




1.Yolov基本使用
1.创建conda虚拟环境
conda create -n yolov5 python=3.7.5
conda activate yolov5
pip install -r requirements_yolov5.txt
requirements_yolov5.txt 内容如下
gitpython
ipython # interactive notebook
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.1
Pillow>=7.1.2
psutil # system resources
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
thop>=0.1.1 # FLOPs computation
torch>=1.7.0 # see https://pytorch.org/get-started/locally (recommended)
torchvision>=0.8.1
tqdm>=4.64.0
tensorboard>=2.4.1
pandas>=1.1.4
seaborn>=0.11.0
下载代码
git clone -b v7.0 --single-branch https://github.com/ultralytics/yolov5.git
2.PT文件导出为onnx
执行下面的指令会,下载pt文件,并且转换为对应的onnx文件
python export.py --weights yolov5s.pt --include onnx
3.如果修改ONNX的输出参数
1.onnx的输出参数
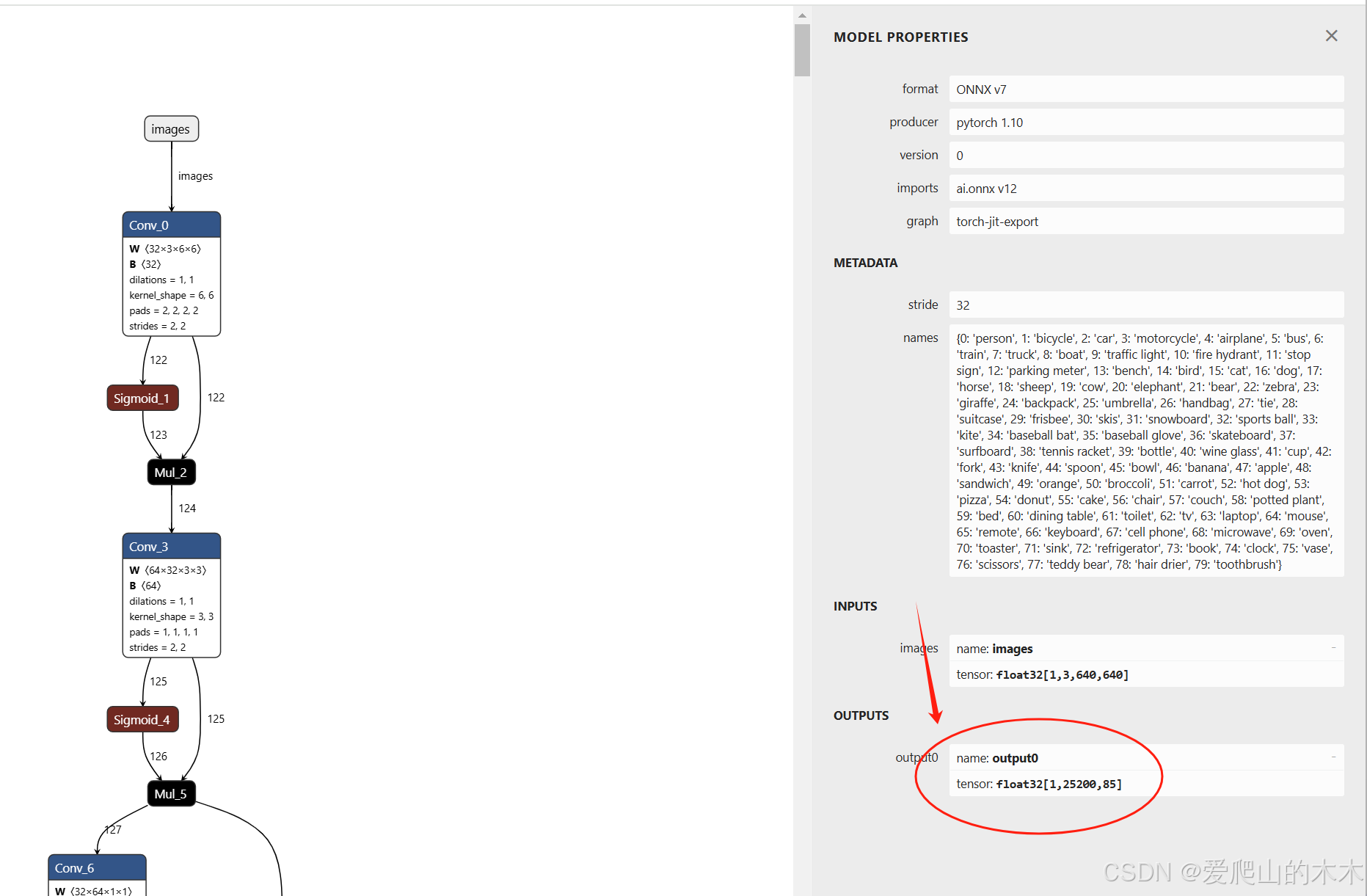
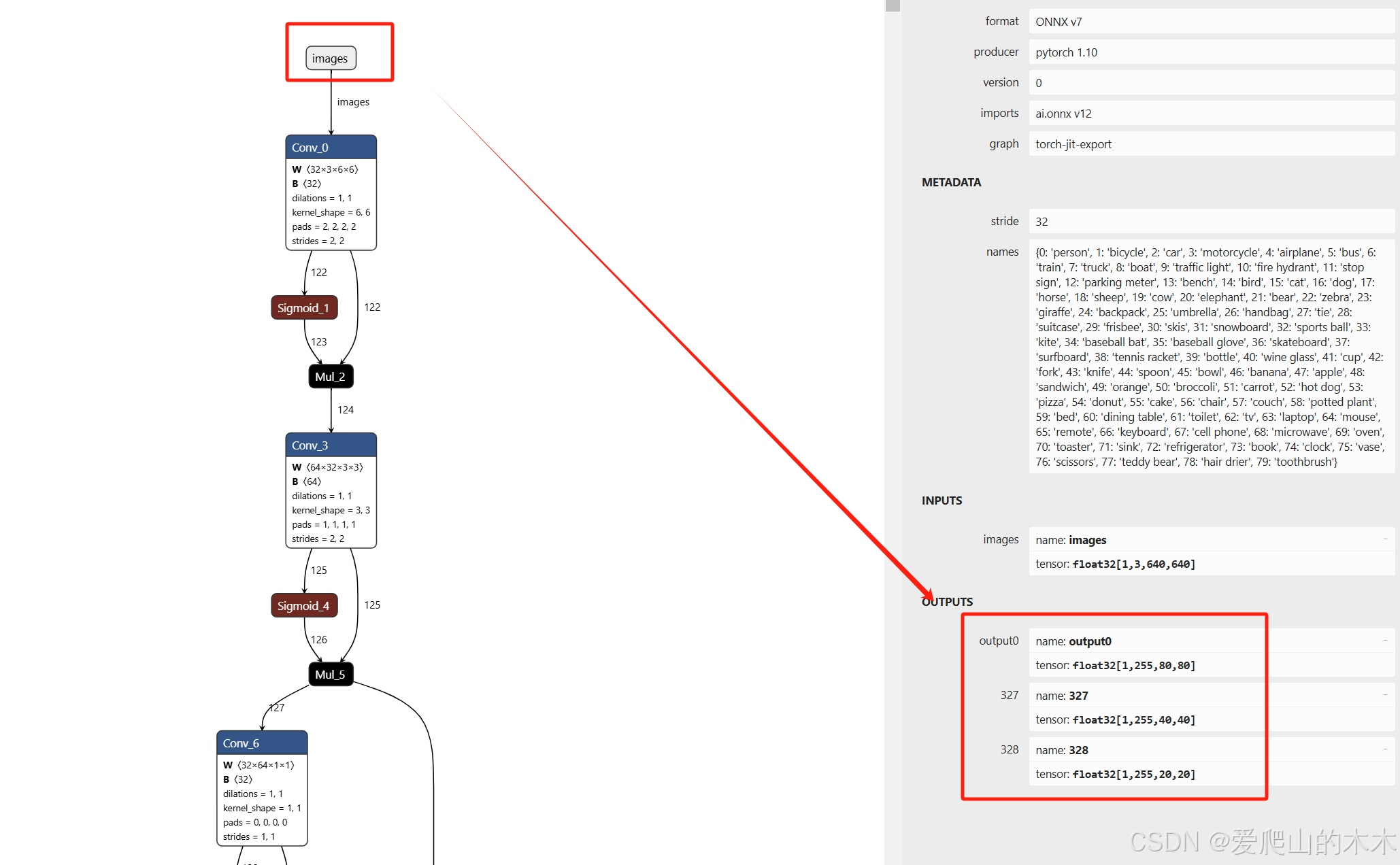
原始代码导出的ONNX,把yolov5输出的三个层的数据,合并为一个输出,如下面图输出为【1,25200,85】,这个在嵌入式设备上数据快比较大,不太好处理,用CPU处理后续nms的时候稍微有点麻烦,可以修改导出的代码变为3个output,【255,80,80】【255,40,40】【255,20,20】
2.代码修改如下
参考资料:https://github.com/sophgo/sophon-demo/blob/release/sample/YOLOv5/docs/YOLOv5_Export_Guide.md
yolov5/models/yolo.py
#大约在54行左右
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
if isinstance(self, Segment): # (boxes + masks)
xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf.sigmoid(), mask), 4)
else: # Detect (boxes only)
xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, self.na * nx * ny, self.no))
# return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
# return x if self.training else (torch.cat(z, 1), x) # 4个输出
return x # 3个输出
# return x if self.training else (torch.cat(z, 1)) # 1个输出
export.py 注释下面三行
# shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
metadata = {'stride': int(max(model.stride)), 'names': model.names} # model metadata
# LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} with output shape {shape} ({file_size(file):.1f} MB)")




















 3287
3287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











