









 本文介绍了如何在Linux环境下启动ElasticSearch 7.0.0,并详细讲解了分词器的概念,包括其在搜索中的作用和组成部分。接着,文章详细阐述了两种分词器的安装过程,包括中文分词器IK和拼音分词器的下载及验证步骤,为ElasticSearch的全文检索功能提供了必要的支持。
本文介绍了如何在Linux环境下启动ElasticSearch 7.0.0,并详细讲解了分词器的概念,包括其在搜索中的作用和组成部分。接着,文章详细阐述了两种分词器的安装过程,包括中文分词器IK和拼音分词器的下载及验证步骤,为ElasticSearch的全文检索功能提供了必要的支持。
启动ES
Linux下启动
将下载好的压缩包放到指定目录,使用root以外的账号启动:
tar -zxvf elasticsearch-7.0.0-darwin-x86_64.tar.gz
chown -R web:web elasticsearch-7.0.0
su web
cd elasticsearch-7.0.0
./bin/elasticsearch
验证启动:
[root@pe51 ~]# curl http://127.0.0.1:9200
以下表示成功:
{
“name” : “pe51”,
“cluster_name” : “elasticsearch”,
“cluster_uuid” : “SSzu6PgTSdOCRHBqtyWGsg”,
“version” : {
“number” : “7.0.0”,
“build_flavor” : “default”,
“build_type” : “tar”,
“build_hash” : “b7e28a7”,
“build_date” : “2019-04-05T22:55:32.697037Z”,
“build_snapshot” : false,
“lucene_version” : “8.0.0”,
“minimum_wire_compatibility_version” : “6.7.0”,
“minimum_index_compatibility_version” : “6.0.0-beta1”
},
“tagline” : “You Know, for Search”
}
分词器介绍
1.什么是分词器
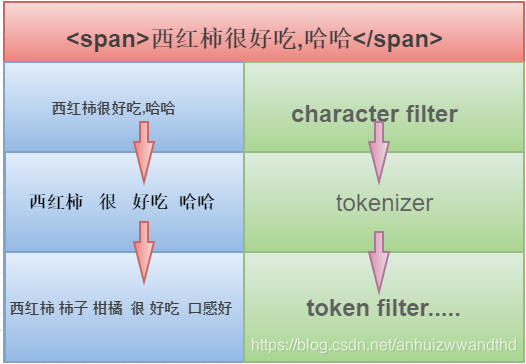
分词器(analyzer)主要包含两个功能: 切分词语,normalization(时态的转换,单复数的转换,同义词的转换,大小写的转换等等)
分词器主要包含2个部分:
- tokenizer(分解器)
- token filter(词元过滤器)
tokenizer:
分解器在处理之前会经过预处理,比如去除html标记等,这些预处理的算法叫做字符过滤器(character filter)
一个分解器会有一个或多个character filter。分解器可以把一个字符串分解成一系列的词元(就是单个的词条).
token filter
token filter会将tokenizer处理完的一系列token进一步处理,比如转换大小写,同义词处理,停止词去掉等。
2.分词器种类
es内置分词器:
standard analyzer,whitespace analyzer,language analyzer…
安装中文分词器
在线安装(推荐)
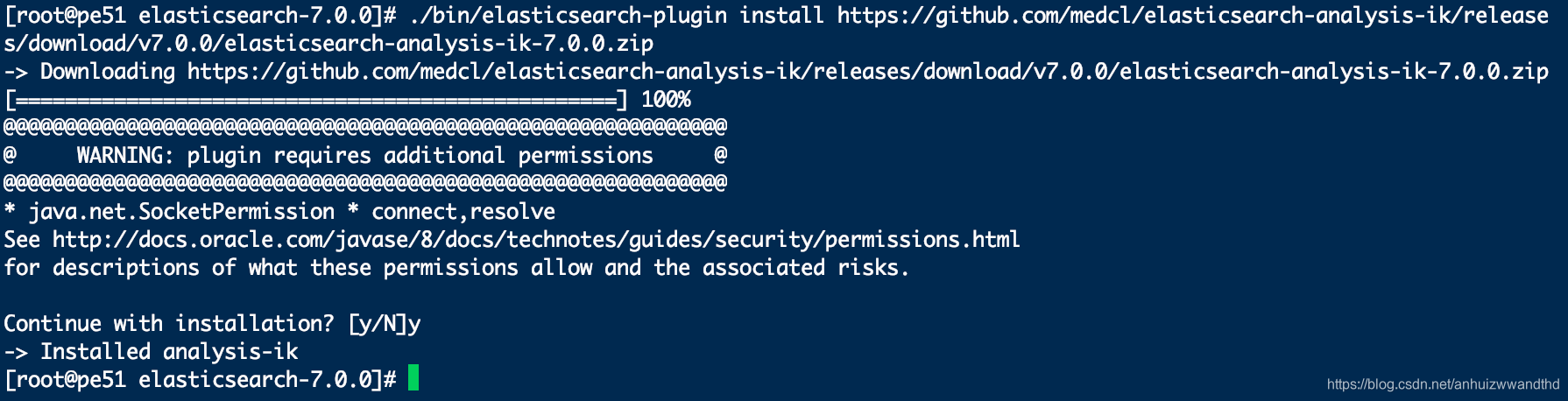
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.0.0/elasticsearch-analysis-ik-7.0.0.zip
下载安装
IK中文分词下载 下载自己对应的版本,解压放到elasticsearch-7.0.0/plugins下
重启验证:
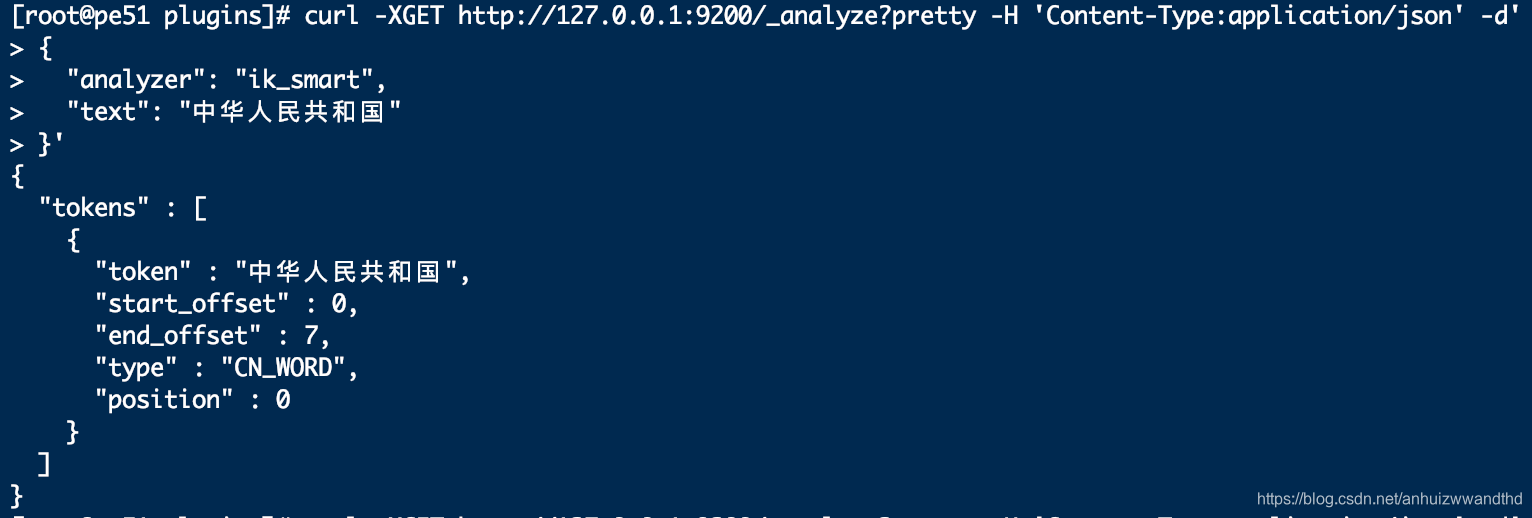
curl -XGET http://127.0.0.1:9200/_analyze?pretty -H 'Content-Type:application/json' -d'
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}'
[root@pe51 plugins]# curl -XGET http://127.0.0.1:9200/_analyze?pretty -H 'Content-Type:application/json' -d'
> {
> "analyzer": "ik_max_word",
> "text": "中华人民共和国"
> }'
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
}
]
}
安装拼音分词器
在线安装(推荐)
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.0.0/elasticsearch-analysis-pinyin-7.0.0.zip

下载安装
拼音分词下载 下载自己对应的版本,解压放到elasticsearch-7.0.0/plugins下


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









