




背景:All-reduce 和 Ring 算法
GPU并行计算中需要大规模地在计算节点之间同步参数梯度,产生了大量的集合通信流量。为了优化集合通信性能,业界开发了不同的集合通信库(xCCL),其核心都是实现 All-Reduce,这也是分布式训练最主要的通信方式。

LLM训练中的 All Reduce 操作一般分为三个步骤:
-
把每个节点的数据切分成N份;
-
通过reduce-scatter,让每个节点都得到1/N的完整数据块;
-
通过all-gather,让所有节点的每个1/N数据块都变得完整
基于这种流量模式,Ring算法是目前实现该操作最常见的基础算法之一。
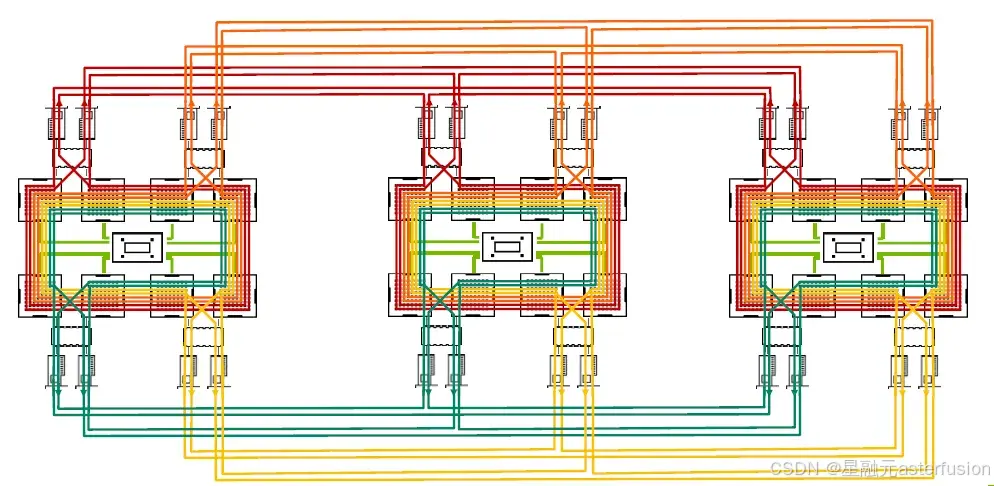
顾名思义,Ring算法构建了一个环形网络——每个节点的数据会被切分成N份数据在所有GPU之间移动,且每个GPU只和相邻的GPU通信。这种流水线模式能充分利用所有节点的发送和接收带宽,减少 GPU 等待数据的空闲时间,同时也改善了传输大数据块时的性能和时延抖动问题。(但对于小规模数据传输,Ring算法可能会表现出较高的延迟和低效。)
工具说明:NCCL-Tests
NVIDIA提供的NCCL是当前面向AI的集合通信事实标准,NCCL-Test 是 NVIDIA 开源的工具,我们可以在官方Github下载来进行不同算法的性能测试(例如:ring,trees…)。本次测试使用All reduce的ring算法来进行性能评估。
root@bm-2204kzq:~# /usr/local/openmpi/bin/mpirun #多机集群测试需要使用MPI方式执行
--allow-run-as-root
-bind-to none #不将进程绑定到特定的CPU核心
-H 172.17.0.215:8,172.17.0.81:8 # host列表,:后指定每台机器要用的GPU数量
-np 16 #指定要运行的进程数,等于总GPU数量
-x NCCL_SOCKET_NTHREADS=16
-mca btl_tcp_if_include bond0
-mca pml ^ucx -mca btl ^openib #指定BTL的value为'^openib'
-x NCCL_DEBUG=INFO #NCCL的调试级别为info
-x NCCL_IB_GID_INDEX=3
-x NCCL_IB_HCA=mlx5_0:1,mlx5_2:1,mlx5_3:1,mlx5_4:1
-x NCCL_SOCKET_IFNAME=bond0 #指定了 NCCL 使用的网络接口
-x UCX_TLS=sm,ud #调整MPI使用的传输模式
-x LD_LIBRARY_PATH -x PATH
-x NCCL_IBEXT_DISABLE=1 #如使用RoCE网络,此处应禁用
-x NCCL_ALGO=ring
/root/nccl-tests/build/all_reduce_perf -b 512 -e 18G -f 2 -g 1 #执行all reduce操作
NCCL-Tests常用参数及解释
-
GPU 数量
-
-t,--nthreads <num threads>每个进程的线程数量配置, 默认 1; -
-g,--ngpus <GPUs per thread>每个线程的 GPU 数量,默认 1;
-
-
数据大小配置
-
-b,--minbytes <min size in bytes>开始的最小数据量,默认 32M; -
-e,--maxbytes <max size in bytes>结束的最大数据量,默认 32M;
-
-
数据步长设置
-
-i,--stepbytes <increment size>每次增加的数据量,默认: 1M; -
-f,--stepfactor <increment factor>每次增加的倍数,默认禁用;
-
-
NCCL 操作相关配置
-
-o,--op <sum/prod/min/max/avg/all>指定哪种操作为reduce,仅适用于Allreduce、Reduce或ReduceScatter等操作。默认值为:求和(Sum); -
-d,--datatype <nccltype/all>指定使用哪种数据类型,默认 : Float;
-
-
性能相关配置
-
-n,--iters <iteration count>每次操作(一次发送)循环多少次,默认 : 20; -
-w,--warmup_iters <warmup iteration count>预热迭代次数(不计时),默认:5; -
-m,--agg_iters <aggregation count>每次迭代中要聚合在一起的操作数,默认:1; -
-a,--average <0/1/2/3>在所有 ranks 计算均值作为最终结果 (MPI=1 only). <0=Rank0,1=Avg,2=Min,3=Max>,默认:1;
-
-
测试相关配置
-
-p,--parallel_init <0/1>使用线程并行初始化 NCCL,默认: 0; -
-c,--check <0/1>检查结果的正确性。在大量GPU上可能会非常慢,默认:1; -
-z,--blocking <0/1>使NCCL集合阻塞,即在每个集合之后让CPU等待和同步,默认:0; -
-G,--cudagraph <num graph launches>将迭代作为CUDA图形捕获,然后重复指定的次数,默认:0;
-
案例验证:优化GPU互连拓扑
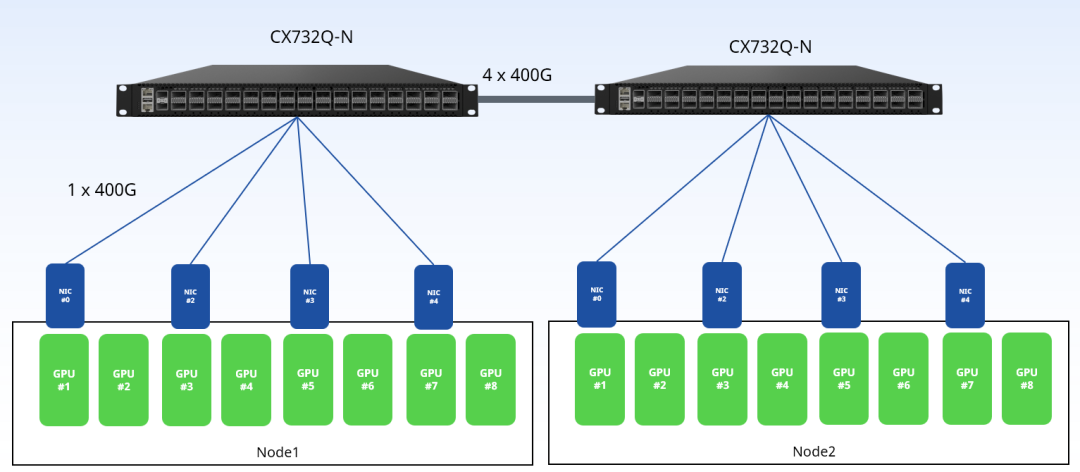
下图是一个未优化的双机8卡(H20)组网测试拓扑:
按照一般CPU云数据中心的连接方式,将同服务器的网卡连接到一台交换机上,两台交换机之间有4条400G链路相连。参与测试的为星融元(Asterfusion)交换机(CX732Q-N,32 x 400GE QSFP-DD, 2 x 10GE SFP+)。
NCCL-Test 性能测试结果
# out-of-place in-place
# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
# (B) & 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1005
1005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









