



前言
最近云途收到很多读者私信,都在问同一个问题:网上到处都是本地部署AI的教程,看着很厉害的样子,但我用ChatGPT网页版不是挺好的吗?为什么要折腾本地部署?
还有朋友说:我按照教程部署了DeepSeek,结果又慢又卡,还不如直接用官网!是不是我哪里搞错了?
今天我就实话实说,告诉你本地部署AI的真实情况,什么时候值得折腾,什么时候别浪费时间。
前排提示,文末有大模型AGI-优快云独家资料包哦!

什么是本地部署AI?
首先搞清楚什么是本地部署。
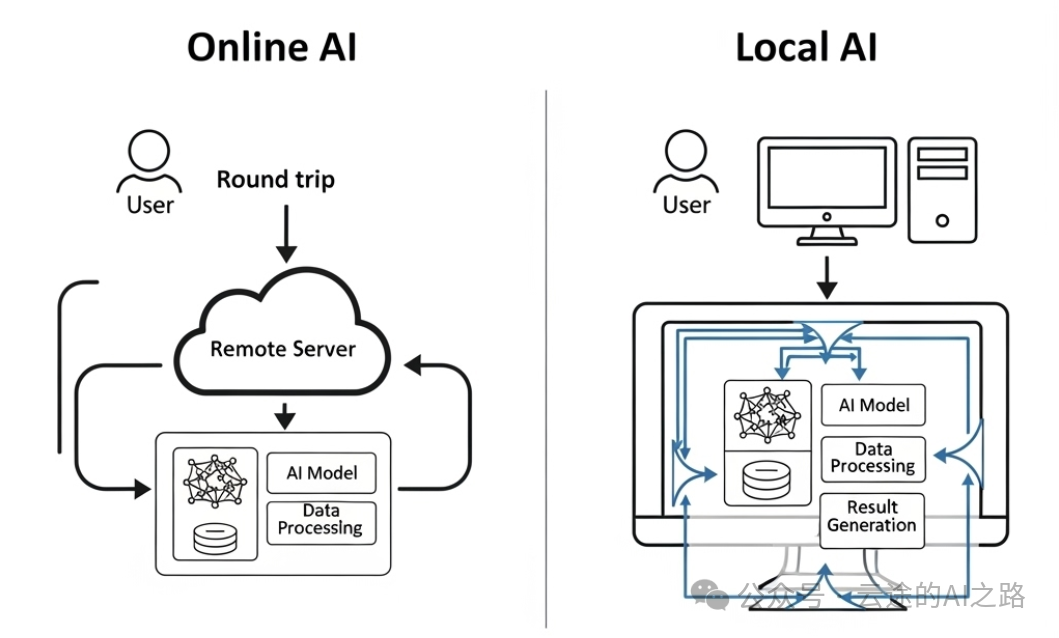
你平时用Deepseek或者其他的大模型比如Qwen3,打开网页,输入问题,得到回答。这个过程中,你的问题被发送到他们公司自己的服务器,在他们的大模型处理后,再把答案发回给你。
而本地部署就是把这个AI模型下载到你自己的电脑上,所有的处理都在你的机器上完成。
听起来好像很厉害对吧?但实际情况是什么呢?
本地部署的真实优势
-
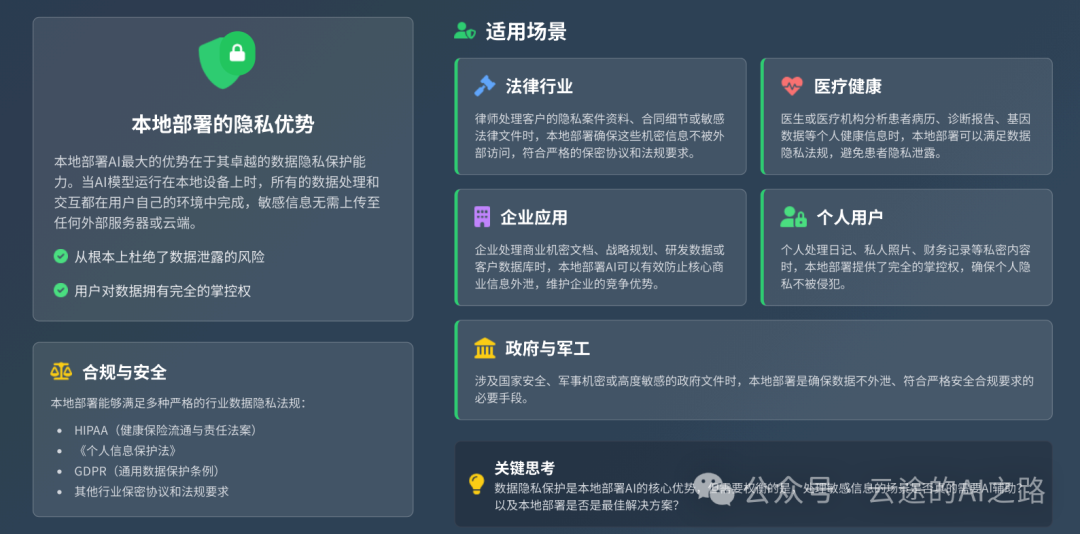
1. 数据隐私保护
这是本地部署最大的优势。
你和AI的所有对话,包括上传的文件、处理的数据,都在你自己的电脑里,不会被上传到任何地方。对于处理敏感信息的用户来说,这点非常重要。
适用场景:
- 律师处理客户隐私案件
- 医生处理患者病历
- 企业处理商业机密文档
- 个人处理私密内容
-
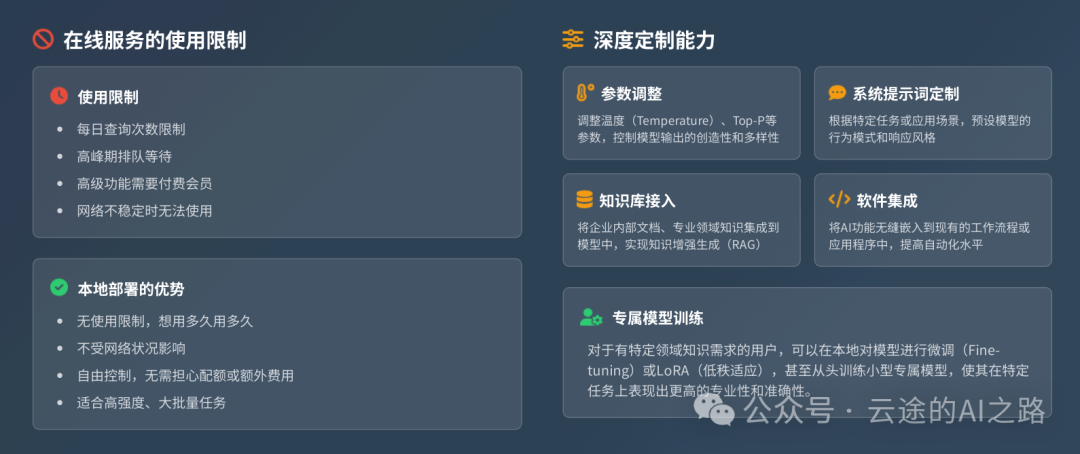
2. 无使用限制
网页版AI通常有各种限制:
- 每天只能问有限个问题
- 高峰期需要排队等待
- 某些高级功能需要付费会员
- 网络不稳定时无法使用
本地版本没有这些限制,想用多久用多久,想问多少问多少。
-
3. 深度定制能力
本地部署允许你:
- 调整模型参数(温度、top-p等)
- 自定义系统提示词
- 接入自己的知识库
- 集成到其他软件中
- 训练专属模型
这些是网页版做不到的。
-
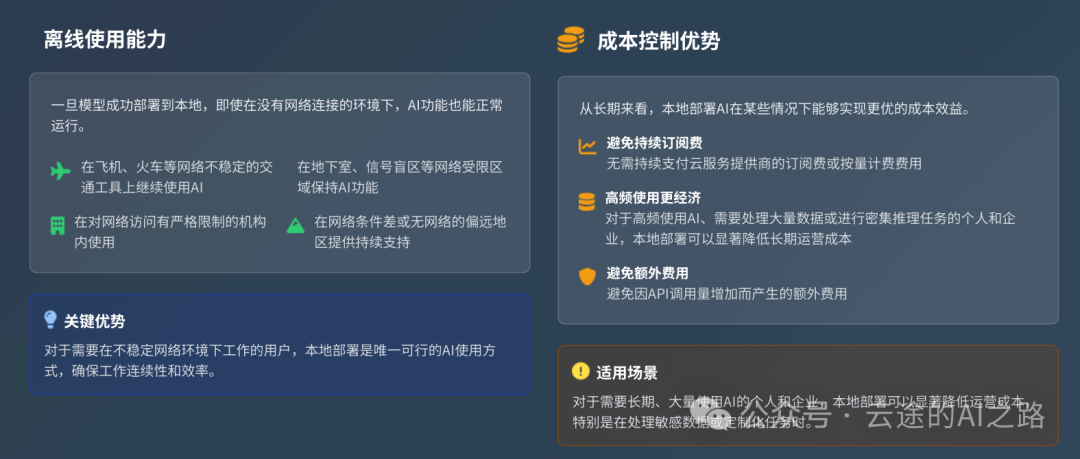
4. 离线使用能力
一旦部署完成,即使断网也能使用。这在以下场景很有用:
- 飞机上工作
- 地下室或信号差的地方
- 网络访问受限的环境
- 出差到网络不稳定的地区

本地部署的真实劣势
说完优势,现在说说为什么很多人部署完就后悔。
-
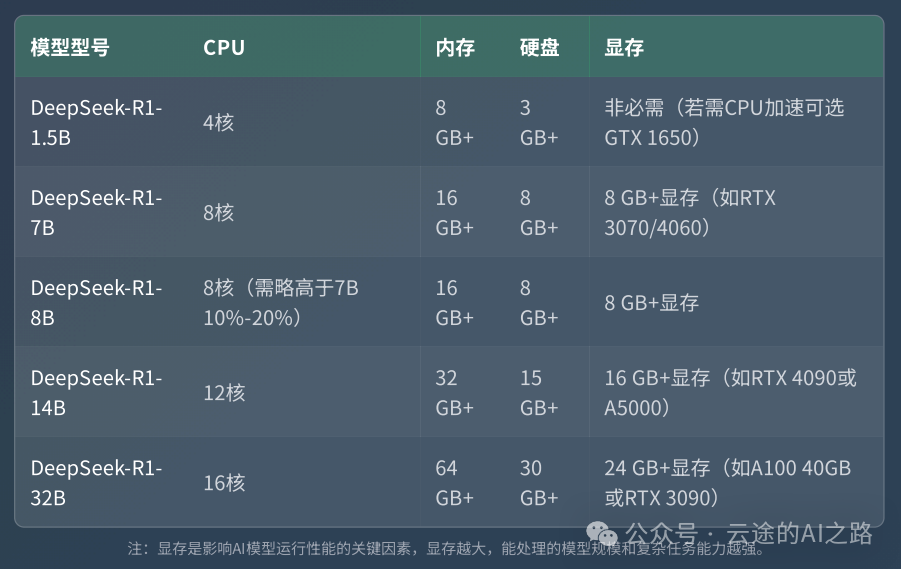
5. 硬件成本高昂
显卡要求: 想要好的体验,至少需要16GB显存的显卡:
- RTX 4090(24GB显存):12000-15000元
- RTX 4070 Ti Super(16GB显存):6000-8000元
- RTX 3090(24GB显存):二手4000-6000元
CPU版本的现实: 如果用CPU运行,速度慢到你怀疑人生。一个简单问题可能要等3-5分钟,基本没有实用价值。
-
6. 技术门槛不低
本地部署涉及:
- Python环境配置
- CUDA驱动安装
- 依赖库管理
- 版本兼容性问题
- 模型下载和管理
一个环节出错就可能卡住,很多人在这一步就放弃了。
常见问题:
- 环境变量配置错误
- CUDA版本不匹配
- 内存不足导致崩溃
- 模型文件损坏
- 网络问题导致下载失败

-
7. 维护成本持续
部署成功只是开始,后续还需要:
- 定期更新模型(每个模型几GB到几十GB)
- 处理系统兼容性问题
- 解决各种bug和报错
- 管理磁盘空间
- 监控系统性能
【配图建议:系统维护界面,显示各种需要管理的项目】
-
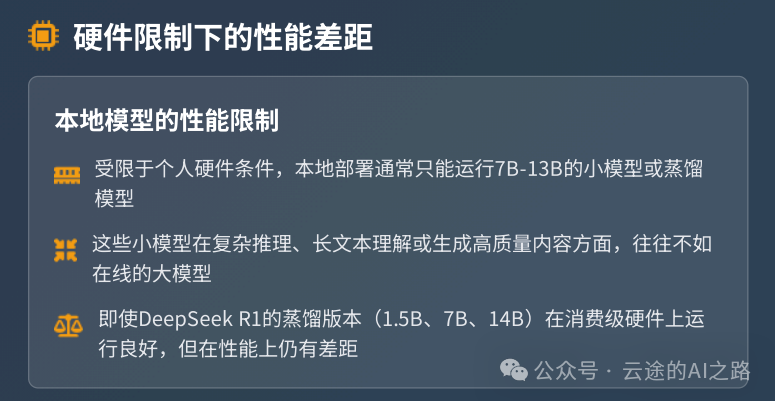
8. 效果可能不如预期
模型大小限制: 受显存限制,本地通常只能运行7B-13B的小模型,效果往往不如GPT-4、Claude这些大模型。
实际对比测试:
什么时候值得本地部署?
场景1:数据敏感度极高
如果你经常处理以下类型的内容,本地部署是必要的:
- 法律文件和案件资料
- 医疗记录和诊断报告
- 企业商业机密和战略规划
- 个人隐私信息和私密内容
- 政府或军工相关敏感资料
场景2:有特殊定制需求
适用于以下情况:
- 需要接入专业数据库
- 要训练特定领域模型
- 需要深度集成到现有系统
- 要开发AI相关产品
- 需要特定的输出格式或行为模式
场景3:网络环境受限
在以下环境中,本地部署可能是唯一选择:
- 军工企业内网环境
- 海上石油平台
- 偏远地区作业
- 对外网访问有严格限制的机构
- 经常出差到网络不稳定地区
场景4:技术和预算都充足
如果你同时满足:
- 有足够预算购买高端硬件
- 具备解决技术问题的能力
- 确实需要长期大量使用AI
- 享受折腾和学习的过程
那么本地部署能带来很好的体验。

给新手的实用建议
-
9. 先算清成本账
硬件成本:
- 高端显卡:6000-15000元
- 配套CPU和内存:3000-5000元
- 电费(高功耗显卡):每月100-200元
时间成本:
- 学习和配置:10-40小时
- 日常维护:每月2-5小时
- 问题排查:不定期几小时到几天
对比方案: ChatGPT Plus:20美元/月 = 1600元/年 Claude Pro:20美元/月 = 1600元/年

-
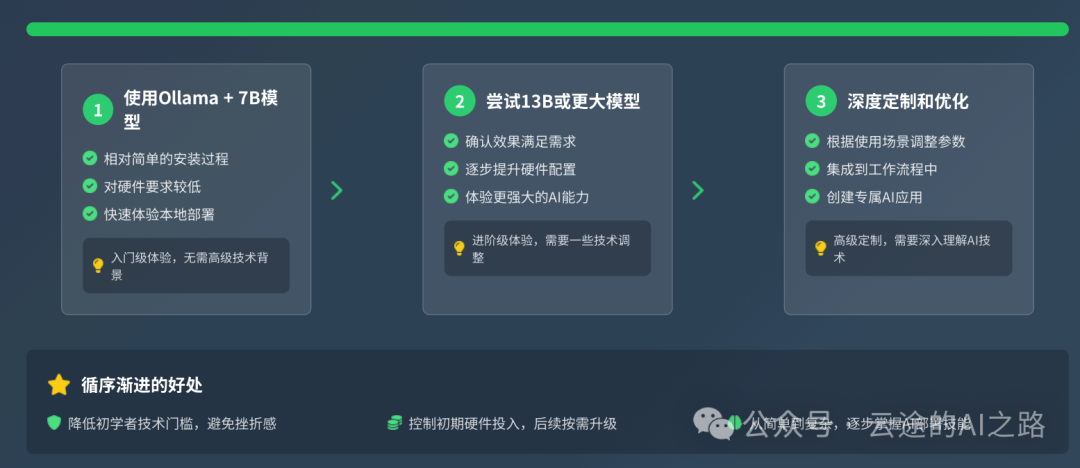
10. 从小模型开始
如果决定尝试,建议路径:
第一步:使用Ollama + 7B模型
- 相对简单的安装过程
- 对硬件要求较低
- 快速体验本地部署
第二步:尝试13B或更大模型
- 在确认效果满足需求后再升级
- 逐步提升硬件配置
第三步:深度定制和优化
- 根据使用场景来调整参数,对大模型进行微调,不过这个功能需要有一定基础的朋友才能够做到
- 集成到工作流程中,将本地大模型的API使用到本地部署的工作流当中,比如N8N和Coze本地版
-
11. 做好心理准备
把本地部署当作学习项目,而不是期望立即获得完美体验:
- 会遇到各种技术问题 - 这是正常的
- 效果可能不如在线版 - 特别是开始阶段
- 需要持续投入时间 - 维护和优化是长期过程
- 硬件投入不小 - 要有心理预算
-
12. 不必非黑即白
最佳实践往往是组合使用:
本地处理:
- 敏感数据分析
- 批量重复任务
- 离线环境工作
- 深度定制需求
在线处理:
- 日常对话和咨询
- 复杂推理任务
- 最新信息查询
- 偶发性需求

主流本地部署方案对比
Ollama
优点:
- 安装简单,一键部署
- 模型管理方便
- 社区活跃,文档完善
缺点:
- 模型选择相对有限
- 自定义程度不高
适合人群: 新手入门
LM Studio
优点:
- 图形界面友好
- 支持多种模型格式
- 内置对话界面
缺点:
- Windows和Mac限定
- 商业使用需付费
适合人群: 不想折腾命令行的用户
text-generation-webui
优点:
- 功能最全面
- 自定义程度最高
- 支持插件扩展
缺点:
- 安装配置复杂
- 学习曲线陡峭
适合人群: 技术能力较强的用户
总结
本地部署AI不是银弹,也不是必需品。
在决定是否本地部署前,先问自己几个问题:
-
1. 我真的需要处理敏感数据吗?
-
2. 我有足够的预算和技术能力吗?
-
3. 我能接受效果可能不如在线版吗?
-
4. 我愿意投入时间学习和维护吗?
如果以上问题的答案都是肯定的,那么本地部署确实能带来价值。
如果答案大多是否定的,那就老老实实用在线版,把时间花在更有价值的事情上。
最重要的是:选择适合自己需求的方案,而不是盲目跟风。

参考资源
官方文档:
- Ollama官网
- LM Studio官网
- text-generation-webui项目
社区资源:
- Reddit r/LocalLLaMA
- GitHub相关项目
- 各大技术论坛讨论区
硬件选购建议:
- 显卡性能天梯图
- 二手硬件交易平台
- 专业硬件评测网站
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 4326
4326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









