




 本文深入探讨了Web Streams API,将其与Node.js Stream进行对比,并介绍了readable、writable和transform streams的原理及用法。通过类比水流,解释了流作为I/O操作标准抽象的优势,强调了其在大数据量处理中的重要性。文章通过实例展示了如何使用Web Streams API进行数据转换和传输,最后总结了流在现代Web开发中的应用价值。
本文深入探讨了Web Streams API,将其与Node.js Stream进行对比,并介绍了readable、writable和transform streams的原理及用法。通过类比水流,解释了流作为I/O操作标准抽象的优势,强调了其在大数据量处理中的重要性。文章通过实例展示了如何使用Web Streams API进行数据转换和传输,最后总结了流在现代Web开发中的应用价值。
Node stream 比较难理解,也比较难用,但 “流” 是个很重要而且会越来越常见的概念(fetch 返回值就是流),所以我们有必要认真学习 stream。
好在继 node stream 之后,又推出了比较好用,好理解的 web streams API,我们结合 Web Streams Everywhere (and Fetch for Node.js)、2016 - the year of web streams、ReadableStream、WritableStream 这几篇文章学一下。
node stream 与 web stream 可以相互转换:
.fromWeb()将 web stream 转换为 node stream;.toWeb()将 node stream 转换为 web stream。
精读
stream(流)是什么?
stream 是一种抽象 API。我们可以和 promise 做一下类比,如果说 promise 是异步标准 API,则 stream 希望成为 I/O 的标准 API。
什么是 I/O?就是输入输出,即信息的读取与写入,比如看视频、加载图片、浏览网页、编码解码器等等都属于 I/O 场景,所以并不一定非要大数据量才算 I/O,比如读取一个磁盘文件算 I/O,同样读取 "hello world" 字符串也可以算 I/O。
stream 就是当下对 I/O 的标准抽象。
为了更好理解 stream 的 API 设计,以及让你理解的更深刻,我们先自己想一想一个标准 I/O API 应该如何设计?
I/O 场景应该如何抽象 API?
read()、write() 是我们第一个想到的 API,继续补充的话还有 open()、close() 等等。
这些 API 确实可以称得上 I/O 场景标准 API,而且也足够简单。但这些 API 有一个不足,就是缺乏对大数据量下读写的优化考虑。什么是大数据量的读写?比如读一个几 GB 的视频文件,在 2G 慢网络环境下访问网页,这些情况下,如果我们只有 read、write API,那么可能一个读取命令需要 2 个小时才能返回,而一个写入命令需要 3 个小时执行时间,同时对用户来说,不论是看视频还是看网页,都无法接受这么长的白屏时间。
但为什么我们看视频和看网页的时候没有等待这么久?因为看网页时,并不是等待所有资源都加载完毕才能浏览与交互的,许多资源都是在首屏渲染后再异步加载的,视频更是如此,我们不会加载完 30GB 的电影后再开始播放,而是先下载 300kb 片头后就可以开始播放了。
无论是视频还是网页,为了快速响应内容,资源都是 在操作过程中持续加载的,如果我们设计一个支持这种模式的 API,无论资源大还是小都可以覆盖,自然比 read、wirte 设计更合理。
这种持续加载资源的行为就是 stream(流)。
什么是 stream
stream 可以认为在形容资源持续流动的状态,我们需要把 I/O 场景看作一个持续的场景,就像把一条河的河水导流到另一条河。
做一个类比,我们在发送 http 请求、浏览网页、看视频时,可以看作一个南水北调的过程,把 A 河的水持续调到 B 河。
在发送 http 请求时,A 河就是后端服务器,B 河就是客户端;浏览网页时,A 河就是别人的网站,B 河就是你的手机;看视频时,A 河是网络上的视频资源(当然也可能是本地的),B 河是你的视频播放器。
所以流是一个持续的过程,而且可能有多个节点,不仅网络请求是流,资源加载到本地硬盘后,读取到内存,视频解码也是流,所以这个南水北调过程中还有许多中途蓄水池节点。
将这些事情都考虑到一起,最后形成了 web stream API。
一共有三种流,分别是:writable streams、readable streams、transform streams,它们的关系如下:
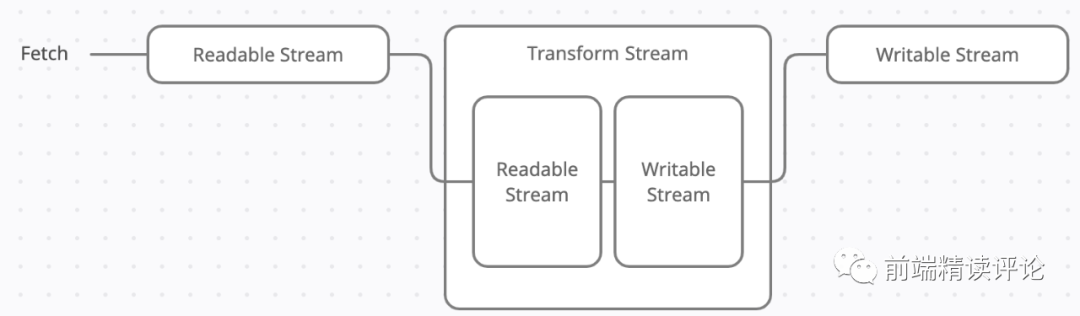
readable streams 代表 A 河流,是数据的源头,因为是数据源头,所以只可读不可写。
writable streams 代表 B 河流,是数据的目的地,因为要持续蓄水,所以是只可写不可读。
transform streams 是中间对数据进行变换的节点,比如 A 与 B 河中间有一个大坝,这个大坝可以通过蓄水的方式控制水运输的速度,还可以安装滤网净化水源,所以它一头是 writable streams 输入 A 河流的水,另一头提供 readable s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









