







 该文介绍了如何复现关于模糊粗糙集的文献算法,包括三角变换、梯形变换以及高斯隶属度函数等。通过数据预处理,如MinMaxScaler和LabelEncoder,对案例数据进行处理,并运用维度约简方法进行属性选择,以提高依赖度。最终展示了属性约简的结果和过程。
该文介绍了如何复现关于模糊粗糙集的文献算法,包括三角变换、梯形变换以及高斯隶属度函数等。通过数据预处理,如MinMaxScaler和LabelEncoder,对案例数据进行处理,并运用维度约简方法进行属性选择,以提高依赖度。最终展示了属性约简的结果和过程。
前言
使用于入门模糊粗糙集,且需要复现文献算法。
一、文献
Richard Jensen and Qiang Shen .Semantics-Preserving Dimensionality Reduction[J]:
Rough and Fuzzy-Rough-Based Approaches.
二、复现
2.0 文献算法与案例

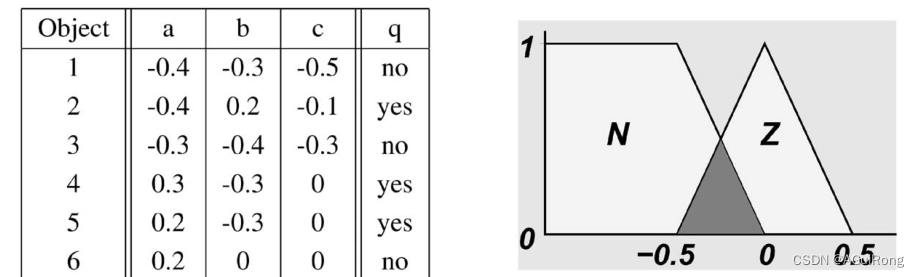
2.1 编写函数功能
import numpy as np
import copy
import itertools
def triangular_transform_x(x):
x = np.array(x)
result = np.zeros_like(x) # 初始化结果向量为全0向量
result[x < -0.5] =0
result[x > 0.5] =0
# 元素x<0的时候2x+1
result[(x < 0) & (x>=-0.5)] = 2 * x[(x < 0) & (x>=-0.5)] + 1
# 元素x>=0的时候-2x+1
result[(x >= 0) & (x<=0.5) ] = -2 * x[(x >= 0) & (x<=0.5)] + 1
return result
import numpy as np
def trapezoidal_transform_x(x):
x = np.array(x)
result = np.zeros_like(x) # 初始化结果向量为全0向量或结果矩阵为全0矩阵
# 元素≥0的时候为0
result[x >= 0] = 0
# 小于等于-0.5的时候为1
result[x <= -0.5] = 1
# 在(-0.5,0)取值为-2x
result[(x > -0.5) & (x < 0)] = -2 * x[(x > -0.5) & (x < 0)]
return result
# 高斯隶属度函数
def gaussian(X, mean, std):
return np.exp(-np.power(X - mean, 2) / (2 * np.power(std, 2)))
def infmax(μ_F_values,Di): # 4
values = []
for index in range(n):
values.append(max(1-μ_F_values[index],Di[index]))
return min(values)
def μ_F(combined_matrix,P):# 3
'''
希望各位同学朋友能够关注、评论
后续私聊,会发完整算法。
pass
'''
def μ_P_Di(P,x,Di):# 2
μ_F_values = μ_F(combined_matrix,P)# 3
Values = []
for F in range(μ_F_values.shape[0]):
Values.append(min(μ_F_values[F][x],infmax(μ_F_values[F],Di)))# 4
return max(Values)
def POS_P(P,x):# 1
low_operator = []
for Di in Di_s:
low_operator.append(μ_P_Di(P,x,Di))
return max(low_operator)
def get_dependency(P):
if len(P)==0:return 0
temp_dependency = sum([POS_P(P,x) for x in range(n)])/n
return temp_dependency2.2 数据预处理
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelEncoder
from itertools import product
import numpy as np
import pandas as pd
# 数据导入需要修改
data = np.array([[-0.4,-0.3,-0.5],
[-0.4,0.2,-0.1],
[-0.3,-0.4,-0.3],
[0.3,-0.3,0],
[0.2,-0.3,0],
[0.2,0,0]])
U = np.array([0,1,0,1,1,0])
X1 = trapezoidal_transform_x(data)
X2 = triangular_transform_x(data)
matrix_list = [X1,X2]
combined_matrix = np.stack(matrix_list, axis=0) # (2, 6, 3)==(k,n,m)
Di_s = []
class_ = tuple([np.where(U==i)[0] for i in set(U)])
for class_i in class_:
mask = np.zeros(len(U), dtype=bool)
mask[class_i]=True
Di_s.append(mask)
n,m=data.shape
k = len(set(U))2.3 运行
R = [] # 约简结果
Epoch__dependency=0
tempT_dependency=-1
all_columns = set([i for i in range(data.shape[1])])# 列用0,1,2,m-1来表示m个变量
while Epoch__dependency!=tempT_dependency:
# 当前轮次的效果
T=copy.deepcopy(R)
Epoch__dependency = get_dependency(T)
tempT_dependency = tempT_dependency
for r in [i for i in all_columns if i not in R]:
R.append(r)
temp_dependency = get_dependency(R)
print(temp_dependency,tempT_dependency)
if temp_dependency>tempT_dependency:
T = copy.deepcopy(R) # 此时将r添加进去了
tempT_dependency = temp_dependency
R.remove(r)
R=copy.deepcopy(T)
print("属性:",R,"\n")2.4 结果
[0.33333333] -1
[0.4] [0.33333333]
[0.26666667] [0.4]
属性: [1]
0.5666666666666667 [0.4]
0.5333333333333333 0.5666666666666667
属性: [1, 0]
0.5666666666666667 0.5666666666666667
属性: [1, 0]
总结
实现论文中的算法,并将文献的案例进行复现,并经过检验。
(希望各位同学朋友能够关注、评论,后续私聊,会发完整算法。)

















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









