







 Apache Spark在大数据处理领域持续发展,Spark 3.0引入动态分区裁减、自适应执行和DataSource API V2等优化。Koalas的出现使得Spark与pandas无缝兼容,简化大数据分析。Delta Lake作为数据湖解决方案,提供事务性、版本控制和元数据管理。Spark面对数据工程师和科学家,通过不断进化满足从小数据到大规模数据分析的需求。
Apache Spark在大数据处理领域持续发展,Spark 3.0引入动态分区裁减、自适应执行和DataSource API V2等优化。Koalas的出现使得Spark与pandas无缝兼容,简化大数据分析。Delta Lake作为数据湖解决方案,提供事务性、版本控制和元数据管理。Spark面对数据工程师和科学家,通过不断进化满足从小数据到大规模数据分析的需求。
本资料来自2019-09-26在杭州举办的云栖大会的大数据 & AI 峰会分会。议题名称《 New Developments in the Open Source Ecosystem: Apache Spark 3.0 and Koalas 》,分享嘉宾 李潇, Databricks Spark 研发总监。
下面是本次会议的视频(由于微信公众号的限制,只能发布小于30分钟的视频,
完整视频和 PPT 请关注 过往记忆大数据 公众号并回复 spark_yq 获取。 )
2019年对 Spark 社区来说是一个比较特殊的年份。 10年前,马铁为了帮助自己的同学得到 Netflix 发起的 Netflix Prize 竞赛百万美金,诞生了一个伟大的项目,这就是现在的 Apache Spark。
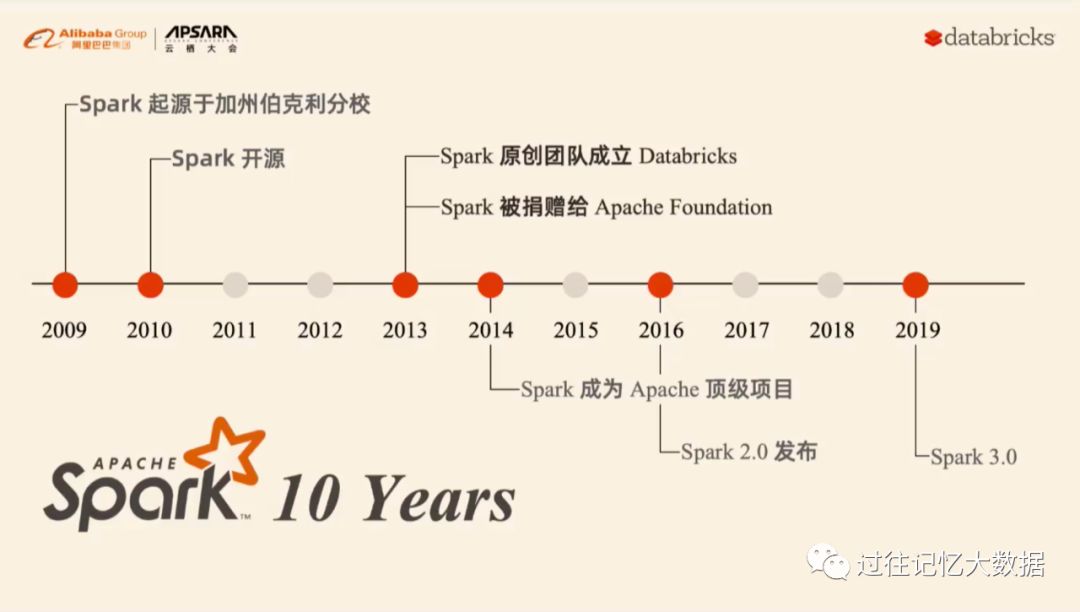
上面就是 Apache Spark 的发展历史。2019年09月将会发布 Apache Spark 3.0 预览版,明年年初将会发布 Apache Spark 3.0 正式版。
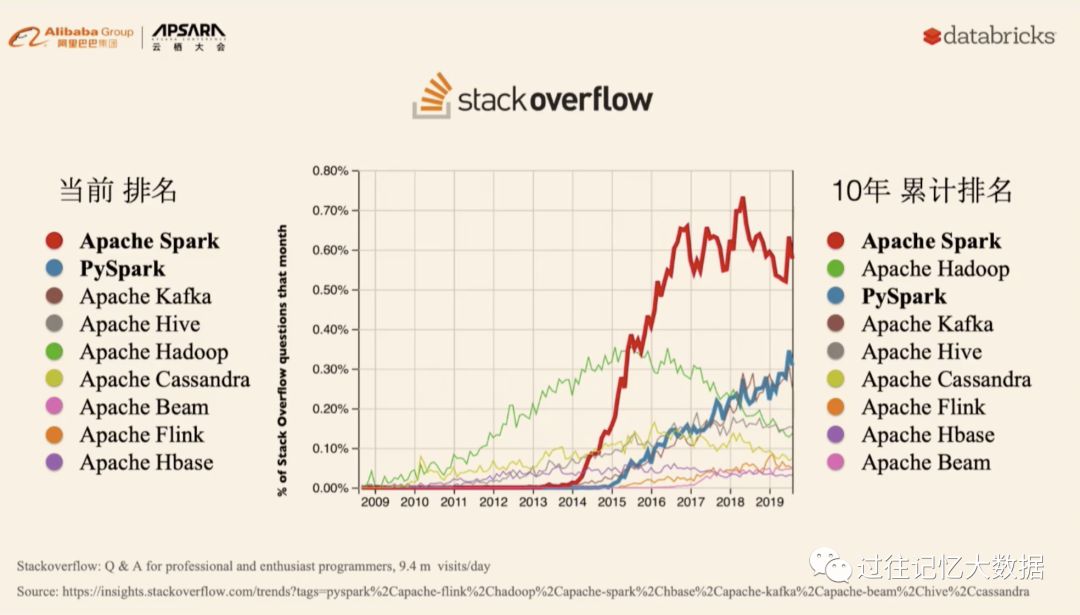
世界级的知乎 stackoverflow 中当年 Spark 和 PySpark 排名都很靠前,10年累计排名 Apache Spark 第一,Apache Hadoop 第二;未来 Apache Spark 和 PySpark 将会垄断世界。

Apache Spark 3.0 是社区共同努力的结果,大概开发了一年多。下面是 Apache Spark 3.0 的主要特性:

动态分区裁减
自适应
Spark Graph
加速感应调度(GPU,具体参见 )
Spark on k8s
DataSource API V2
ANSI SQL 兼容
SQL Hint
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4253
4253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









