




 本文介绍了一个使用Python爬取并分析《少年的你》豆瓣短评的项目,包括数据抓取、词云制作、情感分析和PowerBI展示。通过审查网页结构,利用request和xpath爬取前25页数据,使用jieba进行分词和词频统计,snownlp进行情感分析。数据展示部分包含评分分布和每日评分趋势图。未来计划改进代码结构和实现断点续爬功能。
本文介绍了一个使用Python爬取并分析《少年的你》豆瓣短评的项目,包括数据抓取、词云制作、情感分析和PowerBI展示。通过审查网页结构,利用request和xpath爬取前25页数据,使用jieba进行分词和词频统计,snownlp进行情感分析。数据展示部分包含评分分布和每日评分趋势图。未来计划改进代码结构和实现断点续爬功能。
本文以《少年的你》为例, 简单实现了爬取数据–保存数据–分析数据–图表展示的全流程. 此为第一个版本, 有很多需要地方将在后续版本中改进.
具体代码见github: https://github.com/shaoecho/DataAnalysis_01_douban
文章目录
1. 豆瓣短评数据抓取
首先, 去网上查一下豆瓣的反爬机制, 豆瓣从2017.10月开始全面禁止爬取数据:
- 白天1分钟最多可以爬取40次,晚上一分钟可爬取60次数,超过此次数则会封禁IP地址.
- 非登录状态下,最多能爬200条数据.
- 登录状态下,最多能爬500条数据, 也就是前25页.
本文抓取的是《少年的你》豆瓣热门短评前25页的数据.
1.1 网页分析 : 审查网页元素,获取目标网站树状结构
目标网页网址为:
https://movie.douban.com/subject/30166972/comments?sort=new_score&status=P
如下图所示:
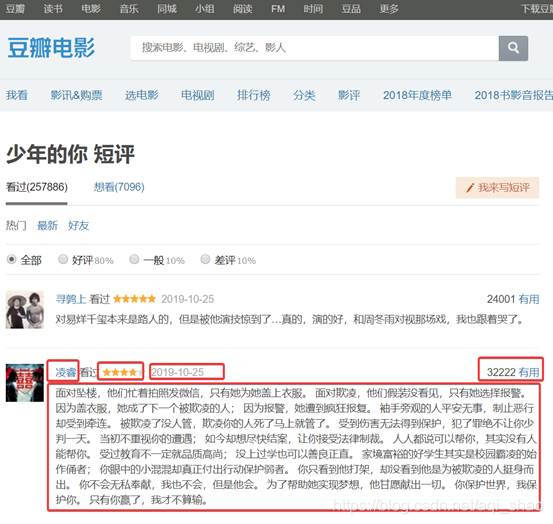
本此数据爬取主要获取的内容有:
- 评论用户ID
- 评论内容
- 评分
- 评论日期
- 支持数
分析一下网页结构, 每一页都有20条评论, 即有20个”comment-item”中,要爬取的数据都在comment-item中, 所以在每个页面依次提取20个”comment-item”中的数据即可.
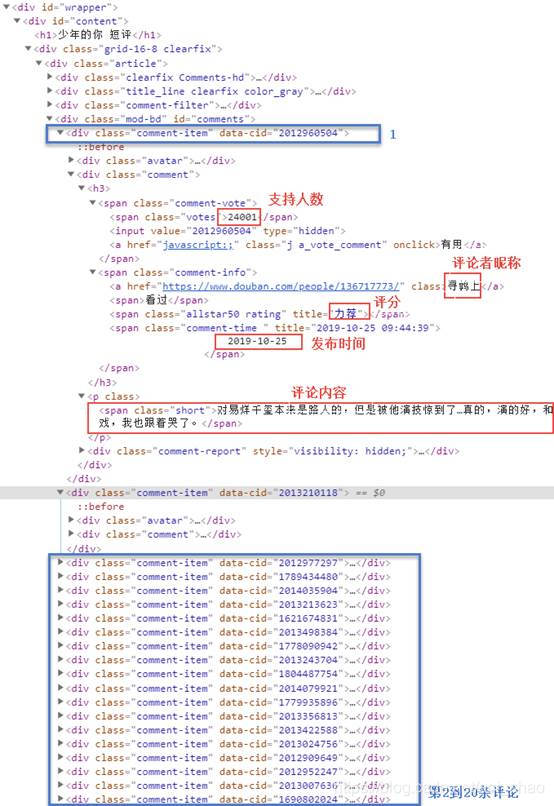
最后再分析一下翻页的逻辑:
第1页URL如下:
https://movie.douban.com/subject/30166972/comments?start=0&limit=20&sort=new_score&status=P
第2页URL如下:
https://movie.douban.com/subject/30166972/comments?start=20&limit=20&sort=new_score&status=P
第3页URL如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3074
3074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









