







前言
今日解读文章来自:
原文链接🔗
原文解读
业务中单机数据库往往有可能成为瓶颈。

这篇文章也是强调了读写分离的目的。一起来看看是如何在Spring应用中配置读写分离的数据库。
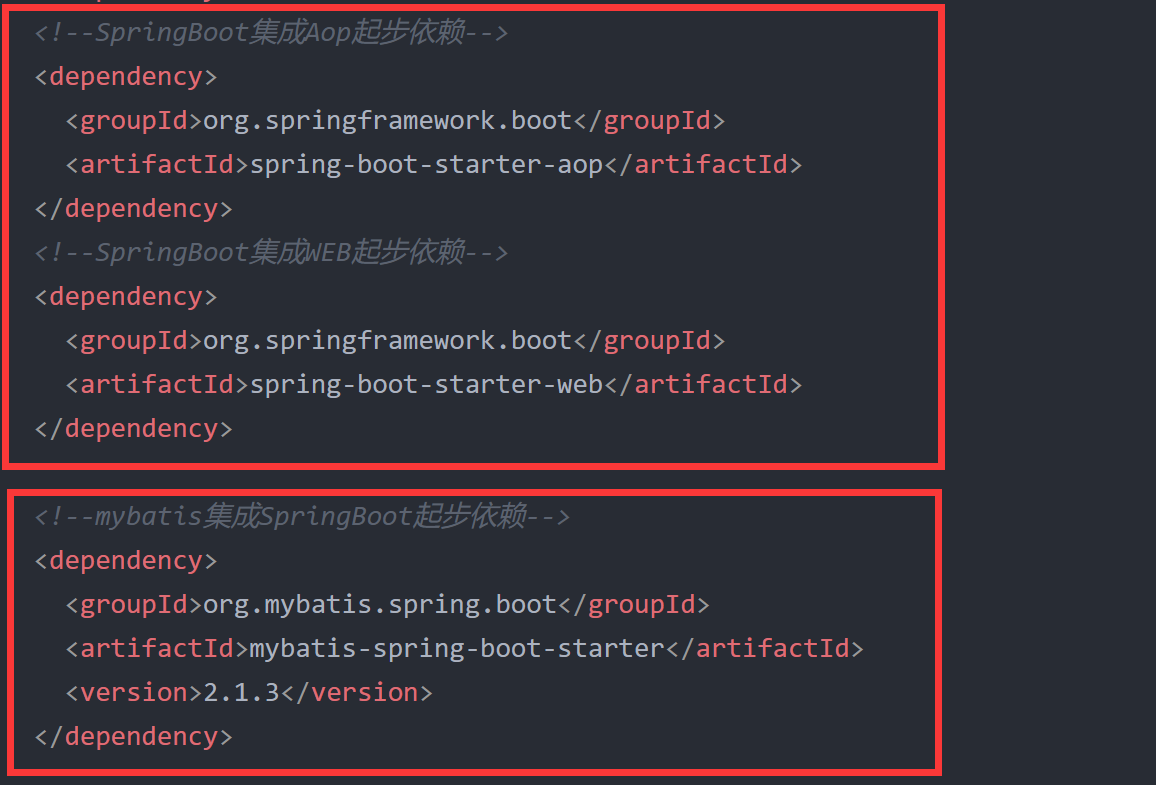
首先是准备工作,可以看到作者使用了基本的web和mybatis。为啥我会分开框中这两部分呢?不知道大家有没有发现官方库的命名方式为spring-boot-starter-xxx,三方库的命名方式为xxx-spring-boot-starter。
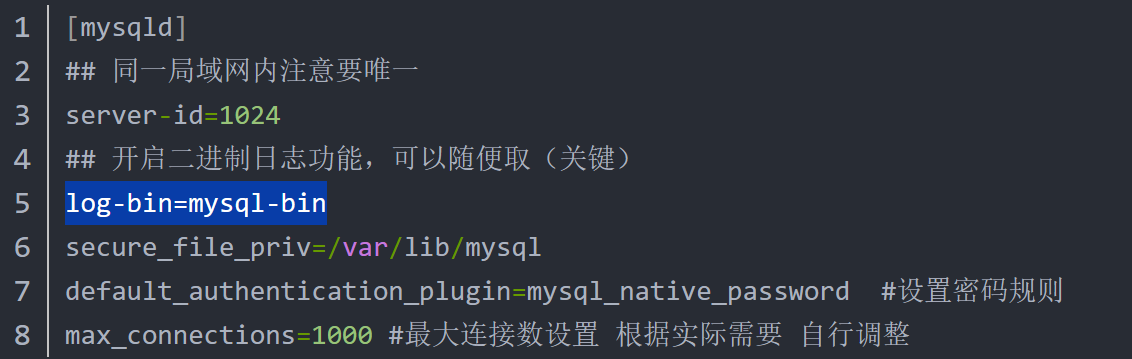
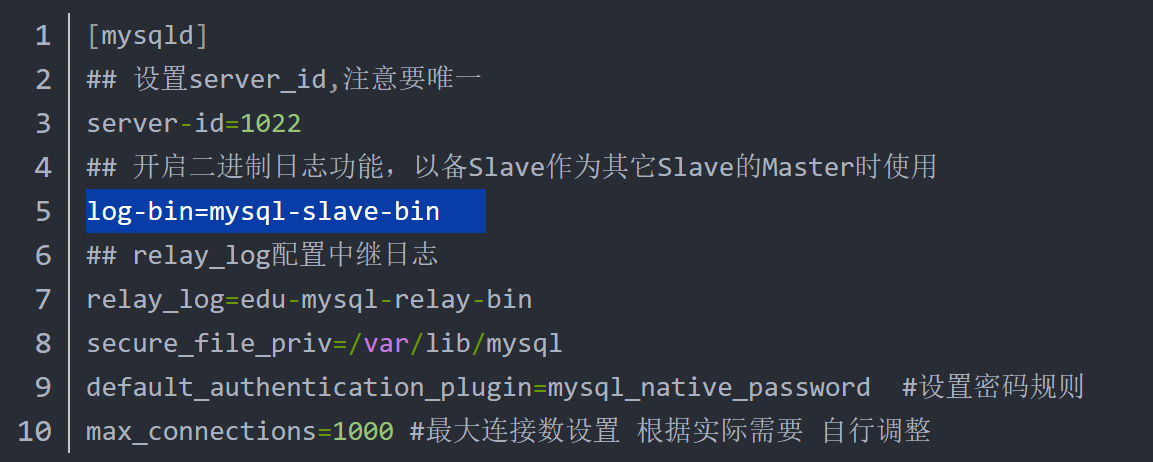
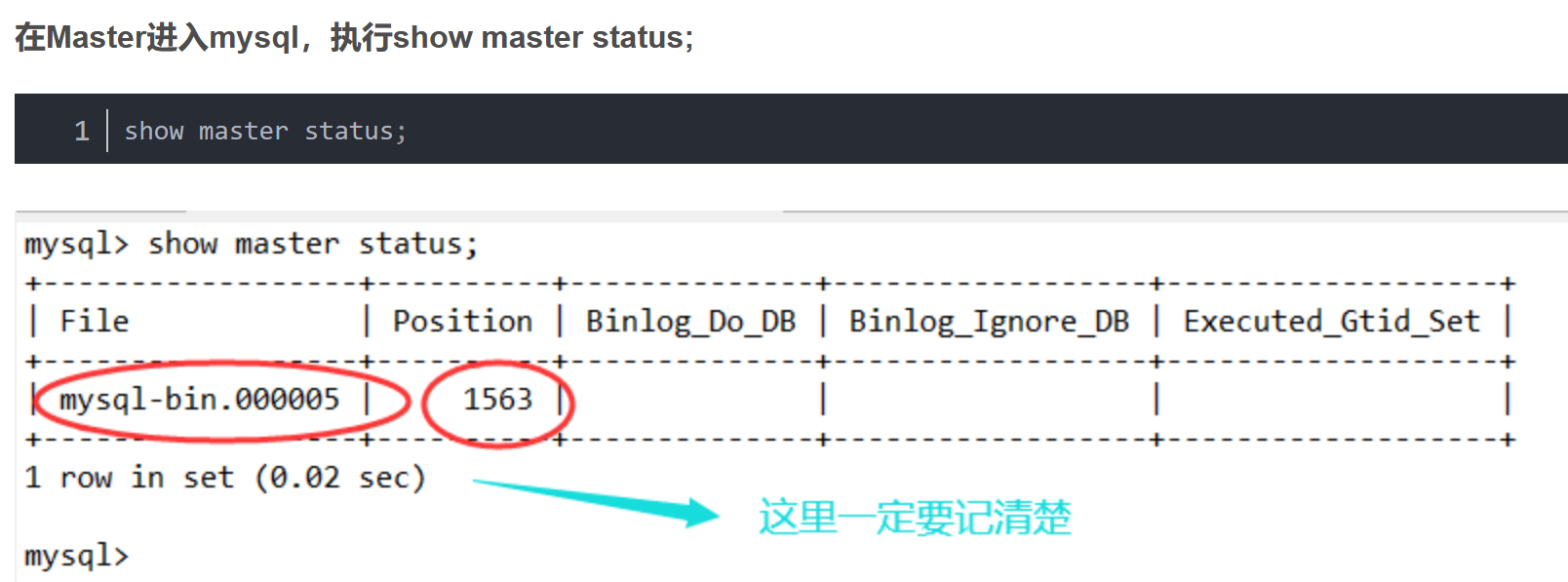
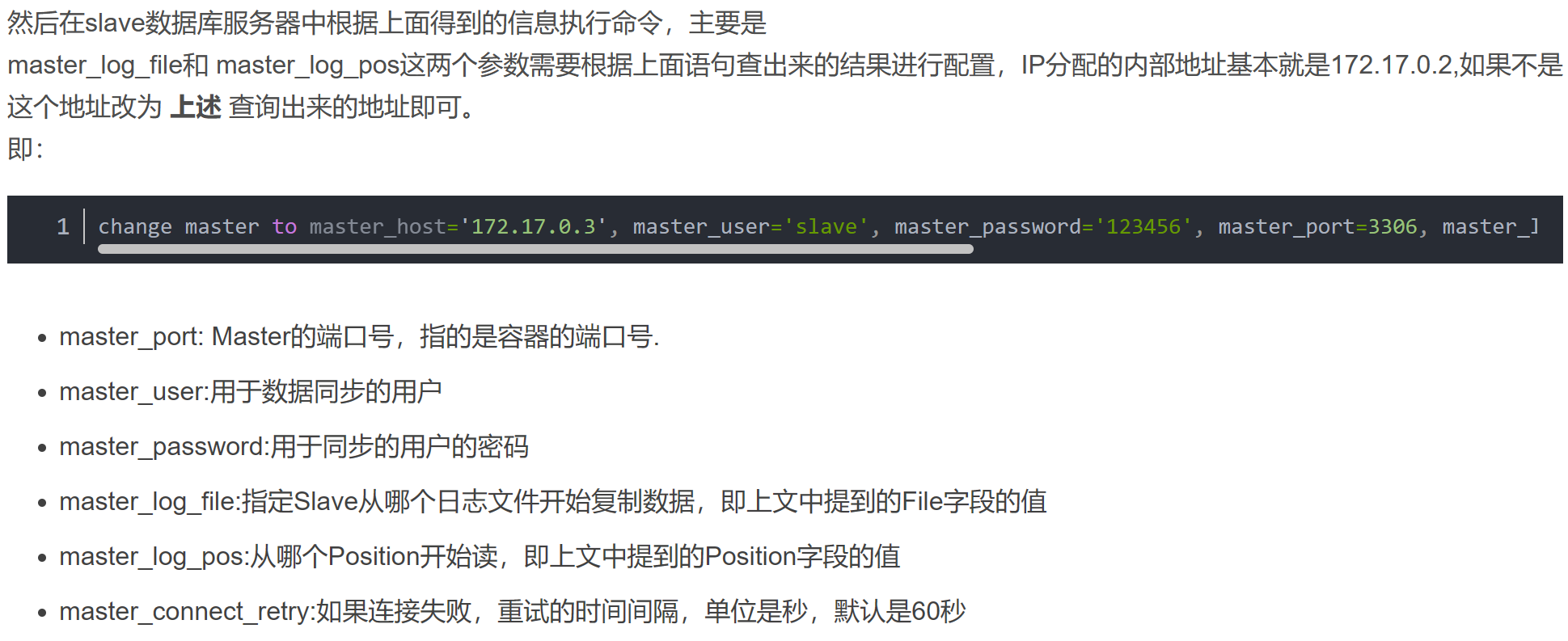
除了项目需要准备之外,数据库也需要准备。作者介绍的还是比较全的,大致过程是通过master的state更新salve的信息,按照master-binlog和salve-binlog启动两个db。线上不停机创建的化其实要根据mysqldump的信息启动从数据库。
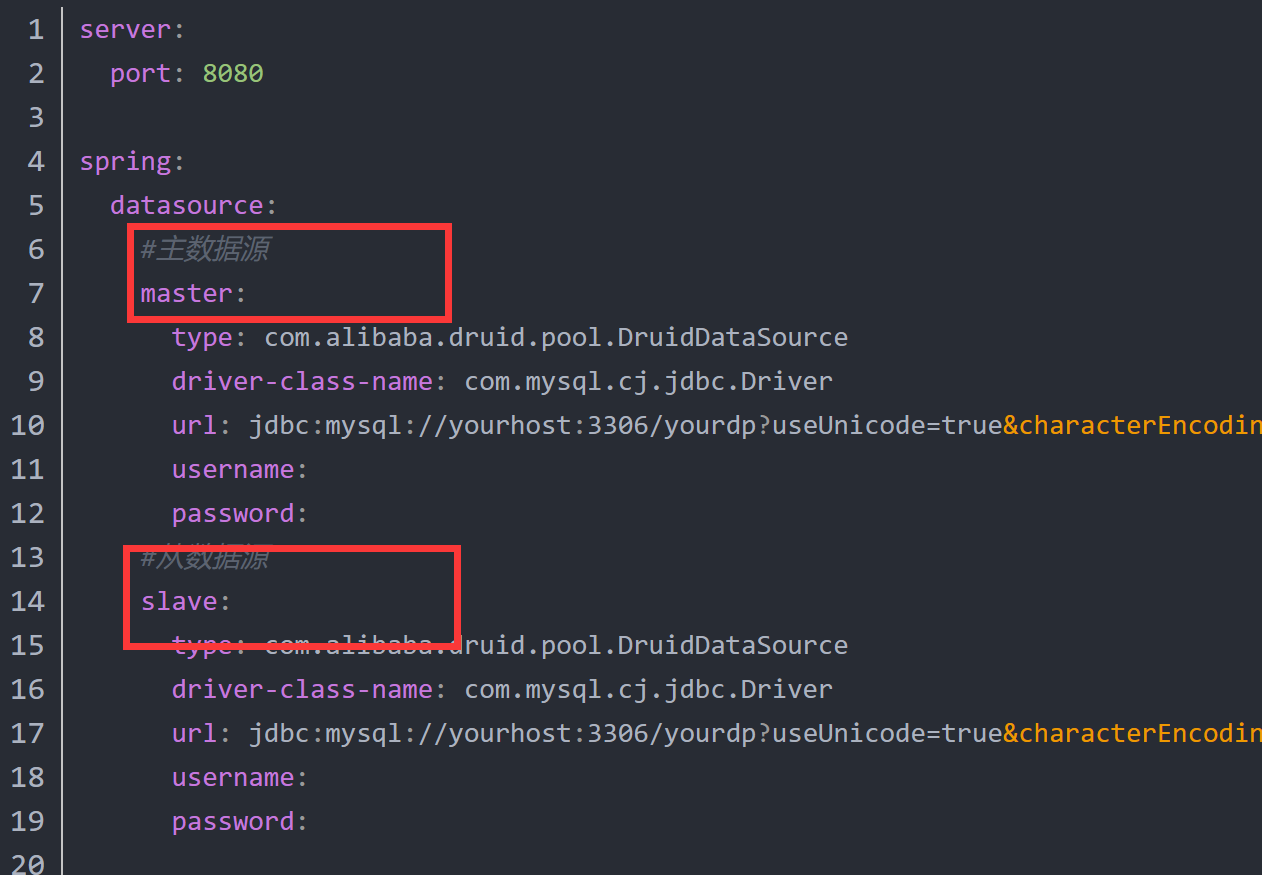
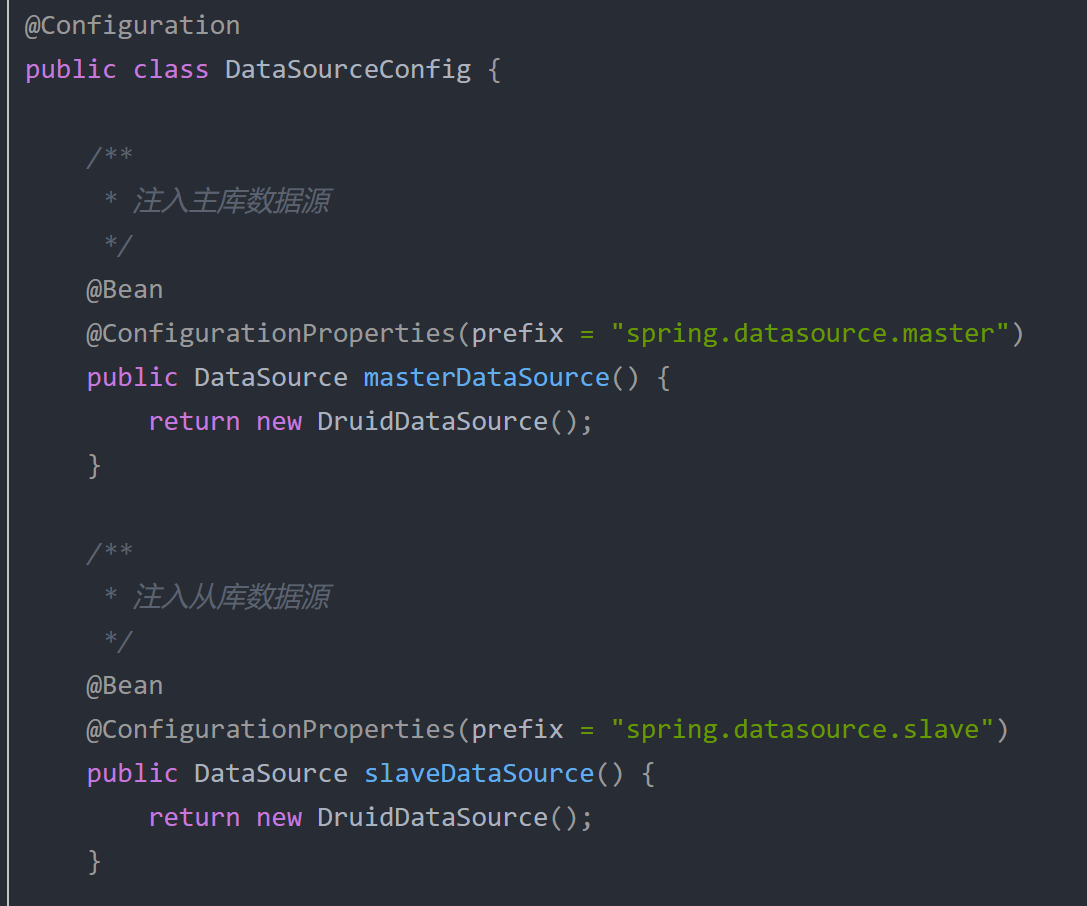
配置文件更新下之前配置的两个数据库,并注入到容器中。
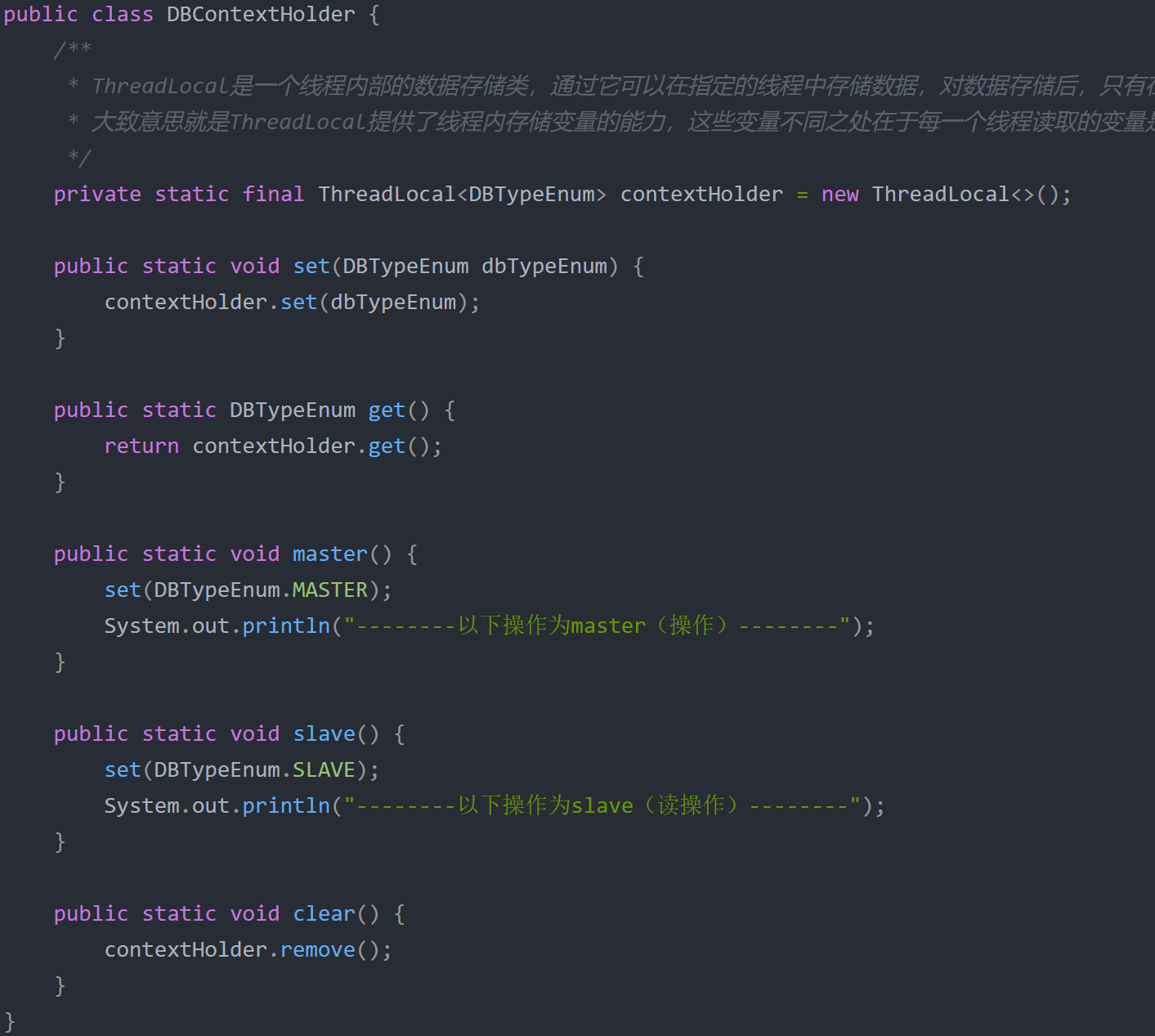
之后实现一个线程级别的数据源切换,这里只切换使用哪个数据源的标识。
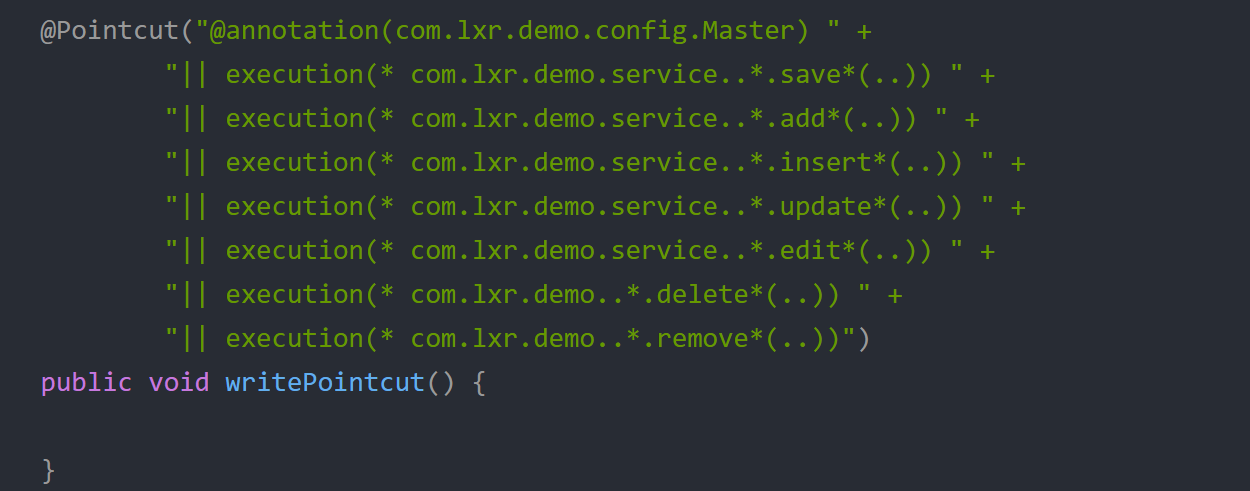
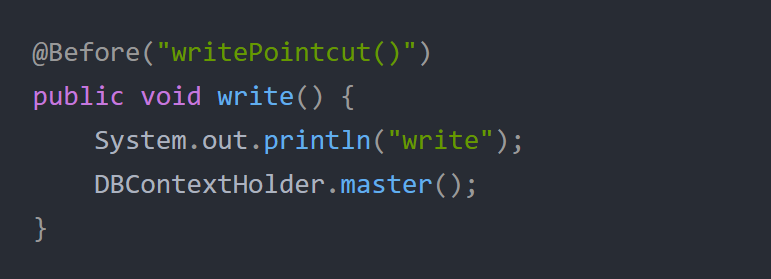
这部分会切换成写,其他会切换成读。
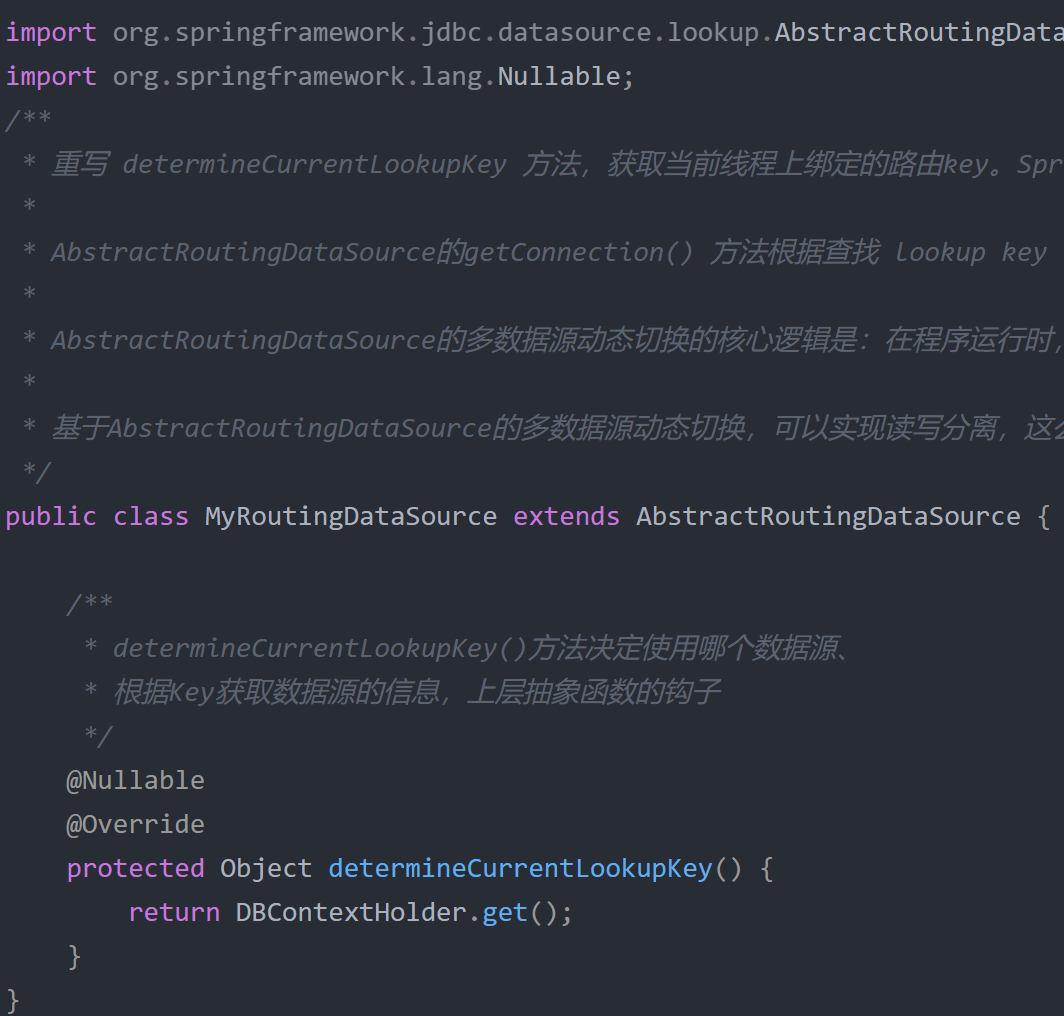
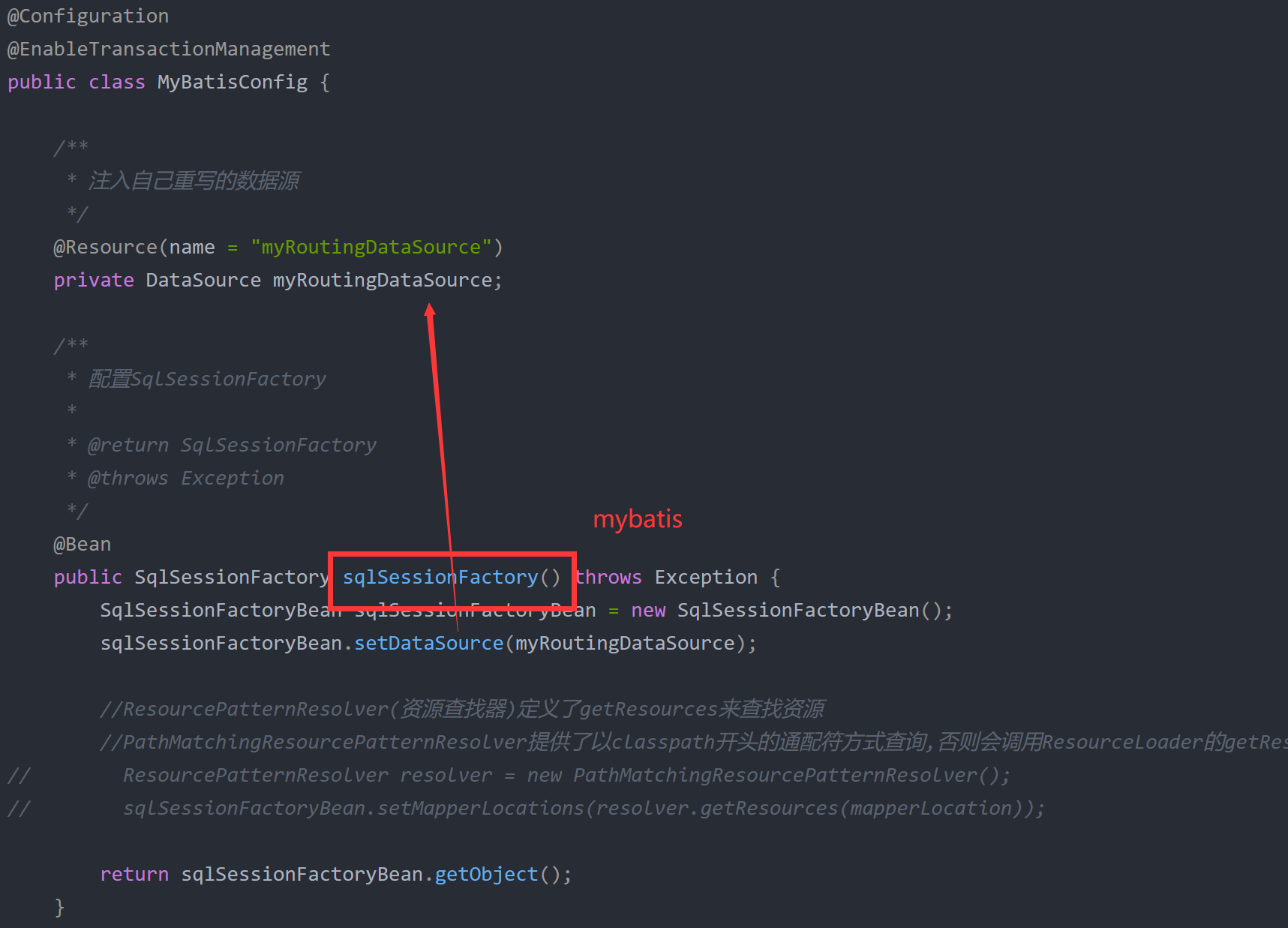
数据源路由时会根据之前线程内存储的数据进行选择,之后配置mybatis从刚刚配置的动态数据源中获取。
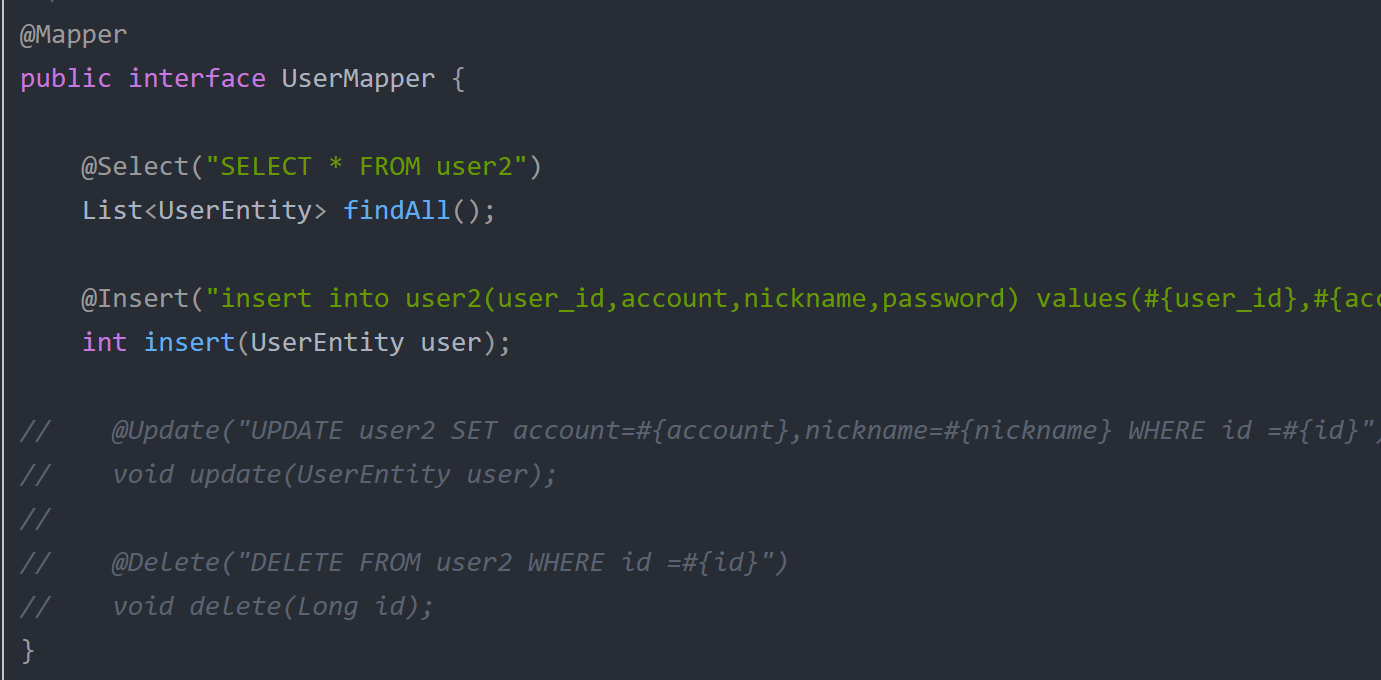
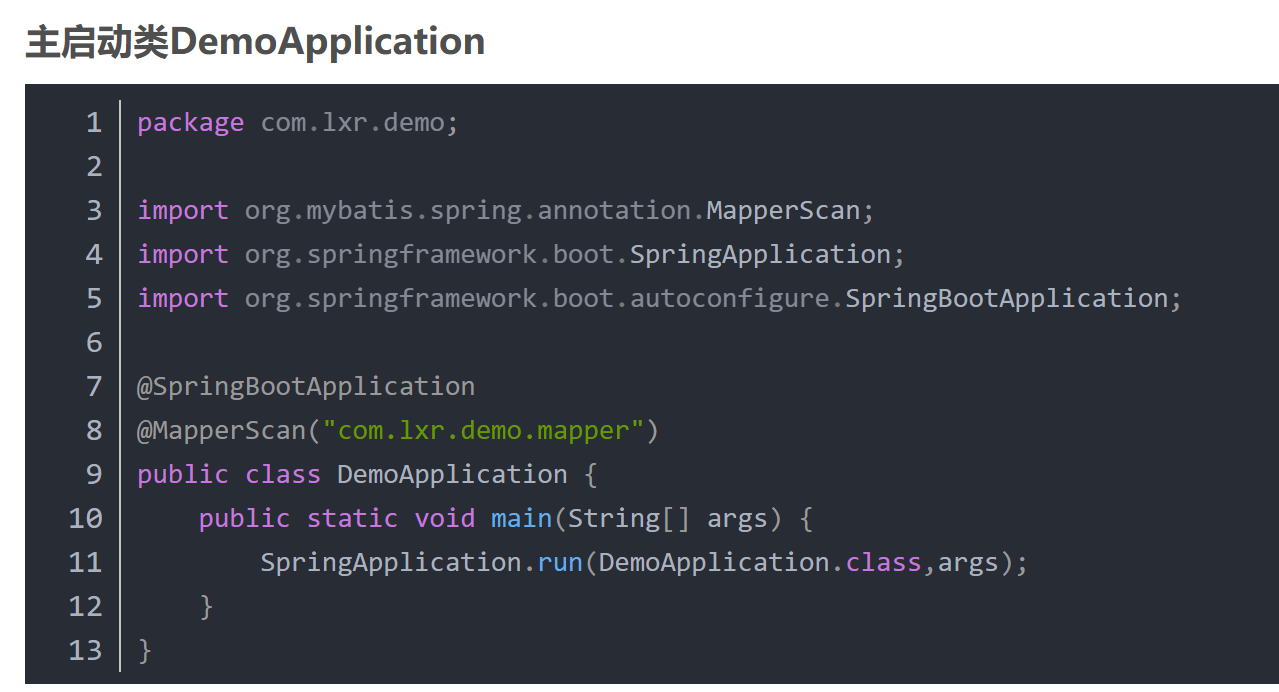
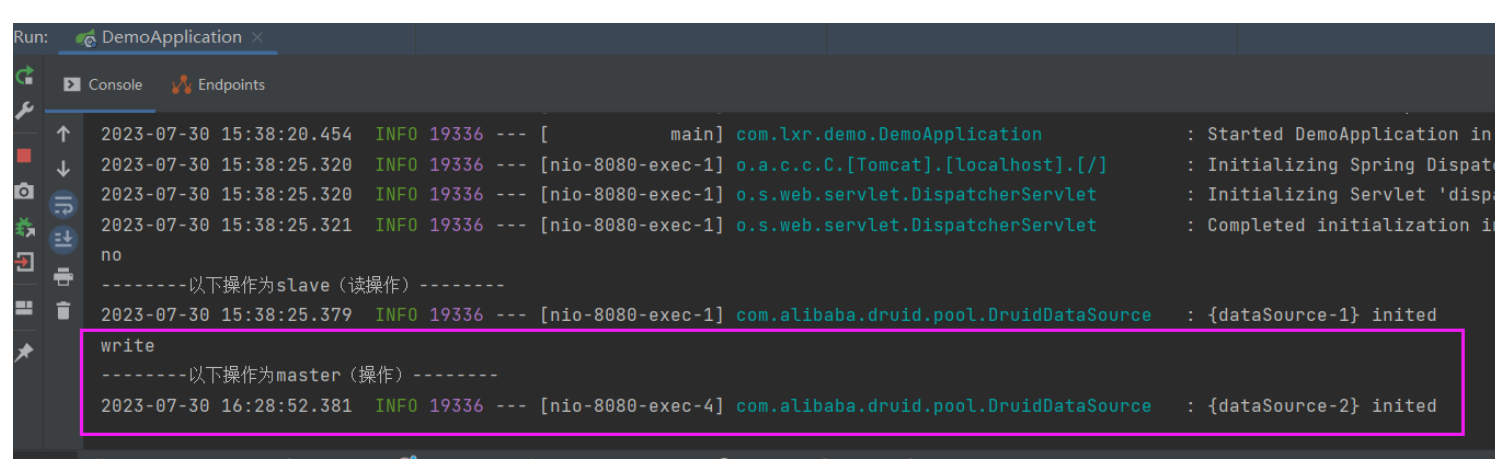
最终通过上面一系列的操作,终于实现了读从从库取,写从主库写。
后记
总结一哈,这里作者介绍了基于切面实现的动态切换数据源的方案,用到了线程独占哈希表来标识当前属于读操作还是写操作,还是值得大家学习的。
专栏所有文章均取材自博客排行榜,并附加个人的解读。
感兴趣的老爷们点个👍,想看其他文章的解读可以评论区留言。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









