




贝叶斯优化算法原理
在贝叶斯优化的数学过程当中,我们主要执行以下几个步骤:
-
1 定义需要估计的 f ( x ) f(x) f(x)以及 x x x的定义域
-
2 取出有限的n个 x x x上的值,求解出这些 x x x对应的 f ( x ) f(x) f(x)(求解观测值)
-
3 根据有限的观测值,对函数进行估计(该假设被称为贝叶斯优化中的先验知识),得出该估计 f ∗ f^* f∗上的目标值(最大值或最小值)
-
4 定义某种规则,以确定下一个需要计算的观测点
并持续在2-4步骤中进行循环,直到假设分布上的目标值达到我们的标准,或者所有计算资源被用完为止(例如,最多观测m次,或最多允许运行t分钟)。
以上流程又被称为序贯模型优化(SMBO),是最为经典的贝叶斯优化方法。在实际的运算过程当中,尤其是超参数优化的过程当中,有以下具体细节需要注意:
-
当贝叶斯优化不被用于HPO时,一般 f ( x ) f(x) f(x)可以是完全的黑盒函数(black box function,也译作黑箱函数,即只知道 x x x与 f ( x ) f(x) f(x)的对应关系,却丝毫不知道函数内部规律、同时也不能写出具体表达式的一类函数),因此贝叶斯优化也被认为是可以作用于黑盒函数估计的一类经典方法。但在HPO过程当中,需要定义的 f ( x ) f(x) f(x)一般是交叉验证的结果/损失函数的结果,而我们往往非常清楚损失函数的表达式,只是我们不了解损失函数内部的具体规律,因此HPO中的 f ( x ) f(x) f(x)不能算是严格意义上的黑盒函数。
-
在HPO中,自变量 x x x就是超参数空间。在上述二维图像表示中, x x x为一维的,但在实际进行优化时,超参数空间往往是高维且极度复杂的空间。
-
最初的观测值数量n、以及最终可以取到的最大观测数量m都是贝叶斯优化的超参数,最大观测数量m也决定了整个贝叶斯优化的迭代次数。
-
在第3步中,根据有限的观测值、对函数分布进行估计的工具被称为概率代理模型(Probability Surrogate model),毕竟在数学计算中我们并不能真的邀请数万人对我们的观测点进行连线。这些概率代理模型自带某些假设,他们可以根据廖廖数个观测点估计出目标函数的分布 f ∗ f^* f∗(包括 f ∗ f^* f∗上每个点的取值以及该点对应的置信度)。在实际使用时,概率代理模型往往是一些强大的算法,最常见的比如高斯过程、高斯混合模型等等。传统数学推导中往往使用高斯过程,但现在最普及的优化库中基本都默认使用基于高斯混合模型的TPE过程。
-
在第4步中用来确定下一个观测点的规则被称为采集函数(Aquisition Function),采集函数衡量观测点对拟合 f ∗ f^* f∗所产生的影响,并选取影响最大的点执行下一步观测,因此我们往往关注采集函数值最大的点。最常见的采集函数主要是概率增量PI(Probability of improvement,比如我们计算的频数)、期望增量(Expectation Improvement)、置信度上界(Upper Confidence Bound)、信息熵(Entropy)等等。上方gif图像当中展示了PI、UCB以及EI。其中大部分优化库中默认使用期望增量。
在HPO中使用贝叶斯优化时,我们常常会看见下面的图像,这张图像表现了贝叶斯优化的全部基本元素,我们的目标就是在采集函数指导下,让 f ∗ f^* f∗尽量接近 f ( x ) f(x) f(x)。
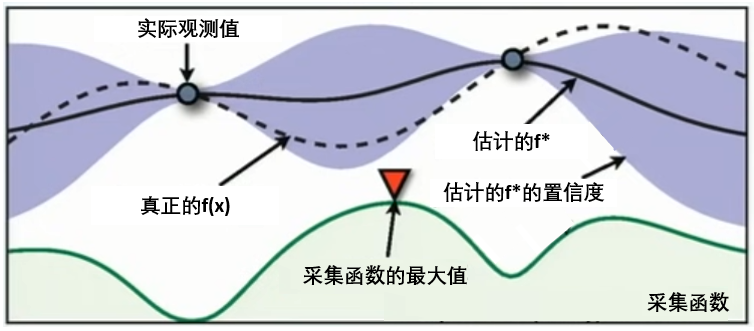
贝叶斯优化的实现(三种方法均有代码实现)
贝叶斯优化是当今黑盒函数估计领域最为先进和经典的方法,在同一套序贯模型下使用不同的代理模型以及采集函数、还可以发展出更多更先进的贝叶斯优化改进版算法,因此,贝叶斯优化的其算法本身就多如繁星,实现各种不同种类的贝叶斯优化的库也是琳琅满目,几乎任意一个专业用于超参数优化的工具库都会包含贝叶斯优化的内容。我们可以在以下页面找到大量可以实现贝叶斯优化方法的HPO库:https://www.automl.org/automl/hpo-packages/ ,其中大部分库都是由独立团队开发和维护,因此不同的库之间之间的优劣、性格、功能都有很大的差异。在课程中,我们将介绍如下三个可以实现贝叶斯优化的库:bayesian-optimization,hyperopt,optuna。
| HPO库 | 优劣评价 | 推荐指数 |
|---|---|---|
| bayes_opt | ✅实现基于高斯过程的贝叶斯优化 ✅当参数空间由大量连续型参数构成时 ⛔包含大量离散型参数时避免使用 ⛔算力/时间稀缺时避免使用 |
⭐⭐ |
| hyperopt | ✅实现基于TPE的贝叶斯优化 ✅支持各类提效工具 ✅进度条清晰,展示美观,较少怪异警告或报错 ✅可推广/拓展至深度学习领域 ⛔不支持基于高斯过程的贝叶斯优化 ⛔代码限制多、较为复杂,灵活性较差 |
⭐⭐⭐⭐ |
| optuna | ✅(可能需结合其他库)实现基于各类算法的贝叶斯优化 ✅代码最简洁,同时具备一定的灵活性 ✅可推广/拓展至深度学习领域 ⛔非关键性功能维护不佳,有怪异警告与报错 |
⭐⭐⭐⭐ |
- 导入库,确认使用数据(基于随机森林回归器进行优化)
#基本工具
import numpy as np
import pandas as pd
import time
import os #修改环境设置
#算法/损失/评估指标等
import sklearn
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.model_selection import KFold, cross_validate
#优化器
from bayes_opt import BayesianOptimization
import hyperopt
from hyperopt import hp, fmin, tpe, Trials, partial
from hyperopt.early_stop import no_progress_loss
import optuna
#导入波士顿房价数据
data = pd.read_csv(r"D:\Pythonwork\datasets\House Price\train_encode.csv",index_col=0)
#查看数据
data.head()
X = data.iloc[:,: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









