







操作系统
1、进程和线程的区别
进程:进程是操作系统资源分配的最小单位。他是程序的一次执行实例,拥有独立的内存空间。
线程:线程是cpu调度的最小单位。
联系:线程是进程的基本执行单元,进程包含线程。
区别:不同进程拥有自己独立的地址空间(只能通过IPC的方式进行数据交换),同一进程的不同线程共享本进程的地址空间。一个进程崩溃后,在保护模式下不会对其他的进程产生影响,但是同一进程的线程奔溃后,会影响其他线程。在频繁切换的情况下,线程的消耗资源比进程小。
2、多进程和多线程的通讯方式
多进程:
进程间的通信(IPC)是操作系统中不同进程之间进行数据交换和共享机制。无名管道,有名管道都是常见的进程间的通信。
无名管道(Pipe),有名管道(FIFO),消息队列,共享内存,信号量(semaphore),信号,套接字(sokect)。
(信号是异步的,而信号量是同步(等待阻塞)。)
(互斥锁是包含优先级继承机制的二进制信号量。 )
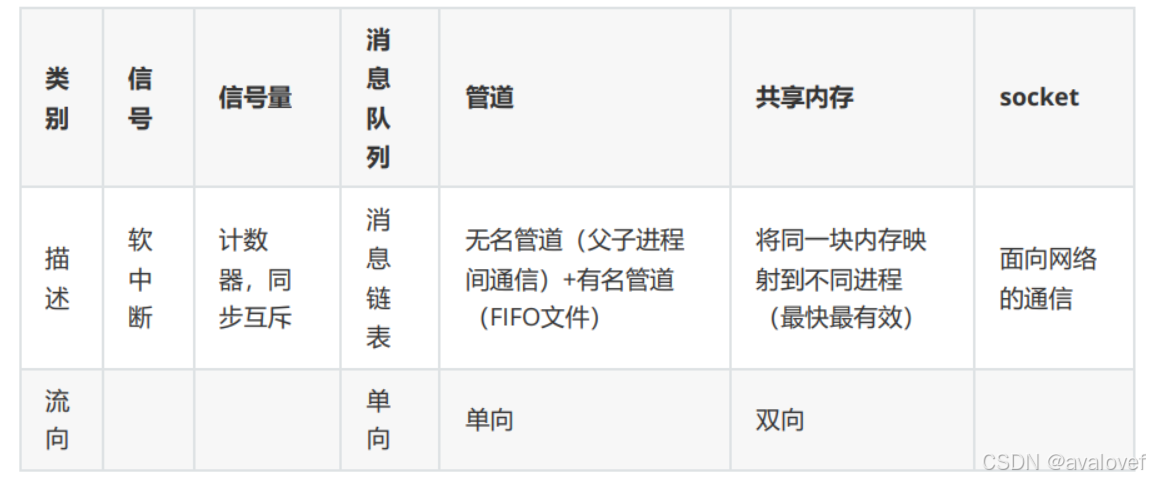
进程之间通信有什么方式,有什么优缺点,为什么不选择某某方式?
①无名管道、有名管道
无名管道(PIPE):
无名管道是半双工的,只有一个读端或者写端,他常用在父子进程或者有亲缘关系的进程间的通信。无名管道在创建后没有名字,只能通过文件描述符进行操作。
有名管道(FIFO):
有名管道也是半双工的,但可以在任意两个进程间使用,即使它们没有亲缘关系。有名管道在文件系统中有一个名字,可以通过这个路径名进行访问。有名管道提供了一个持久的通信方式,即使创建它的进程已经退出,有名管道依然存在。
//无名管道
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
//无名管道 父进程向管道写入数据,子进程从管道读取并打印数据。
int main(){
int pipefd[2];
pid_t cpid;
//create pipe
if(pipe(pipefd) == -1)
{
perror("pipe");
exit(EXIT_FAILURE);
}
//clone the process
cpid = fork();
if(cpid == -1){
perror("fork");
exit(EXIT_FAILURE);
}
// create a new process succuessfully
if(cpid == 0){//son process
close(pipefd[1]);//cloese the write com
//子进程只能读
char buf;
while(read(pipefd[0],&buf,1)>0){
write(STDOUT_FILENO, &buf, 1);//打印到终端
}
close(pipefd[0]);
exit(EXIT_SUCCESS);
}else{//father process
close(pipefd[0]); // 关闭读端
write(pipefd[1], "Hello, World!\n", 14);
close(pipefd[1]); // 关闭写端,子进程见EOF会退出
wait(NULL); // 等待子进程退出
}
return 0;
}
//有名管道 创建一个有名管道,一个进程通过读的形式打开有名管道进行读,一个进程则可以写入该有名管道
mkfifo myfifo
//一个进程读
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int main() {
int fd;
char buf;
// 以读方式打开有名管道
fd = open("myfifo", O_RDONLY);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
// 从有名管道读取数据
while (read(fd, &buf, 1) > 0) {
write(STDOUT_FILENO, &buf, 1);
}
close(fd);
return 0;
}
//一个进程写
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int main() {
int fd;
// 以写方式打开有名管道
fd = open("myfifo", O_WRONLY);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
// 写数据到有名管道
const char *message = "Hello, World through FIFO!\n";
write(fd, message, strlen(message));
close(fd);
return 0;
}
②消息队列
消息队列是一种进程间通信(IPC)机制,允许不同进程之间以消息的形式交换数据。
消息队列的特点:
消息顺序:消息队列保证按照消息的发送顺序进行处理。
持久性:消息可以设置为持久性,这意味着即使系统崩溃,消息也不会丢失。
异步通信:发送者和接收者不需要同时运行,消息队列作为中介存储消息。
消息缓冲:消息队列可以作为缓冲区,平衡生产者和消费者的速度差异。
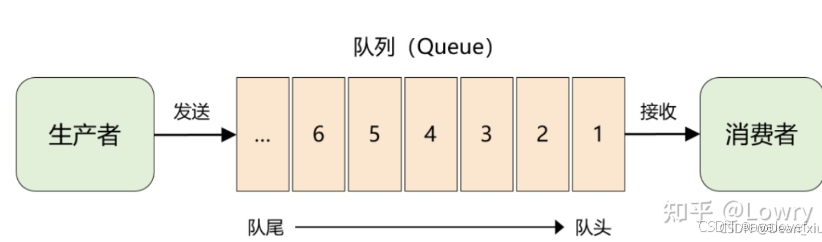
消息队列的数据结构:
struct mq_attr
{
__syscall_slong_t mq_flags; /* Message queue flags. */
__syscall_slong_t mq_maxmsg; /* Maximum number of messages. */
__syscall_slong_t mq_msgsize; /* Maximum message size. */
__syscall_slong_t mq_curmsgs; /* Number of messages currently queued. */
__syscall_slong_t __pad[4];
};
其中两个进程一个创建消息队列发送消息,一个根据消息队列的名称直接打开队列,接收消息:
创建消息队列的进程负责创建消息队列,通过消息队列这个媒介来发送消息:
//sender.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <mqueue.h>
#define QUEUE_NAME "/my_queue"
#define MAX_SIZE 1024
#define MSG_STOP "exit"
mqd_t mq;//INT
struct mq_attr attr;
int main() {
char *message = "Hello, World!";
attr.mq_flags = 0;//默认标志 (非阻塞O_NONBLOCK)
attr.mq_maxmsg = 10;// 最大队列中的的消息数量
attr.mq_msgsize = MAX_SIZE;// 消息的最大大小
attr.mq_curmsgs = 0;/// 初始时队列中的消息数量,通常由系统维护
// 创建消息队列
mq = mq_open(QUEUE_NAME, O_CREAT | O_WRONLY, 0644, &attr);//创建消息队列,具有读写权
if (mq == (mqd_t)-1) {
perror("mq_open");
exit(1);
}
// 发送消息
if (mq_send(mq, message, strlen(message) + 1, 0) == -1) {
perror("mq_send");
exit(1);
}
// 可以发送更多消息或处理其他逻辑
// 关闭消息队列
mq_close(mq);
return 0;
}
其中接收队列根据名称打开队列,接收方这边接受完了以后通过mq_unlink来删除消息队列。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <mqueue.h>
#define QUEUE_NAME "/my_queue"
#define MAX_SIZE 1024
#define MSG_STOP "exit"
mqd_t mq;
struct mq_attr attr;
int main() {
char buffer[MAX_SIZE + 1];
unsigned int priority;
// 打开消息队列
mq = mq_open(QUEUE_NAME, O_RDONLY);
if (mq == (mqd_t)-1) {
perror("mq_open");
exit(1);
}
// 接收消息
while (1) {
if (mq_receive(mq, buffer, MAX_SIZE, &priority) == -1) {
perror("mq_receive");
exit(1);
}
buffer[MAX_SIZE] = '\0'; // 确保字符串正确终止
printf("Received: %s\n", buffer);
// 检查是否为停止消息
if (strcmp(buffer, MSG_STOP) == 0) {
break;
}
}
// 关闭并删除消息队列
mq_close(mq);
mq_unlink(QUEUE_NAME);
return 0;
}
③共享内存
通过共享内存,进程可以直接访问同一块内存区域,从而实现快速的数据交换,无需进行数据的复制或移动。
通常使用 shm_open 函数创建一个共享内存对象,并使用 ftruncate 或 mmap 来设置其大小。使用 mmap 函数将共享内存对象映射到进程的地址空间。映射成功后,进程可以通过指针直接访问和操作共享内存区域。通常需要使用互斥锁(如 POSIX 互斥锁)或其他同步机制来控制对共享内存的访问,以防止数据竞争和不一致。使用 munmap 函数解除映射,使用 shm_unlink 函数删除共享内存对象。
④套接字
网络通信建立socket(套接字是支持TCP/IP网络通信的基础。也支持UDP等等)
创建套接字:使用 socket() 函数创建一个套接字。
绑定地址:使用 bind() 函数将套接字绑定到一个地址和端口上(对于服务器端)。
监听连接:对于服务器端,使用 listen() 函数监听客户端的连接请求。
接受连接:对于服务器端,使用 accept() 函数接受客户端的连接请求,建立连接。
连接服务器:对于客户端,使用 connect() 函数连接到服务器端。
数据传输:使用 send() 和 recv()(或 read() 和 write())函数进行数据的发送和接收。
关闭套接字:通信结束后,使用 close() 函数关闭套接字。
多线程:
线程间由于可以一份共享内存区域,所以线程之间可以快速地共享信息,只用把数据同步到全局变量中就可以了。但是考虑到线程的同步和护持,全局
线程间的通信方式:
互斥锁、读写锁、自旋锁(各种锁的区别 )
信号、信号量、条件变量、生产者消费者模型。(信号和信号量的区别)
①互斥锁、读写锁、自旋锁
互斥锁(mutex):确保同一时间只有一个线程能操作共享数据。
POSIX线程库种提供了互斥锁pthread_mutex_t,访问顺序包括初始化初始化线程-互斥锁-锁定-线程访问互斥资源-解锁
读写锁 (rwlcok):读写锁当以写模式加锁而处于写状态时任何试图加锁的线程(不论是读或写)都阻塞,当以读状态模式加锁而处于读状态时“读”线程不阻塞,“写”线程阻塞。读模式共享,写模式互斥
pthread_rwlock_rdlock pthread_rwlock_t定义读写锁变量。
自旋锁(spinlock):
自旋锁是“原地等待”的方式解决资源冲突的,即,一个线程获取了一个自旋锁后,另外一个线程期望获取该自旋锁,获取不到,只能够原地“打转”(忙等待)。由于自旋锁的这个忙等待的特性,注定了它使用场景上的限制 —— 自旋锁不应该被长时间的持有(消耗 CPU 资源)。
中断上下文要用锁,首选 spinlock。共享数据被中断上下文和进程上下文访问,该如何保护呢?如果只有进程上下文的访问,那么可以考虑使用semaphore或者mutex的锁机制,但是现在中断上下文也参和进来。因为在中断上下文,是不允许睡眠的,这里需要的是一个不会导致睡眠的锁——spinlock。
特别注意,线程得不到互斥锁是阻塞(挂起,线程不占用CPI资源,不会被调度执行)。线程得不到自旋锁是进入忙等待状态,不断检查自旋锁是否可用,仍然消耗CPU资源。
#include <linux/spinlock.h>
#include <linux/interrupt.h>
// 定义一个自旋锁变量
spinlock_t my_lock;
// 定义一个全局变量,需要被保护
int shared_data;
// 中断处理程序
irqreturn_t my_interrupt_handler(int irq, void *dev_id) {
unsigned long flags;
// 禁用本地中断并获取自旋锁
spin_lock_irqsave(&my_lock, flags);
// 访问或修改共享数据
shared_data++;
// 释放自旋锁并恢复本地中断状态
spin_unlock_irqrestore(&my_lock, flags);
return IRQ_HANDLED;
}
// 初始化自旋锁
void init_my_lock(void) {
spin_lock_init(&my_lock);
}
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
// 定义互斥锁变量
pthread_mutex_t lock;
// 共享资源
int counter = 0;
// 线程函数
void* increment_counter(void* arg) {
// 锁定互斥锁
pthread_mutex_lock(&lock);
// 安全地更新共享资源
counter++;
printf("Counter value: %d\n", counter);
// 解锁互斥锁
pthread_mutex_unlock(&lock);
return NULL;
}
int main() {
pthread_t thread1, thread2;
// 初始化互斥锁
if (pthread_mutex_init(&lock, NULL) != 0) {
perror("Mutex init has failed");
return 1;
}
// 创建两个线程
pthread_create(&thread1, NULL, increment_counter, NULL);
pthread_create(&thread2, NULL, increment_counter, NULL);
// 等待线程结束
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
// 销毁互斥锁
pthread_mutex_destroy(&lock);
// 打印最终的计数器值
printf("Final counter value: %d\n", counter);
return 0;
}
②信号、信号量、条件变量(生产者消费者模型)
信号:信号是一种软件中断,用于通知进程发生了某种事件。Linux提供了多种标准信号,如SIGINT(中断信号)、SIGKILL(杀死进程信号)等。(用法:用户按下Ctrl+C时,会向前台进程组发送SIGINT信号,通常会导致进程终止)
信号量: 信号量是一个计数器,用于控制对共享资源的访问。它可以用来实现线程、进程间的同步和互斥。(互斥锁、资源同步)
条件变量:条件变量用于线程间的同步,它允许线程在某些条件尚未满足时挂起,并在条件满足时被唤醒。
(生产者-消费者模型,等待模型)
//信号捕获
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
void sigal_handler(int signum){
printf("caught signal:%d\n",signum);
exit(0);
}
int main(){
signal(SIGINT,sigal_handler);//按下ctrl+c就调用sigal_handler结束进程
printf("waiting for signal...\n");
while(1){
sleep(1);
}
return 0;
}
//信号量
#include <stdio.h>
#include <stdlib.h>
#include <semaphore.h>
#include <pthread.h>
sem_t sem;
void* thread_func(void* arg) {
sem_wait(&sem); // 等待信号量
printf("Thread %ld got the semaphore\n", pthread_self());
sem_post(&sem); // 释放信号量
return NULL;
}
int main() {
pthread_t t1, t2;
// 初始化信号量
sem_init(&sem, 0, 1);
// 创建两个线程
pthread_create(&t1, NULL, thread_func, NULL);
pthread_create(&t2, NULL, thread_func, NULL);
// 等待线程结束
pthread_join(t1, NULL);
pthread_join(t2, NULL);
// 销毁信号量
sem_destroy(&sem);
return 0;
}
//条件变量和互斥锁 在生产者消费者上面的应用
//如果没有接收到发送的条件信号,那么就阻塞睡眠
//互斥锁是为了同步共享的资源
#include <stdio.h>
#include <stdlib.h>
#include <semaphore.h>
#include <pthread.h>
#include <unistd.h>
#define BUFFER_SIZE 10
int buffer[BUFFER_SIZE];
int count = 0;
int in = 0;//下一个生产者放置数据的位置
int out = 0;//下一个消费者将数据取出的位置
//互斥锁和条件变量
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t can_produce = PTHREAD_COND_INITIALIZER;
pthread_cond_t can_consume = PTHREAD_COND_INITIALIZER;
//生产者
void* producer(void* arg){
int item;
for(int i =0;i<20;i++){
item = i;
pthread_mutex_lock(&mutex);
while (count == BUFFER_SIZE)//缓冲区域满了
{
pthread_cond_wait(&can_produce,&mutex);//等待消费者消费,阻塞
}
buffer[in] = item;
in = (in + 1) % BUFFER_SIZE;//环形位置,重新更新start
count++;
printf("Produced: %d\n", item);
pthread_cond_signal(&can_consume); // 通知消费者可以消费
pthread_mutex_unlock(&mutex);
sleep(1); // 模拟生产耗时
}
return NULL;
}
//消费者
void* consumer(void* arg){
int item;
for (int i = 0; i < 20; i++) {
pthread_mutex_lock(&mutex);
while (count == 0) { // 缓冲区空
pthread_cond_wait(&can_consume, &mutex); // 等待生产者生产,阻塞
}
item = buffer[out];
out = (out + 1) % BUFFER_SIZE;
count--;
printf("Consumed: %d\n", item);
pthread_cond_signal(&can_produce); // 通知生产者
pthread_mutex_unlock(&mutex);
sleep(1); // 模拟消费耗时
}
return NULL;
}
int main() {
pthread_t prod, cons;
pthread_create(&prod,NULL,producer,NULL);
pthread_create(&cons,NULL,consumer,NULL);
//wait until thread ends
pthread_join(prod,NULL);
pthread_join(cons,NULL);
// 销毁互斥锁和条件变量
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&can_produce);
pthread_cond_destroy(&can_consume);
return 0;
}
③多线程缓存
单核CPU只含有一套L1,L2,L3缓存;如果CPU含有多个核心,即多核CPU,则每个核心都含有一套L1(甚至和L2)缓存,而共享L3(或者和L2)缓存。多CPU,每个CPU都相互独立,拥有自己的缓存,CPU之间无法共享缓存。
没有缓存的结构中,CPU执行进程的时候,使用虚拟地址,虚拟地址通过MMU翻译为物理地址,映射到内存中;在有缓存的结构中,CPU访问数据先查找缓存中是否存在该数据,这可以通过数据在进程中的虚拟地址去到缓存中查找,也可以通过该数据在内存中的物理地址去到缓存中查找。
在多线程模式下,一个CPU,且CPU单核,进程中的多个线程会同时访问进程中的共享数据,CPU将某块内存加载到缓存后,不同线程在访问相同的物理地址的时候,都会映射到相同的缓存位置,这样即使发生线程的切换,缓存仍然不会失效。
多线程模式下,一个CPU,且CPU有多核,每个核都至少有一个L1 cache。多个线程访问进程中的某个共享内存,且这多个线程分别在不同的核心上执行,则每个核心都会在各自的caehe中保留一份共享内存的缓冲。由于多核可以做到真并行,可能会出现多个线程同时写各自的cache,
因此CPU有“缓存一致性”原则,即每个处理器(核)都会通过嗅探在总线上传播的数据来检查自己的缓存值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器(核)。因此,我们经常看到在多核多线程的场景下,在声明变量时候使用volatile,volatile变量要求在更新了缓存之后立即写入到系统内存,而非volatile变量,则是CPU修改缓存,缓存在适当的识货(不知道什么时候)将缓存数据写入内存。写入内存的操作会出发其他处理器(核)将自己已经缓存的那块正在被写入的内存失效,并在下次需要使用到该内存的时候重新从内存读取。
CPU缓存一致性协议:如MESI协议,它确保多核处理器中每个核心的缓存数据保持一致。MESI代表四种状态:Modified(修改)、Exclusive(独占)、Shared(共享)和Invalid(无效)。这个协议通过监听和通信机制,确保当一个核心修改了缓存行的数据时,其他核心的相应缓存行会被置为无效,从而保证数据的一致性
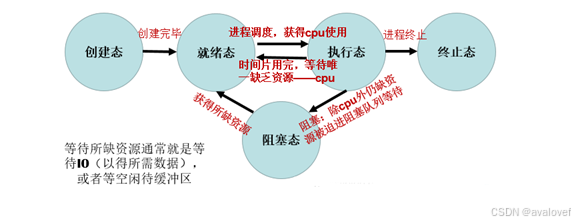
3、进程线程转换图
到阻塞态—>wait
4、进程上下文、中断上下文
进程上下文:CPU调度的时候,会为其建立一个执行环境,保存PC程序计数器,MSP栈指针,通用寄存器等等。当进程被抢占时,操作系统会将其上下文保存,以便其下次调度时恢复执行.进程上下文切换涉及保存和恢复现场,其开销较大.
当 CPU接收到中断时,当前执行的进程会被暂停,转入中断服务例程执行.
中断服务例程有自己的上下文,包括堆栈指针、程序计数器等.在中断处理完后,CPU 会恢复到中断发生前的进程,继续执行.
与进程上下文切换相比,中断上下文切换开销较小,并且保护的是中断上下文(中断服务例程),并且中断切换一般在内核态。
5、并发,并行,同步,异步,互斥,阻塞,非阻塞的理解
并发:同一个时间间隔内,多个任务都在交替执行。(多核cpu)
并行:同一个时间内多个任务同时执行。
同步:一个任务在执行某个操作时,需要等待其他任务的信息或信号才能继续执行.同步处理通常使用互斥锁,条件变量等机制实现.。
异步:一个任务在执行某个操作时,不需要等待其他任务的信息或信号就继续执行.异步通常使用回调函数,事件等机制实现。
互斥:多个任务同一时间只能有一个任务进入临界区,其他任务必须等待.互斥的实现使用的是互斥锁(Mutex).
阻塞:一个任务在等待某个事件(如 I/O 操作或互斥锁)发生时,被暂停执行.阻塞通常用于同步处理,以协调多个任务的执行.
非阻塞:一个任务在等待某个事件(如 I/O 操作)时,不暂停执行.非阻塞通常用于异步处理,提高程序的响应性.
6、内核态、用户态的区别
区别:运行级别不同,内核态可以访问硬件系统。一般从用户态切换到内核态的情况:系统调用、异常、外围设备中断。
7、进程可以创建多少线程数量
理论情况下看进程的总的虚拟空间,假设有2GB,那么总进程的虚拟空间是2*2^30字节。然后看线程栈的大小,假设有1MB = 1*2^20字节
那么最大的线程数 = 总的虚拟空间的/线程栈 = 2*2^10 字节。
8、进程控制块PCB、线程控制块TCB(任务控制块TCB)
进程控制块(PCB):
ps aux、top
(1)进程标识符(内部(UID)),外部(PID))
(2)处理机的信息(通用寄存器,指令计数器,PSW,用户的栈指针)。
(3)进程调度信息(进程状态,进程的优先级,进程调度所需的其它信息,事件)
(4)进程控制信息(程序的数据的地址,资源清单,进程同步和通信机制,链接指针)
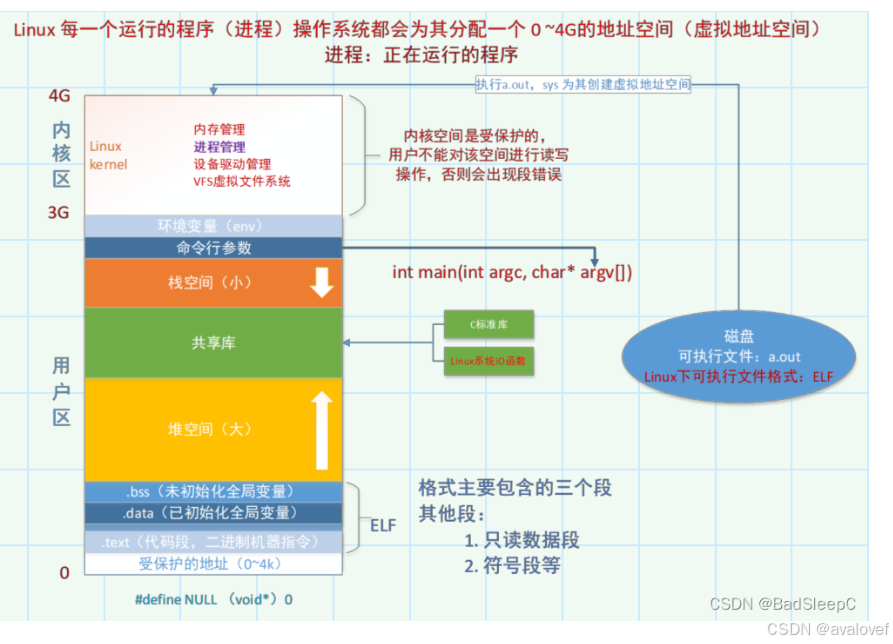
进程上下文切换要保存的内容:PCB、CPU通用寄存器、浮点寄存器、用户栈、内核数据结构(页表、进程表、文件表)
线程控制块(TCB):
(1)线程ID
(2)线程状态寄存器
(3)锁、信号量等同步机制与上下文信息
(4)线程优先级
线程上下文切换要保存的内容:TCB、寄存器(R0-R3、SP、LR、PC)、程序状态字:如程序处于中断、用户态、内核态等标志位 堆栈:线程执行期间所用的变量等信息 浮点FPU寄存器
9、ARM通用寄存器
在ARM架构中,有一组共16个通用寄存器(R0-R15)。这些寄存器可以用于各种目的,包括:
R0-R3:这些是低编号的通用寄存器,通常用于函数调用时传递参数。在ARM的函数调用约定中,R0-R3 用于传递前四个参数。
R4-R12:这些寄存器用于通用目的,但在函数调用过程中可能会被调用者或被调用者修改。
R13:通常用作堆栈指针(SP),但在某些模式下,它可能有不同的用途。
R14:通常用作链接寄存器(LR),用于存储子程序返回地址。
R15:通常用作程序计数器(PC),指示下一条指令的地址。
除了上述寄存器,ARM架构还包含一些特殊用途的寄存器,例如:
CPSR(Current Program Status Register):当前程序状态寄存器,用于存储当前执行状态的信息,如条件标志(零标志、负标志、溢出标志等)和处理器模式。
SPSR(Saved Program Status Register):保存的程序状态寄存器,用于在异常或中断处理期间保存CPSR的状态。
10、内存管理
1、虚拟内存
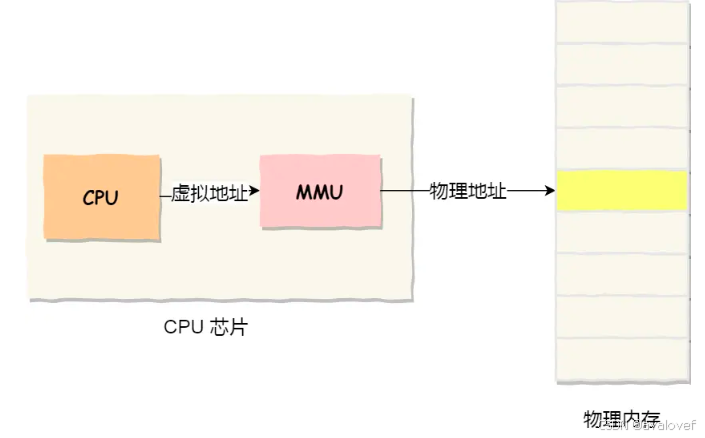
单片机是操作内存的物理地址,想要在内存中运行两个程序是不允许的,一个程序会擦除另外一个程序,同时运行两个程序是不行的。
linux中为了使用多个进程,操作系统通过MMU来映射物理内存地址和虚拟地址,通过分页和分段的方式来管理两个地址。
2、内存分段
把虚拟地址分为段基地值和段偏移量,(代码分段、数据分段、栈段、堆段组成。)通过虚拟地址与段表的映射到物理内存中。
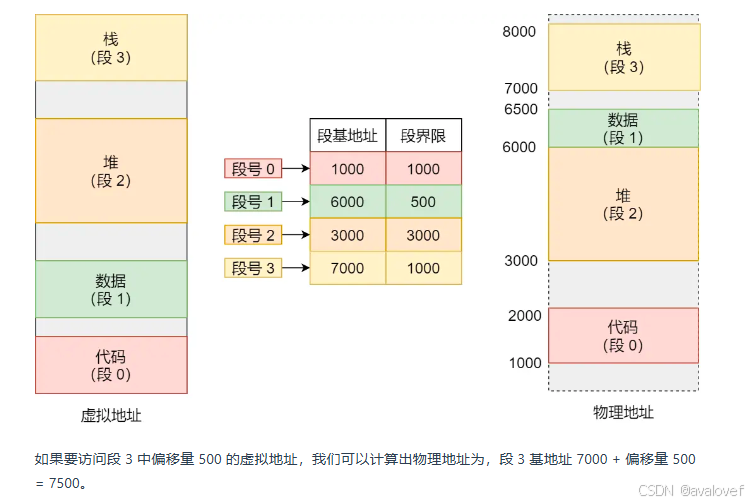
但是有问题:内存碎片(外部碎片(物理地址碎片))、内存交换的效率低(内存交换到的效率低)。
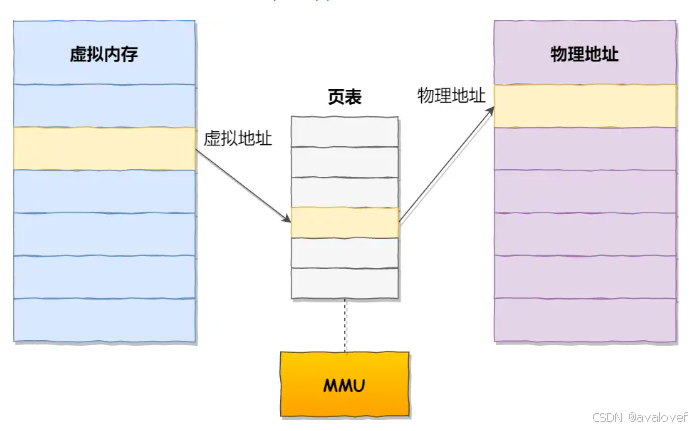
3、内存分页
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在 Linux 下,每一页的大小为 4KB。
因为每一页都连续,所以不会有外部内存碎片。但是最小只能分配一页,所以可能有内部内存碎片的情况。
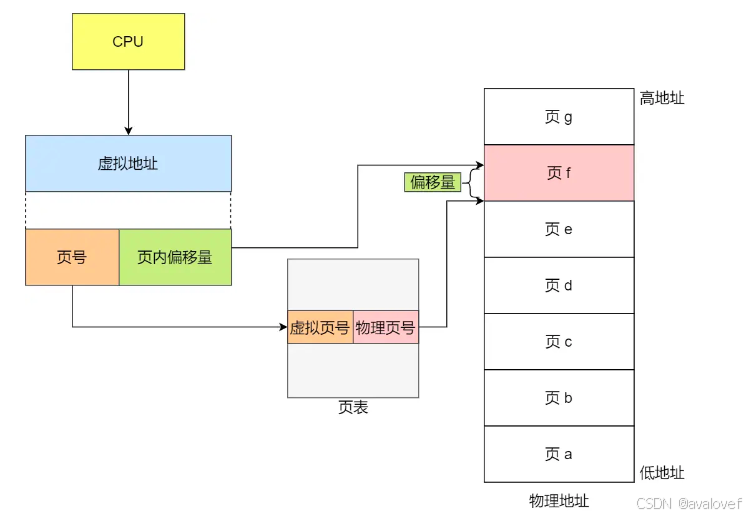
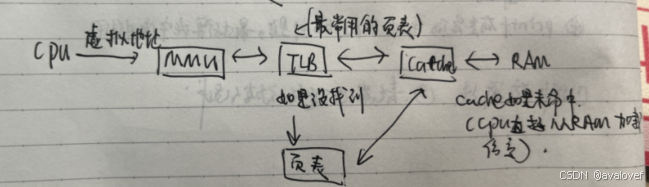
10.1 TLB、页表、Cache、主存之间的访问关系
CPU 首先检查 TLB(页表缓存)。
如果 TLB 命中,CPU 使用 TLB 中的物理地址直接访问 Cache。
如果 TLB 未命中,CPU 检查页表:
如果页表中的映射信息导致 Cache 命中,
如果页表中的映射信息导致 Cache 未命中,CPU 从主存中加载数据到 Cache,然后使用这些数据。
如果 Cache 未命中,CPU 直接从主存中加载数据。
10.2 内存的一些基础概念
网络Linux
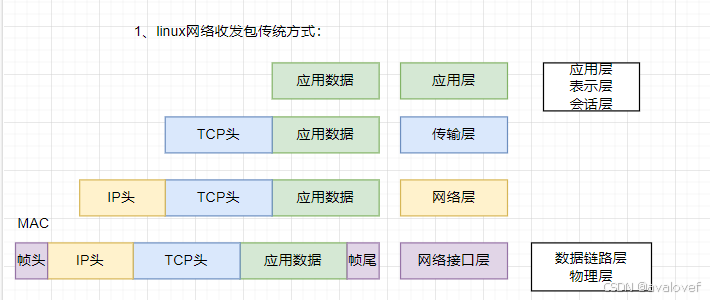
0、Linux网络收发
1、linux的收发包方式
处理发送数据,从应用层出发,到传输层加TCP头,后面再加IP头,到了接口层就加帧头帧尾,然后把数据传出去。
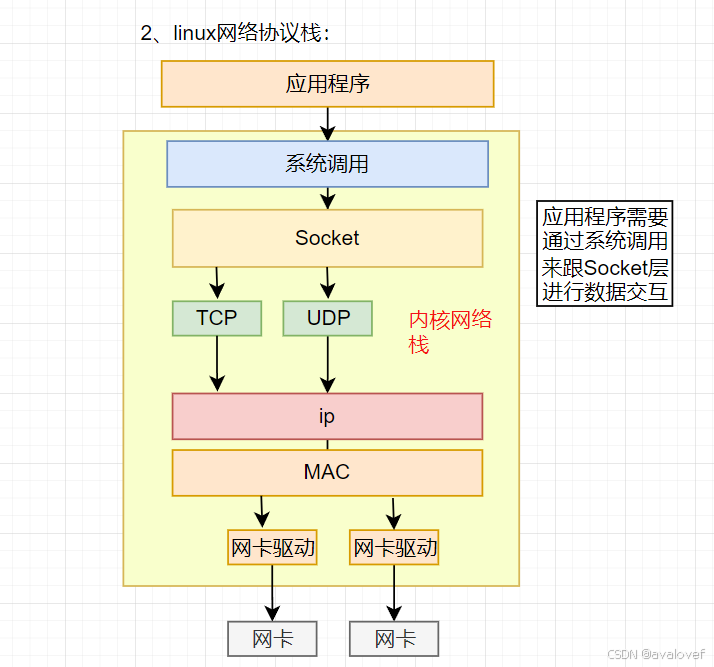
2、linux网络协议栈
3、网络包接收的过程
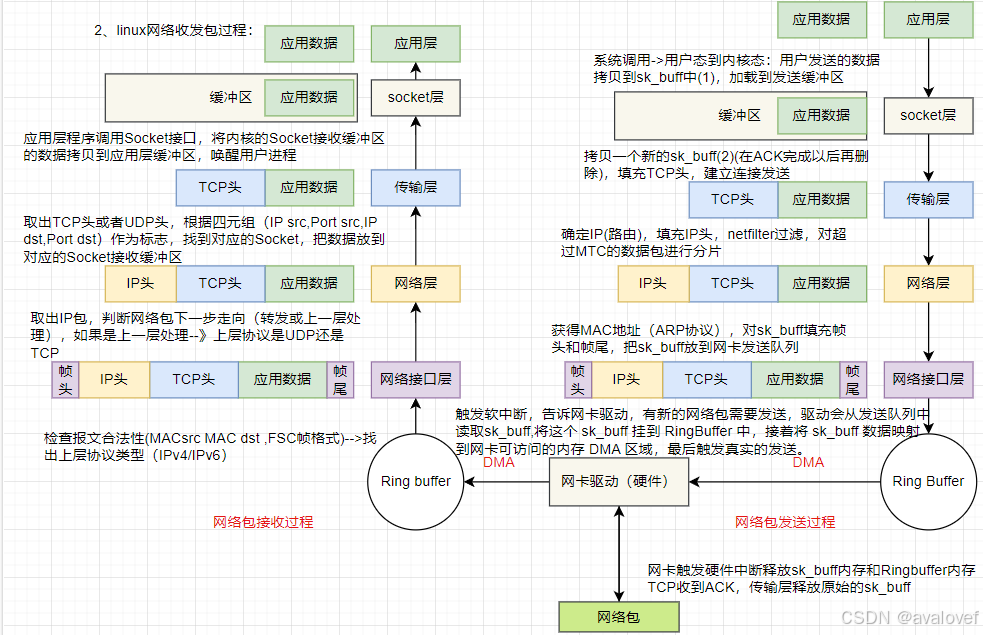
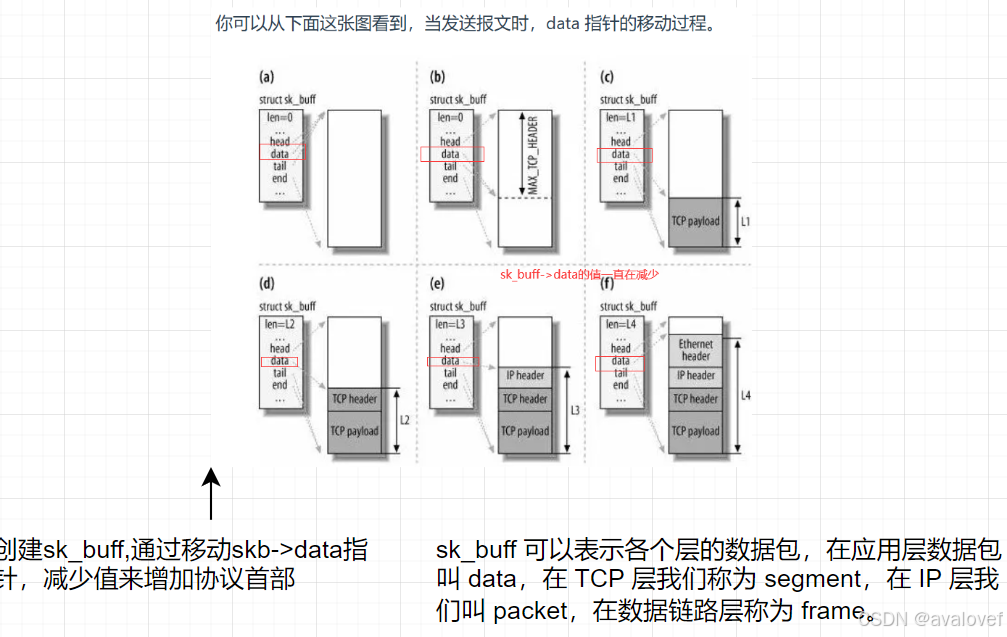
其中scocket buff 里面的data指针会一直移动:
2、典型的网络接口层
OSI七层模型:物理层、数据链路层、网络层、运输层、会话层、表示层、应用层.
TCP/IP四层模型:网络接入层、Internet层、传输层、应用层.
物理层:IEEE 802.3(以太网协议)、RJ45
数据链路层:HDLC 、 VLAN 、 MAC (网桥,交换机)、ARP(属于TCP/IP协议族)(在TCP/IP四层中属于网络层)
网络层: IP 、ICMP(互联网控制信息协议)、 (ARP 、 RARP) 工作内容在数据链路层
传输层: TCP、UDP
会话层: NFS(网络文件系统协议) 、 SQL、RPC(远程调用协议)
表示层: JPEG、MPEG
应用层: FTP (文本传输协议)、 DNS 、 Telnet(远程登录协议) 、 SMTP(简单邮件传输协议) 、 HTTP(超远文本传输协议) 、 NFS
3、网络四类地址的区间?
网络地址分为网络位和主机位。
A类地址:1.0.0.0 — 127.255.255.255(127.0.0.1为回环地址)(ping通本地回环地址说明本机协议没问题)
B类地址:128.0.0.0 — 191.255.255.255
C类地址:192.0.0.0 — 223.255.255.255
D类地址:224.0.0.0 — 239.255.255.255(广播地址)
4、 有关TCP的题目
4.0、TCP头的格式
TCP是面向连接的(一对一)、可靠的(TCP 都可以保证一个报文一定能够到达接收端)、字节流的(有序的)传输层通信协议,TCP是工作在传输层的可靠数据传输服务,他能确保接收端接收的网络包是无损坏、无间隔、非冗余和按序的。
TCP报头由10个必须字段(源端口号16位、目标端口号16位、序列号32位、确认号32位、报文长度4位、保留位与控制位各6位、窗口位16位、校验和16位、紧急指针16位)和一个可选字段,至少20个字节构成。
UDP由(源端口号、目标端口号、数据报长度、校验值)四部分组成,每个域各占两个字节,故UDP报头为8个字节。
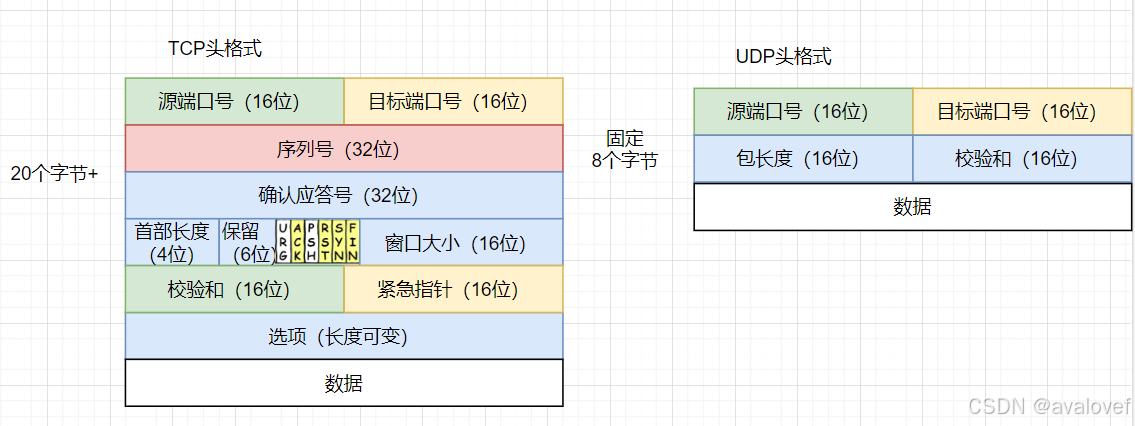
1、头拆解
TCP:序列号,初始值是随机数,通过SYN包传给接收数据,每发送一次,就累加一次该数据字节的大小。(防止网络包乱序)
确认应答号:防止丢包,发送一次以后ACK一下
首部长度:TCP有可变长的选项字段(但是UDP头部长度是不会变化的)所以TCP需要去记录一下首部长度
控制位:
ACK:该位为1,确定应答字段变有效,TCP表示除了最初建立连接的SYN包外,其他位之外该位必须置1.
RST:该位为 1 时,表示 TCP 连接中出现异常必须强制断开连接。
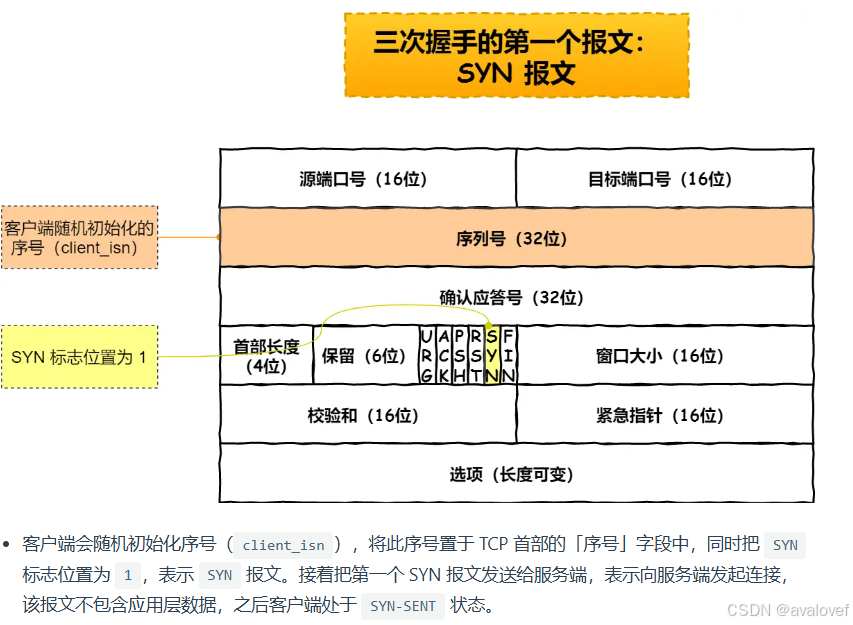
SYN:该位为 1 时,表示希望建立连接,并在其「序列号」的字段进行序列号初始值的设定。
FIN:该位为 1 时,表示今后不会再有数据发送,希望断开连接。
当通信结束希望断开连接时,双方的主机之间就可以相互交换 FIN 位为 1 的 TCP 段。
2、TCP连接的定义
TCP连接:用于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括Socket,序列号和窗口大小,称为连接。
(Socket:由 IP 地址和端口号组成、序列号:用来解决乱序问题等、窗口大小:用来做流量控制)
3、TCP四元组
源地址和目的地址的字段(32 位)是在IP 头部中,作用是通过IP协议发送报文给对方主机。.
源端口和目的端口的字段(16 位)是在TCP头部中,作用是告诉TCP协议应该把报文发给哪个进程。
最大的TCP 连接数= 客户端的IP数*客户端的端口数

4.1、简述TCP/UDP服务器端创建流程与客户端创建流程。
- TCP服务器端创建流程 :创建通信用文件描述符(socket)–>设置端口号和IP地址(为绑定做准备)–>绑定(bind)–>== 监听(listen)–>接受请求,建立连接(accept)==–>发送与接收消息(send/recv)–>关闭文件(close)
- TCP客户端创建流程:创建通信用文件描述符(socket)–>设置端口号和IP地址–>发起连接请求(connect)–>接受与发送消息(send/recv)–>关闭文件(close)
- UDP服务器端创建流程:创建通信用文件描述符(socket)–>设置端口号和IP地址(为绑定做准备)–>绑定(bind)–>接受和发送消息(sendto && recvfrom)–>关闭文件(close)
- UDP客户端创建流程:创建通信用文件描述符(socket)–>设置端口号和IP地址–>接受与发送消息(sendto && recvfrom)–>关闭文件
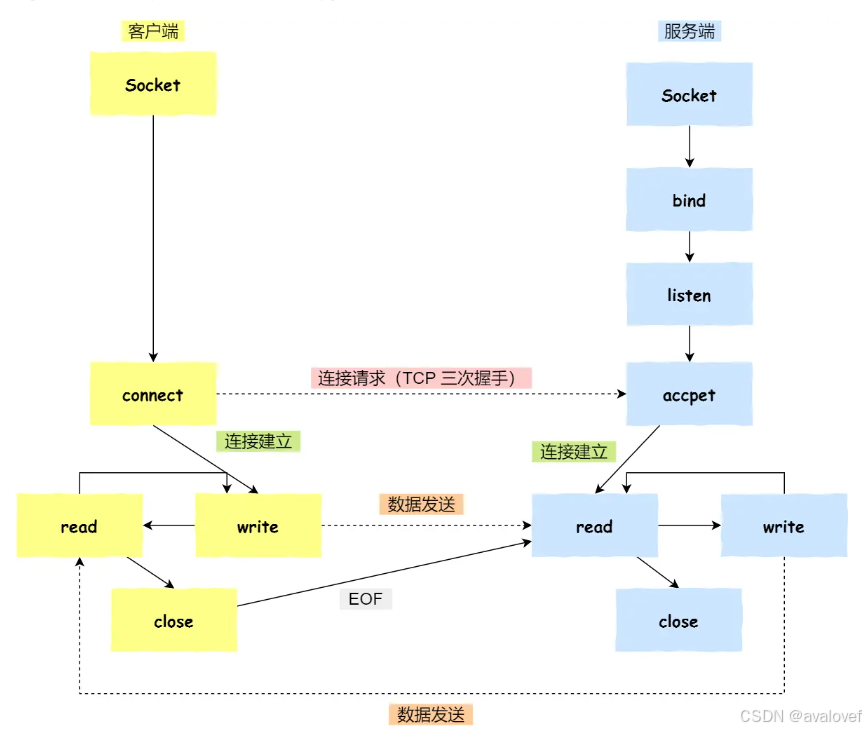
4.2、简述三次握手与四次挥手。
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接。
三次握手的过程:
一开始,客户端和服务端都处于close状态,先是服务端主动监听某个端口,处于Listen状态:
第一次握手:建立连接时,客户端发送SYN(SYN = j)包到服务器,并进入SYN_SEND状态,等待服务器的确认;
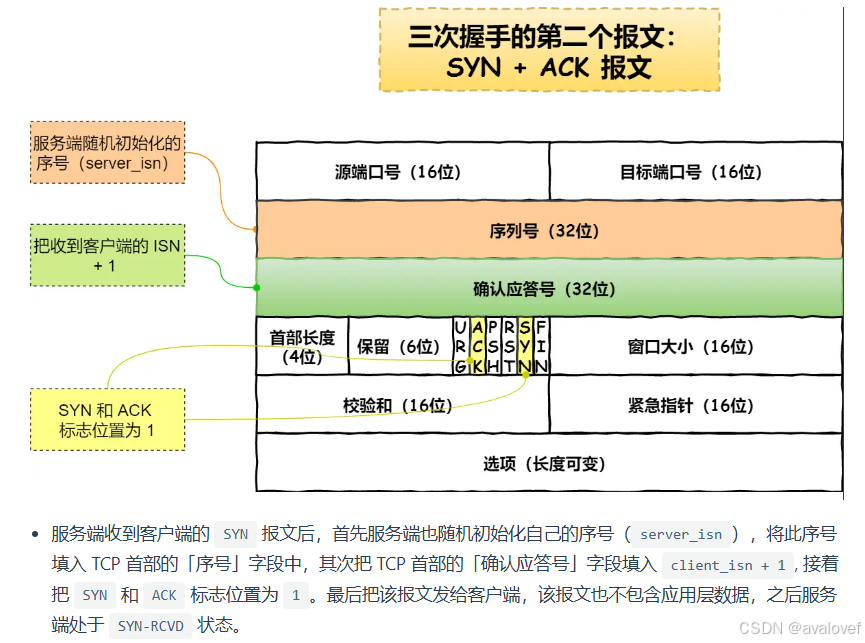
第二次握手:服务器收到SYN包,必须确认客户的SYN(ACK = j+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
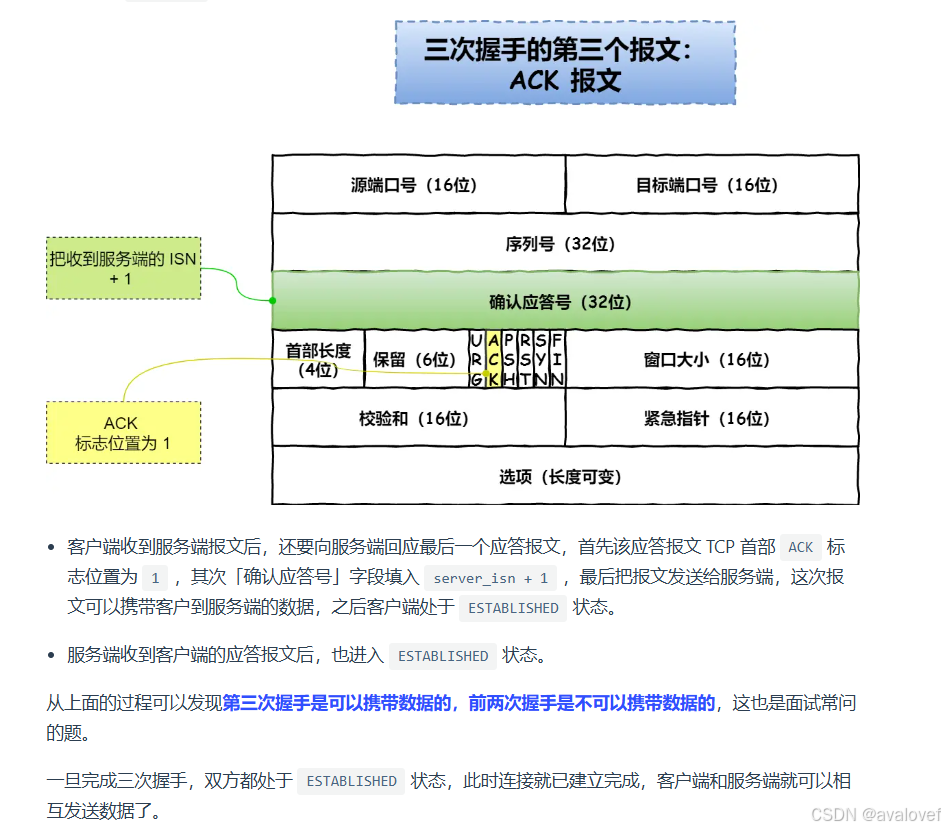
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ACK=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
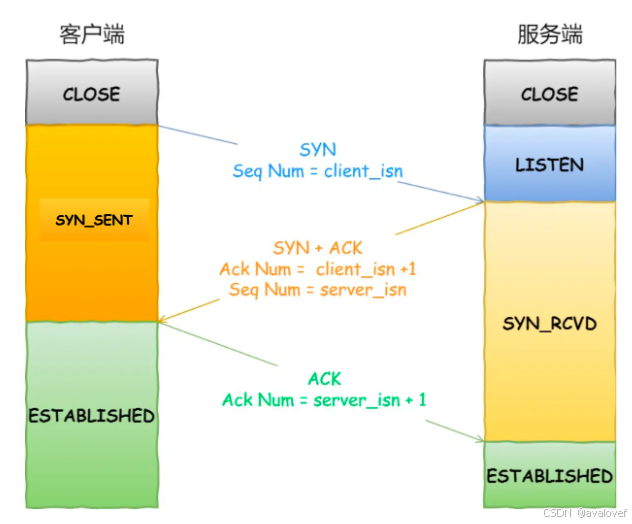
三次报文:
四次挥手的过程(客户端或服务器均可主动发起挥手动作):
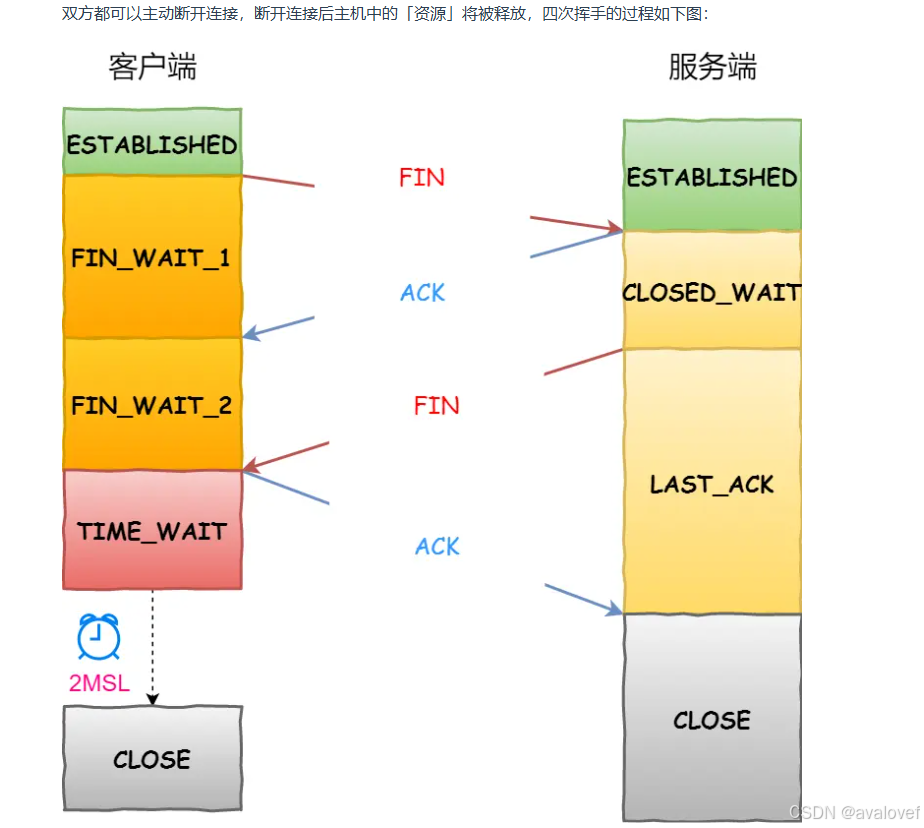
(1)客户端A发送一个FIN,用来关闭客户A到服务器B的数据传送。
(2)服务器B收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。
(和SYN一样,一个FIN将占用一个序号)。
(3)服务器B关闭与客户端A的连接,发送一个FIN给客户端A。
(4)客户端A发回ACK报文确认,并将确认序号设置为收到序号加1.
4.4、TCP 三次握手为什么不能是四次握手,两次握手?四次挥手为什么一定是四次?
TCP三次握手:
三次握手才可以阻止重复历史连接的初始化(主要原因) (重复发送以后,接收方根据ACK NUM 的正确性,发送RST报文终止连接)
三次握手才可以同步双方的初始序列号 (接收发送方都需要维护seq NUM)
三次握手才可以避免资源浪费(没有ACK,服务端每收到一个SYN就必须主动建立一个连接)
「两次握手」:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
「四次握手」:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
TCP四次挥手:
关闭连接的时候,客户端向服务端发送FIN,表示客户端不再发送数据,但是能接受数据。服务端收到客户端的FIN后,先收到了ACK以后,服务端需要处理数据和发送,所以会过一会儿再发送FIN包,后面客户端才会回复一个ACK.
4.5、如何在Linux系统中查看TCP状态
TCP的连接状态查看:在linux中可以通过netstat -napt 命令查看

4.6 TCP重传、滑动窗口、流量控制、拥塞控制
1)TCP重传:超时重传
2)滑动窗口:
由于发送方接收方收到需要ACK,如果发的数据量比较大的时候,等待时间就比较长。所以引入窗口,在串口内无需等待确认应答,可以继续发送数据的最大值。在发送方等待确认应答返回之前,必须在缓冲区保留已经发送的数据,如果按期收到确认应答,此时数据就可以从缓存区清除。
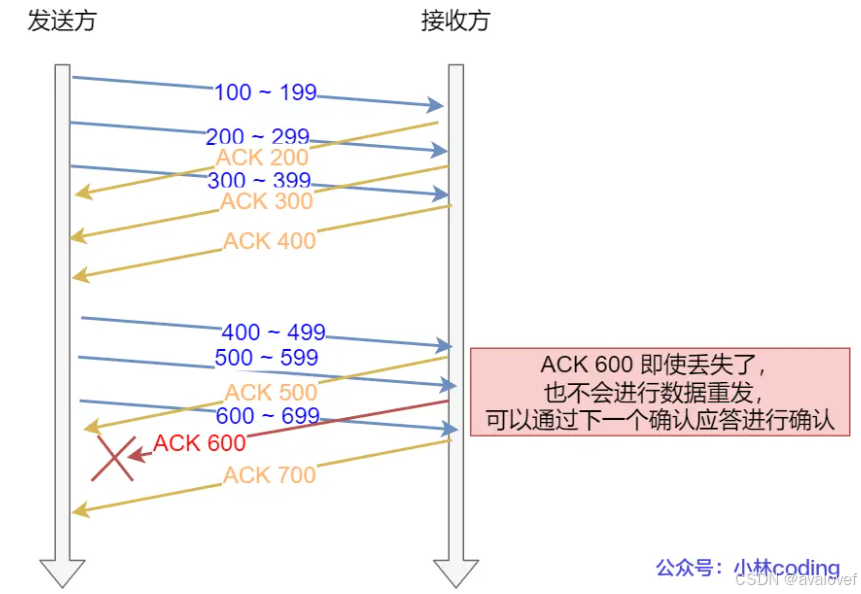
3)流量控制
4)拥塞控制
慢启动、拥塞避免、拥塞发生、快速回复
4.6 TCP粘包是如何产生的
5、TCP、UDP的区别
(1)TCP是面向连接的协议,UDP是面向无连接的协议。(UDP直接可以传数据)。
(2)TCP是一对一两点服务,UDP可以支持一对一,一对多,多对多的交互通信。
(3)TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按序到达,UDP 是尽最大努力交付,不保证可靠交付数据。
(4)TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
(5)TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是 20 个字节,如果使用了「选项」字段则会变长的。UDP首部只有8个字节。
(6)TCP 是流式传输,没有边界,但保证顺序和可靠。UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
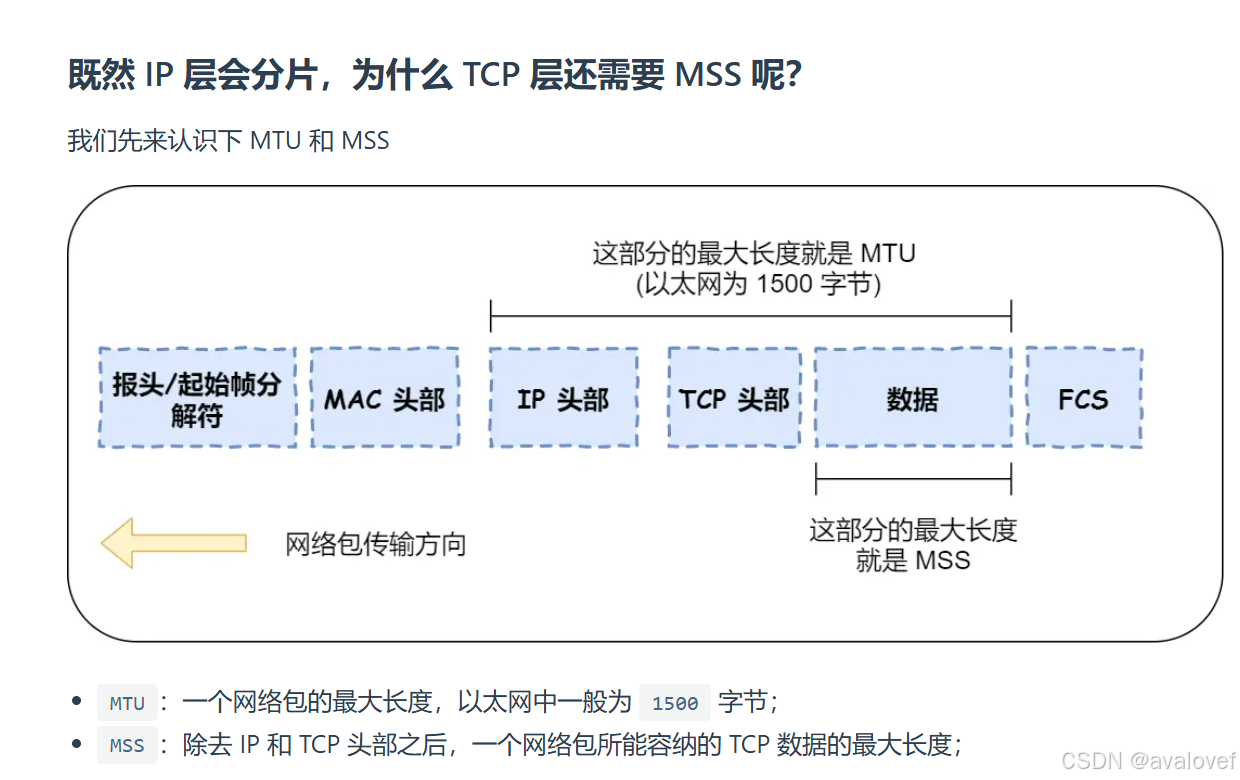
(7) TCP 的数据大小如果大于 MSS 大小,则会在传输层进行分片,目标主机收到后,也同样在传输层组装,TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。接着再传给传输层。
三次握手建立连接,四次挥手关闭连接: 这可以确保客户端与服务端都准备好传送数据后才开始.
校验和:TCP首部包含校验和字段,用于检验TCP报文内容是否发生变化,确保报文完整.
确认和重传机制:TCP每发送一个报文段后,会等待对方确认(ACK).如果超时未收到ACK,会重传该报文段.这可以确保报文到达.
流量控制:TCP使用滑动窗口来控制发送方的数据发送量,防止接收方来不及处理数据.这可以避免接收方的内存溢出.
序号:TCP为每个字节的数据分配一个序号,接收方按序号排列数据,这可以保证数据到达顺序.
所以,TCP具有完整性校验、流量控制、确认重传、序号排序等机制,这使其成为一种面向连接的可靠协议.
6、Linux内核功能
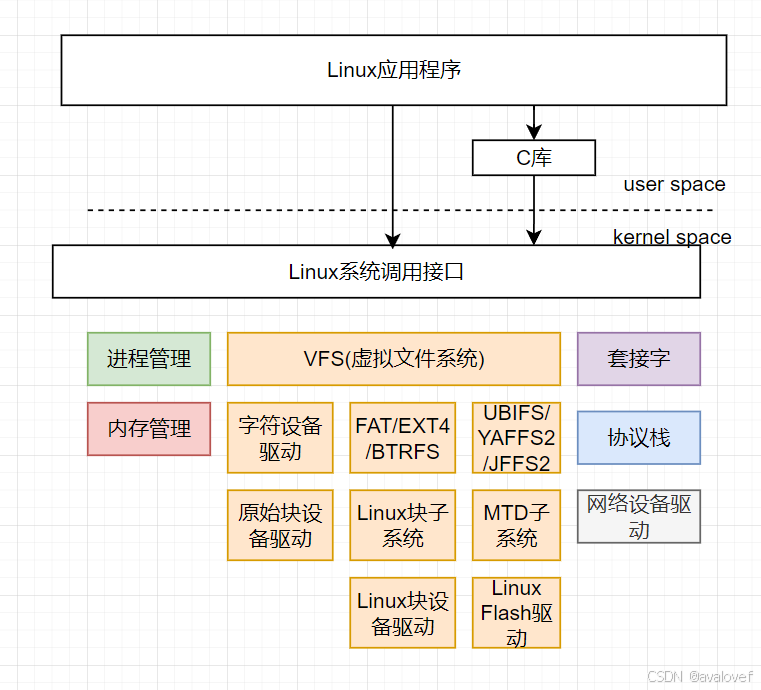
1、进程管理:多进程多线程那一套。
2、内存管理:cpu\mmu\TLB\页表\cache\ram
3、网络功能:套接字,socket通信,TCP/UDP
4、设备控制:字符设备、块设备、网络设备
5、文件系统管理:一切皆文件,VFS针对不同的文件提供统一的系统调用
MTD:memory Technology Device
6.1 Linux文件种类
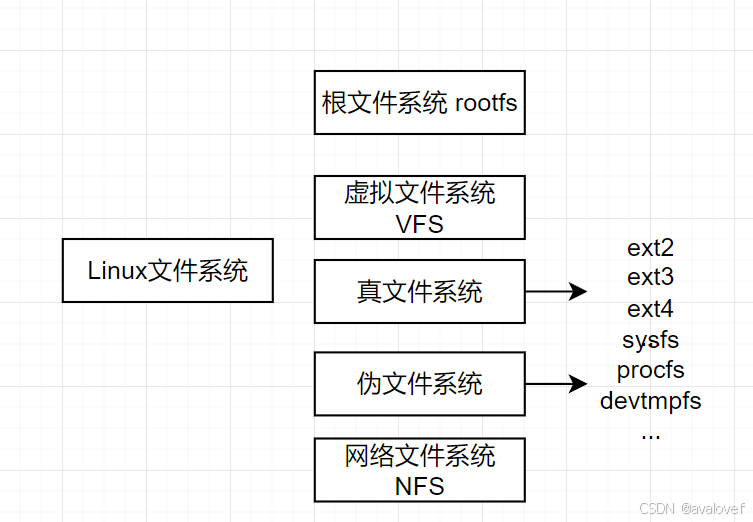
roofs根文件系统:是内核启动时mount的第一个文件系统。内核代码映射保存在根文件系中,bootloader会在根文件系统挂载之后从中把一些基本的初始化脚本和服务等加载到内存中。
6.2Linux基本的语法
1、chmod
chmod <数字> <文件或目录>
读权限:4 写权限:2 执行权限:1
对于 所有者u 组g 其他用户o:权限可以相加
chmod 755 <文件> :给文件所有者读写执行权限 给组和其他用户写和执行的无权限
2、grep
3、makefile
# 定义变量
CC = gcc
CFLAGS = -Wall
# 默认目标
all: hello
# 规则:hello 依赖于 main.o 和 utils.o
hello: main.o utils.o
$(CC) $(CFLAGS) main.o utils.o -o hello
# 规则:编译 main.c 为 main.o
main.o: main.c
$(CC) $(CFLAGS) -c main.c
# 规则:编译 utils.c 为 utils.o
utils.o: utils.c
$(CC) $(CFLAGS) -c utils.c
# 清理构建文件
clean:
rm -f hello main.o utils.o
# 伪目标
.PHONY: all clean
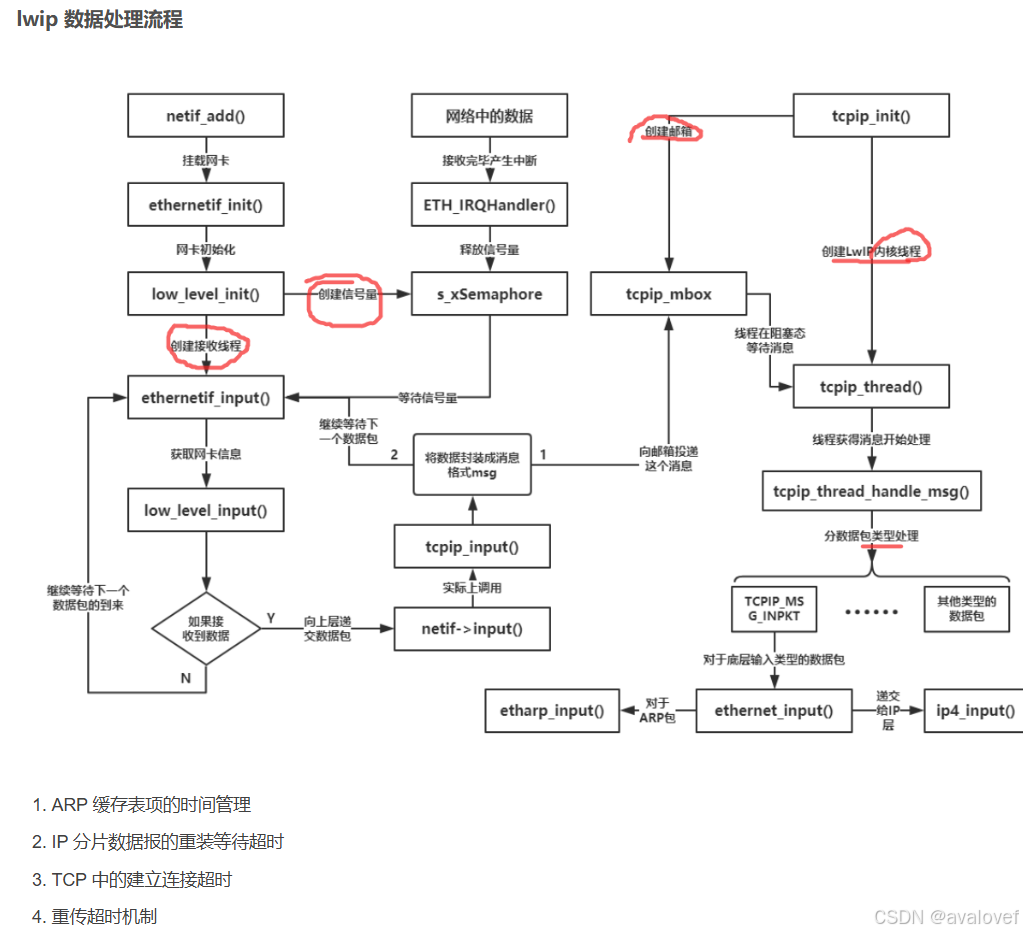
7、Lwip的原理
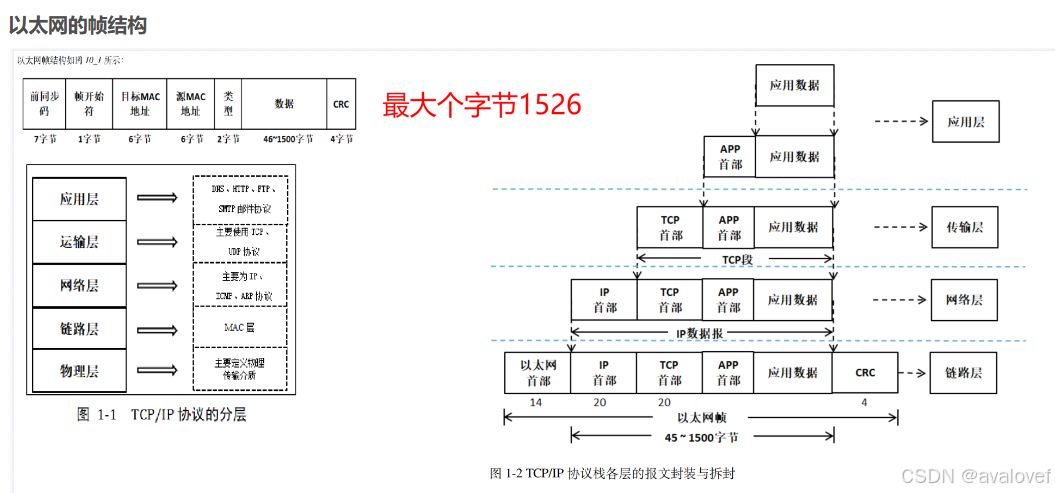
其中lwip 的结构图:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









