



 本文对比了PB(Protocol Buffers)与JSON在不同场景和数据结构下的解析速度,指出当数据主要包含double类型时,PB能显著提升速度。通过Java测试环境下的对比,展示了PB在二进制数据处理上的优势。
本文对比了PB(Protocol Buffers)与JSON在不同场景和数据结构下的解析速度,指出当数据主要包含double类型时,PB能显著提升速度。通过Java测试环境下的对比,展示了PB在二进制数据处理上的优势。
今天发现腾讯的某个开源游戏项目中采用的是pb格式的数据作为通信传输
于是大概查找了一下pb的特性和相关用法,是这样描述比较的
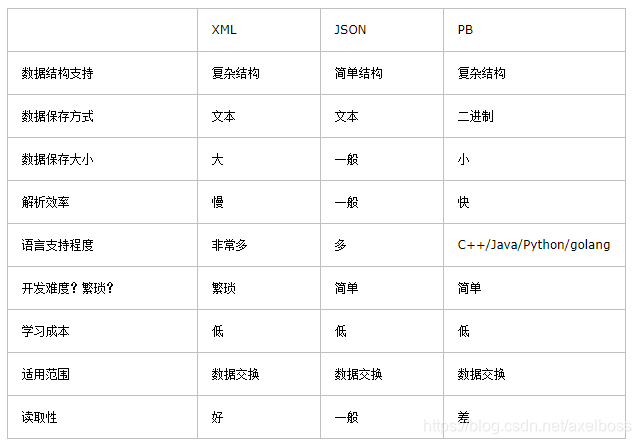
——————————————————————————————————
下两图描述了在java测试环境下json和pb在不同场景和数据结构下的速度
Jackson为java通用解析json工具
Jsoniter为优化过的json解析工具
Protobuf为protocolbuffer协议处理速度
(参考链接 https://www.sohu.com/a/136487507_505779)

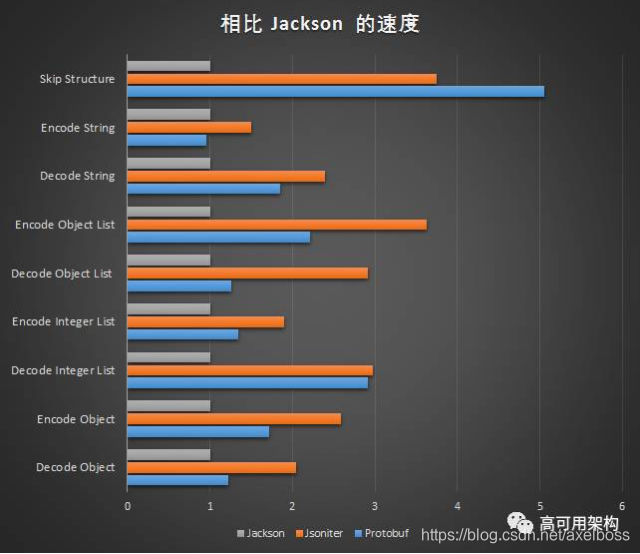
结合以上得知在数据中主要为double时,采用二进制protocolbuffer格式可明显提高解析速度;其他情况下json和protobuf差距不大。

















 33
33

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









