




语音智能和语音转文本 (STT) 技术已变得至关重要,因为组织每天收集数千小时的电话、会议和客户互动。仅靠原始音频并不能推动决策 - 组织需要智能来大规模地从语音数据中提取价值。语音智能结合了语音识别、自然语言处理 (NLP) 和机器学习 (ML),将语音数据转化为可作的见解。现代 STT 模型可以准确地转录对话,并与其他工具配合使用来分析情绪、检测关键主题并生成自动摘要以获得更深入的见解。语音智能和 STT 技术服务于多个行业使用案例,包括呼叫分析和对话智能、医疗保健文档、客户服务、视频内容优化、法律发现和合规性、销售智能和辅导等。随着生成式 AI 和改进模型的出现,这些应用程序对有效 STT 模型的需求持续增长。
AssemblyAI 是 AWS Marketplace 中的独立软件供应商 (ISV),是一家研究型组织,致力于为全世界推进语音 AI 技术并使其大众化。他们成立于 2017 年,建立了一支由跨学科研究领导者、科学家和工程师组成的团队,致力于创建超人语音 AI 模型,为语音数据应用解锁新的可能性。 AssemblyAI 技术通过简单、对开发人员友好的 API 为全球成千上万的客户和数十万开发人员提供服务。AssemblyAI 提供全面的语音 AI 功能,包括:
- 核心语音到文本转录
- 扬声器检测
- 自动语言检测
- 情绪分析
- 章节检测
- 个人身份信息 (PII) 修订
Universal-2 模型展示了 AssemblyAI 致力于突破语音 AI 可能性的界限。此模型通过解决语音识别中的关键挑战、提高正确的名词准确性、格式和大小写以及时间戳生成来实现高准确性。AssemblyAI 采用以研究为中心的方法来构建准确、功能强大的语音 AI 模型,这些模型易于集成。 本文展示了如何从 AWS Marketplace 开始使用 AssemblyAI 的 API,并通过几个步骤调用这些模型 API 来构建初始概念验证 (POC)。
解决方案概述
AssemblyAI 的语音转文本服务通过两阶段管道处理音频。第一阶段使用 Universal-2 自动语音识别 (ASR) 模型,这是一个 600M 参数的 Conformer RNN-T 模型,基于 12.5M 小时的多语言音频数据进行训练。此模型将语音转换为文本,同时处理多个说话人、口音和背景噪音。第二阶段采用神经模型进行文本格式化,处理标点符号、大写和文本规范化等任务,以生成干净、可读的转录文本。 除了基本转录之外,客户还可以启用与核心 ASR 流程一起运行的其他智能模型。其中包括用于跟踪谁说了什么的说话人识别、用于了解情感背景的情绪分析、用于自动对对话进行分类的主题检测、用于提取关键点的内容摘要以及用于维护隐私合规性的 PII 编辑。所有这些模型都通过相同的 API 接口无缝地协同工作。下图显示了高级体系结构。
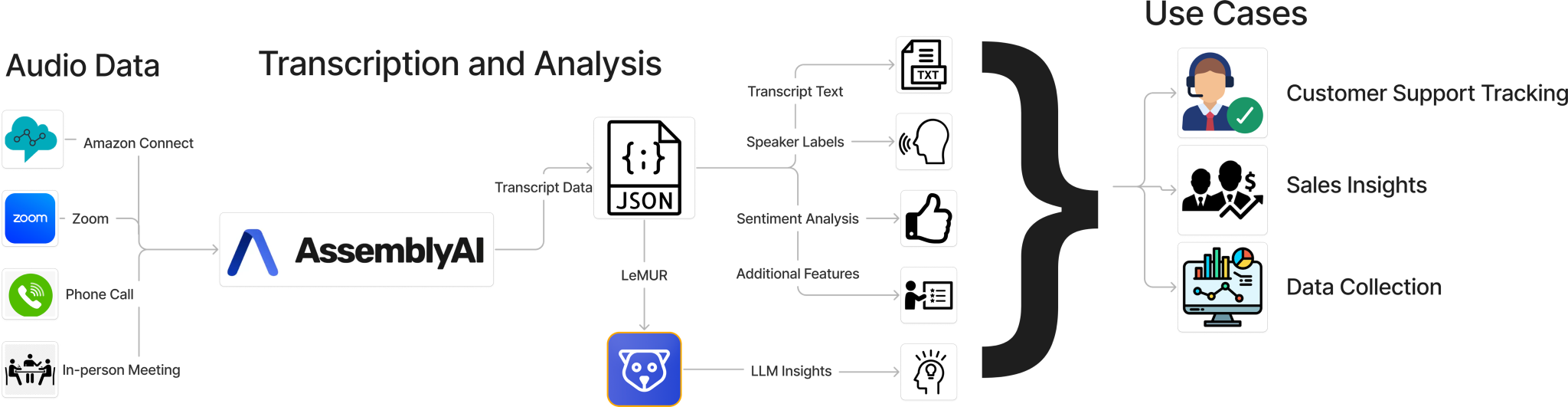
图 1:AssemblyAI 的 API 转录的高级架构图
先决条件
在开始之前,请确保您满足以下先决条件:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









