







 本文详细介绍了SQL Server中的视图和存储过程的创建与使用方法,包括CREATE VIEW、ALTER VIEW、WITH SCHEMABINDING、GROUPINGSETS、CUBE、ROLLUP等语法,以及存储过程的参数设置和查询条件。同时,还提到了窗口函数的基本应用。
本文详细介绍了SQL Server中的视图和存储过程的创建与使用方法,包括CREATE VIEW、ALTER VIEW、WITH SCHEMABINDING、GROUPINGSETS、CUBE、ROLLUP等语法,以及存储过程的参数设置和查询条件。同时,还提到了窗口函数的基本应用。
https://www.yiibai.com/sqlserver/sql-server-views.html (视图不熟悉,编辑以及存储过程不熟悉)
====================================================
[]表示可选,{}表示必选,|表示或
CREATE [OR ALTER] VIEW schema_name.view_name [(column_list)] “视图用于创建新的表格用于后续的复杂操作引用view_name”
[WITH SCHEMABINDING] “建立索引视图,查询性能有优势。”
AS
SELECT
[TOP (number) ]
[PERCENT]
[WITH TIES]
[DISTINCT]
[GROUPING(col|group sets)]
col,
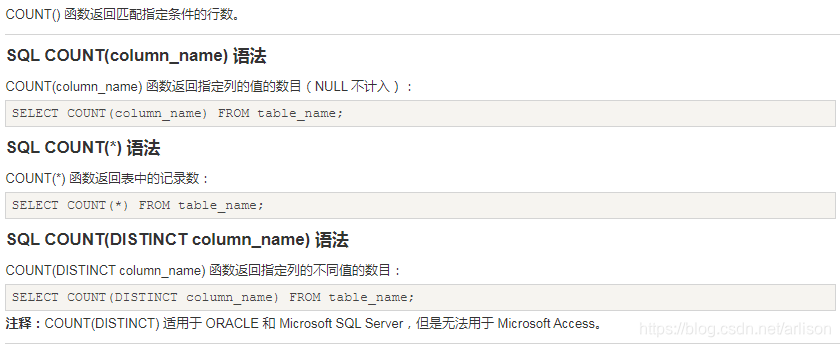
COUNT (*)
FROM
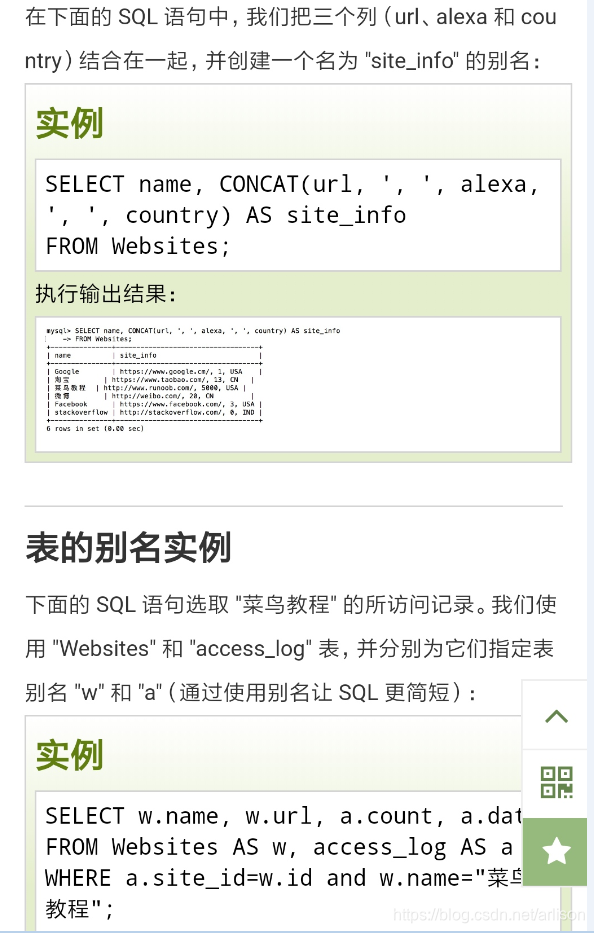
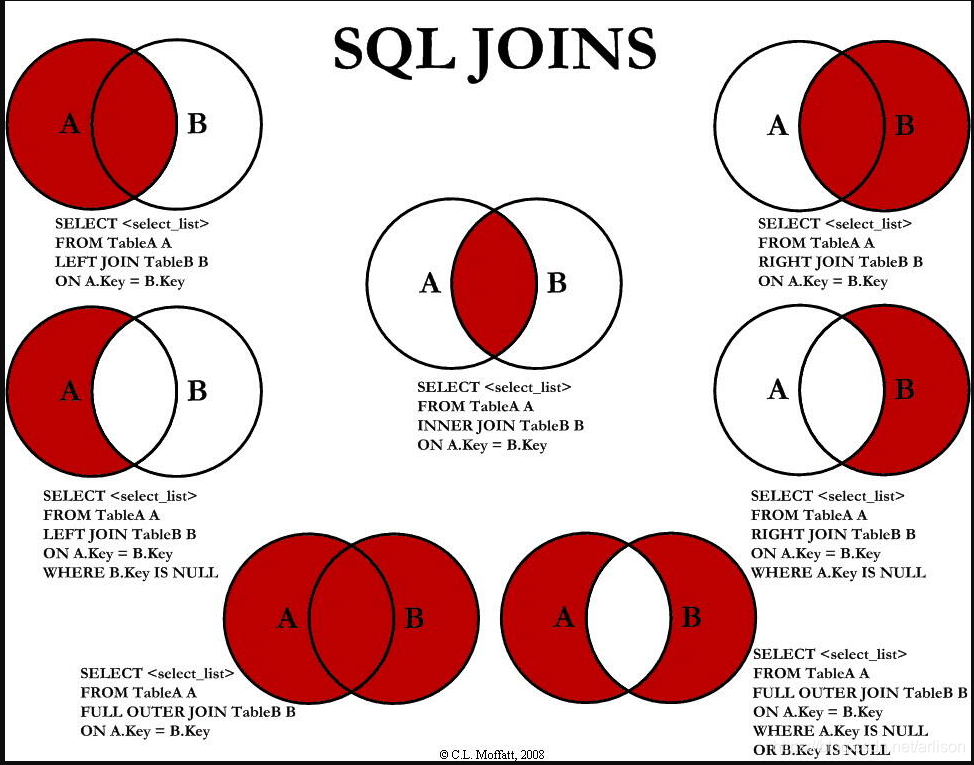
join_table join_type {JOIN|LEFT JOIN|RIGHT JOIN|FULL OUTER JOIN|CROSS JOIN} join_table [ON (join_condition)]
WHERE
condition
[column | expression [NOT] IN [( v1, v2, v3, …)| (SELECT col FROM table WHERE condition)]
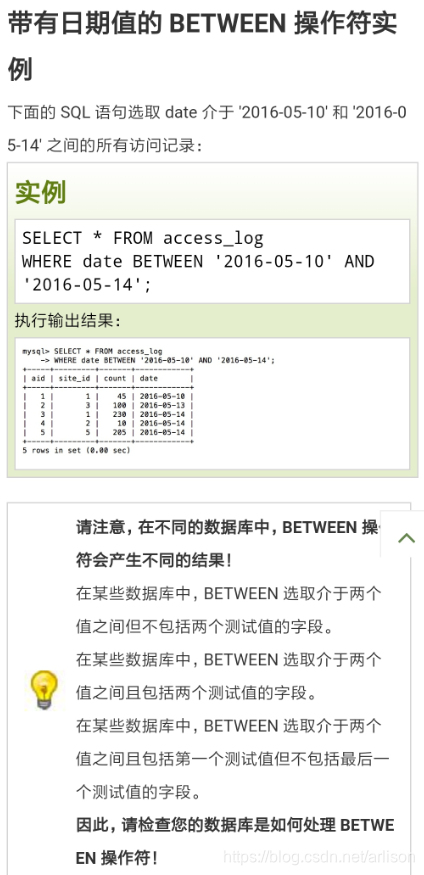
[column | expression BETWEEN start_expression AND end_expression] “包括两端”
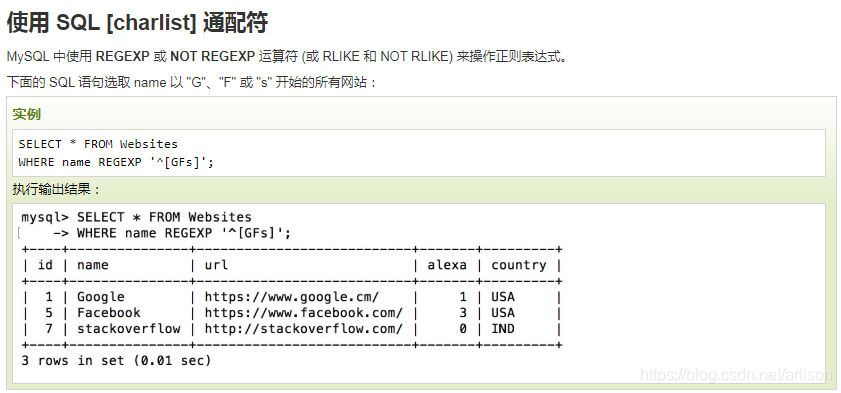
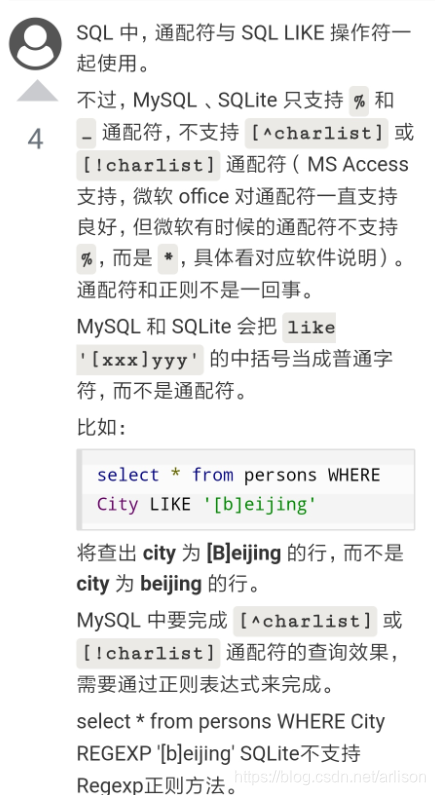
[column | expression [NOT]LIKE pattern [ESCAPE escape_character]]
[scalar_expression comparison_operator ANY (subquery)] "ANY表示任一成立即为真“
[scalar_expression comparison_operator ALL (subquery)] "ALL表示所有成立才为真“
[[NOT] EXISTS (subquery)] “子查询返回有结果不为空,则EXISTS运算符返回TRUE; 否则返回FALSE”
[UNION(不包括重复)|UNION ALL(包括重复)|INTERSECT|EXCEPT] [Another Query: SELECT …]
GROUP BY
col
[ GROUPING SETS ( (brand, category), (brand), (category), () )]
[ CUBE (d1, d2, d3)]
[ROLLUP (d1, d2, d3)]
HAVING
COUNT (*) > 10
ORDER BY column_list [ASC |DESC]
OFFSET offset_row_count {ROW | ROWS}
FETCH {FIRST | NEXT} fetch_row_count {ROW | ROWS} ONLY
[WITH TIES]用于多行等值时,返回所有等值行,否则的话,只返回等值的第一行
GROUPING函数指示是否聚合GROUP BY子句中的指定列。 它是聚合则返回1,或者为结果集是未聚合返回0
pattern
模式是要在列或表达式中搜索的字符序列。它可以包含以下有效通配符:
- 通配符百分比(%):任何零个或多个字符的字符串。
- 下划线(_)通配符:任何单个字符。
- [list of characters]通配符:指定集合中的任何单个字符。
- [character-character]:指定范围内的任何单个字符。
- [^]:不在列表或范围内的任何单个字符。
转义符
ESCAPE定义后面的字符为转义字符,转义字符指示LIKE运算符将通配符视为常规字符,使通配符恢复本意,不再具有特殊功能。转义字符没有默认值,必须仅计算为一个字符。
GROUPING SETS 等于使用UNION ALL将分别按照sets中的分组计算结果结合起来,缺失的部分用null填充#
CUBE (d1, d2, d3)等同于GROUPING SETS ((d1,d2,d3), (d1,d2), (d1,d3),(d2,d3),(d1),(d2), (d3), () )
UBE(brand, category)等同于GROUPING SETS((brand, category),(brand),(category),())
ROLLUP(d1,d2,d3)假设层次结构d1> d2> d3,等同于GROUPING SETS((d1, d2, d3),(d1, d2),(d1),())

 =================================================================================
=================================================================================
存储过程
[CREATE|ALTER] [PROCEDURE|PROC) procedure_name(
@min_list_price AS DECIMAL = 0
,@max_list_price AS DECIMAL = NULL
,@name AS VARCHAR(max)) "@表示参数“
AS
BEGIN
SELECT
product_name,
list_price
FROM
production.products
WHERE
list_price >= @min_list_price AND
(@max_list_price IS NULL OR list_price <= @max_list_price) AND
product_name LIKE ‘%’ + @name + ‘%’
ORDER BY
list_price;
END;
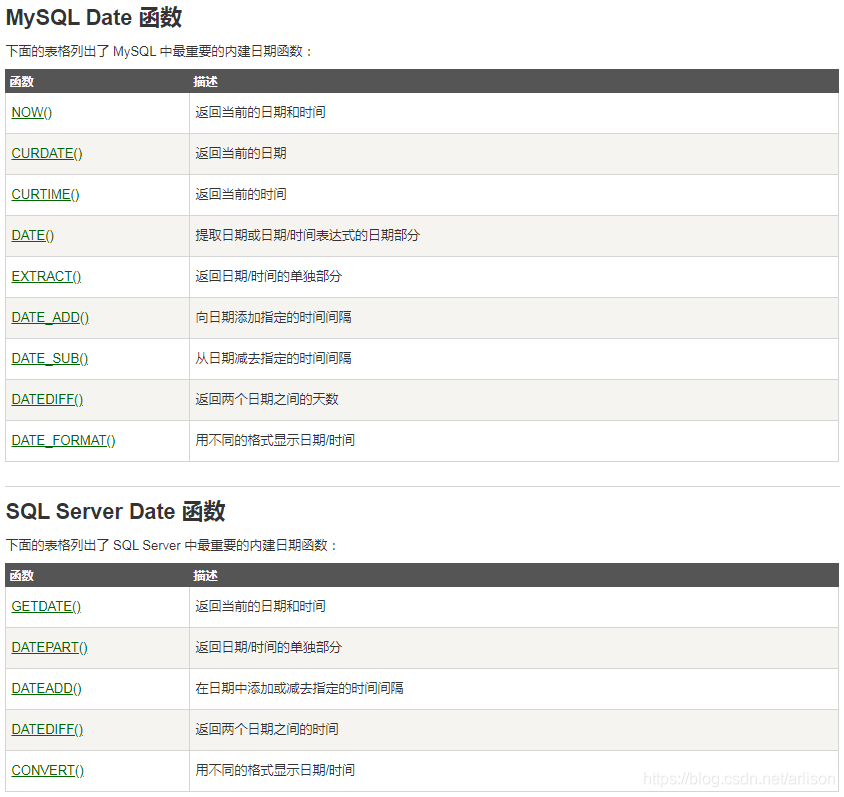
Window函数
https://blog.youkuaiyun.com/weixin_43274226/article/details/83304836(分析函数,未细看)
cume_dist函数计算方法:所在组排名序号除以该组所有的行数,但是如果存在并列情况,则需加上并列的个数-1或者小于等于当前值的行数/分组内总行数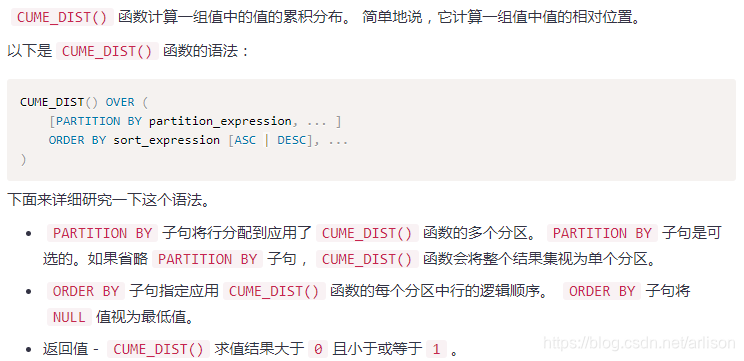
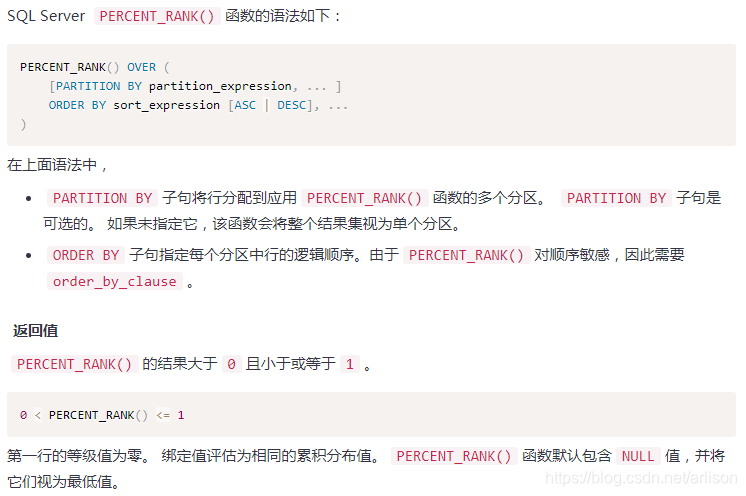
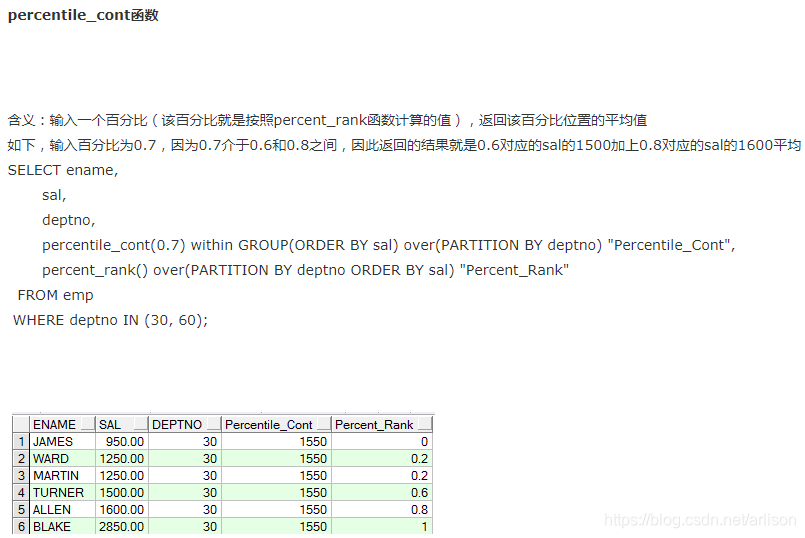
percent_rank计算方法:所在组排名序号-1除以该组所有的行数-1或者分组内当前行的RANK值-1/分组内总行数-1
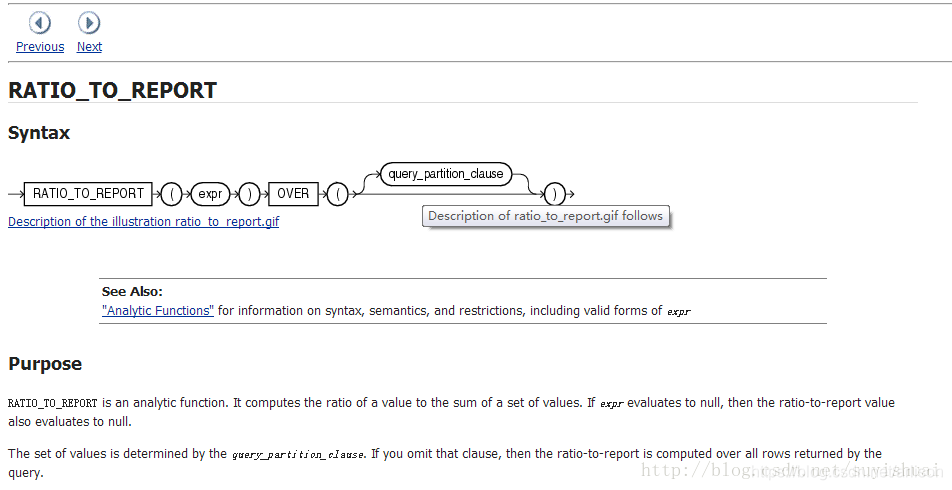
ratio_to_report(a)函数用法:Ratio_to_report() 括号中就是分子,over() 括号中就是分母
https://www.cnblogs.com/cjm123/p/8033639.html

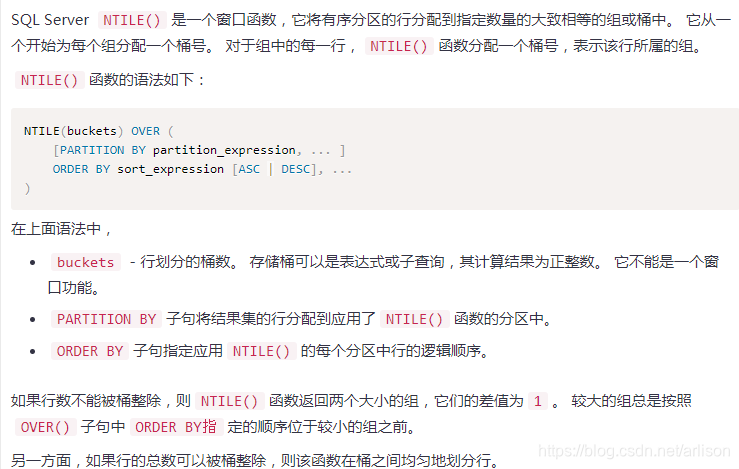
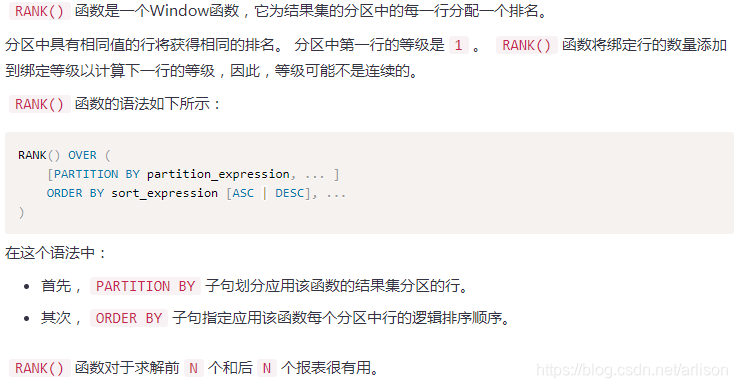

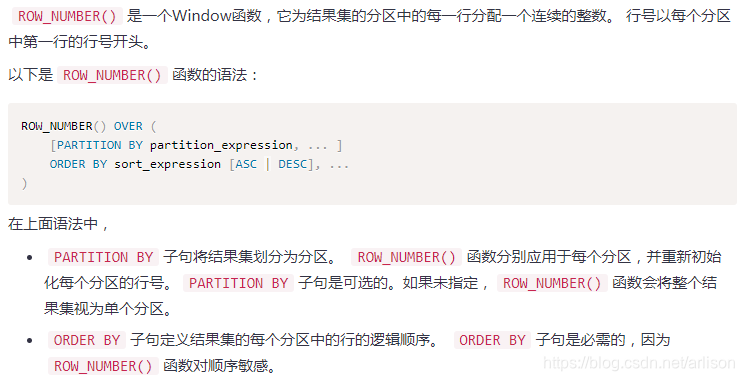

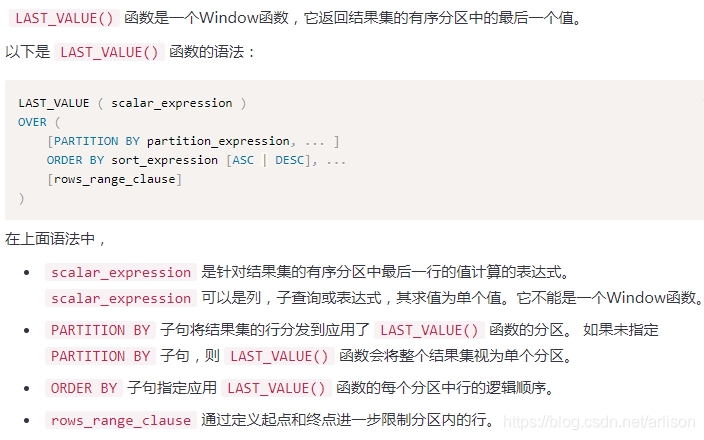
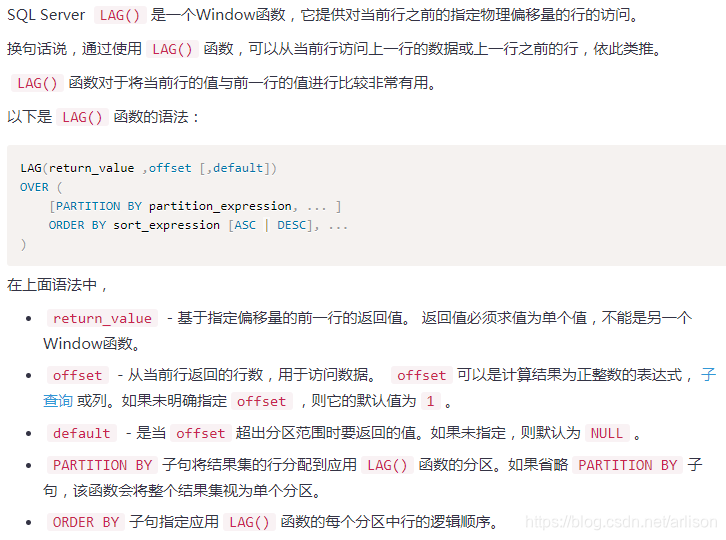
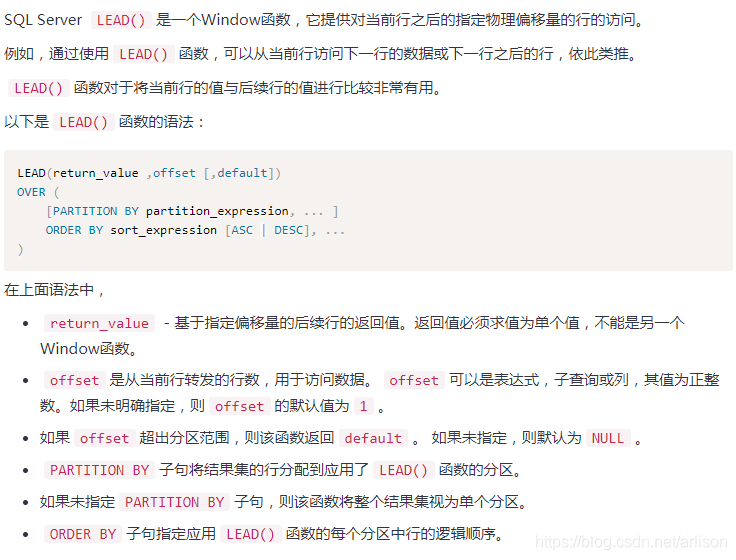
=============================================
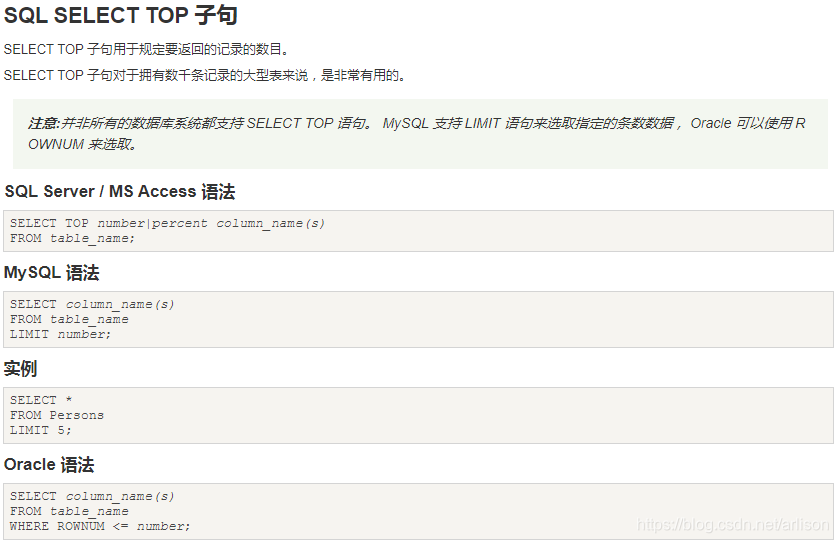
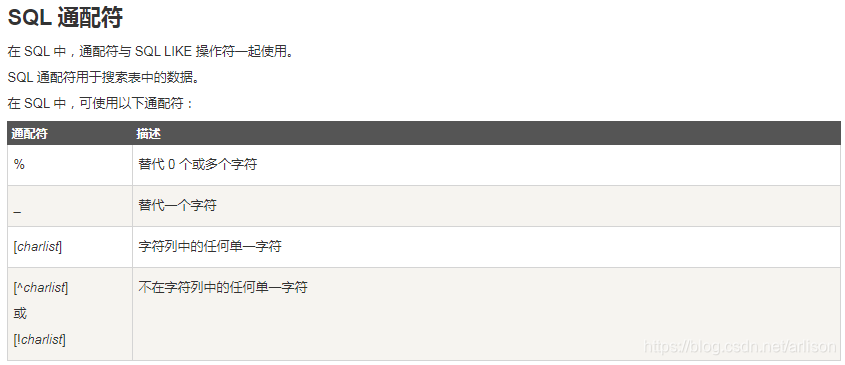





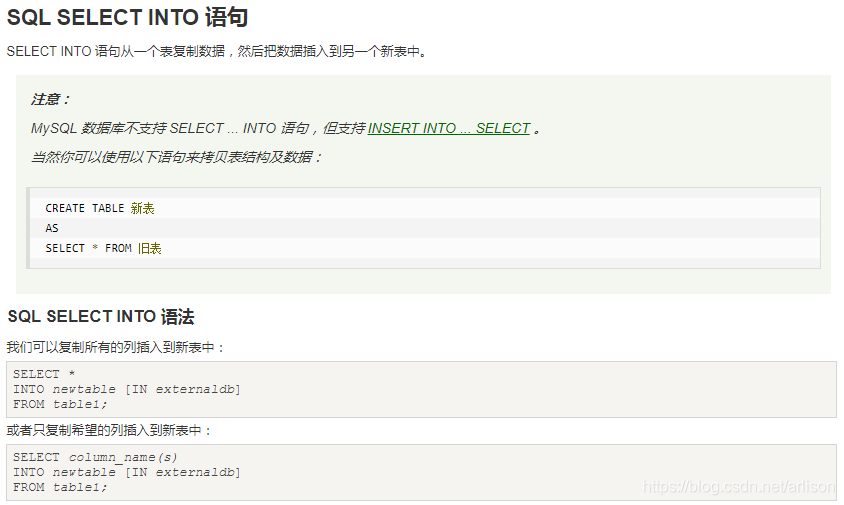
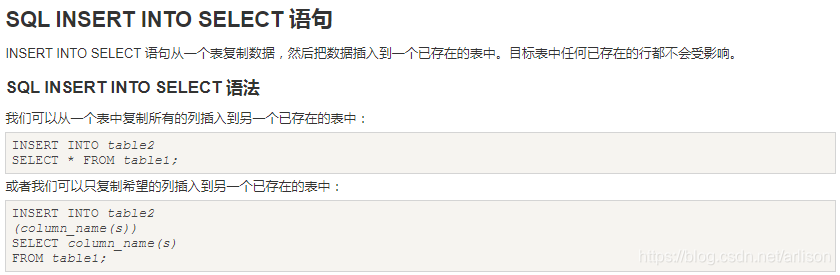
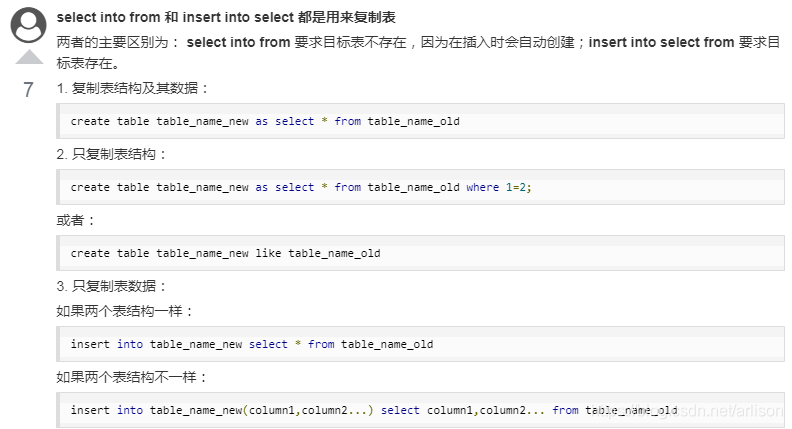

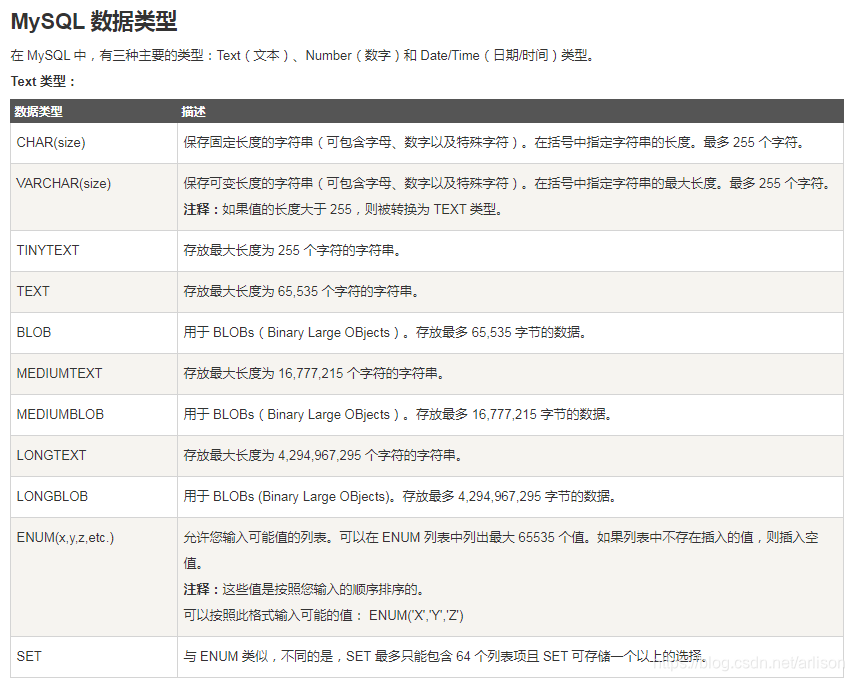
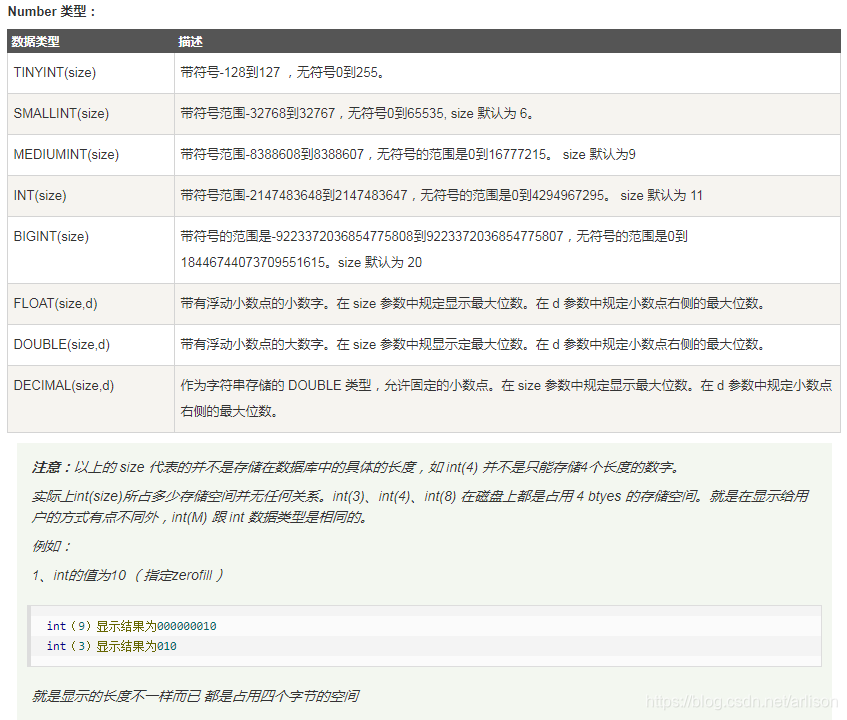
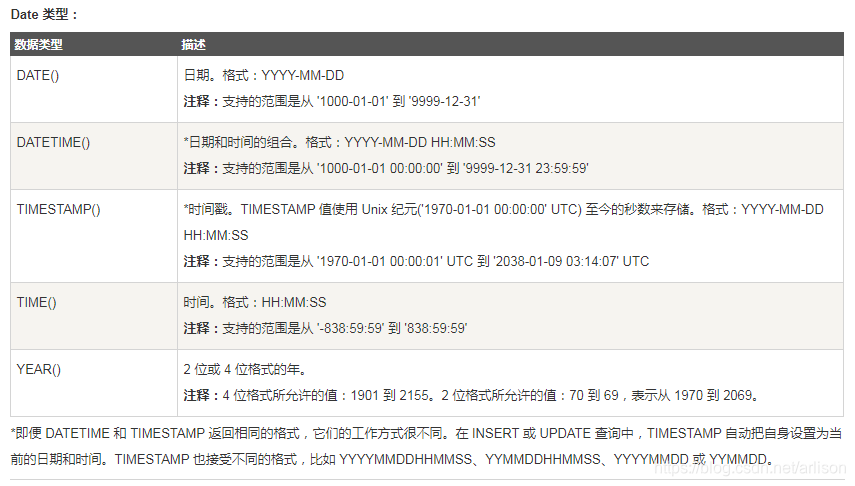
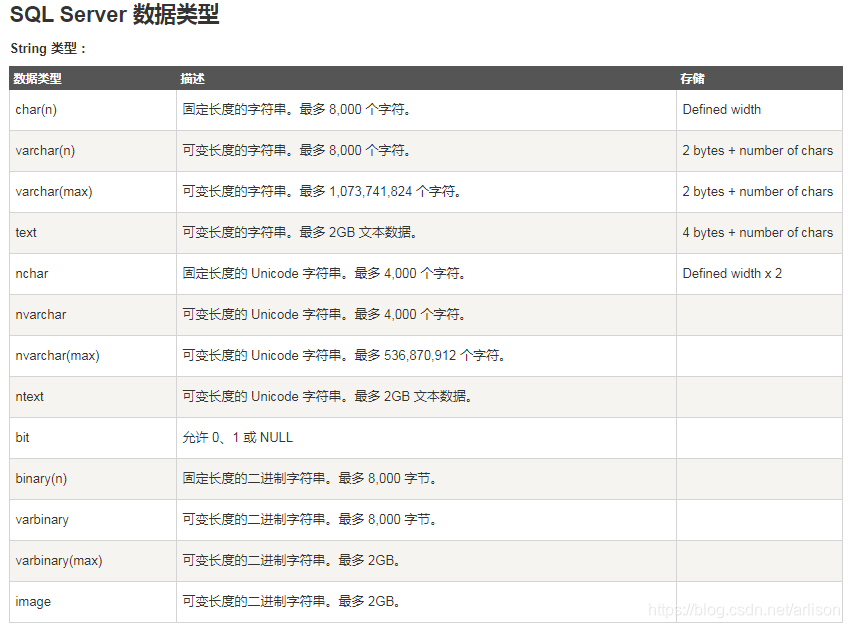
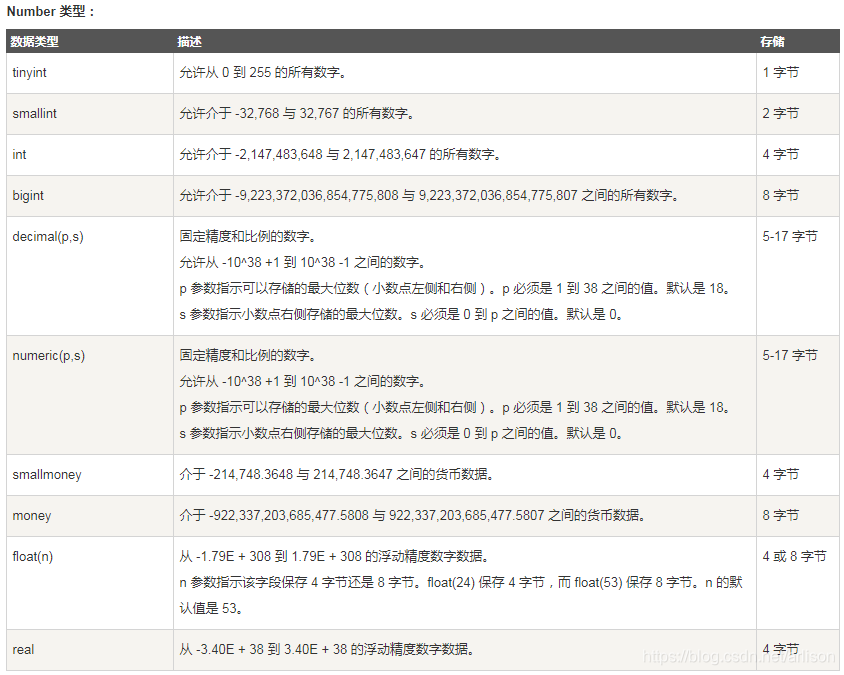
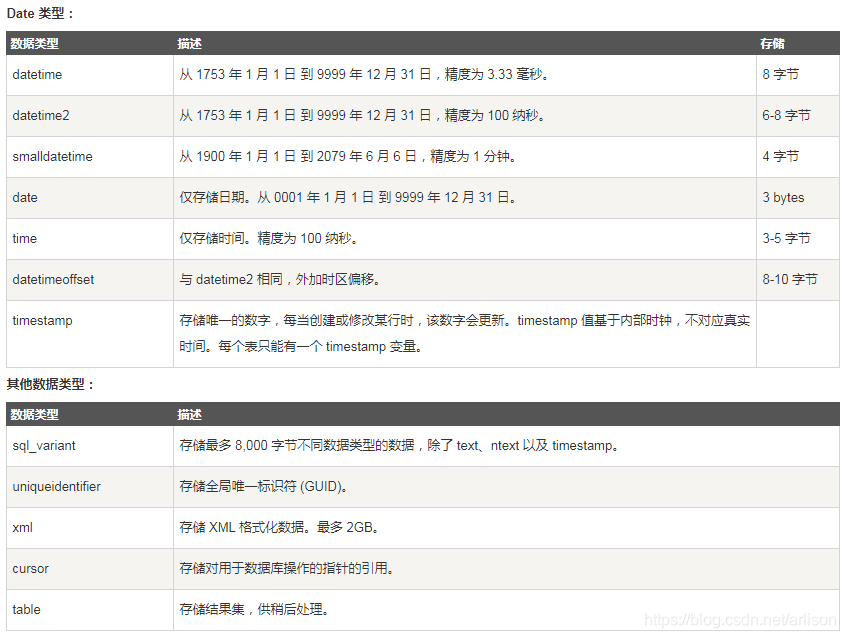
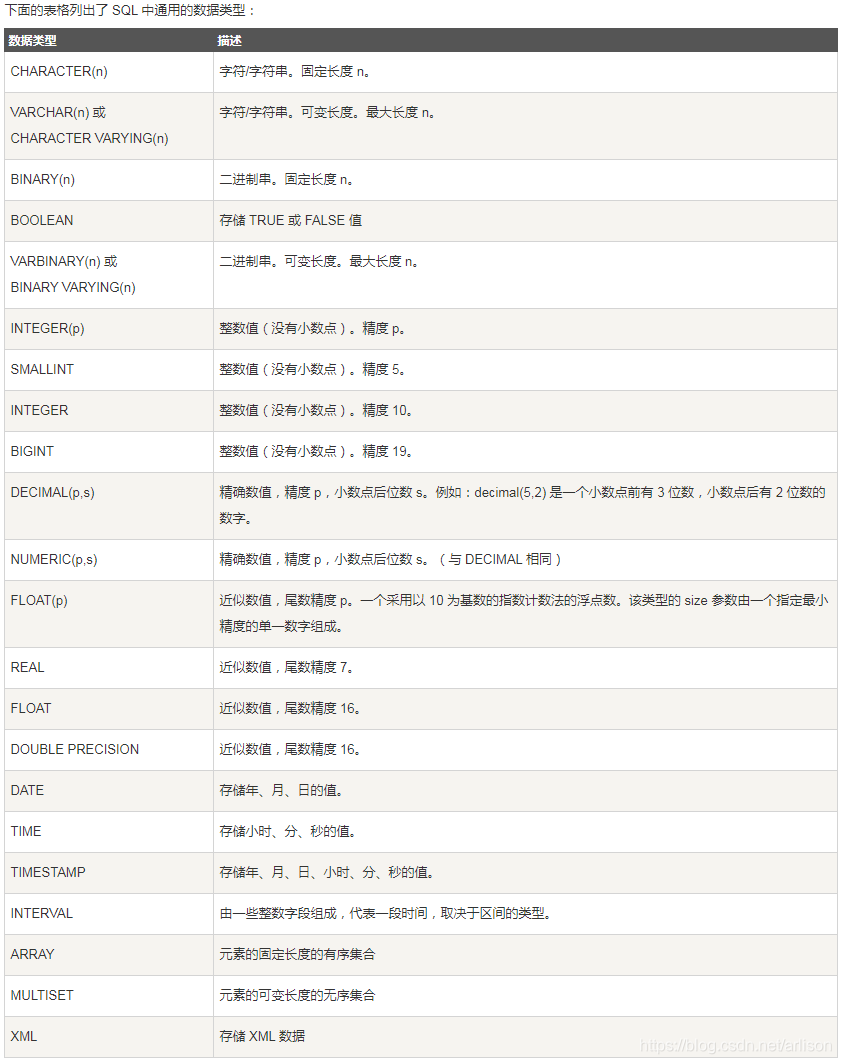
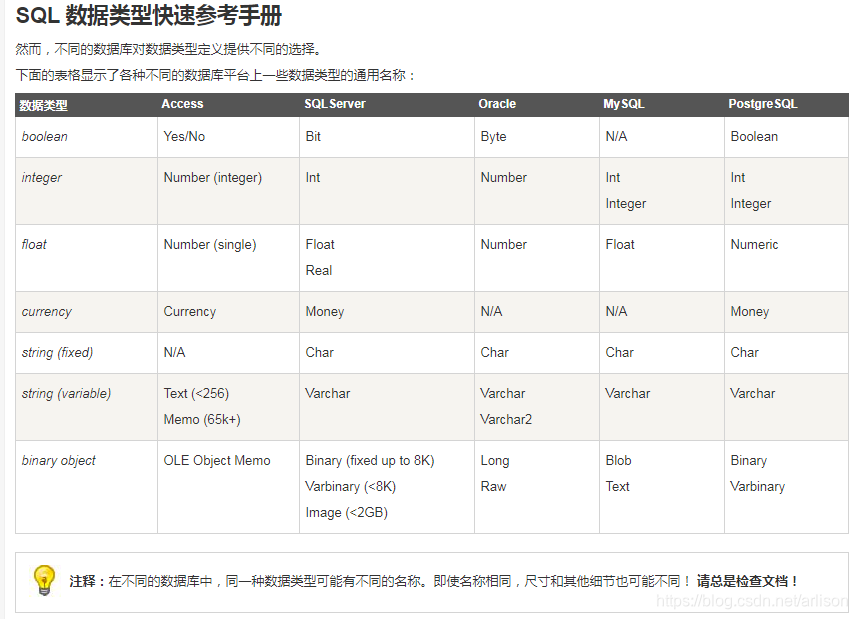
SQL数据类型:
https://www.runoob.com/sql/sql-datatypes.html

































 2533
2533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









