






 本文介绍了缓存穿透问题,即查询数据库和缓存都没有的数据会增大数据库压力。提出两种解决方案:缓存空对象和布隆过滤器。详细阐述了布隆过滤器原理、优缺点及降低误判率方法,还提及python版布隆过滤器,最后探讨了缓存穿透、击穿、雪崩的理解与解决。
本文介绍了缓存穿透问题,即查询数据库和缓存都没有的数据会增大数据库压力。提出两种解决方案:缓存空对象和布隆过滤器。详细阐述了布隆过滤器原理、优缺点及降低误判率方法,还提及python版布隆过滤器,最后探讨了缓存穿透、击穿、雪崩的理解与解决。
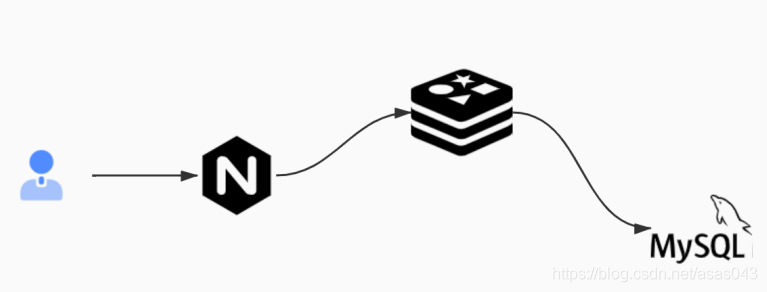
缓存穿透是指查询一条数据库和缓存都没有的一条数据,就会一直查询数据库,对数据库的访问压力就会增大,缓存穿透的解决方案,有以下两种方案:
1、缓存空对象:代码维护简单,但是效果不好。
2、布隆过滤器:代码维护复杂,效果很好
缓存穿透的发生由低到高分三种情况:
第一种情况,客户端请求id=-1的数据,此时数据库和缓存都没有数据,就会一直查询数据库,解决方案就是把id=-1的数据以NULL值缓存在redis中,就是上面的方案一
第二种情况,客户端请求id=UUID的数据,此时如果采用方案一,就会出现两个问题:
(1)大量的NULL值会存储在redis中,占用内存大
(2)由于一些redis的淘汰策略,如LRU,LFU淘汰策略导致一些热点数据被淘汰,没用的数据被缓存,那么redis缓存就没有意义
所以第二种情况使用方案一效果非常不好
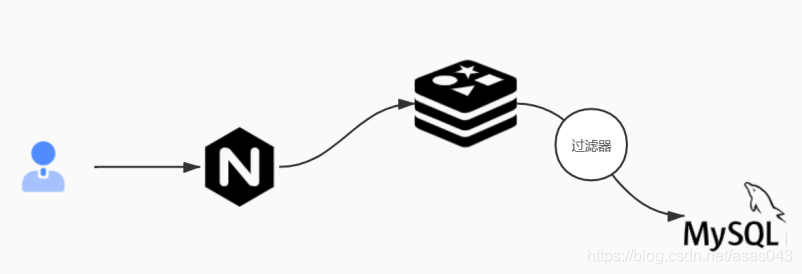
解决上述比较好的方法是添加一个过滤器,当过滤器识别到id=UUID不存在数据库时,直接返回,避免了直接查询数据库,但会有一个问题:
(1)过滤器需要把数据库的数据直接存储在过滤器中,而且最好存储在内存中(这样查询比较快),但假如数据库的数据非常大,就会造成占用内存大的问题
而布隆算法就是为了解决内存大的问题,使用了布隆算法的过滤器就叫布隆过滤器,布隆过滤器也是很好解决缓存穿透的方案。
什么是布隆过滤器?
布隆过滤器(Bloom Filter)本质上是由长度为 m 的位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0,用于检索一个元素是否在一个集合中。由于位列表占用空间小,所以能解决占内存的问题
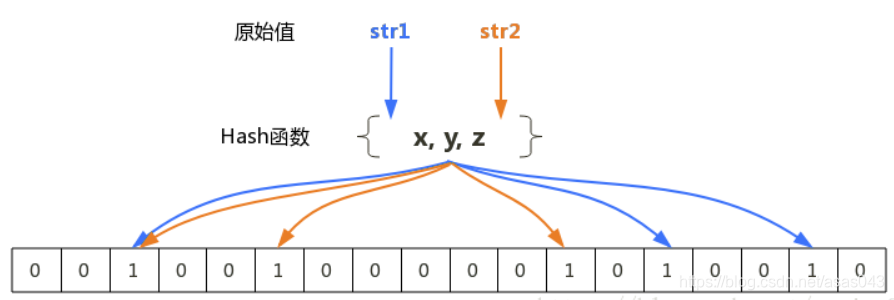 布隆算法会通过hash函数计算出hash值,然后在对应的hash值位置把值标记为1,如上图,有三个hash函数(至少要有一个)计算出三个位置标记为111,证明该元素存在这个集合中。但这里存在一个问题
布隆算法会通过hash函数计算出hash值,然后在对应的hash值位置把值标记为1,如上图,有三个hash函数(至少要有一个)计算出三个位置标记为111,证明该元素存在这个集合中。但这里存在一个问题
(1)hash算法存在hash碰撞,所以可能存在误判的情况。布隆算法是存在一定误判率的,布隆过滤器是通过一定的误判率来换取空间,它的检查值是 “可能在集合中” 或者“绝对不在集合中”。但这种误判率对缓存穿透这种应用场景的影响不大,1)判断可能在集合中大不了去数据库再查一遍 2)误判率是可以降低的
怎么降低误判率:
(1)加大位列表的长度
(2)增加hash函数的个数
增加hash函数的个数能降低误判率,假如只有一个过滤器,位列表长度为100,发生碰撞概率为1/100,假如增加到3个,发生碰撞概率为(1/100)3
总结布隆算法的缺点:
(1)存在误判率
(2)删除困难
了解了原理后,不难理解布隆过滤器是不支持元素删除的,因为位数组上的某一位有可能被多个 元素所公用。如果删除了 key1,那么与key1有公用位的key2 查询时就不存在了,造成误判。
想要解决这个问题,可以添加计数器,对数组每一位进行计数,删除时计数删除,如果计数为0,可直接置0,但这样就会加大内存的占用,本来删除数据就是为了节省空间,但这样做了没效果。
python版的布隆过滤器
import hashlib
import redis
class MultipleHash(object):
def __init__(self, salts, hash_func_name="md5"):
self.hash_func = getattr(hashlib, hash_func_name)
self.salts = salts
def get_hash_values(self, data):
hash_values = []
for i in self.salts:
hash_obj = self.hash_func()
hash_obj.update(data.encode('utf-8'))
hash_obj.update(i.encode('utf-8'))
ret = hash_obj.hexdigest()
hash_values.append(int(ret, 16))
return hash_values
class BloomFilter(object):
def __init__(self, redis_host="localhost", redis_port=6379, redis_db=0):
self.redis_host = redis_host
self.redis_port = redis_port
self.redis_db = redis_db
self.redis_key = redis_key
self.client = self.get_redis_client()
self.multiple_hash = MultipleHash(salts)
def get_redis_client(self):
pool = redis.ConnectionPool(host=self.redis_host. port=self.redis_port, db=self.redis_db)
client = redis.StrictRedis(connection_pool=pool)
return client
def save(self, data):
hash_values = self.multiple_hash.get_hash_values(data)
for hash_value in hash_values:
offset = self._get_offset(hash_value)
self.client.setbit(self.redis_key, offset, 1)
return True
def is_exists(self, data):
hash_values = self.multiple_hash.get_hash_values(data)
bit_values = []
for hash_value in hash_values:
offset = self._get_offset(hash_value)
v = self.client.getbit(self.redis_key, offset)
if v == 0:
return False
return True
def _get_offset(self, hash_value):
# 512m的位列表长度
return hash_value % (512 * 1024 * 1024 * 8)
if __name__ == "__main__":
data = ["asdasd", "123", "123", "456", "asd", "asd"]
bm = BloomFilter(salts=["1", "2", "3", "4"], redis_host="127.0.0.1")
for d in data:
if not bm.is_exists(d):
bm.save(d)
print("映射数据成功:", d)
else:
print("发现重复数据:", d) https://blog.youkuaiyun.com/a898712940/article/details/116212825
https://blog.youkuaiyun.com/a898712940/article/details/116212825




















 到【灌水乐园】发言
到【灌水乐园】发言







