






 本文详细介绍如何在Scrapy框架中使用动态User-Agent避免被目标网站封禁,包括安装fake_useragent库、定义随机UA中间件及在settings中激活。
本文详细介绍如何在Scrapy框架中使用动态User-Agent避免被目标网站封禁,包括安装fake_useragent库、定义随机UA中间件及在settings中激活。
scarpy通过动态的user-agent可以避免被网站封禁,这篇文章主要讲解如何在scarpy中配置动态的UA
1.安装fake_useragent
直接进入cmd
pip install fake_useragent

我这里显示已经安装好了
2.在middleware中添加随机UA的中间件
首先导入我们需要的包
from fake_useragent import UserAgent
然后定义这个类 我已经写好了 直接上代码
#定义随机UA的类
class RandomUserAgentMiddleware(object):
#这里我们需要采用继承的方式
def __init__(self,crawler):
super(RandomUserAgentMiddleware,self).__init__()
#首先生成self.ua
self.ua = UserAgent()
#由于ua有不同的类型,包括IE,chrome,firefox等等所以我们定义一下ua_type
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE","random")
#这里之所以我们可以在settings中设置RANDOM_UA_TYPE = XXX ,XXX为我们需要的浏览器UA
@classmethod
def from_crawler(cls,crawler):
return cls(crawler)
def process_request(self,request,spider):
#这里我们应用了动态语言的比较好用的一点即方法里可以定义方法我们采用getattr的方法获取了ua.ua_type
def get_ua():
return getattr(self.ua,self.ua_type)
#这里注释掉是方便调试用
#random_agent = get_ua()
#print(random_agent)
#最后把headers全部设置为随机的就OK了
request.headers.setdefault("User-Agent",get_ua())
3.在setting中激活中间件和ua_type
DOWNLOADER_MIDDLEWARES = {
#这里是把我们的随机UA启用
'igandan_crawl.middlewares.RandomUserAgentMiddleware': 543,
#这里我们需要禁用掉默认的scarpy的UA,scrapy默认的UA就是'scrapy'容易被判断为爬虫并且被禁用所以需要设置为NONE即禁用
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None
}
RANDOM_UA_TYPE = 'Chrome' #这里可以随机设置 ie/firefox/chrome等等
好啦这些全部设置好就算完成了随机UA的设置了我们看一下结果
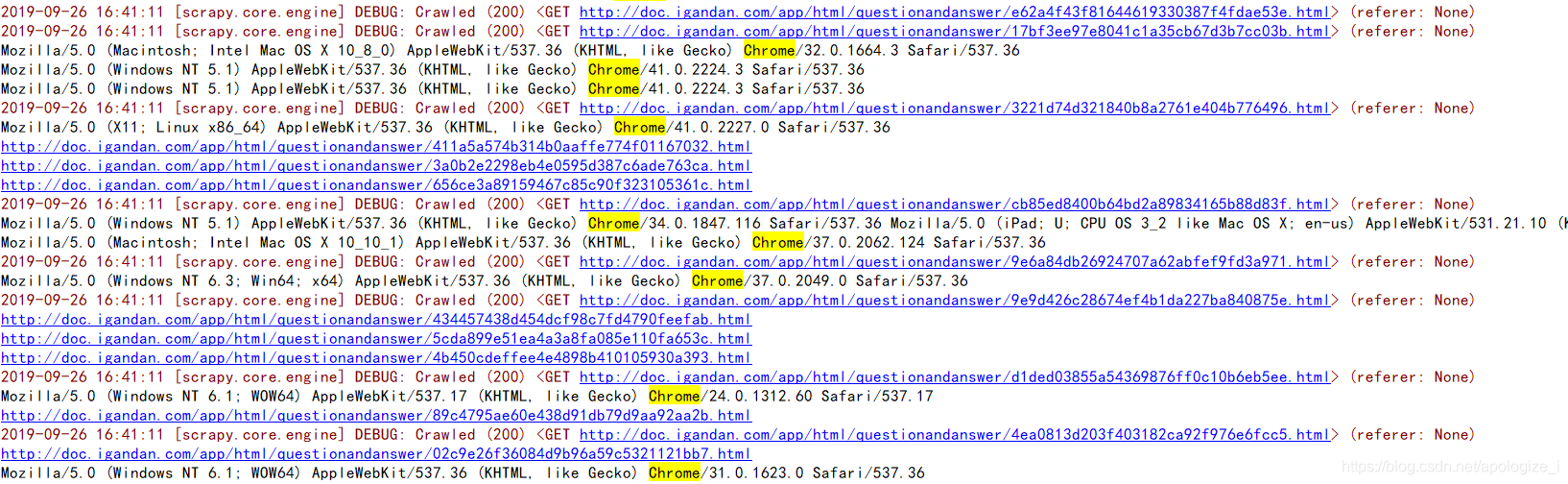
看出打印的结果全是我们设置的Chrome的UA啦 当然也可以设置为random就是所有浏览器的random ua了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









