




一、什么是web自动化测试
自动化(Automation)是指机器设备、系统或过程(生产、管理过程)在没有人或较少人的直接参与下,按照人的要求,经过自动检测、信息处理、分析判断、操纵控制,实现预期的目标的过程。
这是教科书里面的自动化的定义,回归到自动化测试其实自动化测试就是什么呢?
指的是测试的过程在没有人或者较少的人为的干预的情况下进行的测试,再简单点说就是用程序或者脚本来测试程序,那么在web自动化测试中主要用来把测试人员从繁琐的内容中解放出来,主要做一些比如需要多次输入,多次运行的,比如我们用边界值,等价类设计的很多测试数据需要执行,比如业务流程需要执行很多遍的时候我们就可以使用web自动化测试
二、web自动化测试的工具
现在主流的web测试工具我们常用的就是selenium的那一套工具包括
- 浏览器一般选择chrome
- 浏览器对应的driver(chromedriver)
- Python
- Selenium库
三、web自动化测试的环境安装
- 浏览器安装 下载浏览器下一步按照就好了
- chromedriver 下载 可以到 npmmirror.com/
- 注:100的大版本对的上就Ok了
四、web自动化测试的方法
Web自动化测试一般使用设计测试用例的方法跟功能测试相同,使用等价类划分,边界值,因果图,场景法等等就好了
Web自动化测试实施的使用我们一般会采用po模式设计
PO是page object的简称,核心思想是通过对界面元素的封装减少冗余代码,同时在后期维护中,若元素定位发生变化, 只需要调整页面元素封装的代码,提高测试用例的可维护性、可读性。
PO模式可以把一个页面分为三层,对象库层、操作层、业务层。
对象库层:封装定位元素的方法。
操作层:封装对元素的操作。
业务层:将一个或多个操作组合起来完成一个业务功能。
比如登录:需要输入帐号、密码、点 击登录三个操作。
测试脚本只需要调用业务层代码就可以完成
当出现页面需要的时候只需要测试代码可以完全不用修改只需要修改操作层就好了
五、web自动化测试的流程实施
web自动化测试流程和功能测试基本一致:
下面我们已登录需求为例
(1)需求分析
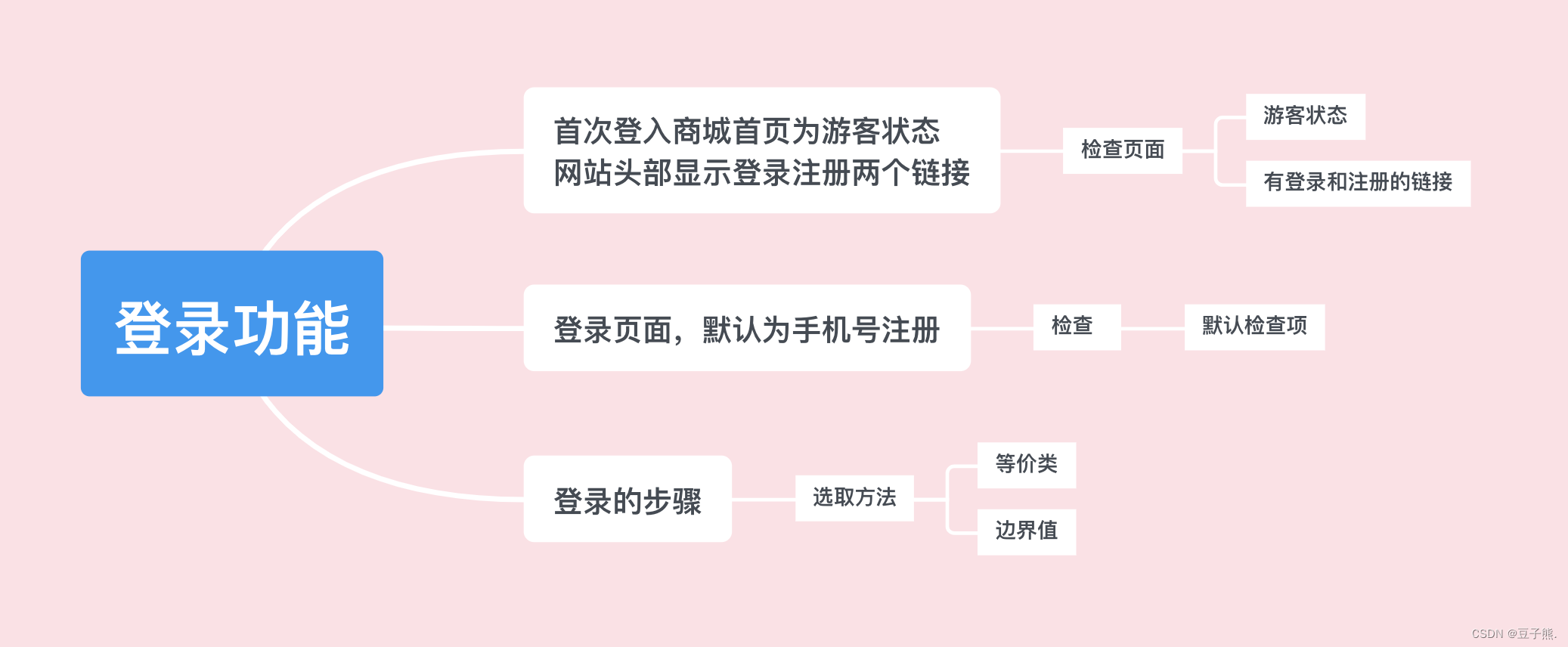
这里我们以手机登录为例
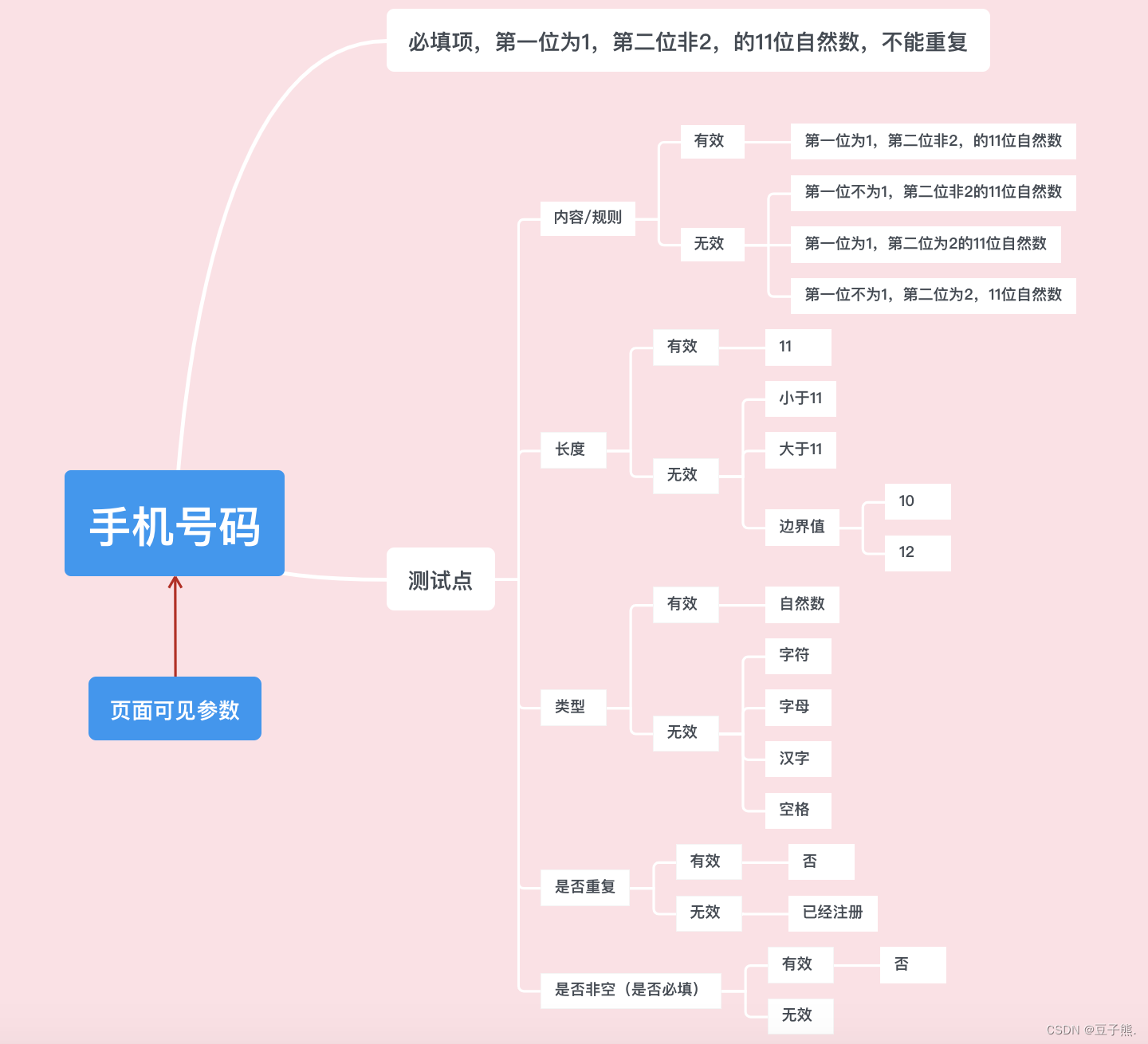
(2)设计测试用例与测试数据
自动化测试测试用例不用像手工测试设计的那么详细

【下方为测试数据】
[
{
"username": "21888888888",
"pwd": "123456",
"code": "8888",
"ast_msg": "账号格式不匹配",
"desc": "用户名错误"
},
{
"username": "12888888888",
"pwd": "123456",
"code": "8888",
"ast_msg": "账号格式不匹配",
"desc": "用户名错误"
},
{
"username": "1088888888",
"pwd": "123456",
"code": "8888",
"ast_msg": "账号格式不匹配",
"desc": "用户名错误"
},
{
"username": "138888888889",
"pwd": "123456",
"code": "8888",
"ast_msg": "账号格式不匹配",
"desc": "用户名错误"
},
{
"username": "32888888888",
"pwd": "123456",
"code": "8888",
"ast_msg": "账号格式不匹配",
"desc": "用户名错误"
},
{
"username": " ",
"pwd": "123456",
"code": "8888",
"ast_msg": "用户名不能为空",
"desc": "用户名错误"
}
]
(3)搭建web自动化测试环境
在上面环境安装那里已经搭建了
(4)设计web自动化测试框架
一般测试po模式的内容包括

(5)编写代码
在po文件夹中创建page_login
from selenium.webdriver.common.by import By
from utils import UtilsDriver
from base.page_base import BasePage
# 界面对象层
class PageLogin(BasePage):
# 账号元素
def find_username(self):
return self.driver.find_element_by_id("username")
# return self.driver.find_element(*self.username)
# return self.get_element(self.username)
# 密码元素
def find_pwd(self):
return self.driver.find_element(By.ID,"password")
# 验证码元素
def find_vcode(self):
return self.driver.find_element_by_id("verify_code")
# 按钮开始登录元素
def find_login_btn(self):
# return self.driver.find_element_by_name("sbtbutton")
return self.driver.find_element(By.NAME,"sbtbutton")
# 操作层
class HandleLogin(object):
def __init__(self):
self.page_login=PageLogin()
def input_username(self,username):
self.page_login.find_username().send_keys(username)
def input_pwd(self,pwd):
self.page_login.find_pwd().send_keys(pwd)
def input_vcode(self,code):
self.page_login.find_vcode().send_keys(code)
def click_login_btn(self):
self.page_login.find_login_btn().click()
# 业务层
# 输入用户名密码验证码 点击登录
class LoginProxy(object):
def __init__(self):
self.handle_login = HandleLogin()
def login(self,username,pwd,code):
self.handle_login.input_username(username)
self.handle_login.input_pwd(pwd)
self.handle_login.input_vcode(code)
self.handle_login.click_login_btn()
脚本执行代码 创建test_login
# from selenium import webdriver
from po.page_home import HomeProxy
from po.page_login import LoginProxy
from utils import UtilsDriver,get_data
import time
import pytest
import allure
@allure.feature("登录功能")
class Test_login:
def setup_class(self):
self.login_p=LoginProxy()
self.home_p=HomeProxy()
def setup(self):
# 进入首页
UtilsDriver.get_driver().get("http://127.0.0.1/")
# 进入到login界面
self.home_p.go_login_page()
def teardown_class(self):
time.sleep(2)
UtilsDriver.quit_driver()
@pytest.mark.parametrize(["username","pwd","code","asrt_msg"],get_data())
@allure.story("登录用户名错误")
def test_login_username_error(self,username,pwd,code,asrt_msg):
self.login_p.login(username,pwd,code)
time.sleep(1)
# 登录是否成功的预期结果
res = UtilsDriver.get_msg()
assert asrt_msg in res
(6)执行测试用例
可以使用pytest控制测试用例的执行
@pytest.mark.parametrize([“username”,“pwd”,“code”,“asrt_msg”],get_data())
[pytest]
addopts = -s --alluredir report
testpaths = ./script
python_files = test_*.py *test.py
python_classes = Test_*
python_functions = test_*
(7)生成测试报告
可以使用allure生成测试报告
最后
如果你想学习自动化测试,那么下面这套视频应该会帮到你很多
如何逼自己1个月学完自动化测试,学完即就业,小白也能信手拈来,拿走不谢,允许白嫖....
最后我这里给你们分享一下我所积累和整理的一些文档和学习资料,有需要直接领取就可以了!

以上内容,对于软件测试的朋友来说应该是最全面最完整的备战仓库了,为了更好地整理每个模块,我也参考了很多网上的优质博文和项目,力求不漏掉每一个知识点,很多朋友靠着这些内容进行复习,拿到了BATJ等大厂的offer,这个仓库也已经帮助了很多的软件测试的学习者,希望也能帮助到你。


















 1998
1998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









