



 本文介绍了如何为17K小说网创建一个爬虫项目,包括需求说明、网页分析、正则表达式匹配、ScrapyRedis爬虫的设置和编写,重点在于获取书本名称、章节名和链接,以实现自动化的爬取和存储功能。
本文介绍了如何为17K小说网创建一个爬虫项目,包括需求说明、网页分析、正则表达式匹配、ScrapyRedis爬虫的设置和编写,重点在于获取书本名称、章节名和链接,以实现自动化的爬取和存储功能。
注:仅为我个人的案例笔记!!!不做其他引导
1、需求说明_网页分析_前置准备
1.1 需求说明
网址:【男生_小说分类_完结小说分类_免费小说分类-17K小说网】
需求:打开首页---->选择:分类---->选择:已完本、只看免费
获取书本的名字、章节名、章节url
这个暂时称呼为榜单页面:
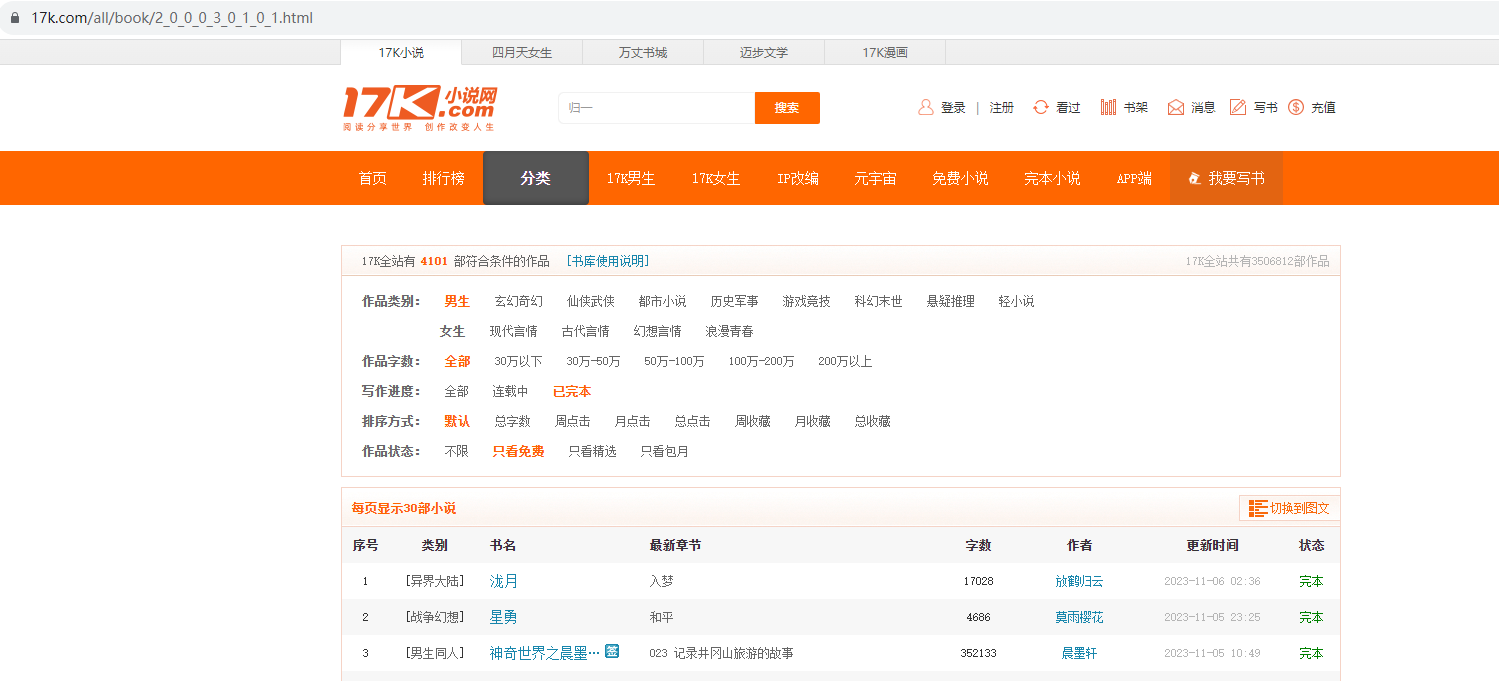
书本介绍页面:
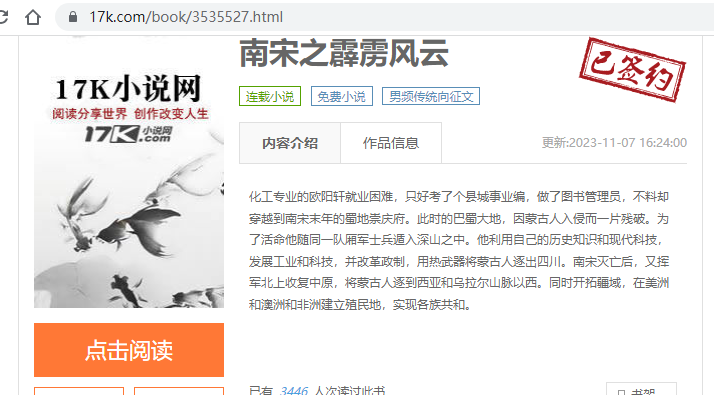
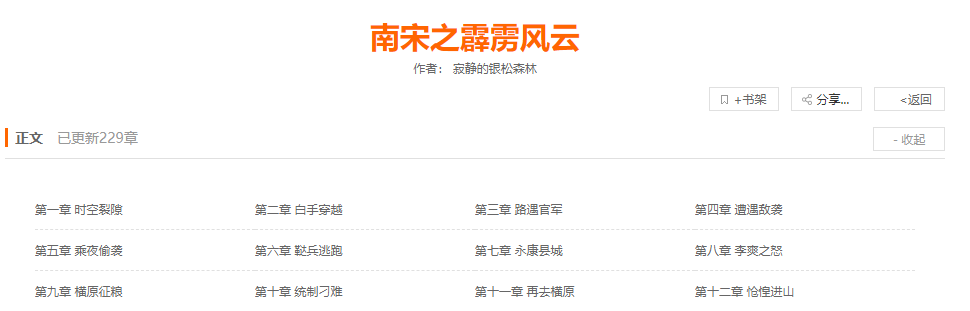
书本页面:
1.2 网页分析
正则匹配语句:r'//www.17k.com/book/\d+.html'
榜单中的书本信息位置:
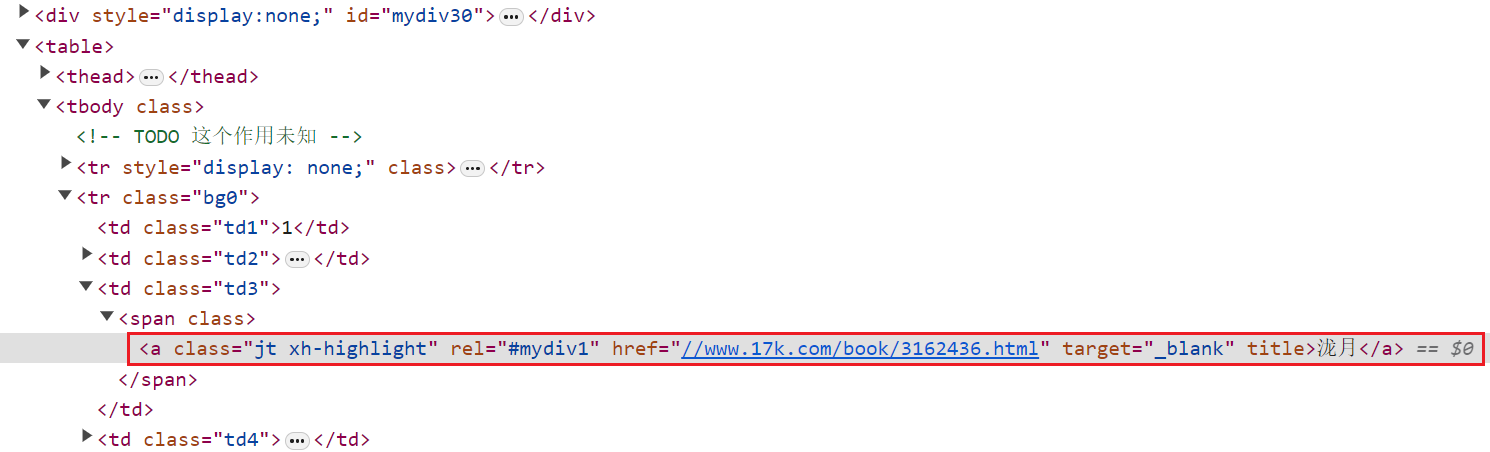
介绍页书本名及url位置:
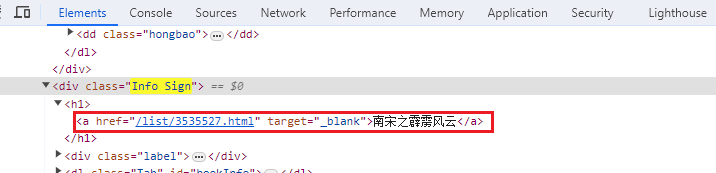
书本中的章节信息位置:
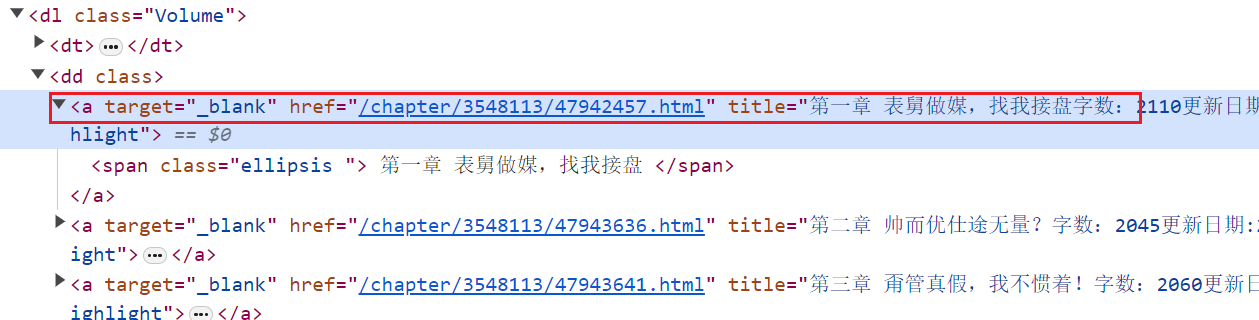
小说的具体链接=f'https://www.17k.com{a_tag.attrs["href"]}'
章节链接=f‘https://www.17k.com{href属性}’
1.3 准备一个新爬虫并修改settings.py
>scrapy startproject scrapy_redis1
>scrapy genspider -t crawl XiaoShuo aaa.com
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False2、爬虫项目的编写
2.1 在items.py里面设置要存储的数据
class XSItem(scrapy.Item):
# 书本名称
title = scrapy.Field()
# 章节名称
chapter = scrapy.Field()
# 章节链接
url = scrapy.Field()2.2 更改XiaoShuo.py模板
修改原生的爬虫模块
- 1、从scrapy模块里面导入 RedisCrawlSpider类-----用于实现自动化爬取
- 2、更改XiaoshuoSpider的父类为 RedisCrawlSpide
- 3、设置redis分配url:原来的start_urls注释掉,在类里面增加一个redis_key的变量名 赋予一个 'XiaoShuo'的值。
- 4、Rules中为每一页中小说连接的匹配规则
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from bs4 import BeautifulSoup
from ..items import XSItem
import logging
logger = logging.getLogger(__name__)
class XiaoshuoSpider(RedisCrawlSpider):
name = "XiaoShuo"
# allowed_domains = ["aaa.com"]
# start_urls = ["https://www.17k.com/all/book/2_0_0_0_3_0_1_0_2.html"]
redis_key = 'XiaoShuo' # 这个就是等下redis数据库中的键名
rules = (Rule(LinkExtractor(allow=r'//www.17k.com/book/\d+.html'),
callback="parse_item",
follow=True),)
def parse_item(self, response):
pass2.3 编写parse_item()以及parse_detail()方法
def parse_item(self, response):
item = XSItem()
soup = BeautifulSoup(response.text, 'lxml')
a_tags = soup.select('.Info Sign > a')
for a_tag in a_tags:
url = f'https://www.17k.com{a_tag.attrs["href"]}'
item['title'] = a_tag.text
return scrapy.Request(url=url,
callback=self.parse_detail,
meta={'item': item})
def parse_detail(self, response):
item = response.meta['item']
soup = BeautifulSoup(response.text, 'lxml')
a_tags = soup.select('dl[class="Volume"] > dd > a')
chapters = [] # 章节名
urls = [] # url
for a_tag in a_tags:
url = "https://www.17k.com" + a_tag.attrs["href"]
urls.append(url)
chapters.append(a_tag.attrs['title'])
item['url'] = urls
item['chapter'] = chapters
logger.warning(item["title"])
yield item2.4 修改配置文件
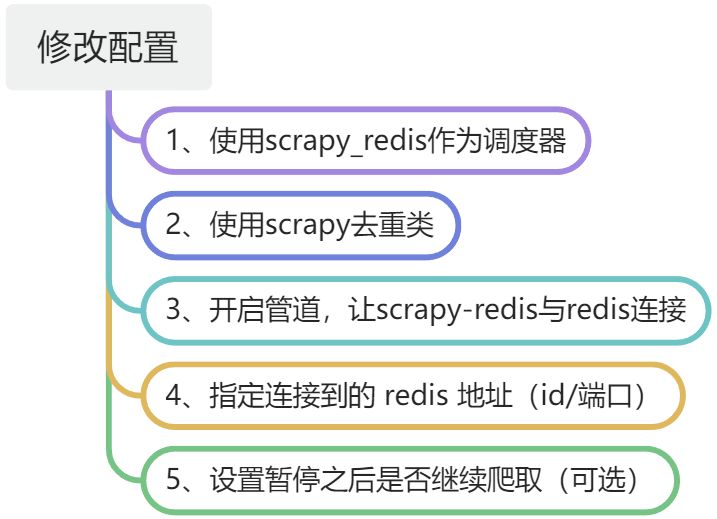
# 使用scrapy_redis 必备的配置
# 1、使用scrapy_redis 作为调度器
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
# 2、使用scrapy_redis 的去重类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 3、开启管道,让 scrapy-redis 与 redis 连接
ITEM_PIPELINES = {
"scrapy_redis.pipelines.RedisPipeline": 300,
}
# 4、指定连接到 Redis 需要的ip和端口号
REDIS_HOST = "127.0.0.1"
REDIS_PORT = "6379"
# 是否暂停之后继续爬取(可选)
SCHEDULER_PERSIST = False3、创建第二个相同的项目
注:因为我们只有一台电脑,所以在这个地方使用两个项目来模拟两台电脑。当然直接用一个项目来爬取也是没有关系的。
>scrapy startproject scrapy_redis2 >cd scrapy_redis2 >scrapy genspider -t crawl XiaoShuo aaa.com
1、修改setting文件, 与第一个项目做相同的更改 UA、robots协议、使用scrapy_redis 必备的配置 (不要直接全部复制,改该改的地方。) 2、item文件,增加一个与第一个项目一样的item类即可 3、爬虫文件,一样的编写
4、创建启动文件
两个项目都需要创建启动文件并开启
from scrapy import cmdline
cmdline.execute('scrapy crawl XiaoShuo -o xs.json'.split())有这个说明已经成功链接到数据库:

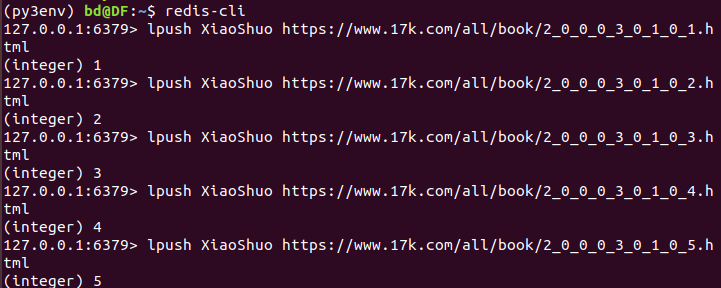
启动数据库调度爬虫项目:
语法:lpush 键名 目标网址
键名:(与设置在爬虫文件的redis_key一致)
目标网址:以每一页为单位进行,是每一页的url
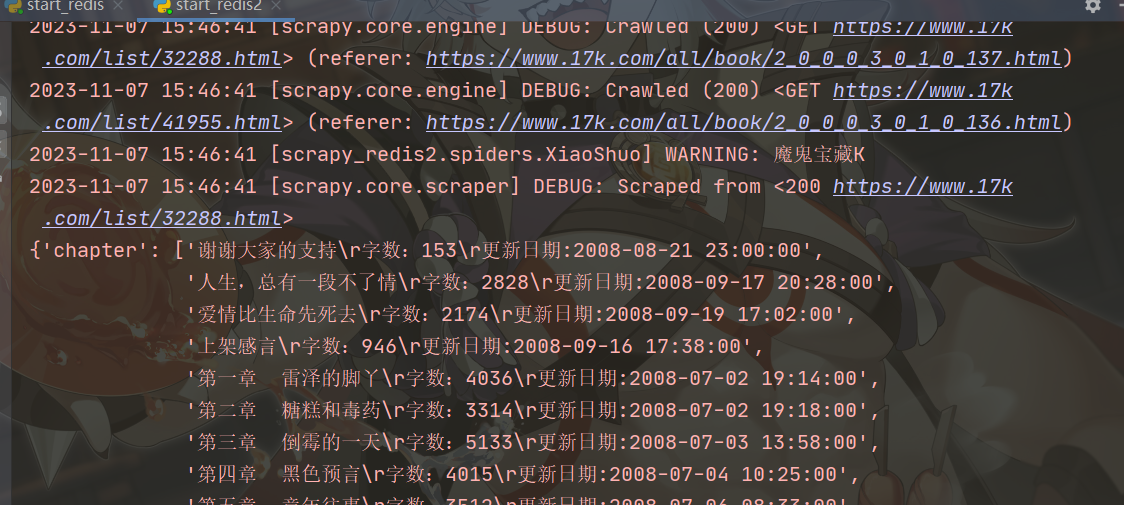
爬取日志展示:
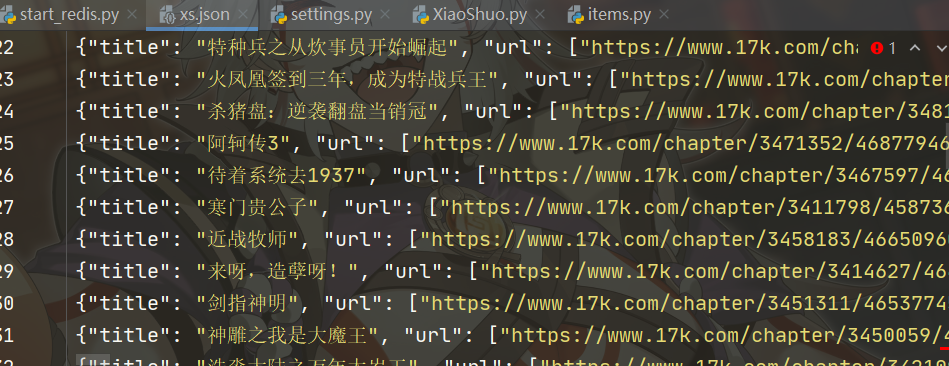
存储结果展示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









