



简介
目的
1、数据传输:进程可以把数据给另一个进程。
2.资源共享:多个进程之间共享相同的资源
3.通知事件:进程可以向另一个或者一组进程发送消息,通知发生了某事。比如子进程终止时要通知父进程。
4.进程控制:有些进程完全控制另一个进程的执行时,进程可以帮另一个进程拦截所有陷入和异常,并能够及时知道它的状态。
注:进程间通信的前提是:不同进程间可以看到同一份资源。
发展
1.管道
* 匿名管道pipe
* 命名管道
2.System V进程间通信
* System V 消息队列
* System V共享内存
* System V信息量
3.POSIX进程间通信
* 消息队列
* 共享内存
*信息量
* 互斥量
* 条件变量
* 读写锁
今天主要讲前面两种——管道和System V进程通信。
管道
含义
管道是Unix中最古老的进程通信方式,我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”。
在之前的学习中我们运用到了一条命令:
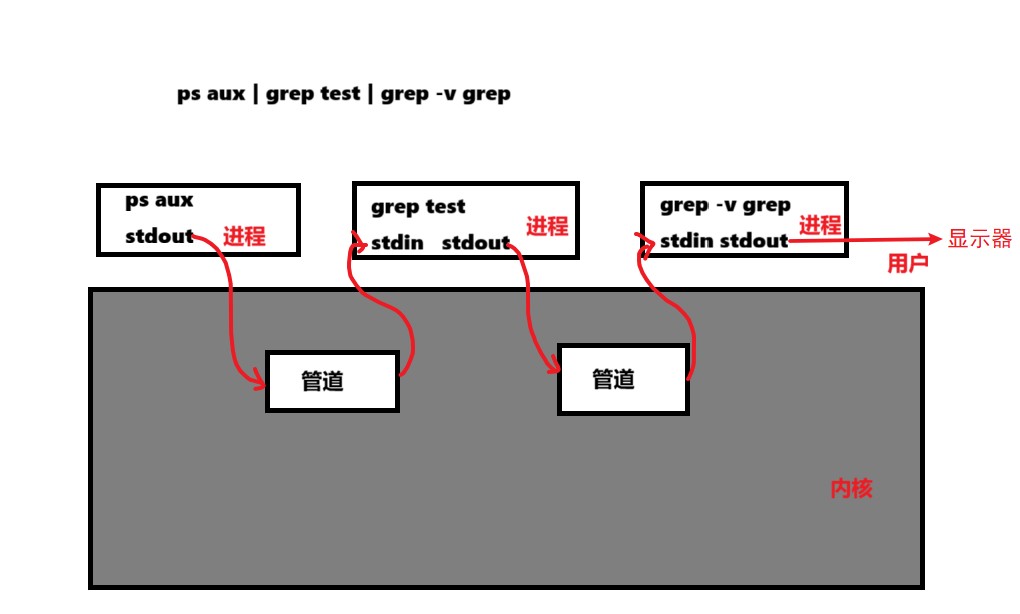
ps aux| grep test | grep -v grep;
在这条命令中我们运用到了管道(“|”),这条命令就是把ps命令的内容放入到管道中,管道通过标准输入,输入到grep命令中,进行grep命令,再把处理好的文件打印到显示器上。
父进程执行ps aux,子进程执行grep命令,所以这条命令相当于父子进程间通信。
而父子间能够看到同一份资源,是因为shell创建一个管道,让父进程的标准输出(stdout)和子进程的标准输入(stdin)都指向这个管道,从而实现数据的传递——这本质上就是父子进程共享了“管道”这份资源。
这种管道也称为匿名管道。
匿名管道
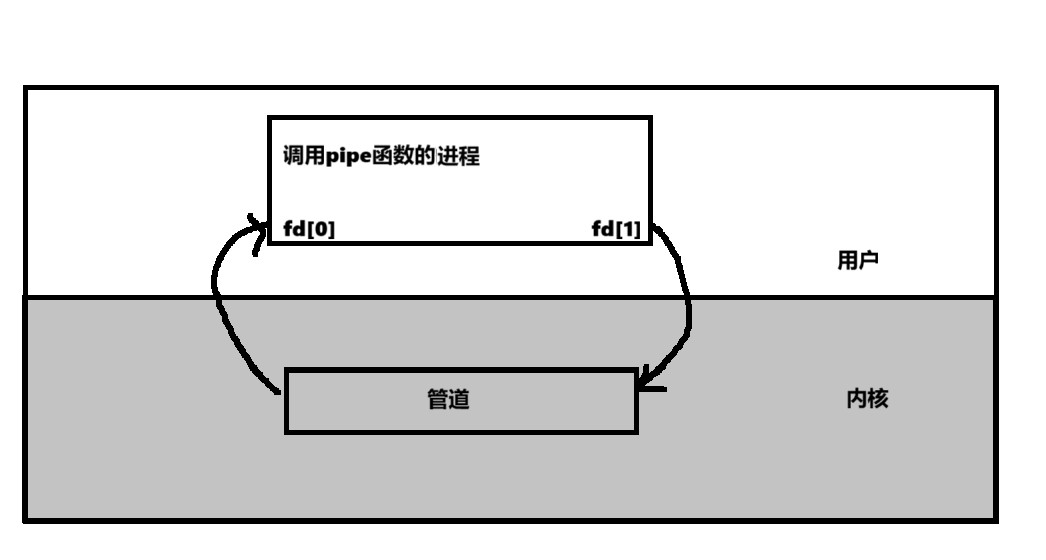
创建匿名管道
#include <unistd.h>
int pipe(int pipefd[2]);
功能:创建一无名管道参数:文件描述符数组,其中fd[0]表示读端,fd[1]表示写端
返回值:成功返回0,失败返回错误代码
一般只有“血缘关系”的进程才能创建匿名管道。通常是父子进程、兄弟进程。
实例:父进程从键盘中读数据并写入管道,子进程读取管道写到显示器上。
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
int fds[2];
int ret=pipe(fds);
pid_t id=fork();//在创建管道之后才能创建子进程,因为子进程要继承父进程的管道描述符
if(ret!=0)
{
perror("pipe");
return 1;
}
char buf[100];
char str[100];
int len=sizeof(buf);
memset(buf,0x00,sizeof(buf));
if(id==0)
{
//子进程
close(fds[1]);
ssize_t n;
while((n=read(fds[0],buf,len-1))>0)
{
buf[n]='\0';
printf("%s",buf);
}
close(fds[0]);
return 0;
}
else if (id>0)
{
//父进程
close(fds[0]);
while(fgets(str,100,stdin))
{
len=strlen(str);
if(write(fds[1],str,len)!=len)
{
perror("write");
break;
}
}
close(fds[1]);
wait(NULL);
}
else
{
perror("fork");
return 1;
}
return 0;
}
父子进程关闭其中一个端口的底层原理:
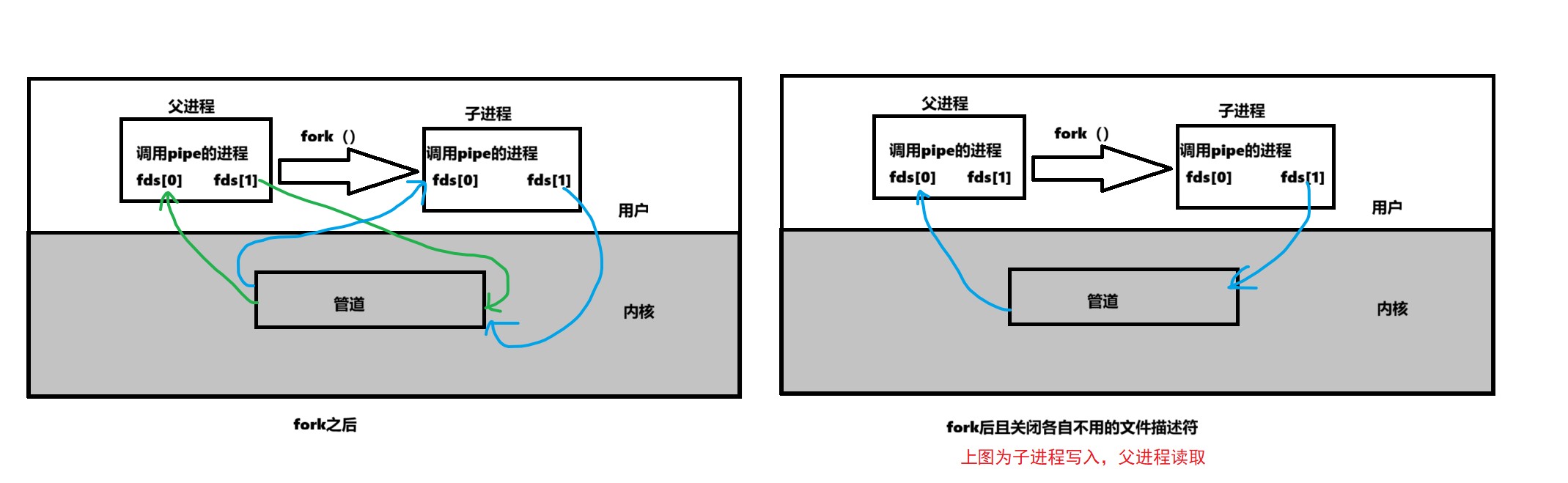
如何记住写端是fds[1],读端是fds[0]?
就把它想象成一支笔,可以写字;而0就想象成张着的嘴巴,正在读书。
底层原理
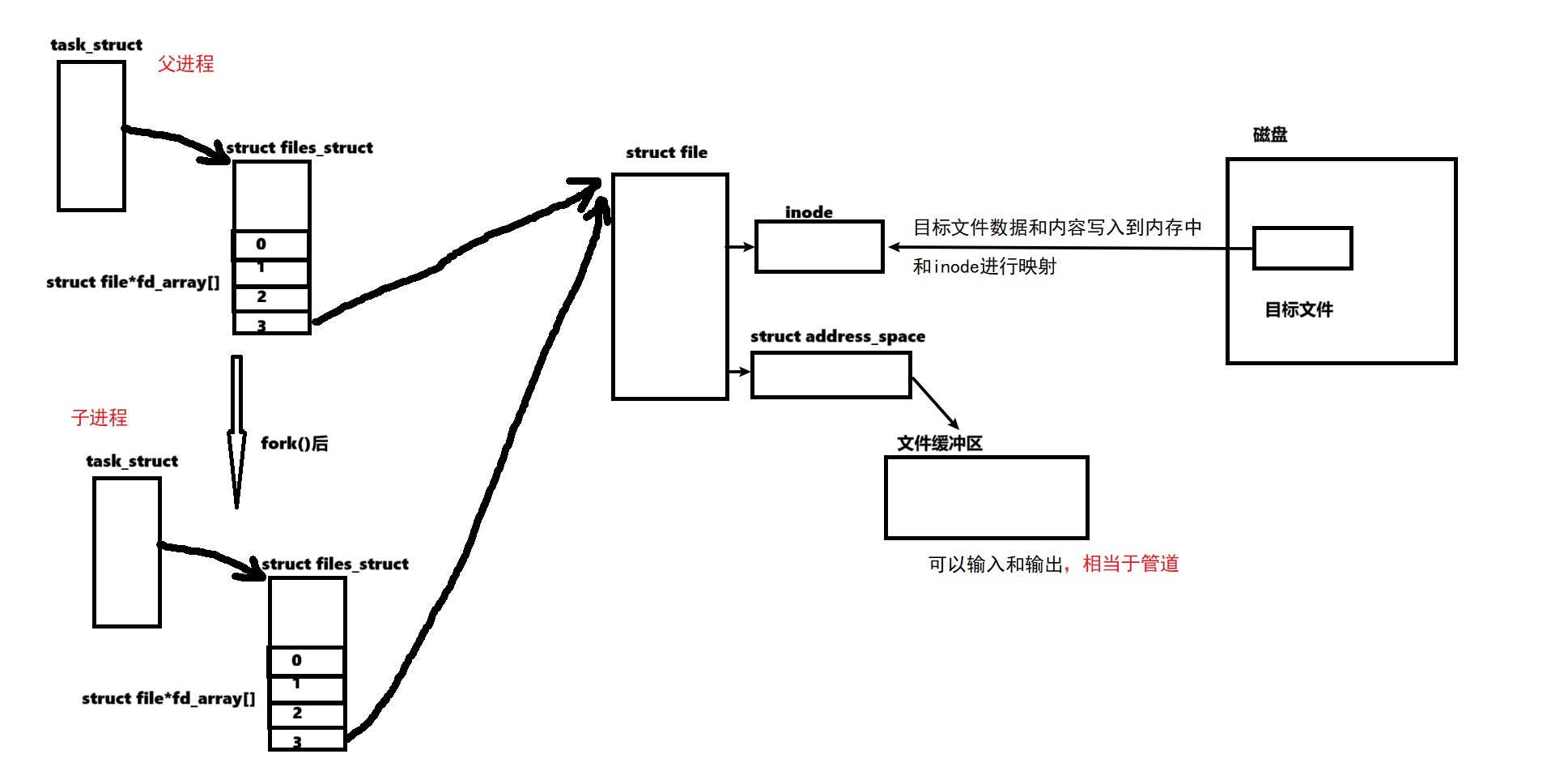
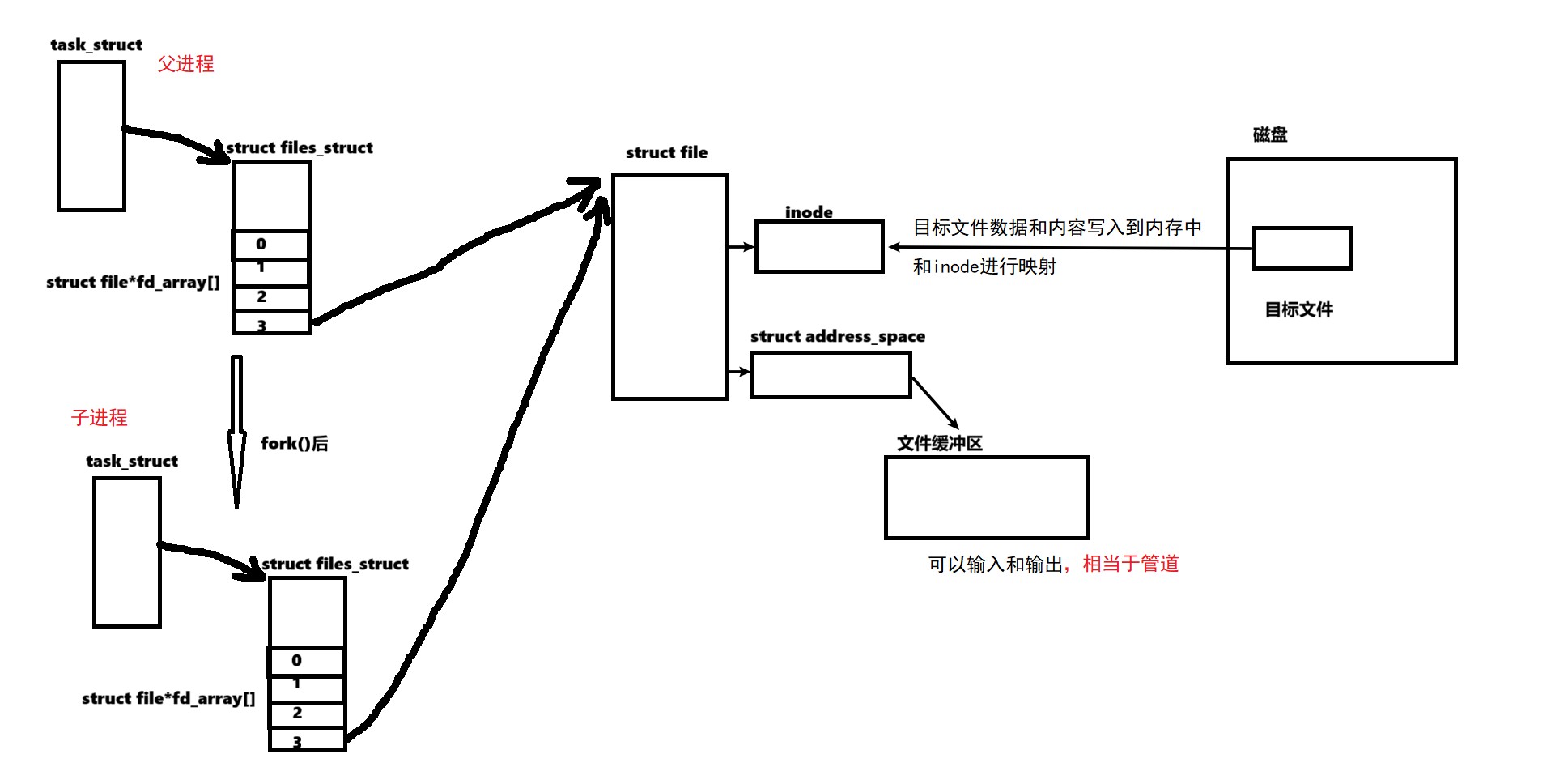
从文件描述符的角度——父子进程进行通信的底层原理:
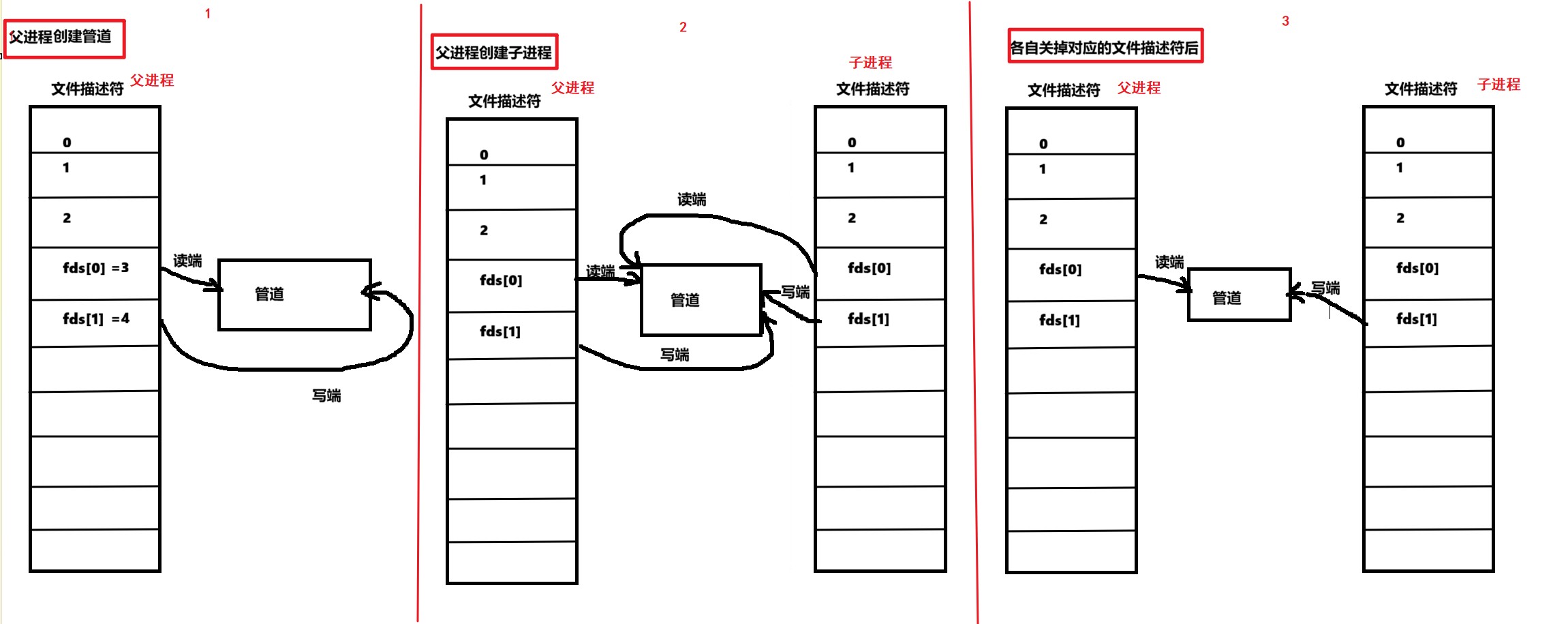
内核角度
关闭各自的文件描述符后,管道形成了一个单向通信的通道,可以防止误操作。
匿名管道的五大特性
1.常用与血缘关系的进程,进行进程间通信,通常为父子进程,兄弟进程
2.单向通信
3.管道的生命周期随进程。管道的生命周期结束的标志是:所有引用它的文件描述符被关闭。即进程终止,管道也被销毁。
4.面向字节流。写入数据时,若缓冲区已满,写操作会阻塞(默认阻塞模式);读取数据时,若缓冲区为空,读操作会阻塞,直到有数据写入或写端关闭。
5.管道自带同步机制。即读写端状态同步。
管道的读写规则
当没有数据可读时
O_NONBLOCK disable(关闭管道的非阻塞模式):read调用阻塞,即进程暂停执行,一直等到有数据来到为止。
O_NONBLOCK enable(开启管道的非阻塞模式):read调用返回-1,errno值为EAGAIN。
当管道满的时候
O_NONBLOCK disable:write调用阻塞,直到有进程读走数据
O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
如果所有管道写端对应的文件描述符被关闭,则read返回0
如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
匿名管道的四种情况
1.管道满了,写端持续写入。
结果:写满了就不再写入,写端被阻塞。
原因:管道的空间有限,最大为65536字节。
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#define Dug 1024
int main()
{
int count=0;
int fds[2];
if((pipe(fds))==-1)
{
perror("pipe");
return 1;
}
char buf[Dug];
memset(buf,'a',Dug);
while(1)
{
write(fds[1],buf,1);
count++;
printf("count=%d\n",count);
}
close(fds[0]);
close(fds[1]);
}
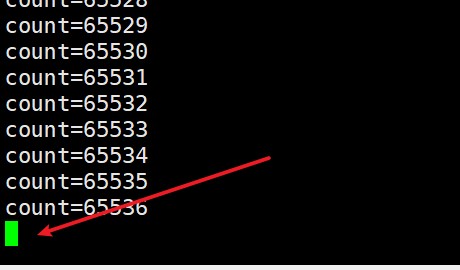
2.管道空了,读端持续读取。
结果:读端会被阻塞。
原因:阻塞机制是管道自带的同步特性,确保读进程不会“空读”无效数据。
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#define Dug 1024
int main()
{
int fds[2];
if((pipe(fds))==-1)
{
perror("pipe");
return 1;
}
char buf[Dug];
while(1)
{
read(fds[0],buf,1);
}
close(fds[0]);
close(fds[1]);
}

3.写端关闭,读取正常读取。
结果:read读取到文件结尾就返回0。
原因:内核通过返回0通知写端终止,避免读进程无限阻塞等待数据。
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#define Dug 24
int main()
{
int ret=0;
int fds[2];
if((pipe(fds))==-1)
{
perror("pipe");
return 1;
}
char buf[Dug];
memset(buf,'a',Dug);
write(fds[1],buf,Dug);
close(fds[1]);
char str[Dug];
while(1)
{
ssize_t n=read(fds[0],&str[ret],1);
if(n==0)
{
printf("一共读取了 %d \n",ret);
break;
}
else if(n==-1)
{
perror("read");
break;
}
else {
ret++;
if(ret>Dug)
{
break;
}
}
}
printf("%s\n",str);
close(fds[0]);
return 0;
}
结果:
[root@localhost d3]# ./test_pipe
一共读取了 24
aaaaaaaaaaaaaaaaaaaaaaaa
4.读端关闭,写端正常写入。
结果:内核会向进程发送SIGPIPE信号,让进程终止,同时write()返回错误码EPIPE(“管道破裂”)
原因:管道的写操作依赖读端存在,若读端已全部关闭,数据写入后无人接收,导致资源浪费。
创建线程池处理任务
线程池中父进程通过管道给子进程发布任务,任务的最终结果要反馈给父进程。但是当没有任务时子进程可以忙自己的事情。
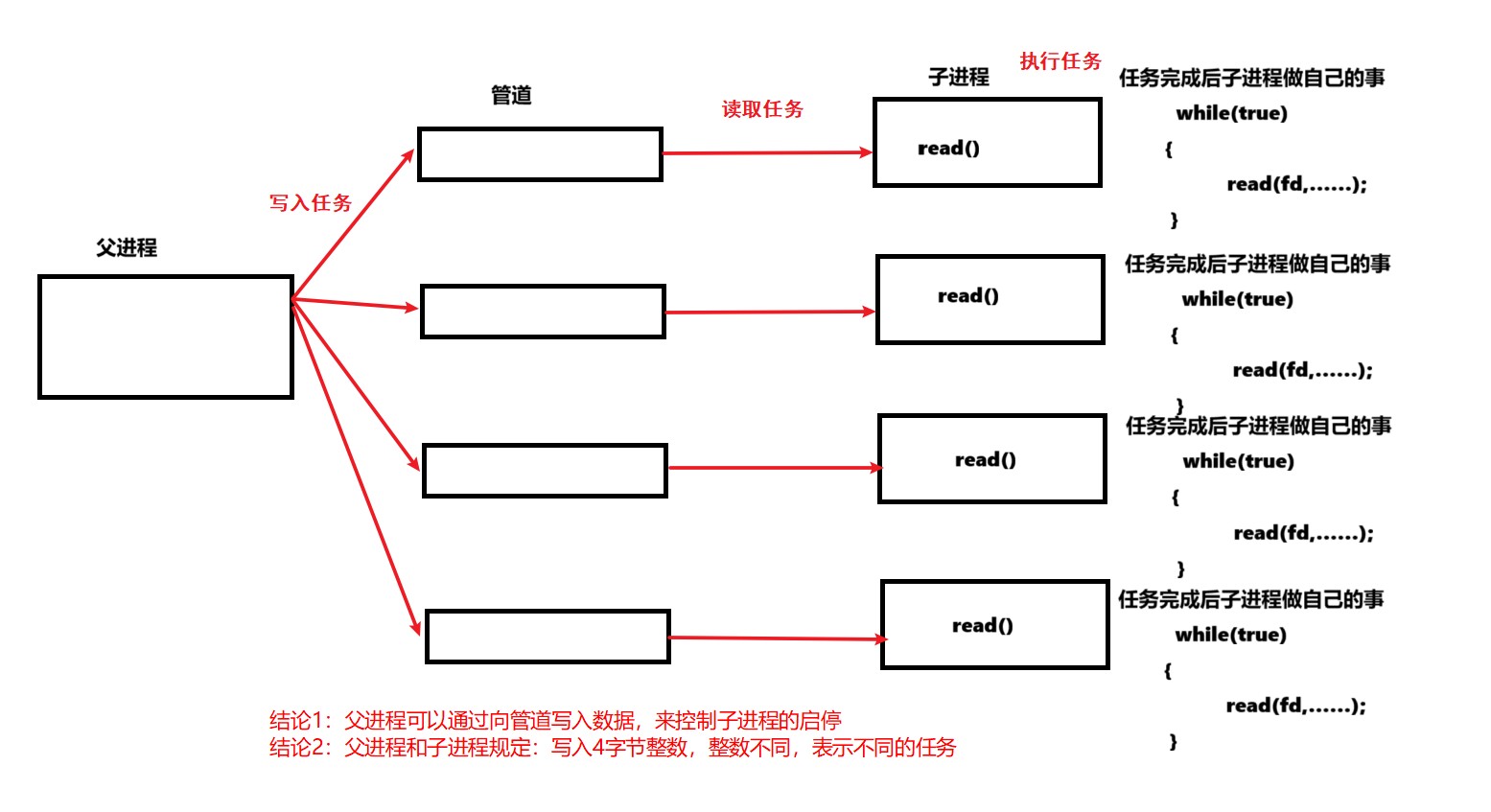
ProcessPool.hpp
#ifndef _PROCESS_POOL_HPP_
#define _PROCESS_POOL_HPP
#include<iostream>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<string>
#include<vector>
#include<cstdlib>
#include<time.h>
#include"task.hpp"
#include<functional>
const int gdefault_process_num=5;
//typedef std::funtion<void(int fd)> callback_t;
//只要返回值是void类型,参数是fd类型的参数
using callback_t=std::function<void(int fd)>;
//描述通道
class Channel
{
public:
Channel()
{}
Channel(int fd,std::string name,pid_t target):_wfd(fd),_name(name),_sub_target(target){}
int Fd(){return _wfd;}
std::string Name(){return _name;}
pid_t Target(){return _sub_target;}
void Close(){close(_wfd);}
void Wait()
{
int ret=waitpid(_sub_target,nullptr,0);
(void)ret;//消除“未使用变量”的编译警告
}
private:
int _wfd;//读写端进程描述符
std::string _name;//管道名
pid_t _sub_target;//管道对应的目标子进程
};
//线程池
class ProcessPool
{
private:
void CtrlSubProcessHelper(int& index)
{
//选择一个管道
int who=index;
index++;
index%=_Channels.size();
//选择一个任务
int x=rand()%tasks.size();
//任务推送给子进程
std::cout<<"选择管道"<<_Channels[who].Name()<<",subtarget:"<<_Channels[who].Target()<<std::endl;
write(_Channels[who].Fd(),&x,sizeof(x));//把x写入管道
sleep(1);
}
public:
ProcessPool(int num=gdefault_process_num):processnum(num)
{
//确保子进程ID随机
srand(time(nullptr)^getpid()^0x777);
}
~ProcessPool(){}
//初始化线程池
bool InitProcessPool(callback_t cb)
{
for(int i=0;i<processnum;i++)
{
//创建管道
int pipefd[2];
if(pipe(pipefd)<0)
{
return false;
}
//创建子进程
pid_t id=fork();
if(id<0)
{
return false;
}
else if(id==0)
{
//子进程读取任务
close(pipefd[1]);
cb(pipefd[0]);//从pipefd[0]中读取类型为void,形参为int的类型的函数
exit(0);
}
else
{
//父进程
close(pipefd[0]);
std::string name="Channel-"+std::to_string(i);//每个通道命名为Channel-1等;
_Channels.emplace_back(pipefd[1],name,id);//把初始化了的管道写入
}
}
return true;
}
//2.控制唤醒指定的子进程,让子进程完成指定任务
//有五个子进程,可以用轮询的方式来提高完成效率
//不指定任务的个数
void PollingCtrlSubProcess()
{
int index=0;
while(true)
{
CtrlSubProcessHelper(index);
}
}
//指定任务个数
void PollingCtrlSubProcess(int count)
{
if(count<0)
{
return ;
}
int index=0;
while(count--)
{
CtrlSubProcessHelper(index);
}
}
//等待子进程退出
void WaitSubProcess()
{
for(auto &c:_Channels)
{
c.Close();
}
for(auto&c:_Channels)
{
c.Wait();
}
}
private:
//组织管道
std::vector<Channel> _Channels;//管道
int processnum;//子进程数量
};
#endif
task.hpp
#pragma once
#include<iostream>
#include<functional>
#include<vector>
using task_t=std::function<void()>;
using namespace std;
void Download()
{
cout<<"这是一个下载任务"<<endl;
}
void MySql()
{
cout<<"这是一个MySql任务"<<endl;
}
void Sync()
{
cout<<"这是一个数据刷新同步任务"<<endl;
}
void Log()
{
cout<<"这是一个日志保存任务"<<endl;
}
std::vector<task_t> tasks;
class Init
{
public:
Init()
{
tasks.push_back(Download);
tasks.push_back(MySql);
tasks.push_back(Sync);
tasks.push_back(Log);
}
};
Init ginit;
main.cc
#include"ProcessPool.hpp"
int main()
{
//1.创建进程池
ProcessPool pp(5);
//2.初始化进程池
pp.InitProcessPool([](int fd){
while(true)
{
int code=0;//任务码
ssize_t n=read(fd,&code,sizeof(code));
if(n==sizeof(code))
{
std::cout<<"子进程被唤醒,getpid为"<<getpid()<<std::endl;
if(code>=0&&code<tasks.size())
{
tasks[code]();
}
else
{
std::cerr<<"任务码不正确"<<endl;
}
}
else if(n==0)
{
std::cout<<"子进程应该退出了:geipid="<<getpid()<<std::endl;
break;
}
else
{
std::cerr<<"read fd:"<<fd<<",error"<<std::endl;
break;
}
}
});
//3.控制线程池
pp.PollingCtrlSubProcess(10);
//4.结束线程池
pp.WaitSubProcess();
std::cout<<"父进程控制子进程完成,父进程结束"<<std::endl;
return 0;
}
makefile
processpool:main.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f processpool
命名管道
它可以在两个不相干的进程之间交换数据,这是和匿名管道之间的主要区别。
而且命名管道是一个特殊的文件。
创建命名管道
有两种方法可以实现:
1.在命令行上输入命令
mkfifo filename
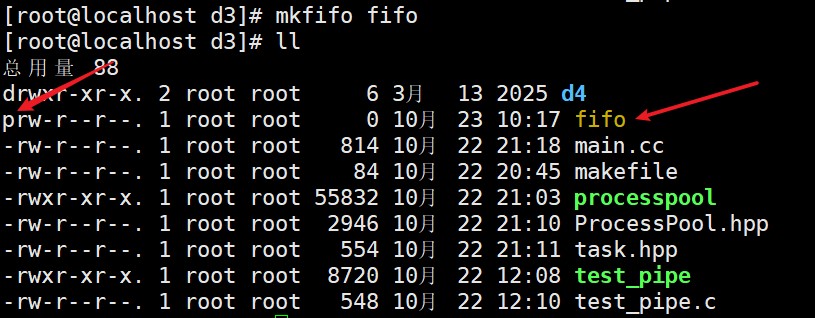
2.在程序中创建,相关函数有:
int mkfifo (const char *filename , mode_t mode );
//mode是文件的权限
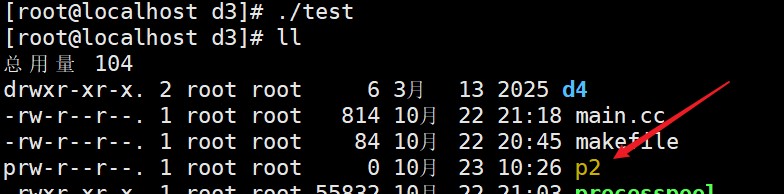
实例:
#include<stdio.h>
int main()
{
mkfifo("p2",0644);
return 0;
}
匿名管道和命名管道的区别
1.匿名管道本质上是个文件缓冲区,而命名管道本质上是个特殊文件。
2.匿名管道直接用pipe函数创建并打开,命名管道用mkfifo函数创建,用open函数打开。
3.匿名管道是两个有“血缘关系”的两个进程间的通信,命名管道是用于两个不相干的进程之间的通信。
管道的读写规则
如果当前打开操作是为读而打开FIFO时
O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO
O_NONBLOCK enable:立刻返回成功
如果当前打开操作是为写而打开FIFO时
O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO
O_NONBLOCK enable:立刻返回失败,错误码为ENXIO
用命名管道实现文件拷贝
把文件中的内容写入管道
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<string.h>
int main()
{
int infd=open("abc",O_CREAT|O_TRUNC|O_WRONLY,0644);
if(infd<0)
{
perror("open");
return 1;
}
char buf[1024];
memset(buf,'a',1024);
write(infd,buf,1024);
close(infd);
int in=open("abc",O_RDONLY);
if(in<0)
{
perror("open");
return;
}
mkfifo("tb",0644);
char str[102];
int fd=open("tb",O_WRONLY);
int n;
while((n=read(in,str,sizeof(str)-1))>0)
{
write(fd,str,n);
}
close(in);
close(fd);
return 0;
}
如果没有进程读取,该写端就会阻塞。
另一个文件读取管道
#include<stdio.h>
#include<unistd.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{
int out =open("abc.txt",O_WRONLY|O_CREAT|O_TRUNC,0644);
int fd=open("tb",O_RDONLY);
if(out<0||fd<0)
{
perror("open");
return ;
}
char str[102];
int n;
while((n=read(fd,str,sizeof(str)-1))>0)
{
write(out,str,n);
}
close(out);
close(fd);
return 0;
}
两个进程分别在两个终端执行,一个把内容传入到管道,一个把管道中的内容传入文件。
System V共享内存
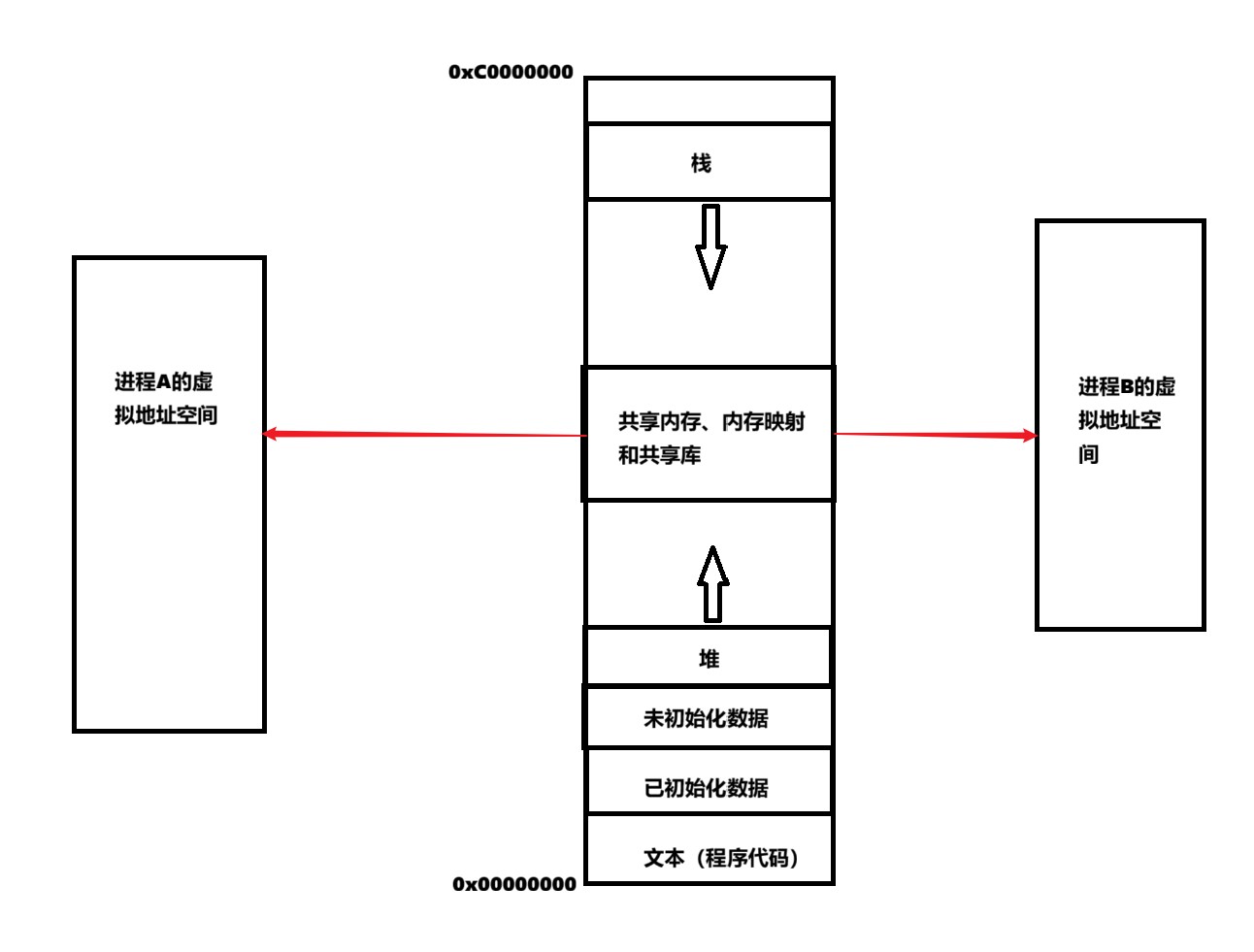
System V共享内存的原理是:将内核的一块物理内存映射到多个进程的虚拟地址空间,使进程无需通过内核即可直接读写共享数据,从而实现高效通信。
共享内存的数据结构
struct shmid_ds
{
struct ipc_perm shm_perm; // 权限控制(关键字段)
size_t shm_segsz; // 共享内存段大小(字节)
pid_t shm_lpid; // 最后操作该段的进程ID
pid_t shm_cpid; // 创建该段的进程ID
shmatt_t shm_nattch;// 当前附加(映射)的进程数
time_t shm_atime; // 最后一次附加(shmat)的时间
time_t shm_dtime; // 最后一次分离(shmdt)的时间
time_t shm_ctime; // 最后一次修改的时间
// 其他填充字段...
};
共享内存的函数
shmget函数
原型
#include<sys/shm.h>
#include<sys/ipc.h>
int shmget(key_t key, size_t size, int shmflg);
参数
key: 这个共享内存段名字,通过ftok函数获取。
#include <sys/ipc.h>
key_t ftok(const char *pathname, int proj_id);
size: 共享内存大小
shmflg: 由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的
- 取值为IPC_CREAT:共享内存不存在,创建并返回;共享内存已存在,获取并返回。
- 取值为IPC_CREAT | IPC_EXCL:共享内存不存在,创建并返回;共享内存已存在,出错返回。
返回值:成功返回一个非负整数,即该共享内存段的标识码;失败返回-1
shmat函数
功能:将共享内存段连接到进程地址空间
原型
#include<sys/ipc.h>
#include<sys/types.h>
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数
shmid: 共享内存标识
shmaddr: 指定连接的地址
shmflg: 它的两个可能取值是SHM_RND和SHM_RDONLY,0表示可读可写
返回值:成功返回指向共享内存第一个节的指针;失败返回-1
说明:
- shmaddr为NULL,核心自动选择一个地址
- shmaddr不为NULL且shmflg无SHM_RND标记,则以shmaddr为连接地址
- shmaddr不为NULL且shmflg设置了SHM_RND标记,则连接的地址会自动向下调整为SHMLBA的整数倍。公式:shmaddr - (shmaddr % SHMLBA)
- shmflg=SHM_RDONLY,表示连接操作用来只读共享内存
shmdt函数
功能:将共享内存段与当前进程脱离
原型
#include <sys/types.h>
#include <sys/shm.h>
int shmdt(const void *shmaddr);
参数
shmaddr: 由shmat所返回的指针
返回值:成功返回0;失败返回-1
注意:将共享内存段与当前进程脱离不等于删除共享内存段
shmctl函数
功能:用于控制共享内存
原型
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数
shmid: 由shmget返回的共享内存标识码
cmd: 将要采取的动作(有三个可取值)
buf: 指向一个保存着共享内存的模式状态和访问权限的数据结构
返回值:成功返回0;失败返回-1
cmd的三个取值:
| 命令 | 说明 |
| IPC_STAT | 把shmid_ds结构中的数据设置为共享内存的当前关联值 |
| IPC_SET | 在进程有足够权限的前提下,把共享内存的当前关联值设置为shmid_ds数据结构中给出的值 |
| IPC_RMID | 删除共享内存段 |
总结:共享内存通信的总流程
1.生成键值:ftok函数
2.创建/获取共享内存:shmget函数
3.连接到内存:shmat函数
4.进程间通信
5.分离共享内存:shmdt函数
6.删除共享内存:shmctl函数
共享内存实现进程通信
A进程读取,B进程写入。 B进程创建共享内存,先写入,防止遗漏字母或者打印乱码。
//shm.cpp
#ifndef __SHM_HPP__
#define __SHM_HPP__
#include<iostream>
#include<sys/ipc.h>
#include<sys/shm.h>
#include<string>
#include<cstdio>
std::string pathname=".";
int gproj_id=0x66;
int gdefaultsize=4096;//4KB,共享内存的大小
class SharedMemory
{
private:
bool CreatHelper(int flags)
{
//获取键值,shmget的第一个参数
_key=ftok(pathname.c_str(),gproj_id);
if(_key<0)
{
perror("ftok");
return false;
}
_shmid=shmget(_key,_size,flags);
if(_shmid<0)
{
perror("shmget");
return false;
}
return true;
}
public:
SharedMemory(int size=gdefaultsize)
:_key(0),_size(size),_shmid(-1),
_start_addr(nullptr),_num(nullptr),_datastart(nullptr),
_windex(0),_rindex(0)
{}
bool Creat()
{
return CreatHelper(IPC_CREAT|IPC_EXCL|0666);//共享内存存在,出错并返回
}
bool Get()
{
return CreatHelper(IPC_CREAT);//共享内存存在,获取并返回
}
//连接,将指定的共享内存挂接到自己的进程地址空间
bool Attch()
{
_start_addr=shmat(_shmid,nullptr,0);
if((long long)_start_addr==-1)
{
perror("shmat");
return false;
}
printf("_start_addr:%p\n",_start_addr);
_num=(int*)_start_addr;
_datastart=(char*)_start_addr+sizeof(int);
return true;
}
void SetZero()
{
*_num=0;
}
//共享内存段和当前进程分离
bool Detach()
{
int n=shmdt(_start_addr);
if(n<0)
{
perror("shmdt");
return false;
}
return true;
}
//写入字符
void AddChar(char &ch)
{
if(*_num==_size)
{
return ;
}
((char*)_datastart)[_windex++]=ch;
((char*)_datastart)[_windex]='\0';
_windex%=_size;
(*_num)++;
}
void PopChar(char &ch)//必须引用,因为对ch进行了操作,把值修改了
{
if(*_num==0)
{
return ;
}
ch=((char*)_datastart)[_rindex++];
_rindex%=_size;
(*_num)--;
}
bool RemoveShm()
{
int n=shmctl(_shmid,IPC_RMID,nullptr);
if(n<0)
{
perror("shmctl");
return false;
}
return true;
}
void PrintAttr()
{
struct shmid_ds buf;
int n=shmctl(_shmid,IPC_STAT,&buf);
if(n<0)
{
perror("shmctl");
return ;
}
printf("key:0x%x\n",buf.shm_perm.__key);
printf("size:%ld\n",buf.shm_segsz);
printf("atime:%lu\n",buf.shm_atime);
printf("nattch:%ld\n",buf.shm_nattch);
}
~SharedMemory(){}
private:
key_t _key;//键值
int _shmid;//共享内存段的标识码
int _size;//共享内存的大小
void *_start_addr;//共享内存段的起始地址
int *_num;//共享内存中有效个数
char *_datastart;//共享内存中实际存储数据的起始地址
int _windex;//记录下一次写入数据的位置
int _rindex;//记录下一次读取数据的位置
};
#endif
A:对共享内存进行读取
//A.cpp
#include"shm.hpp"
#include<unistd.h>
int main()
{
SharedMemory shm;
shm.Get();
shm.Attch();
shm.PrintAttr();
while(true)
{
char c;
//读取
shm.PopChar(c);
printf("A get char:%c\n",c);
sleep(1);
if(c=='Z')
break;
}
shm.Detach();
shm.RemoveShm();
return 0;
}
B:对共享进程进行写入
//B.cpp
#include"shm.hpp"
#include<unistd.h>
int main()
{
SharedMemory shm;
shm.Creat();
shm.Attch();
shm.SetZero();
char c='A';
for(;c<='Z';c++)
{
shm.AddChar(c);
sleep(1);
}
shm.Detach();
return 0;
}
makefile
.PHONY:all
all: A B //all前面没有空格
A:A.cpp
g++ -o $@ $^ -std=c++11
B:B.cpp
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f A B
两个进程分别在两个终端运行,先运行B进程(写入),在运行A进程(读取)。
查询建立的共享内存命令:ipcs -m
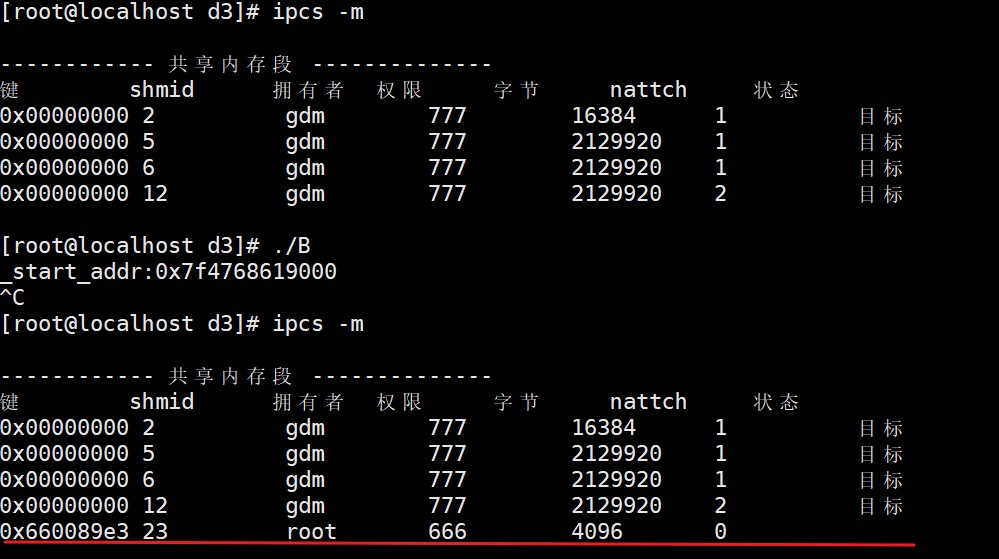
删除共享内存命令:ipcrm -m +shmid号
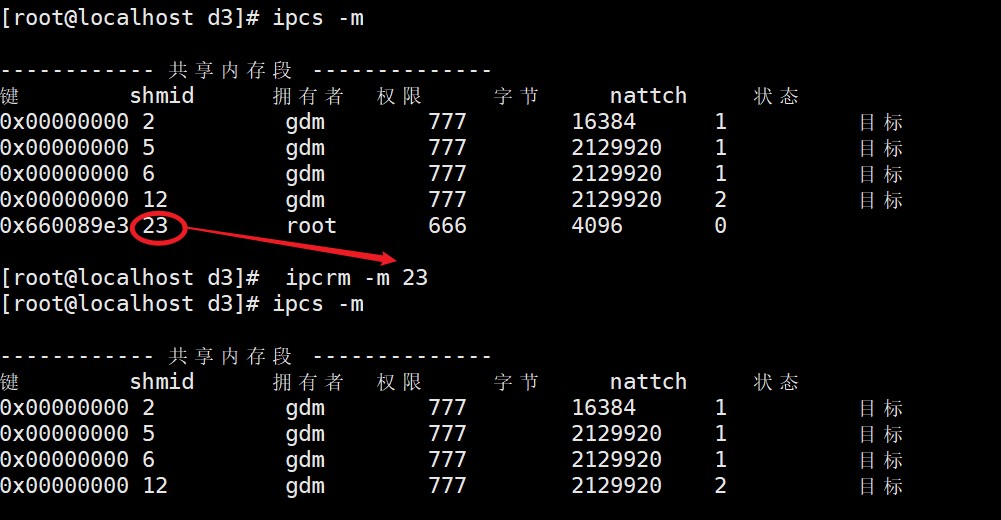
注:nattch是关联的进程数,如果两个进程用共享内存关联了,那么nattch等于2;如果只是创建成功共享内存但是连接失败,那么就是0;如果只有一个进程关联了,那么就是1。
特征总结
1.生命周期随内核。
2.共享内存通信是进程间通信中速度最快的。因为它减少了拷贝的次数,也不需要调用系统调用。
其他IPC方式(如管道、消息队列)需要将数据从用户空间拷贝到内核空间,在从内核空间拷贝到目标进程的用户空间,共两次拷贝。而共享内存只需要让多个进程访问同一块内核内存区域,无需任何数据拷贝。
进程创建共享内存映射后,后续访问共享内存时,都是在用户空间操作,无需频繁调用系统调用。
3.共享内存通信是没有同步,互斥机制。但是这会导致多个进程同时出现“数据竞争”问题,所以需要开发者自行搭配同步工具。
常用的有:
信息量(Semaphore):用于实现进程间的互斥(保证同一时间只有一个进程写)和同步(控制进程读写顺序)。

















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









