







 本文介绍了统计学的基础概念,包括方差、标准差的计算及其在度量偏离程度中的作用。同时,讲解了协方差、Pearson和Spearman相关系数,用于衡量变量间的关系强度和类型。这些统计指标在数据分析和机器学习中具有广泛应用。
本文介绍了统计学的基础概念,包括方差、标准差的计算及其在度量偏离程度中的作用。同时,讲解了协方差、Pearson和Spearman相关系数,用于衡量变量间的关系强度和类型。这些统计指标在数据分析和机器学习中具有广泛应用。
1、方差variance/deviation Var, D(X) , 总体方差,样本方差
方差是实际值与期望值之差平方的平均值,而标准差是方差算术平方根。
概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。
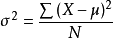
σ^2为总体方差,X为变量,µ为总体均值,N为总体例数。
实际工作中,总体均数难以得到时,应用样本统计量代替总体参数,经校正后,样本方差计算公式:
S^2= ∑(X- ̅X) ^2 / (n-1)
S^2为样本方差,X为变量, ̅X为样本均值,n为样本例数。





2、标准差(均方差)


3、协方差covariance
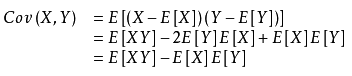
协方差(Covariance)在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。

模仿方差的公式:
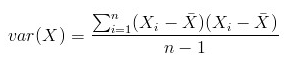
协方差可以使用如下公式:
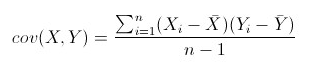
协方差矩阵

4、Pearson相关系数
皮尔森相关系数是衡量线性关联性的程度,p的一个几何解释是其代表两个变量的取值根据均值集中后构成的向量之间夹角的余弦。在机器学习中可以用来计算特征与类别间的相似度,即可判断所提取到的特征和类别是正相关、负相关还是没有相关程度。皮尔森相关性系数受异常值的影响比较大。
如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
(1)、当相关系数为0时,X和Y两变量无关系。
(2)、当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
(3)、当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数 0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关



def pearson(vector1, vector2):
n = len(vector1)
#simple sums
sum1 = sum(float(vector1[i]) for i in range(n))
sum2 = sum(float(vector2[i]) for i in range(n))
#sum up the squares
sum1_pow = sum([pow(v, 2.0) for v in vector1])
sum2_pow = sum([pow(v, 2.0) for v in vector2])
#sum up the products
p_sum = sum([vector1[i]*vector2[i] for i in range(n)])
#分子num,分母den
num = p_sum - (sum1*sum2/n)
den = math.sqrt((sum1_pow-pow(sum1, 2)/n)*(sum2_pow-pow(sum2, 2)/n))
if den == 0:
return 0.0
return num/den
5、Spearman相关性系数

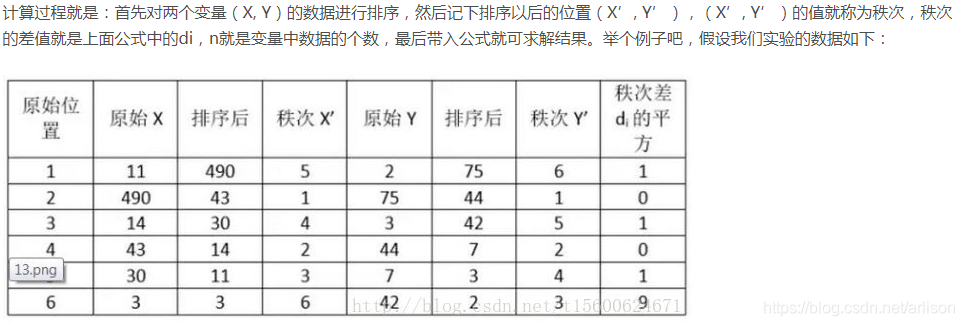
带入公式,求得斯皮尔曼相关性系数:ρs= 1-6*(1+1+1+9)/6*35=0.657
即便在变量值没有变化的情况下,也不会出现像皮尔森系数那样分母为0而无法计算的情况。另外,即使出现异常值,由于异常值的秩次通常不会有明显的变化,所以对斯皮尔曼相关性系数的影响也非常小!
由于斯皮尔曼相关性系数没有那些数据条件要求,适用的范围就广多了。在我们生物实验数据分析中,尤其是在分析多组学交叉的数据中说明不同组学数据之间的相关性时,使用的频率很高。
spearman相关系数和pearson相关系数选择:
1.连续数据,正态分布,线性关系,用pearson相关系数是最恰当,当然用spearman相关系数也可以,
就是效率没有pearson相关系数高。
2.上述任一条件不满足,就用spearman相关系数,不能用pearson相关系数。
3.两个定序测量数据之间也用spearman相关系数,不能用pearson相关系数。
————————————————
6、kendall correlation coefficient(肯德尔相关性系数)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









