




##S³GAN : High-Fidelity Image Generation With Fewer Labels (2019.03)
介绍
- 半监督学习:整个训练集的标签可以从一小部分标记过的训练图像中推断出来,而推断出来的标签可以用作GAN训练的条件信息。
- 自监督学习:旨在通过设计辅助任务来学习可区别性的视觉特征,如此,目标标签就能够自由获取。这些标签能够直接从训练数据或图像中获得,并为计算机视觉模型的训练提供监督信息。
- 传统的GAN在判别器(D)网络的输出端会使用二分类模式,代表真和假。在SGAN中,就是把这个二分类(sigmoid)转化为多分类(softmax),类型数量为N+1,指代N个标签的数据和“一个假数据”,表示为:
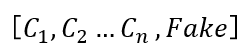
Models
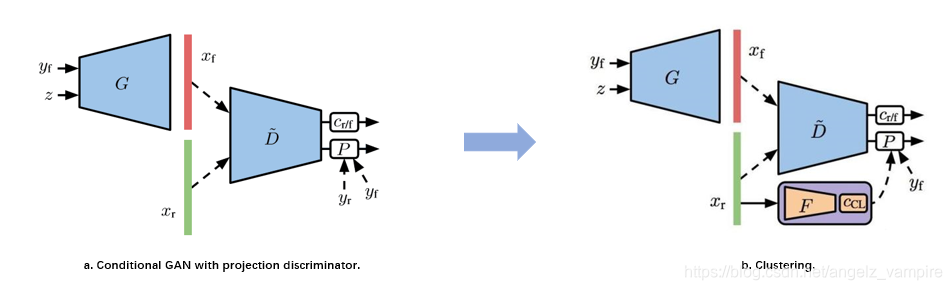
模型a中,鉴别器D被分解为一个鉴别器表征?^~和一个线性分类器?_(?/?),鉴别器表示为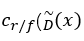 。 y_? 是已知标签信息,z是输入的噪声, x_? 是生成器G生成的带y_?标签的图像, ?_r是真实图像,D可以表示为:
。 y_? 是已知标签信息,z是输入的噪声, x_? 是生成器G生成的带y_?标签的图像, ?_r是真实图像,D可以表示为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









