







 这篇博客探讨了Java编程中常见的几个问题,包括数组转换为字符串时如何避免打印地址,而是显示具体内容,详细介绍了`Arrays.toString()`方法的使用。此外,解释了Java中Map集合的Entry对象及其遍历方式,以及Lambda表达式的概念、作用和使用场景。同时,还讲解了GMT和UTC时区的区别,并提供了正则表达式的入门知识。
这篇博客探讨了Java编程中常见的几个问题,包括数组转换为字符串时如何避免打印地址,而是显示具体内容,详细介绍了`Arrays.toString()`方法的使用。此外,解释了Java中Map集合的Entry对象及其遍历方式,以及Lambda表达式的概念、作用和使用场景。同时,还讲解了GMT和UTC时区的区别,并提供了正则表达式的入门知识。
目
目录
1.2,java基础中Arrays.toString()方法
录
1.2,java基础中Arrays.toString()方法
1,数组转换String时只打印出地址,而不是字符串
public class subStringFind {
public static void main(String[] args) {
isContain("AABCD","BCDA");
}
public static boolean isContain(String s1, String s2) {
char[] chars = s1.toCharArray();
for (int i = 0; i < s1.length(); i++) {
int start=chars[0];
if (String.copyValueOf(chars).indexOf(s2)==-1){
for (int j = 1; j < s1.length(); j++) {
chars[j-1]=chars[j];
}
chars[s1.length()-1]= (char) start;
}else {
return true;
}
}
return false;
}
}方法0:直接把数组转换成字符串,使用
String.copyValueOf()
输出效果:ads
方法一:直接用数组转字符串方法效果如下
1 char[] c1 = new char[]{'a','d','s'};
2 return = Arrays.toString(c1);输出效果:[a, d, s]
方法二:使用StringBuffer转换
1 char[] c4 = new char[]{'a','d','s','a','d','s'};
2 StringBuffer sb = new StringBuffer();
3 for(int i = 1;i<c4.length;i++){
4 sb.append(c4);
5 }
6 System.out.println(c4);输出效果:adsads
方法三:推荐使用
1 char[] c4 = new char[]{'a','d','s','a','d','s'};
2 return new String(c4);输出效果:adsads
原因:
String构造方法中,
String(char[] value)
分配一个新的 String,使其表示字符数组参数中当前包含的字符序列。
在此,需要使用到数组转换字符串,推荐第三种方法。
1.2,java基础中Arrays.toString()方法
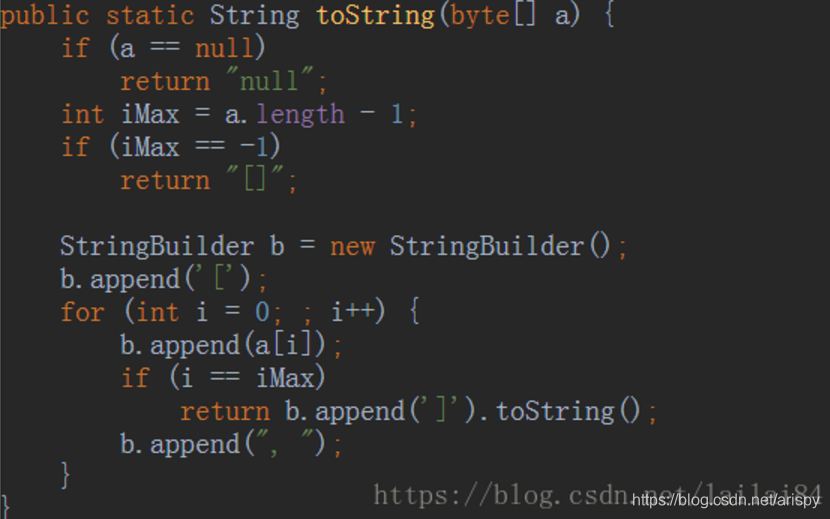
在学完数组以后,如果想要把数组中的内容打印出来,直接调用toString()方法只会打印出数组的地址,因此需要使用Arrays的toString()方法。
//代码

通过源码我们可以看出Arrays的toString()方法是一个重载的方法。方法里的参数可以是8种基本数据类型及String类型的数组
2,Java中Map集合中的Entry对象
Entry: 键值对 对象。
在Map类设计,提供了一个嵌套接口(static修饰的接口):Entry。Entry将键值对的对应关系封装成了对象,即键值对对象,这样我们在遍历Map集合时,就可以从每一个键值对(Entry)对象中获取对应的键与对应的值。
Entry为什么是静态的?
Entry是Map接口中提供的一个静态内部嵌套接口,修饰为静态可以通过类名调用。
Map集合遍历键值对的方式:
Set<Map.Entry<K,V>> entrySet(); //返回此映射中包含的映射关系的Set视图
该方法返回值是Set集合,里面装的是Entry接口类型,即将映射关系装入Set集合。
实现步骤:
1,调用Map集合中的entrySet()方法,将集合中的映射关系对象存储到Set集合中
2,迭代Set集合
3,获取Set集合的元素,是映射关系的对象
4,通过映射关系对象的方法,getKey()和getValue(),获取键值对
3,Lambda表达式 分析详解
什么是Lambda表达式
我们可以把它看成是一种闭包,它允许把函数当做参数来使用,是面向函数式编程的思想,一定程度上可以使代码看起来更加简洁。
为何需要Lambda表达式
- 在Java中,我们无法将函数作为参数传递给一个方法,也无法声明返回一个函数的方法。
- 在JavaScript中,函数参数是一个函数,返回值是另一个函数的情况非常常见的;JavaScript是一们非常典型的函数式语言
在java中我们很容易将一个变量赋值,比如int a =0;int b=a;
但是我们如何将一段代码和一个函数赋值给一个变量?这个变量应该是什么的类型?
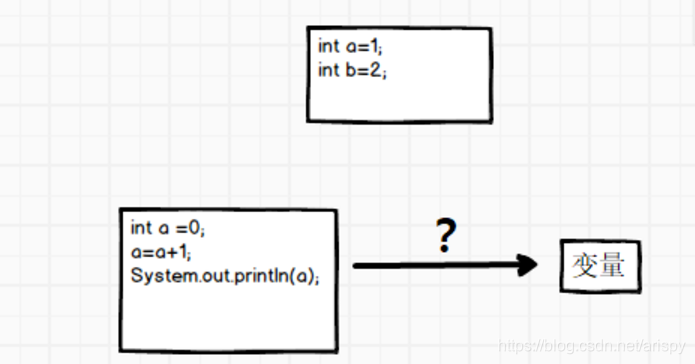
在javascript中,可以用一个对象来存储。
var t=function()
{
int a=1;
a=a+1;
alert(a);
} 在java中,直到java8的lambda的特性问世,才有办法解决这个问题
Lambda表达式基本结构
(param1,param2,param3) -> {
}看一下上述lambda表达式的语法:() -> {}(): 括号就是接口方法的括号,接口方法如果有参数,也需要写参数。只有一个参数时,括号可以省略。-> : 分割左右部分的,没啥好讲的。{} : 要实现的方法体。只有一行代码时,可以不加括号,可以不写return。
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Test1.run");
}
});
new Thread(()-> System.out.println("Test1.main"));不过看到这里我相信有些小伙伴已经许意识到了,如果接口中有多个方法时,那么按照上面的逻辑lambda表达式恐怕没办法表示了。的确是这样,并非任何接口都支持lambda表达式。
而适用于lambda表达式的接口称之为函数型接口。说白了,函数型接口就是只有一个抽象方法的接口。
-
package com.java8; import java.util.Arrays; import java.util.List; import java.util.function.Consumer; public class Test1 { public static void main(String[] args) { List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7); for (Integer i : list) { System.out.println("Test1.main :" + i); } System.out.println("-----------------"); list.forEach(new Consumer<Integer>() { public void accept(Integer integer) { System.out.println("Test1.accept :" + integer); } }); System.out.println("-----------------"); list.forEach((i) -> { System.out.println("Test1.main :" + i); }); System.out.println("-----------------"); } }
打印结果:
- Test1.main :1
- Test1.main :2
- Test1.main :3
- Test1.main :4
- Test1.main :5
- Test1.main :6
- Test1.main :7
- -----------------
- Test1.accept :1
- Test1.accept :2
- Test1.accept :3
- Test1.accept :4
- Test1.accept :5
- Test1.accept :6
- Test1.accept :7
- -----------------
- Test1.main :1
- Test1.main :2
- Test1.main :3
- Test1.main :4
- Test1.main :5
- Test1.main :6
- Test1.main :7
- -----------------
函数式接口
- 如果一个接口只有一个抽象方法,那么该接口就是一个函数式接口。
- 如果我们在某个接口上声明了@FunctionalInterface注解,那么编译器就会按照函数式接口的定义来要求该接口
- 如果某个接口只有一个抽象方法,但我们并没有给该接口声明@FunctionalInterface注解,那么编译器 依旧会将该接口看作是函数式接口
函数式接口基本语法
它们主要用在Lambda表达式和方法引用(实际上也可认为是Lambda表达式)、构造方法引用上。
如定义了一个函数式接口如下:
-
@FunctionalInterface public interface Consumer<T> { /** * Performs this operation on the given argument. * * @param t the input argument */ void accept(T t); }
那么就可以使用Lambda表达式来表示该接口的一个实现,使用 lambda 表达式时,会创建实现了函数式接口的一个匿名类实例
-
Consumer<Integer> consumer = (i) -> System.out.println("Test1.main :"+i); consumer.accept(1);
FunctionalInterface注解
关于@FunctionalInterface注解Java 8为函数式接口引入了一个新注解@FunctionalInterface,主要用于编译级错误检查,加上该注解,当你写的接口不符合函数式接口定义的时候,编译器会报错。
默认方法
函数式接口里是可以包含默认方法,因为默认方法不是抽象方法,其有一个默认实现,所以是符合函数式接口的定义的;
-
@FunctionalInterface public interface Consumer<T> { /** * Performs this operation on the given argument. * * @param t the input argument */ void accept(T t); /** * Returns a composed {@code Consumer} that performs, in sequence, this * operation followed by the {@code after} operation. If performing either * operation throws an exception, it is relayed to the caller of the * composed operation. If performing this operation throws an exception, * the {@code after} operation will not be performed. * * @param after the operation to perform after this operation * @return a composed {@code Consumer} that performs in sequence this * operation followed by the {@code after} operation * @throws NullPointerException if {@code after} is null */ default Consumer<T> andThen(Consumer<? super T> after) { Objects.requireNonNull(after); return (T t) -> { accept(t); after.accept(t); }; } }
静态方法
函数式接口里是可以包含静态方法,因为静态方法不能是抽象方法,是一个已经实现了的方法,所以是符合函数式接口的定义的;
-
@FunctionalInterface public interface Function<T, R> { R apply(T t); default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) { Objects.requireNonNull(after); return (T t) -> after.apply(apply(t)); } static <T> Function<T, T> identity() { return t -> t; } }
Object里的public方法
函数式接口里是可以包含Object里的public方法,这些方法对于函数式接口来说,不被当成是抽象方法(虽然它们是抽象方法);因为任何一个函数式接口的实现,默认都继承了Object类,包含了来自java.lang.Object里对这些抽象方法的实现;
常用的函数式接口
在jdk中通用的函数式接口如下(都在java.util.function包中):
- Supplier<String> sp = () -> "hello";//只有输出消息,没有输入参数
- Consumer<String> cp = r -> System.out.printf(r);//有一个输入参数,没有输出
- Predicate<T>:接收一个参数,返回一个boolean的结果
- Function<Integer, String> func = r -> String.valueOf(r);//有一个输入参数 有一个输出参数
- BiFunction<Integer, Integer, String> biFunc = (a, b) -> String.valueOf(a + b);//有两个输入参数 有一个输出参数
- BiConsumer<Integer, Integer> biCp = (a, b) -> System.out.printf(String.valueOf(a + b));//有两个输入参数 没有输出参数
- Function接口的使用
- @FunctionalInterface
- public interface Function<T, R> {
- R apply(T t);
- /**
- * @return a composed function that first applies the {@code before}
- * function and then applies this function
- */
- default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
- Objects.requireNonNull(before);
- return (V v) -> apply(before.apply(v));
- }
- /**
- * @return a composed function that first applies this function and then
- * applies the {@code after} function
- */
- default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
- Objects.requireNonNull(after);
- return (T t) -> after.apply(apply(t));
- }
- }
1、apply
首先我们已经知道了Function是一个泛型类,其中定义了两个泛型参数T和R,在Function中,T代表输入参数,R代表返回的结果。也许你很好奇,为什么跟别的java源码不一样,Function 的源码中并没有具体的逻辑呢?
其实这很容易理解,Function 就是一个函数,其作用类似于数学中函数的定义 ,(x,y)跟<T,R>的作用几乎一致。
𝑦=𝑓(𝑥)y=f(x)
所以Function中没有具体的操作,具体的操作需要我们去为它指定,因此apply具体返回的结果取决于传入的lambda表达式。
R apply(T t);
举个例子:
- public void test(){
- Function<Integer,Integer> test=i->i+1;
- test.apply(5);
- }
- /** print:6*/
我们用lambda表达式定义了一个行为使得i自增1,我们使用参数5执行apply,最后返回6。这跟我们以前看待Java的眼光已经不同了,在函数式编程之前我们定义一组操作首先想到的是定义一个方法,然后指定传入参数,返回我们需要的结果。函数式编程的思想是先不去考虑具体的行为,而是先去考虑参数,具体的方法我们可以后续再设置。
再举个例子:
- public void test(){
- Function<Integer,Integer> test1=i->i+1;
- Function<Integer,Integer> test2=i->i*i;
- System.out.println(calculate(test1,5));
- System.out.println(calculate(test2,5));
- }
- public static Integer calculate(Function<Integer,Integer> test,Integer number){
- return test.apply(number);
- }
- /** print:6*/
- /** print:25*/
我们通过传入不同的Function,实现了在同一个方法中实现不同的操作。在实际开发中这样可以大大减少很多重复的代码,比如我在实际项目中有个新增用户的功能,但是用户分为VIP和普通用户,且有两种不同的新增逻辑。那么此时我们就可以先写两种不同的逻辑。除此之外,这样还让逻辑与数据分离开来,我们可以实现逻辑的复用。
当然实际开发中的逻辑可能很复杂,比如两个方法F1,F2都需要两个个逻辑AB,但是F1需要A->B,F2方法需要B->A。这样的我们用刚才的方法也可以实现,源码如下:
- public void test(){
- Function<Integer,Integer> A=i->i+1;
- Function<Integer,Integer> B=i->i*i;
- System.out.println("F1:"+B.apply(A.apply(5)));
- System.out.println("F2:"+A.apply(B.apply(5)));
- }
- /** F1:36 */
- /** F2:26 */
也很简单呢,但是这还不够复杂,假如我们F1,F2需要四个逻辑ABCD,那我们还这样写就会变得很麻烦了。
2、compose和andThen
compose和andThen可以解决我们的问题。先看compose的源码
- default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
- Objects.requireNonNull(before);
- return (V v) -> apply(before.apply(v));
- }
compose接收一个Function参数,返回时先用传入的逻辑执行apply,然后使用当前Function的apply。
- default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
- Objects.requireNonNull(after);
- return (T t) -> after.apply(apply(t));
- }
andThen跟compose正相反,先执行当前的逻辑,再执行传入的逻辑。
这样说可能不够直观,我可以换个说法给你看看
compose等价于B.apply(A.apply(5)),而andThen等价于A.apply(B.apply(5))。
-
public void test(){ Function<Integer,Integer> A=i->i+1; Function<Integer,Integer> B=i->i*i; System.out.println("F1:"+B.apply(A.apply(5))); System.out.println("F1:"+B.compose(A).apply(5)); System.out.println("F2:"+A.apply(B.apply(5))); System.out.println("F2:"+B.andThen(A).apply(5)); } /** F1:36 */ /** F1:36 */ /** F2:26 */ /** F2:26 */
我们可以看到上述两个方法的返回值都是一个Function,这样我们就可以使用建造者模式的操作来使用。
B.compose(A).compose(A).andThen(A).apply(5);
- Predicate接口的使用
Predicate的源码跟Function的很像,我们可以对比这两个来分析下。直接上Predicate的源码:
-
public interface Predicate<T> { /** * Evaluates this predicate on the given argument. */ boolean test(T t); /** * Returns a composed predicate that represents a short-circuiting logical * AND of this predicate and another. When evaluating the composed * predicate, if this predicate is {@code false}, then the {@code other} * predicate is not evaluated. */ default Predicate<T> and(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) && other.test(t); } /** * Returns a predicate that represents the logical negation of this * predicate. */ default Predicate<T> negate() { return (t) -> !test(t); } /** * Returns a composed predicate that represents a short-circuiting logical * OR of this predicate and another. When evaluating the composed * predicate, if this predicate is {@code true}, then the {@code other} * predicate is not evaluated. */ default Predicate<T> or(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) || other.test(t); } /** * Returns a predicate that tests if two arguments are equal according * to {@link Objects#equals(Object, Object)}. */ static <T> Predicate<T> isEqual(Object targetRef) { return (null == targetRef) ? Objects::isNull : object -> targetRef.equals(object); } }
Predicate是个断言式接口其参数是<T,boolean>,也就是给一个参数T,返回boolean类型的结果。跟Function一样,Predicate的具体实现也是根据传入的lambda表达式来决定的。
boolean test(T t);
接下来我们看看Predicate默认实现的三个重要方法and,or和negate
-
default Predicate<T> and(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) && other.test(t); } default Predicate<T> negate() { return (t) -> !test(t); } default Predicate<T> or(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) || other.test(t); }
这三个方法对应了java的三个连接符号&&、||和!,基本的使用十分简单,我们给一个例子看看:
-
int[] numbers= {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15}; List<Integer> list=new ArrayList<>(); for(int i:numbers) { list.add(i); } Predicate<Integer> p1=i->i>5; Predicate<Integer> p2=i->i<20; Predicate<Integer> p3=i->i%2==0; List test=list.stream().filter(p1.and(p2).and(p3)).collect(Collectors.toList()); System.out.println(test.toString()); /** print:[6, 8, 10, 12, 14]*/
我们定义了三个断言p1,p2,p3。现在有一个从1~15的list,我们需要过滤这个list。上述的filter是过滤出所有大于5小于20,并且是偶数的列表。
假如突然我们的需求变了,我们现在需要过滤出奇数。那么我不可能直接去改Predicate,因为实际项目中这个条件可能在别的地方也要使用。那么此时我只需要更改filter中Predicate的条件。
- List test=list.stream().filter(p1.and(p2).and(p3.negate())).collect(Collectors.toList());
- /** print:[7, 9, 11, 13, 15]*/
我们直接对p3这个条件取反就可以实现了。是不是很简单?
isEqual这个方法的返回类型也是Predicate,所以我们也可以把它作为函数式接口进行使用。我们可以当做==操作符来使用。
-
List test=list.stream() .filter(p1.and(p2).and(p3.negate()).and(Predicate.isEqual(7))) .collect(Collectors.toList()); /** print:[7] */ Supplier接口 @FunctionalInterface public interface Supplier<T> { /** * Gets a result. * * @return a result */ T get(); }
看语义,可以看到,这个接口是一个提供者的意思,只有一个get的抽象类,没有默认的方法以及静态的方法,传入一个泛型T的,get方法,返回一个泛型T
下面,我们用一个小案例,来看看这个接口,是干什么用的
-
Supplier<String> supplier = String::new; System.out.println(supplier.get());//"" Supplier<Emp> supplierEmp = Emp::new; Emp emp = supplierEmp.get(); emp.setName("dd"); System.out.println(emp.getName());//dd
可以看到,这个接口,只是为我们提供了一个创建好的对象,这也符号接口的语义的定义,提供者,提供一个对象,
直接理解成一个创建对象的工厂,就可以了;
Emp对象定义如下
-
public static class Emp { private String name; public Emp() { } public Emp(String name) { super(); this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } }4,GMT和UTC时区
GMT就是格林尼治标准时间,它是Greenwich mean time的简称。
UTC则是协调世界时间,它是coordinated universal time的时间。它是一种更精确的GMT。
GMT和全球24个时区的划分
「夏日节约时间」Daylight Saving Time(简称D.S.T.),是指在夏天太阳升起的比较早时,将时钟拨快一小时,以提早日光的使用,在英国则称为夏令时间(Summer Time)。这个构想于1784年由美国班杰明·富兰克林提出来,1915年德国成为第一个正式实施夏令日光节约时间的国家,以削减灯光照明和耗电开支。自此以后,全球以欧洲和北美为主的约70个国家都引用这个做法。
正则表达式的语法十分简单,虽然各种编程语言在正则表达式的语法上有细节上的区别,不过主要部分如下:
- [a-z]表示所有小写字母,[0-9]表示所有数字,[amk]表示a、m或k。
- +表示字符重复1或者多次,*表示字符重复0或者多次。在使用+或者*时,正则表达式遵从
maximal munch的原则,也就是说它匹配能够匹配到的最大字符串。 - a|z 表示匹配字符’a’或者’z’
- ?表示字符出现0次或者1次
- 是正则表达式中的escape符号,\*表示的就是’*’这个字符,而不是它在正则表达式中的功能。
- . 表示出了换行符之外的任何字符,而^表示出了紧接它的字符以外的任何字符
- ^ 匹配字符串的开始,$ 匹配字符串的结尾。
回到我们前面的例子中,我们用正则表达式[ab]*abb来匹配由a、b组成的,以abb结尾的字符串。这里[ab]*abb即可以这样解读:a或者b重复0或者多次,然后是abb的字符串。


















 2454
2454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











