", "/webjars/**",
"/v2/**", "/v3/**", "/swagger-ui.html/**", "/error",
"/login", "/register"); // 排除spring的默认页面和Swagger相关路径
}
}7.网络编程【掌握】
常用网络类:(java.net包下)
InetAddress类:用来封装计算机的ip地址和dns(域名)
常用静态方法:
| public static InetAddress getByName(String host) | 传入目标主机的名字或IP地址得到对应的InetAddress对象,其中封装了IP地址和主机名(或域名) |
| public static InetAddress getLocalHost() | 得到本机的InetAddress对象,其中封装了IP地址和主机名 |
常用实例方法:
| public String getHostAddress() | 获得IP地址 |
| public String getHostName() | 获得主机名 |
URL类:URL由4部分组成:协议、存放资源的主机域名、资源文件名和端口号。如果未指定该端口号,则使用协议默认的端口(可以实现简单爬虫)
URL标准格式为:<协议>://<域名或IP>:<端口>/<路径>。其中,路径后面可以加参数以"?"分割,参数用&分隔
URL url = new URL("http://www.jd.com:8080/java/index.html?name=admin&pwd=123456#tip");
// 获取协议,输出:http
System.out.println("协议:" + url.getProtocol());Socket编程:
socket就是位于应用层和传输层之间的传输工具,首先除应用层外其他网络层会协作找到找连接的pc端,然后建立tcp或者udp连接
如果是tcp连接,会先三次握手,之后客户端开始发数据给服务端,应用层通过socket来传输数据给对应端。
socket实现TCP编程:
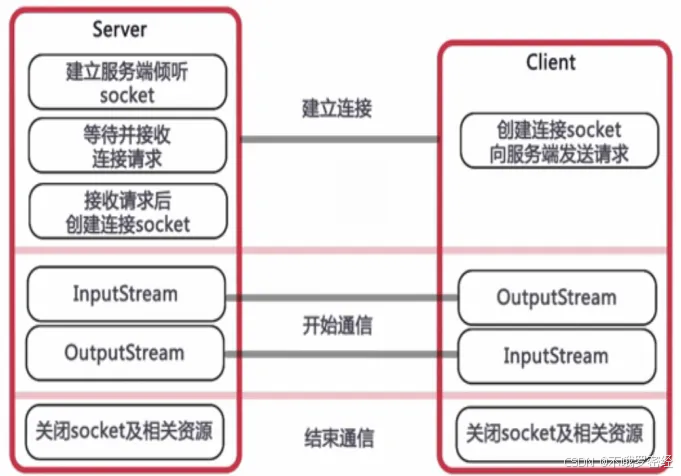
实现服务端:用ServerSocket实现

实现客户端:用Socket实现

应用-实现单向通信:
服务端
public class Test01 {
public static void main(String[] args) {
ServerSocket serverSocket = null;
Socket accept = null;
try {
// 实例化ServerSocket对象(服务端),并明确服务器的端口号
serverSocket = new ServerSocket(8888);
System.out.println("服务端已启动,等待客户端连接..");
// 使用ServerSocket监听客户端的请求
accept = serverSocket.accept();
// 通过输入流来接收客户端发送的数据
InputStreamReader reader = new InputStreamReader(accept.getInputStream());
char[] chars = new char[1024];
int len = -1;
while ((len = reader.read(chars)) != -1) {
System.out.println("接收到客户端信息:" + new String(chars, 0, len));
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭资源
if (accept != null) {
try {
accept.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (serverSocket != null) {
try {
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}客户端
public class Test02 {
public static void main(String[] args) {
Socket socket = null;
try {
// 实例化Socket对象(客户端),并明确连接服务器的IP和端口号
InetAddress inetAddress = InetAddress.getByName("127.0.0.1");
socket = new Socket(inetAddress, 8888);
// 获得该Socket的输出流,用于发送数据
Writer writer = new OutputStreamWriter(socket.getOutputStream());
writer.write("为中华之崛起而读书!");
writer.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭资源
if (socket != null) {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}应用-实现双向通信:
服务端:
public class Test01 {
public static void main(String[] args) {
Socket socket = null;
ServerSocket serverSocket = null;
try {
// 1.创建ServerSocket对象(客户端),并明确端口号
serverSocket = new ServerSocket(8889);
System.out.println("服务端已启动,等待客户端连接..");
// 2.使用ServerSocket监听客户端的请求
socket = serverSocket.accept();
// 3.使用输入流接收客户端发送的图片,然后通过输出流保存图片
InputStream inputStream = socket.getInputStream();
byte[] bytes = new byte[1024];
int len = -1;
FileOutputStream fos = new FileOutputStream("./socket/images/yaya.jpeg");
while ((len = inputStream.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
// 4.给客户端反馈信息
Writer osw = new OutputStreamWriter(socket.getOutputStream());
BufferedWriter bw = new BufferedWriter(osw);
bw.write("图片已经收到,谢谢");
bw.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 5.关闭资源
if (socket != null) {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (serverSocket != null) {
try {
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}客户端:(注意一定要把输出流线关闭,这样服务器才知道图片发完,不会接着read了,结束读循环,发送信息)
public class Test02 {
public static void main(String[] args) {
Socket socket = null;
try {
// 1.实例化Socket对象(客户端),并设置连接服务器的IP和端口号
socket = new Socket(InetAddress.getByName("127.0.0.1"), 8889);
// 2.通过输入流读取图片,然后再通过输出流来发送图片
OutputStream outputStream = socket.getOutputStream();
FileInputStream fis = new FileInputStream("./socket/images/tly.jpeg");
byte[] bytes = new byte[1024];
int len = -1;
while ((len = fis.read(bytes)) != -1) {
outputStream.write(bytes, 0, len);
}
// 注意:此处必须关闭Socket的输出流,来告诉服务器图片发送完毕
socket.shutdownOutput();
// 3.接收服务器的反馈
InputStreamReader isr = new InputStreamReader(socket.getInputStream());
BufferedReader reader = new BufferedReader(isr);
String lineStr = null;
while ((lineStr = reader.readLine()) != null) {
System.out.println("服务器端反馈:" + lineStr);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4.关闭资源
if (socket != null) {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}(1)Socket是最底层的通信机制
(2)HTTP是Socket之上的封装层,例如 HttpClient 等。
(3)Servlet是Java 对 HTTP的封装层,目的是为了更好的处理HTTP请求(包括参数)和HTTP响应,毕竟HTTP就分为请求和响应两大部分。
(4)Tomcat是Servlet容器。Servlet必须运行在容器之上。
servlet虽然可以处理数据和请求,但是数据单线程是,还是要用其他socket技术来实现实时的两者通信。
用servlet当然也可以实现聊天室(尝试做一下,多个用户登录,进入消息发送页面点击提交将ajax请求发送给servlet,将消息存到共享资源中,但是不刷新页面的话收到的就是旧消息,可以用websocket实现同步,当然用前端的轮询方法也可以事项poll() 还有其他技术如sse,在springboot中集成了这个技术)
Java实现简单聊天室【含源码】_java聊天室-优快云博客
8.Properties文件的常用读取方法【掌握】
1.使用InputStream和Properties.load()方法(最常用)
也可以用Reader(io流是从user.dir下读)
Properties props = new Properties();
try (InputStream input = new FileInputStream("config.properties")) {
props.load(input);
} catch (IOException ex) {
ex.printStackTrace();
} 2.使用ClassLoader读取资源
如果资源在类路径下,可以用加载器来读取(加载器读是从target下读)
Properties props = new Properties();
try (InputStream input = YourClass.class.getClassLoader().getResourceAsStream("config.properties")) {
props.load(input);
} catch (IOException ex) {
ex.printStackTrace();
}3.使用ResourceBundle
ResourceBundle是一个更高级的方式,适用于国际化支持并能加载属性文件(从target下找)
ResourceBundle bundle = ResourceBundle.getBundle("config");
String value = bundle.getString("key");9.转义字符
转义字符是以反斜线(\)开头的特殊字符序列,用于表示一些不能直接在字符串中使用的字符。例如,如果你想在字符串中包含一个双引号,你不能直接写",因为这会结束字符串。相反,你需要使用转义字符\"来表示一个字面上的双引号。
String example = "这是一个包含\"双引号\"的字符串";10.Stream API【掌握】
流是为了高效处理数据集合的元素序列, 它不是一种新的数据结构,而是一种可以按需进行处理的元素序列。
Stream API的核心概念包括:
1. 源(Source) :创建Stream的起点,如集合、数组或I/O channel等。
2. 中间操作(Intermediate operations):像filter、map等操作,它们总是返回一个Stream,并且可以串联使用。
它们是惰性执行的,意味着它们不会执行任何处理直到遇到终止操作。
3. 终止操作(Terminal operations):如forEach、collect等操作,用于产生结果或者副作用,它是流的最后一个操作。它们会触发实际的处理过程,并返回最终结果。

具体方法:
前置:
创建不可变集合,一旦创建就不可以修改只可以查询(java 9+)
可以使用方法List.of () ,Set.of () ,Map.of ()
ps:其中Map最多可以有10个键值对,其他多少都行
【原因就是可变参数在一个函数中只能有一个 不支持 public static <K, V> Map<K, V> of(K ...., V ....)】
1.Stream Creation 流的创建

双列集合来获取即Map来得到流,需要通过keySet或者entrySet方法变成单列集合后才可以获得流
代码:
list.stream() set.stream() map.entrySet().stream()
2.中间操作
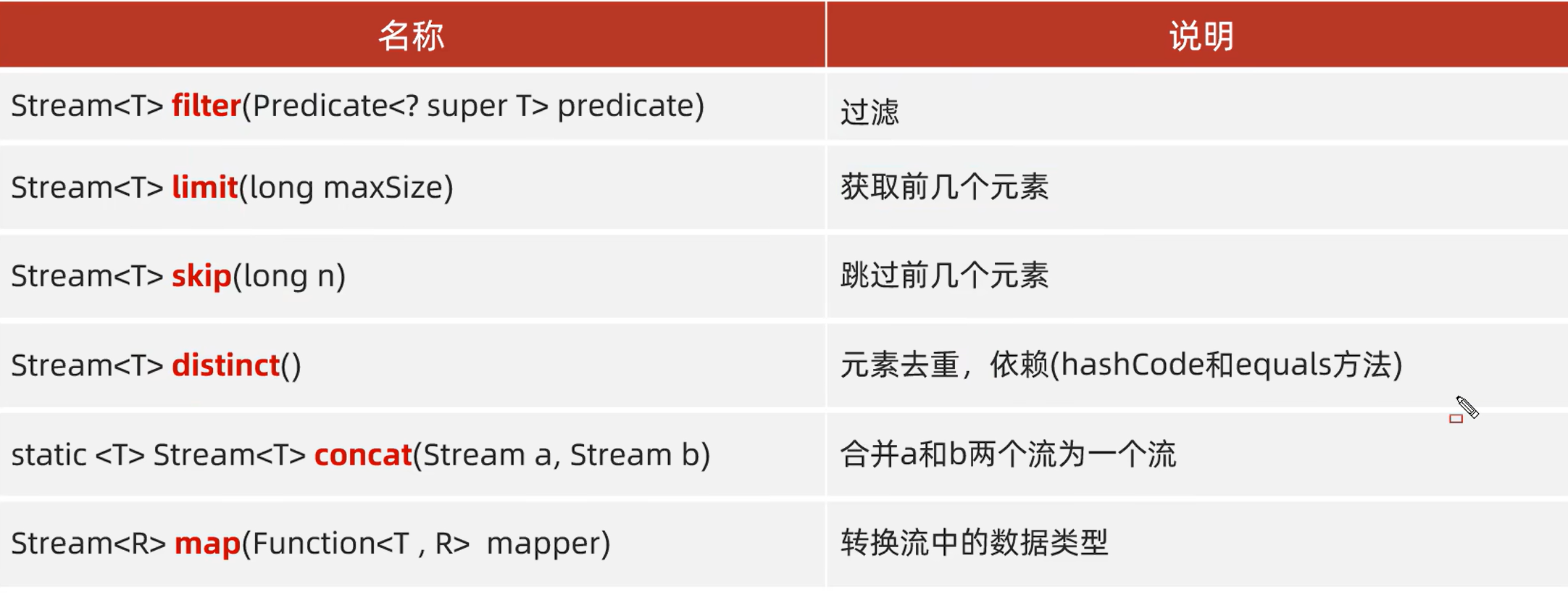
补充:
Stream<T> sorted(Comparator<? super T> comparator) 自定义排序
代码:
1.xxx.stream().filter(o->o.age>18) 遍历每个数据o,然后执行o.age>18为true保留
2.xxx.stream().sorted((o1,o2) -> o2.getAge() - o1.getAge() ) 遍历数据,每次拿两个o1,o2,然后执行o2.getAge() - o1.getAge()如果为0则相等,为负...(就是执行Comparator方法)
3.xxx.stream().map(Function) 这里面需要传入一个方法,我们可以使用方法引用的语法来引入存在的方法或者用Lambda表达式定义一个方法。遍历每个数据,然后执行传入的方法,将数据变为方法执行后返回的值。
xxx.stream().map(String::toUpperCase)
xxx.stream().map(Person::getName) // 使用方法引用提取名字,最后数据为Person的名字集合
xxx.stream().map(n -> n * 2) // 使用 lambda 表达
4.xxx.stream().mapToInt(Function)
xxx.stream().mapToDouble(Function) ...
这种映射会返回IntStream或DoubleStream...更具体的Stream,具体Stream还有一些额外提供方法可以用,比如IntStream可以用sum()等转为此数据类型提供的方法
3.终止操作
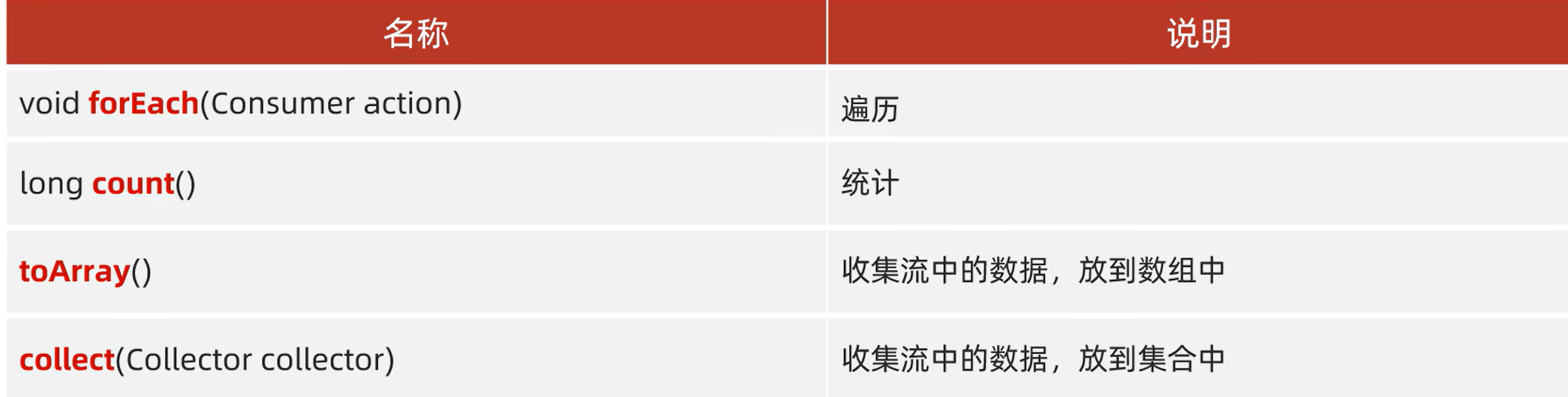
toArray方法
toArray 方法可以生成对象数组,默认是Object[]数组
如果想生成int[]或者doble[]等我们可以结合使用mapToInt或mapToDouble方法来使用
int[] intArray = numbers.stream()
.mapToInt(Integer::intValue) // 将 Integer 转换为 int
.toArray();
为什么用mapToInt后toArray就转成int[]了,而不是Object[]?
原因就是mapToInt会返回IntStream为Stream子类,此时用此流调用toArray方法,其就知道数值类型了,就会转为int
collect方法
其中collect方法为重点,详解:
参数为Collerctor对象
-
Collectors.toList():将流中的元素收集到一个List中。 -
Collectors.toSet():将流中的元素收集到一个Set中。 -
Collectors.toMap():将流中的元素收集Map中。
代码:
1.收集到List或者Set
public class Test {
public static void main(String[] args) {
//创建不可变Map
Map<String, Integer> map = Map.of("apple", 2, "banana", 4, "cherry", 3);
//双列集合先获得单列集合再获得流,之后进行排序(降序),收集到List中(默认ArrayList)
List<Integer> collect = map.values().stream().sorted((o1, o2) -> o2 - o1).collect(Collectors.toList());
System.out.println(collect instanceof ArrayList); // true 放入ArrayList中
//双列集合先获得单列集合再获得流,之后进行排序(升序),收集到Set中(默认HashSet)
Set<Integer> collect1 = map.values().stream().sorted().collect(Collectors.toSet());
System.out.println(collect1);
//如果想指定实现类,可以使用Collectors.toCollection(Class::new)
List<Integer> collect2 = map.values().stream().sorted().collect(Collectors.toCollection(LinkedList::new));
System.out.println(collect2);
System.out.println(collect2 instanceof LinkedList); // true 指定LinkedList
}
}2.收集到Map
public class ToMapExample {
public static void main(String[] args) {
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Charlie", 35)
);
Map<String, Integer> nameToAgeMap = people.stream()
.collect(Collectors.toMap(
Person::getName, // 键:Person 的 name
Person::getAge // 值:Person 的 age
));
System.out.println(nameToAgeMap); // 输出:{Alice=30, Bob=25, Charlie=35}
System.out.println(nameToAgeMap instanceof HashMap); //true 默认使用 HashMap
}但是如果有重复的键,会怎么样呢?
会出现冲突,是因为插入时,会调用key的equals方法,发现有重复的键在,发生冲突,不知道保留哪个。在普通的 Map 操作中(例如直接调用 put 方法),如果键冲突,会直接覆盖旧值,但是这里调用的应该是putVal所以有冲突)
解决方法:指定合并策略,比如保留第一个值
// 但是如果有重复的键,会怎么样呢?
List<Person> people2 = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Charlie", 35),
new Person("Alice", 40)
); // 注意:这里有重复的键 "Alice"
// 这时,如果不指定合并策略,会抛出异常:java.lang.IllegalStateException: Duplicate key: Alice
// 解决方法:指定合并策略,比如保留第一个值
Map<String, Integer> nameToAgeMap2 = people2.stream()
.collect(Collectors.toMap(
Person::getName, // 键:Person 的 name
Person::getAge, // 值:Person 的 age
(e1, e2) -> e1 // 处理冲突:保留第一个值
));
System.out.println(nameToAgeMap2); // 输出:{Alice=30, Bob=25, Charlie=35}除此外,还可以指定实例化的Map类型,默认是HashMap
Map<String, Integer> nameToAgeMap2 = people2.stream()
.collect(Collectors.toMap(
Person::getName, // 键:Person 的 name
Person::getAge, // 值:Person 的 age
(e1, e2) -> e1, // 处理冲突:保留第一个值
TreeMap::new // 指定目标 Map 类型为 TreeMap
));11.泛型
泛型(Generics)是Java引入的一个语言特性,它允许你在定义类、接口和方法时使用类型参数,目的是为了在编译时提供更强的类型检查。
1.泛型类和接口
public class Box<T> {
private T item;
public void set(T item) { this.item = item; }
public T get() { return item; }
} 2.泛型方法
泛型方法是在方法前声明类型变量的,应用于单个方法。
要在方法名前定义泛型
public static <T> void printArray(T[] array) {
for (T element : array) {
System.out.println(element);
}
} ps:
如果你的类或接口已经声明了泛型参数<K, V>,那么在非静态方法里可以直接用K,V,不用再重复声明泛型。但静态方法不能使用类的泛型参数
K,V,因为静态方法属于类,不属于某个具体实例,因此它们看不到类层级的泛型类型参数。
13.序列化反序列化【掌握】
java原生序列化反序列化


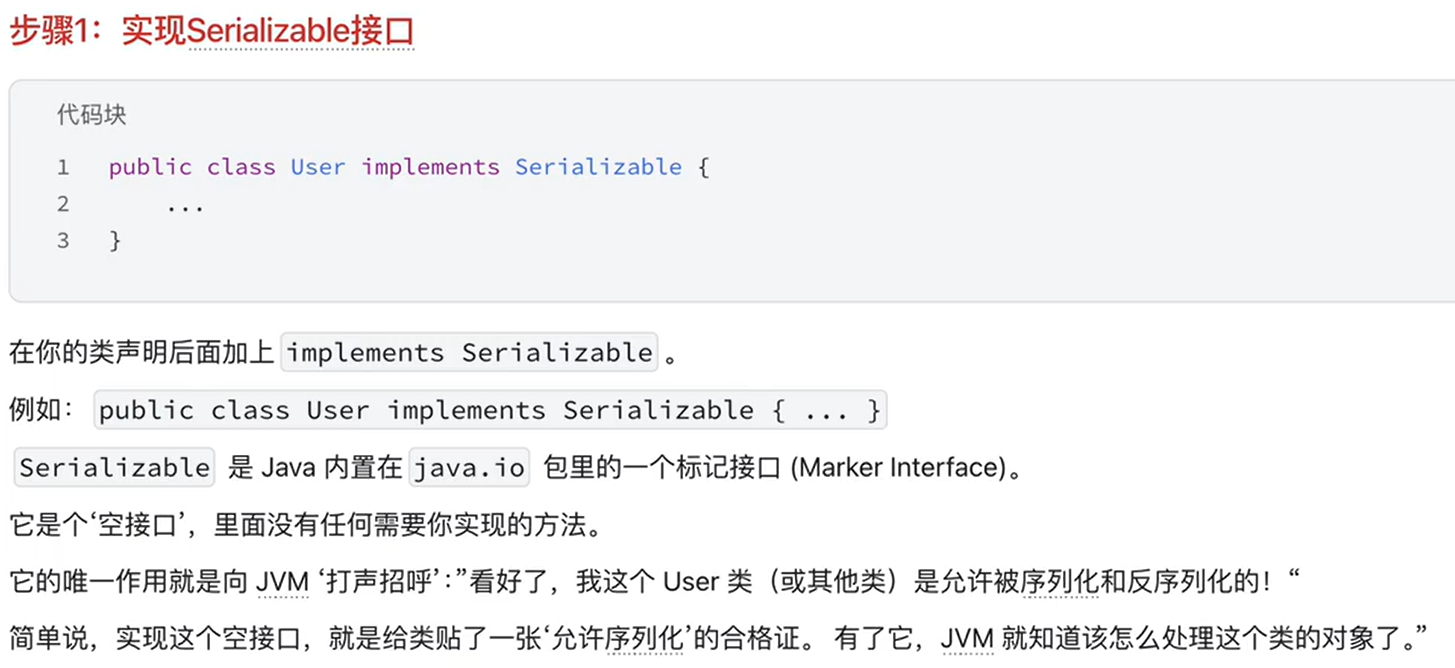
public class Person implements Serializable {
private static final long serialVersionUID = 1L; // 这就是 serialVersionUID
private String name;
private int age;
// ...
}
还有就是里面要写serialVersionUID,来显示声明这个类结构现在的版本号。这是很重要的,如果我们不显示说明这个,那jvm就会自动算一个UID,当此结构的序列化完后,我们之后修改这个类的结构,比如新增了一个属性,jvm又会再算一个UID,之后再反序列化时,jvm会去判断序列化中的字节流文件与现在类的版本是否一致,如果不一致就会报错,不会进行反序列化。而我们显示加上后,就算我们新增属性了也不会再算一个,所以就可以保持版本兼容。
第二步:进行序列化操作
使用 ObjectOutputStream 将对象写入文件(序列化)。
java
import java.io.*;
public class SerializationDemo {
public static void main(String[] args) {
Person person = new Person("Alice", 30);
// 序列化:将对象写入文件
try (FileOutputStream fileOut = new FileOutputStream("person.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut)) {
out.writeObject(person); // 关键方法
System.out.println("对象已序列化并保存到 person.ser");
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后,会在项目根目录生成一个 person.ser 文件,这就是序列化后的字节文件。
第三步:进行反序列化操作
使用 ObjectInputStream 从文件中读取并重建对象(反序列化)。
java
import java.io.*;
public class DeserializationDemo {
public static void main(String[] args) {
// 反序列化:从文件中读取对象
try (FileInputStream fileIn = new FileInputStream("person.ser");
ObjectInputStream in = new ObjectInputStream(fileIn)) {
Person restoredPerson = (Person) in.readObject(); // 关键方法,需要强制类型转换
System.out.println("对象已从 person.ser 反序列化");
System.out.println("反序列化得到的对象: " + restoredPerson);
System.out.println("姓名: " + restoredPerson.getName());
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
运行结果:
对象已从 person.ser 反序列化
反序列化得到的对象: Person{name='Alice', age=30}
姓名: Alice
注意点:

 序列化对继承的影响
序列化对继承的影响
-
如果一个父类实现了
Serializable接口,那么其所有子类默认也都是可序列化的。 -
如果父类没有实现
Serializable接口,而子类实现了,那么:-
序列化子类对象时,父类的字段不会被序列化。
-
在反序列化时,JVM 会调用父类的 无参构造方法 来初始化父类的字段。因此,父类必须有一个可访问的无参构造方法,否则会运行时错误。
-
java对象与json间的序列化和反序列化
使用工具jackson来操作json(springMVC默认的工具->@RestController)
详细使用史上最全的Jackson框架使用教程-优快云博客
以下摘抄自上述文章
1. Jackson 最常用的 API 就是基于"对象绑定" 的 ObjectMapper。
ObjectMapper 通过 writeValue 系列方法将 java 对象序列化为 json,并将 json 存储成不同的格式,String(writeValueAsString),Byte Array(writeValueAsString),Writer, File,OutStream 和 DataOutput。
ObjectMapper 通过 readValue 系列方法从不同的数据源像 String , Byte Array, Reader,File,URL, InputStream 将 json 反序列化为 java 对象。
public class User {
private String name;
private int age;
private Date birthday;
private List<String> hobbies;
// 必须有无参构造方法
public User() {}
// getter/setter 是必须的
public String getName() { return name; }
public void setName(String name) { this.name = name; }
// ... 其他 getter/setter
}
public class JacksonBasicDemo {
public static void main(String[] args) throws Exception {
ObjectMapper mapper = new ObjectMapper();
// 对象 → JSON
User user = new User();
user.setName("张三");
user.setAge(25);
user.setBirthday(new Date());
user.setHobbies(Arrays.asList("阅读", "运动"));
String json = mapper.writeValueAsString(user);
System.out.println("序列化结果: " + json);
// 输出: {"name":"张三","age":25,"birthday":1698765432000,"hobbies":["阅读","运动"]}
// JSON → 对象
String jsonInput = "{\"name\":\"李四\",\"age\":30,\"hobbies\":[\"音乐\"]}";
User user2 = mapper.readValue(jsonInput, User.class);
System.out.println("反序列化结果: " + user2.getName());
}
}2. 在调用 writeValue 或调用 readValue 方法之前,往往需要设置 ObjectMapper 的相关配置信息。这些配置信息应用 java 对象的所有属性上。示例如下:
//在反序列化时忽略在 json 中存在但 Java 对象不存在的属性
mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
//在序列化时日期格式默认为 yyyy-MM-dd'T'HH:mm:ss.SSSZ
mapper.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, false);
//在序列化时自定义时间日期格式
mapper.setDateFormat(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
//在序列化时忽略值为 null 的属性
mapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
//在序列化时忽略值为默认值的属性
mapper.setDefaultPropertyInclusion(JsonInclude.Include.NON_DEFAULT);3. 还有各种注解可以使用:(还有好多...)
| @JsonFormat | 用于属性或者方法,把属性的格式序列化时转换成指定的格式。示例:@JsonFormat(timezone = "GMT+8", pattern = "yyyy-MM-dd HH:mm") public Date getBirthDate() |
| @JsonIgnore | 可用于字段、getter/setter、构造函数参数上,作用相同,都会对相应的字段产生影响。使相应字段不参与序列化和反序列化。 |
public class AnnotatedUser {
@JsonProperty("user_name") // 自定义JSON字段名
private String name;
@JsonIgnore // 忽略该字段
private String password;
@JsonFormat(pattern = "yyyy-MM-dd") // 日期格式
private Date birthday;
@JsonInclude(JsonInclude.Include.NON_NULL) // 非空时才序列化
private String email;
@JsonAlias({"fullName", "realName"}) // 反序列化时的别名
private String fullName;
// 构造方法、getter、setter
}
14.SPI
SPI是Java提供的一种服务发现机制。它允许服务提供者在META-INF/services目录下创建一个以服务接口全限定名命名的文件,文件内容为服务实现类的全限定名。然后,通过ServiceLoader类来加载这些实现类。这样,程序可以在运行时动态为接口寻找实现类,从而实现解耦和扩展。
例如,我们有一个接口com.example.Storage,那么可以在META-INF/services目录下创建一个名为com.example.Storage的文件,文件内容为com.example.FileStorage(这是接口的一个实现类)。然后,我们可以通过ServiceLoader来加载所有实现类。
ServiceLoader<Storage> loader = ServiceLoader.load(Storage.class);
for (Storage storage : loader) {
// 使用storage实例
}
SPI机制在Java中广泛应用,比如JDBC驱动加载就是通过SPI机制。

springboot中也用到了spi思想,注解扫包实体类给ioc只能扫这个启动类的同包下,外部的导入一个starter就把要用的bean注入到ioc就是因为spi这种思想。
Spring Boot通过扫描 META-INF/spring.factories (旧) 和 META-INF/spring/AutoConfiguration.imports (新) 这两个路径,实现了其强大的“约定优于配置”和自动装配能力,这正是SPI“服务发现”思想的极致体现。
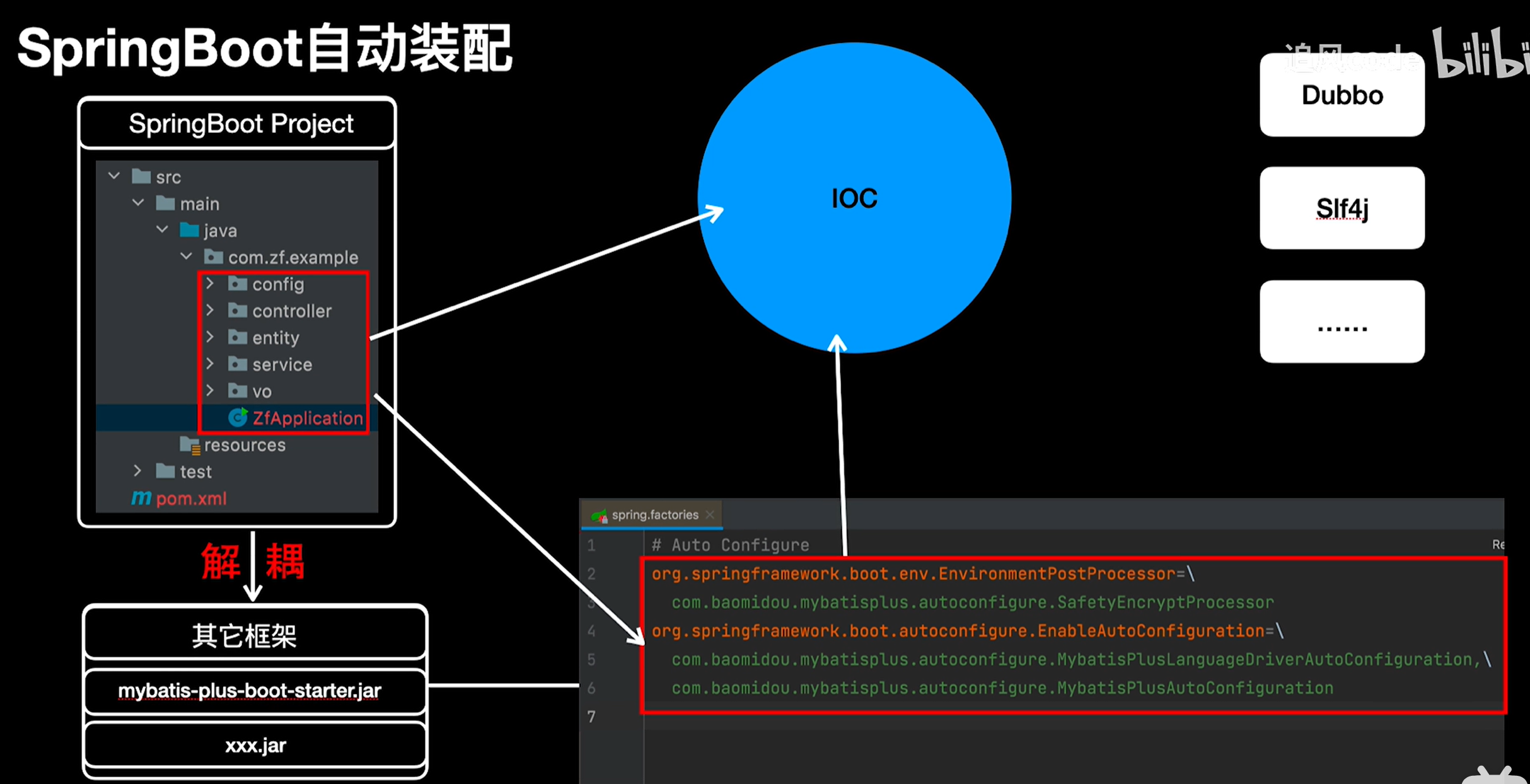
java中运行脚本语言【了解】
ScriptEngineManager 是javax.script的一部分,用于在 Java 程序中执行脚本代码。它支持多种脚本语言,比如 JavaScript、Groovy、Ruby 等。
-
创建脚本引擎:可以使用
ScriptEngineManager来创建特定脚本语言的ScriptEngine实例。 -
管理脚本引擎:它能够管理系统中可用的所有脚本引擎,包括列出可用的引擎,并提供创建引擎的功能。
import javax.script.ScriptEngine;
import javax.script.ScriptEngineManager;
import javax.script.ScriptException;
public class ScriptEngineExample {
public static void main(String[] args) {
// 创建 ScriptEngineManager 实例
ScriptEngineManager manager = new ScriptEngineManager();
// 获取 JavaScript 引擎
ScriptEngine engine = manager.getEngineByName("JavaScript");
// 执行简单的 JavaScript 代码
try {
// 计算表达式
Object result = engine.eval("10 + 20");
System.out.println("计算结果: " + result); // 输出: 计算结果: 30
// 定义变量并执行
engine.eval("var greeting = 'Hello, world!';");
String greeting = (String) engine.get("greeting");
System.out.println(greeting); // 输出: Hello, world!
} catch (ScriptException e) {
e.printStackTrace();
}
}
}java中运行java语言【需编译】【了解】
ResourceBundle类
简单来说就是解决本地和国际问题的读取properties资源的类,如果后面不指定资源语言,就会分析本地操作系统是什么语言,选择此语言版本的。【从target下找】
// 通过以下代码获取属性文件中的配置信息
ResourceBundle bundle = ResourceBundle.getBundle("com.powernode.jdbc.jdbc");
String driver = bundle.getString("driver");
String url = bundle.getString("url");
String user = bundle.getString("user");
String password = bundle.getString("password");
















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









