




 本文深入解析DPDK的QoS入队和出队流程,介绍其基于流水线的高性能调度策略,包括HQOS线程处理、rte_sched_port_enqueue函数应用、预取策略、以及状态机和grinder机制,阐述DPDK如何通过优化数据结构访问和缓存预取提升网络包处理效率。
本文深入解析DPDK的QoS入队和出队流程,介绍其基于流水线的高性能调度策略,包括HQOS线程处理、rte_sched_port_enqueue函数应用、预取策略、以及状态机和grinder机制,阐述DPDK如何通过优化数据结构访问和缓存预取提升网络包处理效率。
入队流程
我们先看看,官网上是怎么说的:
Enqueue Pipeline
The sequence of steps per packet:
Access the mbuf to read the data fields required to identify the destination queue for the packet. These fields are: port, subport, traffic class and queue within traffic class, and are typically set by the classification stage.
Access the queue structure to identify the write location in the queue array. If the queue is full, then the packet is discarded.
Access the queue array location to store the packet (i.e. write the mbuf pointer).
It should be noted the strong data dependency between these steps, as steps 2 and 3 cannot start before the result from steps 1 and 2 becomes available, which prevents the processor out of order execution engine to provide any significant performance optimizations.
Given the high rate of input packets and the large amount of queues, it is expected that the data structures accessed to enqueue the current packet are not present in the L1 or L2 data cache of the current core, thus the above 3 memory accesses would result (on average) in L1 and L2 data cache misses. A number of 3 L1/L2 cache misses per packet is not acceptable for performance reasons.
The workaround is to prefetch the required data structures in advance. The prefetch operation has an execution latency during which the processor should not attempt to access the data structure currently under prefetch, so the processor should execute other work. The only other work available is to execute different stages of the enqueue sequence of operations on other input packets, thus resulting in a pipelined implementation for the enqueue operation.
Fig. 41.6 illustrates a pipelined implementation for the enqueue operation with 4 pipeline stages and each stage executing 2 different input packets. No input packet can be part of more than one pipeline stage at a given time.
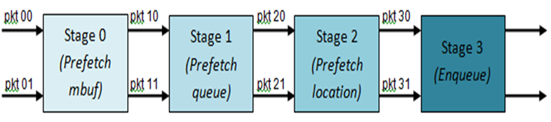
Fig. 41.6 Prefetch Pipeline for the Hierarchical Scheduler Enqueue Operation
The congestion management scheme implemente
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2441
2441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









