




一、简介
同样用面向对象的思想来理解无锁队列ring。dpdk的无锁队列ring是借鉴了linux内核kfifo无锁队列。ring的实质是FIFO的环形队列。
ring的特点:
- 无锁出入队(除了cas(compare and swap)操作)
- 多消费/生产者同时出入队
使用方法:
1.创建一个ring对象。
接口:structrte_ring *
rte_ring_create(constchar *name, unsigned count, int socket_id,
unsignedflags)
例如:
struct rte_ring *r = rte_ring_create(“MY_RING”, 1024,rte_socket_id(), 0);
name:ring的name
count:ring队列的长度必须是2的幂次方。原因下文再介绍。
socket_id:ring位于的socket。
flags:指定创建的ring的属性:单/多生产者、单/多消费者两者之间的组合。
0表示使用默认属性(多生产者、多消费者)。不同的属性出入队的操作会有所不同。
2.出入队
有不同的出入队方式(单、bulk、burst)都在rte_ring.h中。
例如:rte_ring_enqueue和rte_ring_dequeue
这里只是简要介绍使用方法,本文的重点是介绍ring的整体架构。
二、创建ring

-
struct rte_ring { -
/* -
* Note: this field kept the RTE_MEMZONE_NAMESIZE size due to ABI -
* compatibility requirements, it could be changed to RTE_RING_NAMESIZE -
* next time the ABI changes -
*/ -
char name[RTE_MEMZONE_NAMESIZE]; /**< Name of the ring. */ -
int flags; /**< Flags supplied at creation. */ -
const struct rte_memzone *memzone; -
/**< Memzone, if any, containing the rte_ring */ -
/** Ring producer status. */ -
struct prod { -
uint32_t watermark; /**< Maximum items before EDQUOT. */ -
uint32_t sp_enqueue; /**< True, if single producer. */ -
uint32_t size; /**< Size of ring. */ -
uint32_t mask; /**< Mask (size-1) of ring. */ -
volatile uint32_t head; /**< Producer head. cgm 预生产到地方*/ -
volatile uint32_t tail; /**< Producer tail. cgm 实际生产了的数量*/ -
} prod __rte_cache_aligned; -
/** Ring consumer status. */ -
struct cons { -
uint32_t sc_dequeue; /**< True, if single consumer. */ -
uint32_t size; /**< Size of the ring. */ -
uint32_t mask; /**< Mask (size-1) of ring. */ -
volatile uint32_t head; /**< Consumer head. cgm 预出队的地方*/ -
volatile uint32_t tail; /**< Consumer tail. cgm 实际出队的地方*/ -
#ifdef RTE_RING_SPLIT_PROD_CONS -
} cons __rte_cache_aligned; -
#else -
} cons; -
#endif -
#ifdef RTE_LIBRTE_RING_DEBUG -
struct rte_ring_debug_stats stats[RTE_MAX_LCORE]; -
#endif -
void *ring[] __rte_cache_aligned; /**< Memory space of ring starts here. -
* not volatile so need to be careful -
* about compiler re-ordering */ -
};
在rte_ring_list链表中创建一个rte_tailq_entry节点。在memzone中根据队列的大小count申请一块内存(rte_ring的大小加上count*sizeof(void *))。紧邻着rte_ring结构的void *数组用于放置入队的对象(单纯的赋值指针值)。rte_ring结构中有生产者结构prod、消费者结构cons。初始化参数之后,把rte_tailq_entry的data节点指向rte_ring结构地址。
可以注意到cons.head、cons.tail、prod.head、prod.tail的类型都是uint32_t(32位无符号整形)。除此之外,队列的大小count被限制为2的幂次方。这两个条件放到一起构成了一个很巧妙的情景。因为队列的大小一般不会是最大的2的32次方那么大,所以,把队列取为32位的一个窗口,当窗口的大小是2的幂次方,则32位包含整数个窗口。这样,用来存放ring对象的void *指针数组空间就可只申请一个窗口大小即可。我的另一篇文章“图解有符号和无符号数隐藏的含义”解释了二进制的回环性,无符号数计算距离的技巧。根据二进制的回环性,可以直接用(uint32_t)( prod_tail - cons_tail)计算队列中有多少生产的产品(即使溢出了也不会出错,如(uint32_t)5-65535 = 6)。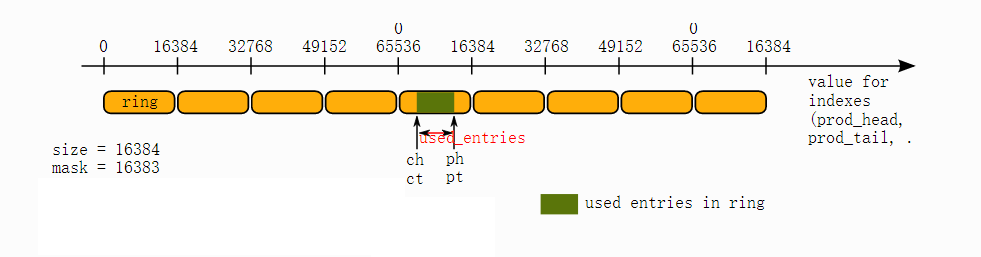
head/tail移动的时候,直接相加位移量即可,既是溢出了,结果也是对的。
三、实现多生产/消费者同时生产/消费
也即是同时出入队。
有个地方可能让人纳闷,为什么prod和cons都定义了head和tail。其实,我加的代码注释说明了这点。这就是为了实现同时出入队。
如图:
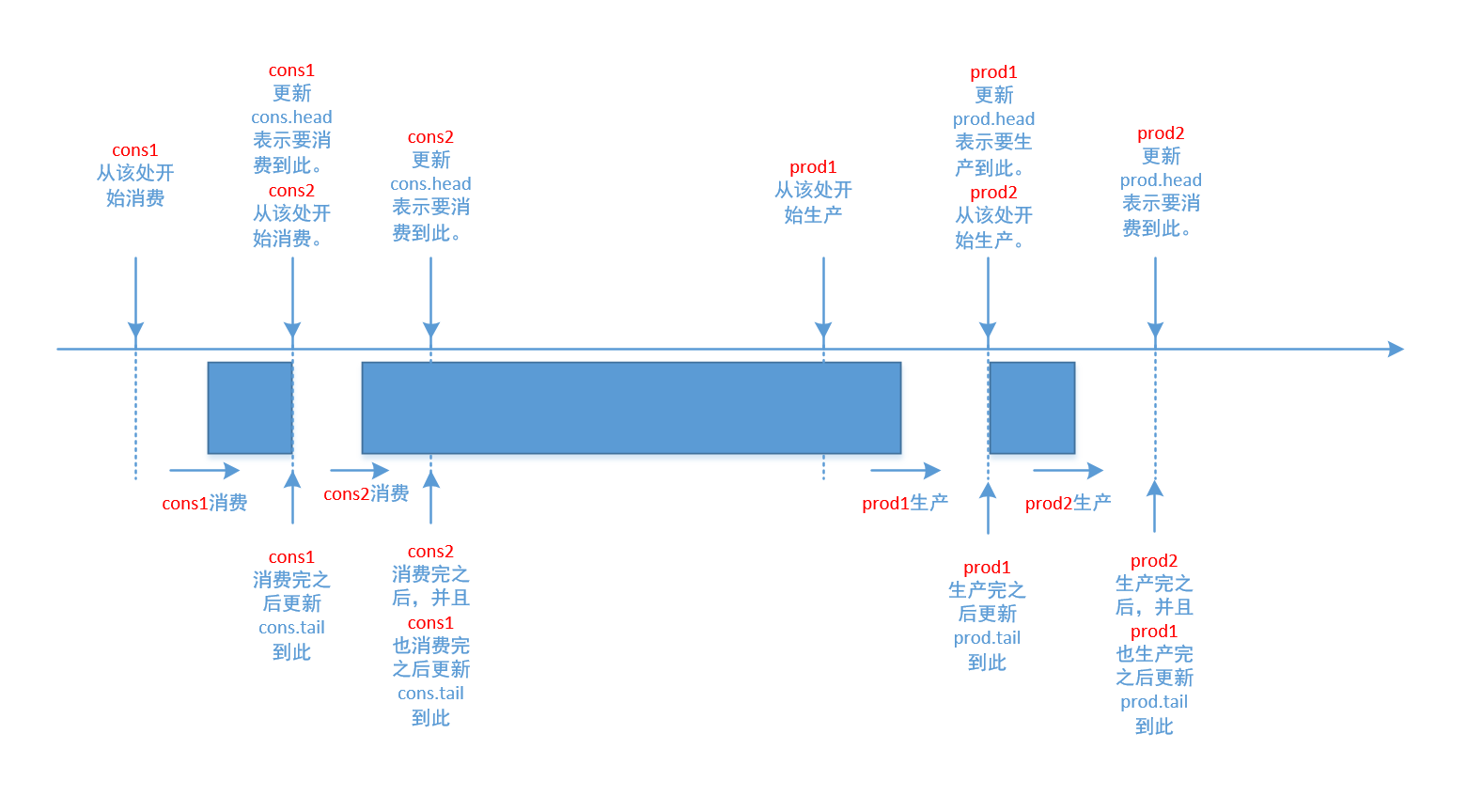
- 移动prod.head表示生产者预定的生产数量
- 当该生产者生产结束,且在此之前的生产也都结束后,移动prod.tail表示实际生产的位置
- 同样,移动cons.head表示消费者预定的消费数量
- 当该消费者消费结束,且在此之前的消费也都结束后,移动cons.tail表示实际消费的位置
四、出/入队列
在前面介绍的基础上,就很容易理解怎么样巧妙的出/入队列的了。
1.入队流程
多生产者入队代码:
-
static inline int __attribute__((always_inline)) -
__rte_ring_mp_do_enqueue(struct rte_ring *r, void * const *obj_table, -
unsigned n, enum rte_ring_queue_behavior behavior) -
{ -
uint32_t prod_head, prod_next; -
uint32_t cons_tail, free_entries; -
const unsigned max = n; -
int success; -
unsigned i, rep = 0; -
uint32_t mask = r->prod.mask; -
int ret; -
/* Avoid the unnecessary cmpset operation below, which is also -
* potentially harmful when n equals 0. */ -
if (n == 0) -
return 0; -
/* move prod.head atomically -
cgm -
1.检查free空间是否足够 -
2.cms生产预约*/ -
do { -
/* Reset n to the initial burst count */ -
n = max; -
prod_head = r->prod.head; -
cons_tail = r->cons.tail; -
/* The subtraction is done between two unsigned 32bits value -
* (the result is always modulo 32 bits even if we have -
* prod_head > cons_tail). So 'free_entries' is always between 0 -
* and size(ring)-1. */ -
/**cgm mask+cons_tail+1到下一个窗口中*/ -
free_entries = (mask + cons_tail - prod_head); -
/* check that we have enough room in ring */ -
if (unlikely(n > free_entries)) { -
if (behavior == RTE_RING_QUEUE_FIXED) { -
__RING_STAT_ADD(r, enq_fail, n); -
return -ENOBUFS; -
} -
else { -
/* No free entry available */ -
if (unlikely(free_entries == 0)) { -
__RING_STAT_ADD(r, enq_fail, n); -
return 0; -
} -
n = free_entries; -
} -
} -
prod_next = prod_head + n; -
success = rte_atomic32_cmpset(&r->prod.head, prod_head, -
prod_next); -
} while (unlikely(success == 0)); -
/* write entries in ring */ -
ENQUEUE_PTRS(); -
rte_smp_wmb(); -
/* if we exceed the watermark -
cgm 检查是否到了阈值,并添加到统计中*/ -
if (unlikely(((mask + 1) - free_entries + n) > r->prod.watermark)) { -
ret = (behavior == RTE_RING_QUEUE_FIXED) ? -EDQUOT : -
(int)(n | RTE_RING_QUOT_EXCEED); -
__RING_STAT_ADD(r, enq_quota, n); -
} -
else { -
ret = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : n; -
__RING_STAT_ADD(r, enq_success, n); -
} -
/* -
* If there are other enqueues in progress that preceded us, -
* we need to wait for them to complete -
cgm 等待之前的入队操作完成 -
*/ -
while (unlikely(r->prod.tail != prod_head)) { -
rte_pause(); -
/* Set RTE_RING_PAUSE_REP_COUNT to avoid spin too long waiting -
* for other thread finish. It gives pre-empted thread a chance -
* to proceed and finish with ring dequeue operation. */ -
if (RTE_RING_PAUSE_REP_COUNT && -
++rep == RTE_RING_PAUSE_REP_COUNT) { -
rep = 0; -
sched_yield(); -
} -
} -
r->prod.tail = prod_next; -
return ret; -
}
1.检查free空间是否足够
把free_entries = (mask + cons_tail - prod_head);写成free_entries = (mask + 1 + cons_tail - prod_head -1);就容易理解了。
先解释mask + 1 + cons_tail的意义: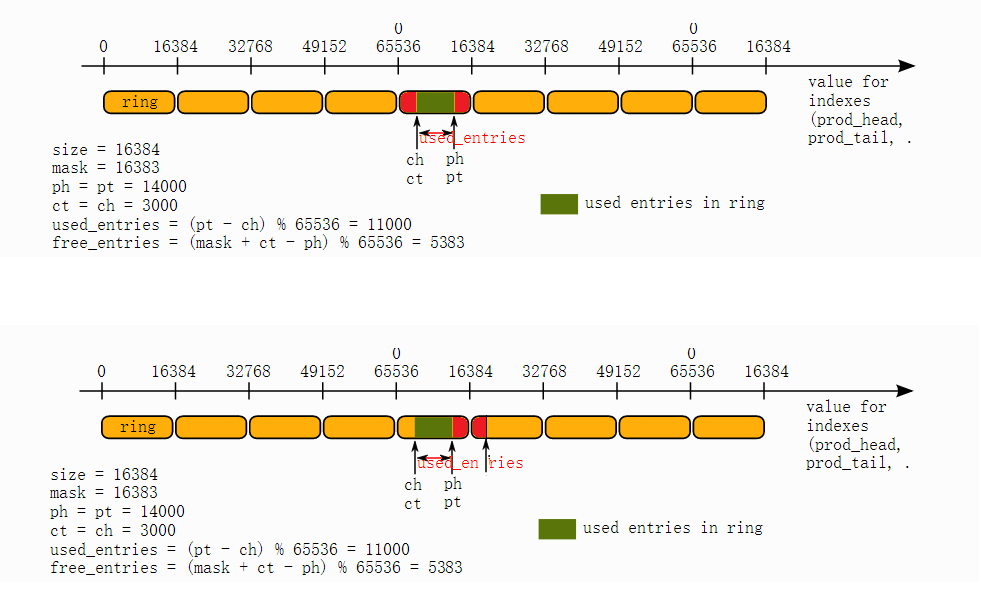
mask + 1 + cons_tail是把cons_tail移到下一个窗口对应的位置上。那么从上面2个图中,下面图中的红色面积等于上图中红色面积(按数学的几何学是这样的,但这里会有1的差错,下面介绍)。
减1的意义:
一个四位的二进制,能表示的两个数之间最大的距离是15,也即是下图中的单元格数:

但当移到下一个窗口中时,15到0之间的一个也会加上,因为15要移动下一个窗口的0(16),必须要增加1。所以,在这里多算了1个,需要减去1。

2.生产预约
利用cas操作,移动r->prod.head,预约生产。
3.检查是否到了阈值,并添加到统计中
4.等待之前的入队操作完成,移动实际位置
检查在此生产者之前的生产者都生产完成后,移动r->prod.tail,移动实际生产了的位置。
2.出队流程
多消费者出队代码:
-
static inline int __attribute__((always_inline)) -
__rte_ring_mc_do_dequeue(struct rte_ring *r, void **obj_table, -
unsigned n, enum rte_ring_queue_behavior behavior) -
{ -
uint32_t cons_head, prod_tail; -
uint32_t cons_next, entries; -
const unsigned max = n; -
int success; -
unsigned i, rep = 0; -
uint32_t mask = r->prod.mask; -
/* Avoid the unnecessary cmpset operation below, which is also -
* potentially harmful when n equals 0. */ -
if (n == 0) -
return 0; -
/* move cons.head atomically -
cgm -
1.检查可消费空间是否足够 -
2.cms消费预约*/ -
do { -
/* Restore n as it may change every loop */ -
n = max; -
cons_head = r->cons.head; -
prod_tail = r->prod.tail; -
/* The subtraction is done between two unsigned 32bits value -
* (the result is always modulo 32 bits even if we have -
* cons_head > prod_tail). So 'entries' is always between 0 -
* and size(ring)-1. */ -
entries = (prod_tail - cons_head); -
/* Set the actual entries for dequeue */ -
if (n > entries) { -
if (behavior == RTE_RING_QUEUE_FIXED) { -
__RING_STAT_ADD(r, deq_fail, n); -
return -ENOENT; -
} -
else { -
if (unlikely(entries == 0)){ -
__RING_STAT_ADD(r, deq_fail, n); -
return 0; -
} -
n = entries; -
} -
} -
cons_next = cons_head + n; -
success = rte_atomic32_cmpset(&r->cons.head, cons_head, -
cons_next); -
} while (unlikely(success == 0)); -
/* copy in table */ -
DEQUEUE_PTRS(); -
rte_smp_rmb(); -
/* -
* If there are other dequeues in progress that preceded us, -
* we need to wait for them to complete -
cgm 等待之前的出队操作完成 -
*/ -
while (unlikely(r->cons.tail != cons_head)) { -
rte_pause(); -
/* Set RTE_RING_PAUSE_REP_COUNT to avoid spin too long waiting -
* for other thread finish. It gives pre-empted thread a chance -
* to proceed and finish with ring dequeue operation. */ -
if (RTE_RING_PAUSE_REP_COUNT && -
++rep == RTE_RING_PAUSE_REP_COUNT) { -
rep = 0; -
sched_yield(); -
} -
} -
__RING_STAT_ADD(r, deq_success, n); -
r->cons.tail = cons_next; -
return behavior == RTE_RING_QUEUE_FIXED ? 0 : n; -
}
同生产者一个道理,代码中加了点注释,就不详细解释了。

















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









