




 Spark MLlib 中的 Transformer 包括特征转换器和学习模型,实现 transform() 方法用于 DataFrame 的转换。Estimator 表征学习算法,实现 fit() 方法以 DataFrame 为基础训练模型。Pipeline 是一系列 Transformer 和 Estimator 阶段的序列,依次运行进行数据转换和模型训练。PipelineModel 是 Pipeline 的训练结果,用于测试阶段,确保训练和测试数据经历相同处理步骤。
Spark MLlib 中的 Transformer 包括特征转换器和学习模型,实现 transform() 方法用于 DataFrame 的转换。Estimator 表征学习算法,实现 fit() 方法以 DataFrame 为基础训练模型。Pipeline 是一系列 Transformer 和 Estimator 阶段的序列,依次运行进行数据转换和模型训练。PipelineModel 是 Pipeline 的训练结果,用于测试阶段,确保训练和测试数据经历相同处理步骤。
Transformer: A Transformer is an abstraction that includes feature transformers and learned models. Technically, a Transformer implements a method transform(), which converts one DataFrame into another, generally by appending one or more columns.
Estimator: An Estimator abstracts the concept of a learning algorithm or any algorithm that fits or trains on data. Technically, an Estimator implements a method fit(), which accepts a DataFrame and produces a Model, which is a Transformer.
Pipeline:A Pipeline is specified as a sequence of stages, and each stage is either a Transformer or an Estimator. These stages are run in order, and the input DataFrame is transformed as it passes through each stage. For Transformer stages, the transform() method is called on the DataFrame. For Estimator stages, the fit() method is called to produce a Transformer, and that Transformer’s transform() method is called on the DataFrame.
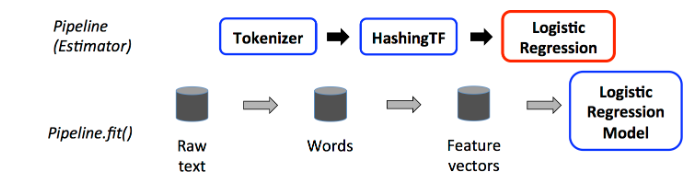
The first two (Tokenizer and HashingTF) are Transformers (blue), and the third (LogisticRegression) is an Estimator (red). Since LogisticRegression is an Estimator, the Pipeline first calls LogisticRegression.fit() to produce a LogisticRegressionModel. If the Pipeline had more Estimators, it would call the LogisticRegressionModel’s transform() method on the DataFrame before passing the DataFrame to the next stage.
A Pipeline is an Estimator. Thus, after a Pipeline’s fit() method runs, it produces a PipelineModel, which is a Transformer. This PipelineModel is used at test time.
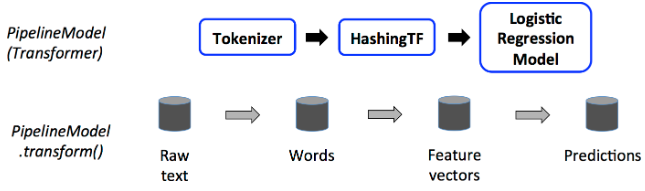
In the figure above, the PipelineModel has the same number of stages as the original Pipeline, but all Estimators in the original Pipeline have become Transformers.
Pipelines and PipelineModels help to ensure that training and test data go through identical feature processing steps.
Parameters:
A Param is a named parameter with self-contained documentation. A ParamMap is a set of (parameter, value) pairs.There are two main ways to pass parameters to an algorithm:
- Set parameters for an instance. E.g., lr.setMaxIter(10)
- Pass a ParamMap to fit() or transform(). Any parameters in the ParamMap will override parameters previously specified via setter methods.
Parameters belong to specific instances of Estimators and Transformers. For example, ParamMap(lr1.maxIter = 10, lr2.maxIter = 20).
lr = LogisticRegression(maxIter=10, regParam=0.01)
# Print out the parameters, documentation, and any default values.
## lr.explainParams()##model.extractParamMap()
print("LogisticRegression parameters:\n" + lr.explainParams() + "\n")
print(model1.extractParamMap())
paramMap = {lr.maxIter: 20}
paramMap.update({lr.regParam: 0.1, lr.threshold: 0.55}) # Specify multiple Params.

















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









