



本文详细介绍大模型微调的五种主流方法:全量微调、Adapter、LoRA/QLoRA、前缀微调和指令微调。涵盖各方法原理、代码实现及优缺点分析。LoRA/QLoRA因其高效性成为首选,全量微调适合追求极致性能场景,前缀微调适合资源受限情况,指令微调是打造对话机器人的必经之路。文章提供方法选择指南,帮助开发者根据需求选择最合适的微调策略。
前排提示,文末有大模型AGI-优快云独家资料包哦!
在大语言模型(LLM)快速发展的今天,如何让通用的预训练模型适应特定领域和任务成为了关键挑战。微调技术正是解决这一挑战的核心手段。本文将详细介绍五种主流的大模型微调方法:**全量微调、Adapter、LoRA/QLoRA和前缀微调,指令微调,**涵盖原理详解、代码实例、方法选择和原理图示。

全量微调:彻底的模型重塑
原理与过程
全量微调是最传统、最彻底的微调方法。其核心思想是使用领域特定数据,更新预训练模型中的所有参数。
工作原理
加载预训练模型权重
准备目标任务训练数据
在整个训练过程中更新模型的所有层和参数
保存完整的微调后模型

代码实例
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
加载模型和分词器
model_name = “bert-base-uncased”
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
准备训练参数
training_args = TrainingArguments(
output\_dir="./full\_finetuning\_results",
learning\_rate=2e-5,
per\_device\_train\_batch\_size=16,
num\_train\_epochs=3,
weight\_decay=0.01,
)
创建Trainer并开始训练
trainer = Trainer(
model=model,
args=training\_args,
train\_dataset=train\_dataset,
eval\_dataset=eval\_dataset,
tokenizer=tokenizer,
)
执行全量微调
trainer.train()
trainer.save_model(“./full_tuned_model”)
优缺点分析
优点:
- 性能潜力最大,能深度适配目标任务
- 方法简单直接,无需复杂配置
缺点:
- 计算资源和显存需求极高
- 训练时间长,碳足迹大
- 容易发生过拟合和灾难性遗忘
- 存储成本高(每个任务保存完整模型)
Adapter微调:模块化插件方案
原理与过程
Adapter方法通过在Transformer模块中插入小型神经网络层,实现参数高效微调。原始模型参数被冻结,只训练新增的Adapter层。
工作原理:
- 在Transformer的每个FFN层后插入Adapter模块
- 冻结预训练模型的所有参数
- 只训练新添加的Adapter层
- 通过残差连接保持信息流通

代码实例
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers.adapters import AdapterConfig
加载模型
model = AutoModelForSequenceClassification.from_pretrained(“bert-base-uncased”, num_labels=2)
配置并添加Adapter
adapter_config = AdapterConfig.load(“pfeiffer”)
model.add_adapter(“sentiment_adapter”, config=adapter_config)
激活Adapter并冻结基础模型
model.train_adapter(“sentiment_adapter”)
model.freeze_model()
训练Adapter
training_args = TrainingArguments(
output\_dir="./adapter\_results",
learning\_rate=1e-4,
per\_device\_train\_batch\_size=16,
num\_train\_epochs=3,
)
trainer = Trainer(
model=model,
args=training\_args,
train\_dataset=train\_dataset,
)
trainer.train()
model.save_adapter(“./saved_adapter”, “sentiment_adapter”)
优缺点分析
优点:
- 参数效率高(仅训练1-3%参数)
- 支持多任务学习,轻松切换适配器
- 保持原始模型知识,减少灾难性遗忘
缺点:
- 增加模型推理延迟
- 需要修改模型结构
- 性能可能略低于全量微调

LoRA/QLoRA:低秩适配的革新
原理与过程
LoRA基于低秩适应假设,通过分解权重更新矩阵来高效微调模型。QLoRA在此基础上引入量化,进一步降低资源需求。
核心数学原理:
h = W₀x + ΔWx = W₀x + BAx
其中:
- W₀:冻结的预训练权重
- B和A:可训练的低秩矩阵
- r:秩,控制适配器大小
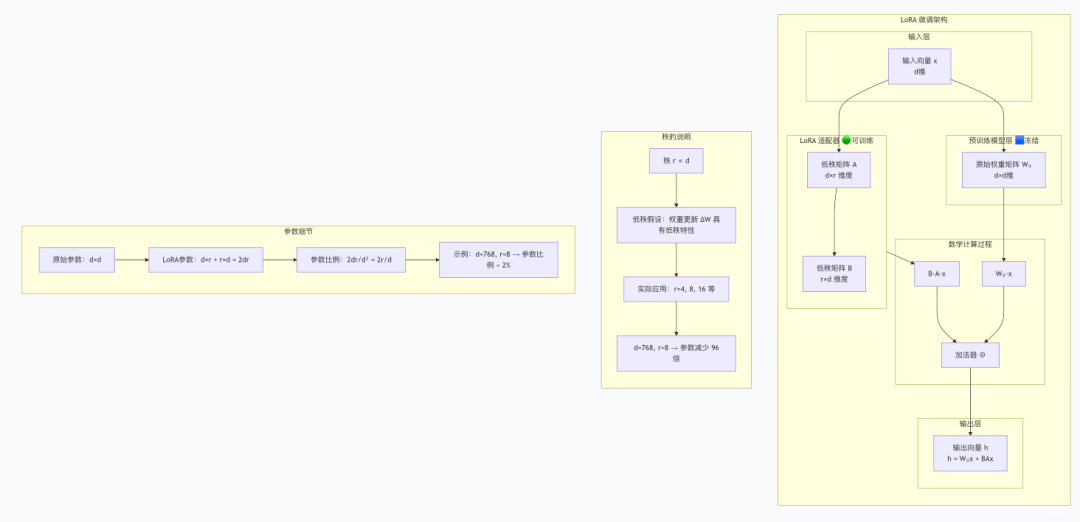
核心原理总结
LoRA 的数学基础
LoRA 的核心思想基于低秩适应假设,其数学表达式为:
text
h = W₀x + ΔWx = W₀x + BAx
其中:
- W₀:预训练的权重矩阵(冻结)
- ΔW:权重更新矩阵
- B 和 A:低秩分解矩阵(可训练)
- r:秩(r ≪ d),控制适配器大小
参数效率计算
对于维度为 d×d 的权重矩阵:
- 原始参数数量:d²
- LoRA 参数数量:2dr
- 参数比例:2r/d
示例:
- d=768, r=8 → 参数比例 = 16/768 ≈ 2.08%
- 训练参数减少约 50 倍
代码实例
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoTokenizer, AutoModelForSequenceClassification
加载模型
model = AutoModelForSequenceClassification.from_pretrained(“bert-base-uncased”, num_labels=2)
配置LoRA
lora_config = LoraConfig(
task\_type=TaskType.SEQ\_CLS,
inference\_mode=False,
r=8, # 秩
lora\_alpha=32,
lora\_dropout=0.1,
target\_modules=["query", "value"]
)
包装模型
lora_model = get_peft_model(model, lora_config)
lora_model.print_trainable_parameters() # 输出可训练参数占比
训练LoRA
training_args = TrainingArguments(
output\_dir="./lora\_results",
learning\_rate=1e-3,
per\_device\_train\_batch\_size=16,
num\_train\_epochs=3,
)
trainer = Trainer(
model=lora\_model,
args=training\_args,
train\_dataset=train\_dataset,
)
trainer.train()
保存适配器(文件很小)
trainer.save_model(“./lora_adapter”)
优缺点分析
优点:
- 极高的参数效率(0.1-1%参数)
- 无推理延迟(权重可合并)
- QLoRA使得单卡微调超大模型成为可能
- 性能接近全量微调
缺点:
- 需要理解低秩适应概念
- 超参数(秩r)需要调优
- QLoRA可能带来轻微精度损失
前缀微调:提示工程的进阶
原理与过程
前缀微调通过在输入序列前添加可训练的"虚拟令牌"来引导模型行为,整个原始模型保持冻结。
工作原理:
- 在输入文本前添加可训练的前缀令牌
- 冻结整个预训练模型
- 仅优化前缀令牌的嵌入向量
- 通过注意力机制影响模型输出
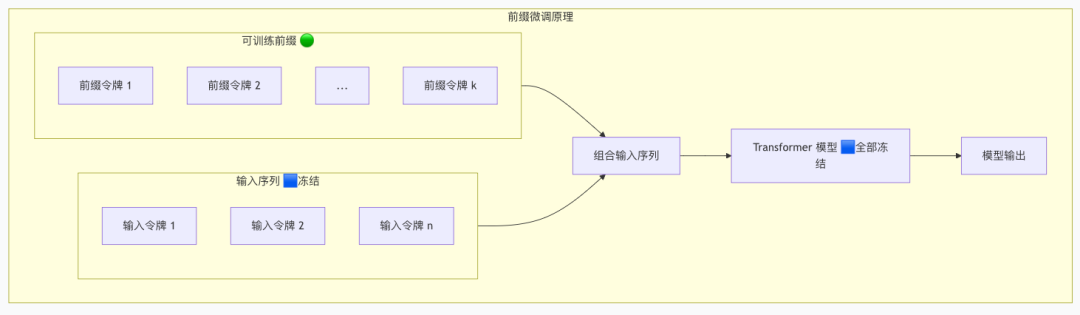
代码实例
from peft import PrefixTuningConfig, get_peft_model
from transformers import AutoTokenizer, AutoModelForSequenceClassification
加载模型
model = AutoModelForSequenceClassification.from_pretrained(“bert-base-uncased”, num_labels=2)
配置前缀微调
prefix_config = PrefixTuningConfig(
task\_type=TaskType.SEQ\_CLS,
num\_virtual\_tokens=10, # 虚拟令牌数量
)
包装模型
prefix_model = get_peft_model(model, prefix_config)
prefix_model.print_trainable_parameters()
训练前缀
training_args = TrainingArguments(
output\_dir="./prefix\_results",
learning\_rate=1e-2,
per\_device\_train\_batch\_size=16,
num\_train\_epochs=5,
)
trainer = Trainer(
model=prefix\_model,
args=training\_args,
train\_dataset=train\_dataset,
)
trainer.train()
优缺点分析
优点:
- 参数效率极高(0.01-0.1%参数)
- 完全保持原始模型不变
- 训练速度最快
缺点:
- 性能可能低于其他方法
- 前缀长度和初始化对效果影响大
- 可解释性较差
指令微调:训练专业助手
核心概念
传统预训练模型:
- 擅长补全文本:给定"今天天气很好,“,可能续写"适合出去玩”
- 但不擅长遵循特定指令
指令微调后的模型:
- 理解指令:给定"请把这句话翻译成英文:今天天气很好",会输出"The weather is nice today"
- 能够执行分类、总结、翻译、对话等多种任务
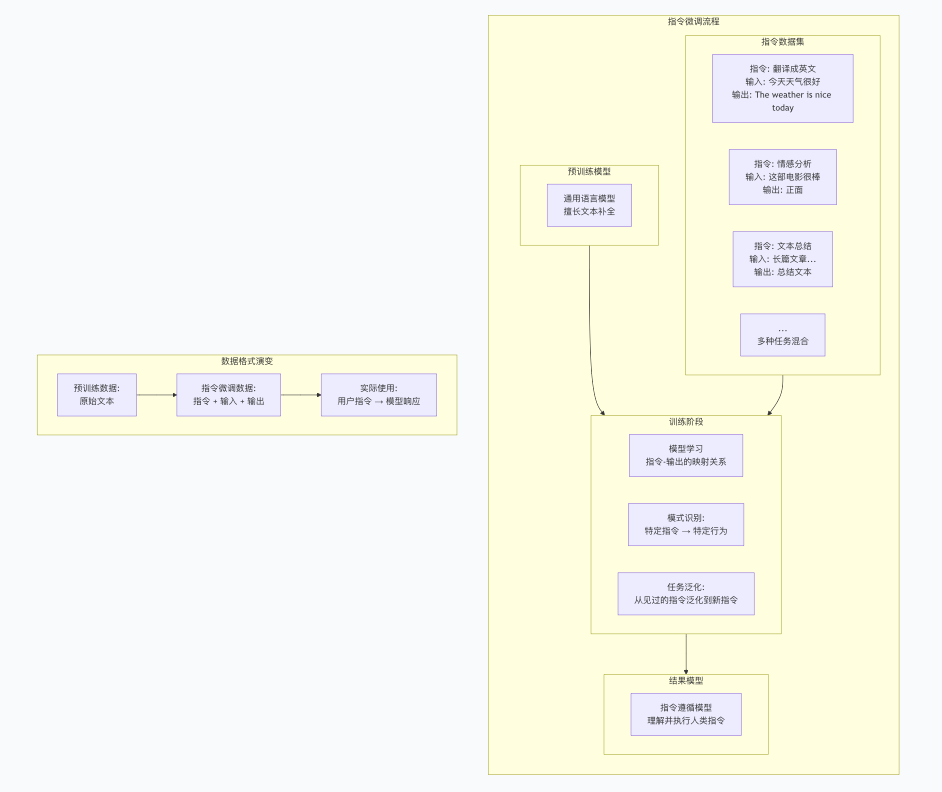
基础指令微调代码
import torch
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling
)
from datasets import Dataset
import json
1. 加载模型和分词器
model_name = “microsoft/DialoGPT-medium” # 以DialoGPT为例
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置pad token
model = AutoModelForCausalLM.from_pretrained(model_name)
2. 准备指令数据格式
def format_instruction_data(example):
"""将指令数据格式化为模型输入"""
instruction = example["instruction"]
input\_text = example.get("input", "")
output = example["output"]
构建训练文本:指令 + 输入 + 响应
if input\_text:
prompt = f"指令: {instruction}\n输入: {input\_text}\n响应: "
else:
prompt = f"指令: {instruction}\n响应: "
训练时,我们需要prompt + output作为完整序列
full\_text = prompt + output
return {"text": full\_text, "prompt": prompt}
3. 示例数据
instruction_data = [
{
"instruction": "将以下中文翻译成英文",
"input": "今天天气很好",
"output": "The weather is nice today"
},
{
"instruction": "情感分析",
"input": "这部电影太精彩了!",
"output": "正面"
},
{
"instruction": "总结以下文本",
"input": "人工智能是计算机科学的一个分支...",
"output": "人工智能是计算机科学的分支,致力于创造智能机器。"
},
更多指令数据…
]
4. 数据处理
def tokenize_function(examples):
# 对文本进行分词
tokenized = tokenizer(
examples["text"],
truncation=True,
padding=False,
max\_length=512,
return\_tensors=None
)
对于因果语言模型,标签就是输入本身(移位后)
tokenized["labels"] = tokenized["input\_ids"].copy()
return tokenized
创建数据集
formatted_data = [format_instruction_data(ex) for ex in instruction_data]
dataset = Dataset.from_list(formatted_data)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
5. 训练参数
training_args = TrainingArguments(
output\_dir="./instruction\_tuned\_model",
overwrite\_output\_dir=True,
num\_train\_epochs=3,
per\_device\_train\_batch\_size=4,
save\_steps=500,
save\_total\_limit=2,
prediction\_loss\_only=True,
remove\_unused\_columns=False,
learning\_rate=5e-5,
logging\_dir='./logs',
)
6. 创建Trainer
trainer = Trainer(
model=model,
args=training\_args,
train\_dataset=tokenized\_dataset,
data\_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False, # 不使用掩码语言模型
),
)
7. 开始训练
print(“开始指令微调…”)
trainer.train()
trainer.save_model()
结合LoRA的指令微调(推荐)
from peft import LoraConfig, get_peft_model, TaskType
在基础代码上添加LoRA配置
lora_config = LoraConfig(
task\_type=TaskType.CAUSAL\_LM, # 因果语言模型
inference\_mode=False,
r=8,
lora\_alpha=32,
lora\_dropout=0.1,
target\_modules=["q\_proj", "v\_proj"] # 针对LLaMA等模型
)
应用LoRA到模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
然后使用相同的训练流程…
指令微调
优点
- 听话好用:从此模型能听懂人话,你说它做,告别答非所问
- 一专多能:一个模型搞定翻译、总结、问答,无需为每个任务单独训练
- 举一反三:学会指令模式后,遇到新指令也能智能应对
- 输出精准:回答简洁到位,不再啰嗦跑题,直接给你想要的结果
- 开发省心:统一接口处理多任务,大大降低部署复杂度
缺点
- 数据挑剔:需要大量高质量的指令数据,收集清洗成本高
- 表达敏感:换个说法下指令,效果可能天差地别
- 记忆衰退:学了新技能,可能忘了旧知识,需要反复平衡
- 资源大户:训练过程依然烧钱烧显卡,成本不容小觑
- 过度适应:容易变成“应试专家”,对奇葩指令束手无策
方法选择总结与建议
综合对比表
| 方法 | 训练参数 | 存储开销 | 推理速度 | 性能表现 | 易用性 | 适用场景 |
| 全量微调 | 100% | 大(完整模型) | 正常 | ★★★★★ | 简单 | 资源充足,追求极致性能 |
| Adapter | 1-3% | 小(适配器) | 略慢 | ★★★★ | 中等 | 多任务学习,需要模块化 |
| LoRA | 0.1-1% | 极小(适配器) | 正常 | ★★★★☆ | 简单 | 大多数场景的首选 |
| QLoRA | 0.1-1% | 极小(适配器) | 正常 | ★★★★ | 简单 | 资源受限,单卡微调大模型 |
| 前缀微调 | 0.01-0.1% | 极小(前缀) | 正常 | ★★★ | 中等 | 极低资源,快速实验 |
选择决策指南
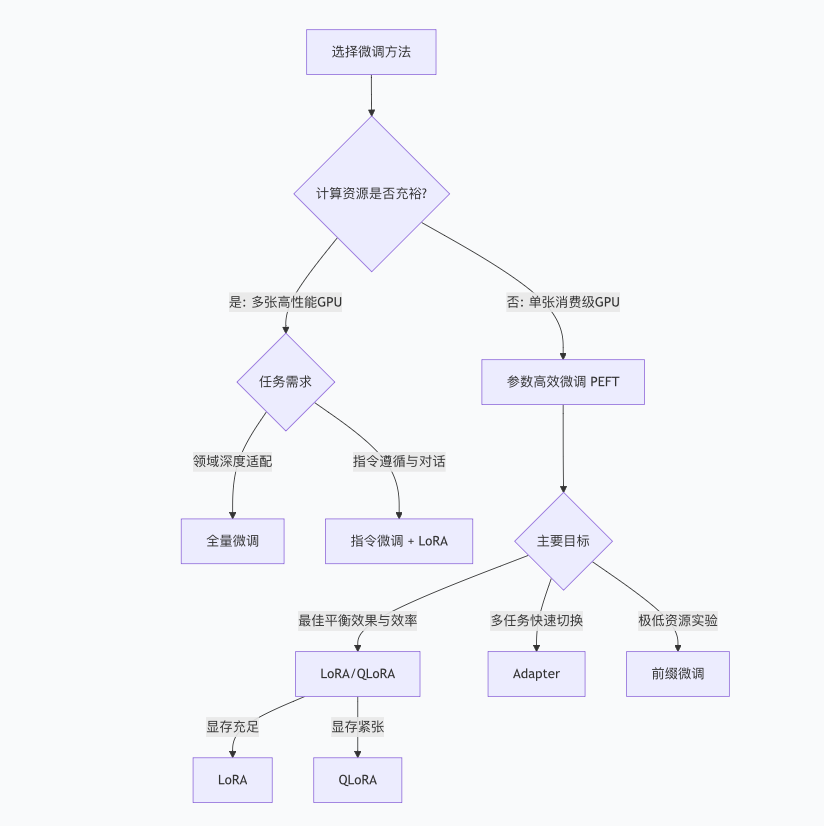
给新手的实践建议:
- 几乎总是从LoRA/QLoRA开始:它们在绝大多数场景下都能达到接近全量微调的效果,但成本极低,是目前的“黄金标准”。
- 如果你的目标是打造一个对话机器人,那么指令微调是你的必经之路,可以使用QLoRA在单卡上完成。
- 只有在你拥有海量数据和高性能计算集群,且非常追求性能时,才考虑全量微调。
4、当计算资源极度紧张或需要快速实验验证想法时,使用前缀微调是最轻量、最快捷的选择。
5、当需要同一个模型切换处理多个不同任务,或团队需要模块化开发时,使用Adapter微调的插件化设计最为合适。
🔥 调教AI大模型,这五种微调方法才是真正的“屠龙技”!从烧显卡的全量微调到轻量高效的LoRA,从模块化Adapter到极速前缀微调,我花了整整一周,用保姆级教程+原理图解+真实代码,帮你彻底搞懂如何让通用模型变成你的专属神器!希望这个全面的总结能帮助你理解大模型微调的各个方法!
💡 不管你是AI新手还是老司机,这份避坑指南都能让你少走半年弯路。点赞收藏这篇,下次调模型时翻出来看看,关键步骤一目了然!觉得有用别忘了分享给身边也在学AI的小伙伴,让我们一起进步~ ✨
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 28万+
28万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









