




Python实践提升-面向对象编程
Python 是一门支持多种编程风格的语言。面对同样的需求,不同的程序员会写出风格迥异的 Python 代码。一个习惯“过程式编程”的人,可能会用一大堆环环相扣的函数来解决问题。而一个擅长“面向对象编程”的人,可能会搞出数不清的类来完成任务。
虽然不同的编程风格各有优缺点,无法直接比较,但如今面向对象编程的流行度与接受度远超其他编程风格。
几乎所有现代编程语言都支持面向对象功能,但由于设计理念不同,不同编程语言所支持的面向对象有许多差异。比如接口(interface)是 Java 面向对象体系中非常重要的组成部分,而在 Python 里,你压根儿就找不到接口对象。
Python 语言在整体设计上深受面向对象思想的影响。你经常可以听到“在 Python 里,万物皆对象”这句话。这并不夸张,在 Python 中,最基础的浮点数也是一个对象:
>>> i = 1.3
>>> i.is_integer() ➊
False
❶ 调用浮点数对象的 is_integer() 方法
要创建自定义对象,你需要用 class 关键字来定义一个类:
class Duck:
def __init__(self, name):
self.name = name
def quack(self):
print(f"Quack! I'm {self.name}!")
实例化一个 Duck 对象,并调用它的 .quack() 方法:
>>> donald = Duck('donald')
>>> donald.quack()
Quack! I'm donald!
为了区分,我们常把类里定义的函数称作方法。除了普通方法外,你还可以使用 @classmethod、@staticmethod 等装饰器来定义特殊方法。在 9.1.2 节,我会介绍这部分内容。
Python 支持类之间的继承,你可以用继承来创建一个子类,并重写父类的一些方法:
class WordyDuck(Duck): ➊
def quack(self):
print(f"Quack!Quack!Quack! I'm {self.name}!")
❶ 继承 Duck 类
在创建继承关系时,你不止可以继承一个父类,还能同时继承多个父类。在 9.1.5 节中,我会介绍多重继承的相关知识。
在日常编写代码时,继承作为一个强大的代码复用机制,常被过度使用。本章的案例故事与继承有关,我会介绍何时该用继承,何时该用组合替代继承。
在本章中,你还会看到一些如图 9-1 所示的图。
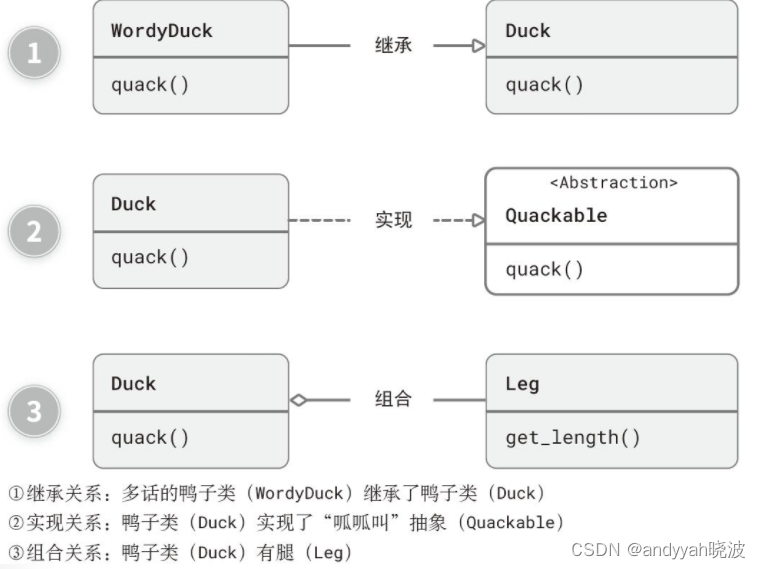
图 9-1 类之间的关系示意图
这是一种简化过的 UML 图,能帮助你更直观地理解类之间的关系。
面向对象是一个非常庞大的主题,除了上述内容外,本章还会涉及鸭子类型、抽象类、元类等内容。话不多说,我们开始吧!
9.1 基础知识
9.1.1 类常用知识
在 Python 中,类(class)是我们实践面向对象编程时最重要的工具之一。通过类,我们可以把头脑中的抽象概念进行建模,进而实现复杂的功能。同函数一样,类的语法本身也很简单,但藏着许多值得注意的细节。
下面我会分享一些与类相关的常用知识点。
私有属性是“君子协定”
封装(encapsulation)是面向对象编程里的一个重要概念,为了更好地体现类的封装性,许多编程语言支持将属性设置为公开或私有,只是方式略有不同。比如在 Java 里,我们可以用 public 和 private 关键字来表达是否私有;而在 Go 语言中,公有 / 私有则是用首字母大小写来区分的。
在 Python 里,所有的类属性和方法默认都是公开的,不过你可以通过添加双下划线前缀 __ 的方式把它们标示为私有。举个例子:
class Foo:
def __init__(self):
self.__bar = 'baz'
上面代码中 Foo 类的 bar 就是一个私有属性,如果你尝试从外部访问它,程序就会抛出异常:
>>> foo = Foo()
>>> foo.__bar
AttributeError: 'Foo' object has no attribute '__bar'
虽然上面是设置私有属性的标准做法,但 Python 里的私有只是一个“君子协议”。“君子协议”是指,虽然用属性的本名访问不了私有属性,但只要稍微调整一下名字,就可以继续操作 __bar 了:
>>> foo._Foo__bar
'baz'
这是因为当你使用 {var} 的方式定义一个私有属性时,Python 解释器只是重新给了它一个包含当前类名的别名 _{class}{var},因此你仍然可以在外部用这个别名来访问和修改它。
因为私有属性依靠这套别名机制工作,所以私有属性的最大用途,其实是在父类中定义一个不容易被子类重写的受保护属性。
而在日常编程中,我们极少使用双下划线来标示一个私有属性。如果你认为某个属性是私有的,直接给它加上单下划线 _ 前缀就够了。而“标准”的双下划线前缀,反而可能会在子类想要重写父类私有属性时带来不必要的麻烦。
在 Python 圈,有一句常被提到的老话:“大家都是成年人了。”(We are all consenting adults here.)这句话代表了 Python 的一部分设计哲学,那就是期望程序员做正确的事,而不是在语言上增加太多条条框框。Python 没有严格意义上的私有属性,应该就是遵循了这条哲学的结果。
实例内容都在字典里
在第 3 章的开篇,我提到 Python 语言内部大量使用了字典类型,比如一个类实例的所有成员,其实都保存在了一个名为 dict 的字典属性中。
而且,不光实例有这个字典,类其实也有这个字典:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print(f"Hi, My name is {self.name}, I'm {self.age}")
查看 dict:
>>> p = Person('raymond', 30)
>>> p.__dict__ ➊
{'name': 'raymond', 'age': 30}
>>> Person.__dict__ ➋
mappingproxy({'__module__': '__main__', '__init__': <function Person.__init__ at 0x109611ca0>, 'say': <function Person.say at 0x109611d30>, '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None})
❶ 实例的 dict 里,保存着当前实例的所有数据
❷ 类的 dict 里,保存着类的文档、方法等所有数据
在绝大多数情况下,dict 字典对于我们来说是内部实现细节,并不需要手动操作它。但在有些场景下,使用 dict 可以帮我们巧妙地完成一些特定任务。
比如,你有一份包含 Person 类数据的字典 {‘name’: …, ‘age’: …}。现在你想把这份字典里的数据直接赋值到某个 Person 实例上。最简单的做法是通过遍历字典来设置属性:
>>> d = {'name': 'andrew', 'age': 20}
>>> for key, value in d.items():
... setattr(p, key, value)
但除此之外,其实也可以直接修改实例的 dict 属性来快速达到目的:p.dict.update(d)。
不过需要注意的是,修改实例的 dict 与循环调用 setattr() 方法这两个操作并不完全等价,因为类的属性设置行为可以通过定义 setattr 魔法方法修改。
举个例子:
class Person:
...
def __setattr__(self, name, value):
# 不允许设置年龄小于 0
if name == 'age' and value < 0:
raise ValueError(f'Invalid age value: {value}')
super().__setattr__(name, value)
在上面的代码里,Person 类增加了 setattr 方法,实现了对 age 值的校验逻辑。执行效果如下:
>>> p = Person('raymond', 30)
>>> p.age = -3
ValueError: Invalid age value: -3
虽然普通的属性赋值会被 setattr 限制,但如果你直接操作实例的 dict 字典,就可以无视这个限制:
>>> p.__dict__['age'] = -3
>>> p.say()
Hi, My name is raymond, I'm -3
在某些特殊场景下,合理利用 dict 属性的这个特性,可以帮你完成常规做法难以做到的一些事情。
9.1.2 内置类方法装饰器
在编写类时,除了普通方法以外,我们还常常会用到一些特殊对象,比如类方法、静态方法等。要定义这些对象,得用到特殊的装饰器。下面简单介绍这些装饰器。
类方法
当你用 def 在类里定义一个函数时,这个函数通常称作方法。调用方法需要先创建一个类实例。
举个例子,下面的 Duck 是一个简单的鸭子类:
class Duck:
def __init__(self, color):
self.color = color
def quack(self):
print(f"Hi, I'm a {self.color} duck!")
创建一只鸭子,并调用它的 quack() 方法:
>>> d = Duck('yellow')
>>> d.quack()
Hi, I'm a yellow duck!
如果你不使用实例,而是直接用类来调用 quack(),程序就会因为找不到类实例而报错:
>>> Duck.quack()
TypeError: quack() missing 1 required positional argument: 'self'
不过,虽然普通方法无法通过类来调用,但你可以用 @classmethod 装饰器定义一种特殊的方法:类方法(class method),它属于类但是无须实例化也可调用。
下面给 Duck 类加上一个 create_random() 类方法:
class Duck:
...
@classmethod
def create_random(cls): ➊
"""创建一只随机颜色的鸭子"""
color = random.choice(['yellow', 'white', 'gray'])
return cls(color=color)
❶ 普通方法接收类实例(self)作为参数,但类方法的第一个参数是类本身,通常使用名字 cls
调用效果如下:
>>> d = Duck.create_random()
>>> d.quack()
Hi, I'm a white duck!
>>> d.create_random() ➊
<__main__.Duck object at 0x10f8f2f40>
❶ 虽然类方法通常是用类来调用,但你也可以通过实例来调用类方法,效果一样
作为一种特殊方法,类方法最常见的使用场景,就是像上面一样定义工厂方法来生成新实例。类方法的主角是类型本身,当你发现某个行为不属于实例,而是属于整个类型时,可以考虑使用类方法。
静态方法
如果你发现某个方法不需要使用当前实例里的任何内容,那可以使用 @staticmethod 来定义一个静态方法。
下面的 Cat 类定义了 get_sound() 静态方法:
class Cat:
def __init__(self, name):
self.name = name
def say(self):
sound = self.get_sound()
print(f'{self.name}: {sound}...')
@staticmethod
def get_sound(): ➊
repeats = random.randrange(1, 10)
return ' '.join(['Meow'] * repeats)
❶ 静态方法不接收当前实例作为第一个位置参数
代码运行效果如下:
>>> c = Cat('Jack')
>>> c.say()
Jack: Meow Meow Meow...
除了实例外,你也可以用类来调用静态方法:
>>> Cat.get_sound()
'Meow Meow Meow Meow Meow Meow'
和普通方法相比,静态方法不需要访问实例的任何状态,是一种与状态无关的方法,因此静态方法其实可以改写成脱离于类的外部普通函数。
选择静态方法还是普通函数,可以从以下几点来考虑:
如果静态方法特别通用,与类关系不大,那么把它改成普通函数可能会更好;
如果静态方法与类关系密切,那么用静态方法更好;
相比函数,静态方法有一些先天优势,比如能被子类继承和重写等。
属性装饰器
在一个类里,属性和方法有着不同的职责:属性代表状态,方法代表行为。二者对外的访问接口也不一样,属性可以通过 inst.attr 的方式直接访问,而方法需要通过 inst.method() 来调用。
不过,@property 装饰器模糊了属性和方法间的界限,使用它,你可以把方法通过属性的方式暴露出来。举个例子,下面的 FilePath 类定义了 get_basename() 方法:
import os
class FilePath:
def __init__(self, path):
self.path = path
def get_basename(self):
"""获取文件名"""
return self.path.split(os.sep)[-1]
使用 @property 装饰器,你可以把上面的 get_basename() 方法变成一个虚拟属性,然后像使用普通属性一样使用它:
class FilePath:
...
@property
def basename(self):
"""获取文件名"""
return self.path.rsplit(os.sep, 1)[-1]
调用效果如下:
>>> p = FilePath('/tmp/foo.py')
>>> p.basename
'foo.py'
@property 除了可以定义属性的读取逻辑外,还支持自定义写入和删除逻辑:
class FilePath:
...
@property
def basename(self):
"""获取文件名"""
return self.path.rsplit(os.sep, 1)[-1]
@basename.setter ➊
def basename(self, name): ➋
"""修改当前路径里的文件名部分"""
new_path = self.path.rsplit(os.sep, 1)[:-1] + [name]
self.path = os.sep.join(new_path)
@basename.deleter
def basename(self): ➌
raise RuntimeError('Can not delete basename!')
❶ 经过 @property 的装饰以后,basename 已经从一个普通方法变成了 property 对象,因此这里可以使用 basename.setter
❷ 定义 setter 方法,该方法会在对属性赋值时被调用
❸ 定义 deleter 方法,该方法会在删除属性时被调用
调用效果如下:
>>> p = FilePath('/tmp/foo.py')
>>> p.basename = 'bar.txt' ➊
>>> p.path
'/tmp/bar.txt'
>>> del p.basename ➋
RuntimeError: Can not delete basename!
❶ 触发 setter 方法
❷ 触发 deleter 方法
@property 是个非常有用的装饰器,它让我们可以基于方法定义类属性,精确地控制属性的读取、赋值和删除行为,灵活地实现动态属性等功能。
除了 @property 以外,描述符也能做到同样的事情,并且功能更多、更强大。在 12.1.3 节中,我会介绍如何用描述符来实现复杂属性。
当你决定把某个方法改成属性后,它的使用接口就会发生很大的变化。你需要学会判断,方法和属性分别适合什么样的场景。
举个例子,假如你的类有个方法叫 get_latest_items(),调用它会请求外部服务的数十个接口,耗费 5~10 秒钟。那么这时,盲目把这个方法改成 .latest_items 属性就不太恰当。
人们在读取属性时,总是期望能迅速拿到结果,调用方法则不一样——快点儿慢点儿都无所谓。让自己设计的接口符合他人的使用预期,也是写代码时很重要的一环。
9.1.3 鸭子类型及其局限性
每当我们谈论 Python 的类型系统时,总有一句话被大家反复提起:“Python 是一门鸭子类型的编程语言。”
虽然这个定义被广泛接受,但是和“静态类型”“动态类型”这些名词不一样,“鸭子类型”(duck-typing)不是什么真正的类型系统,而只是一种特殊的编程风格。
在鸭子类型编程风格下,如果想操作某个对象,你不会去判断它是否属于某种类型,而会直接判断它是不是有你需要的方法(或属性)。或者更激进一些,你甚至会直接尝试调用需要的方法,假如失败了,那就让它报错好了(参考 5.1.1 节)。
当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以称为鸭子。
——来自“鸭子类型”的维基百科词条
也就是说,虽然 Python 提供了检查类型的函数:isinstance(),但是鸭子类型并不推荐你使用它。你想调用 items 对象的 append() 方法?别拿 isinstance(items, list) 判断 items 究竟是不是列表,想调就直接调吧!
举个更具体的例子,假如某人要编写一个函数,来统计某个文件对象里有多少个元音字母,那么遵循鸭子类型的指示,应该直接把代码写成代码清单 9-1。
代码清单 9-1 统计文件中元音数量
def count_vowels(fp):
"""统计某个文件中元音字母(aeiou)的数量"""
VOWELS_LETTERS = {'a', 'e', 'i', 'o', 'u'}
count = 0
for line in fp: ➊
for char in line:
if char.lower() in VOWELS_LETTERS:
count += 1
return count
# 合法的调用方式:传入一个可读的文件对象
with open('small_file.txt') as fp:
print(count_vowels_v2(fp))
❶ 不做任何类型判断,直接开始遍历 fp 对象
在超过 90% 的情况下,你能找到的合理的 Python 代码就如上所示:没有任何类型检查,想做什么就直接做。你肯定想问,假如调用方提供的 fp 参数不是文件对象怎么办?答案是:不怎么办,直接报错就好。示例如下。
>>> count_vowels(100)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "duck_typing.py", line 8, in count_vowels
for line in fp:
TypeError: 'int' object is not iterable
如果编码者觉得:“这实在是太随意了,我非得给它加上一点儿类型校验不可。”那么他也可以选择补充一些符合鸭子类型的校验语句,比如通过判断 fp 对象有没有 read 方法来决定是否继续执行,如代码清单 9-2 所示。
代码清单 9-2 统计文件中元音数量(增加校验)
def count_vowels(fp):
"""统计某个文件中元音字母(aeiou)的数量"""
if not hasattr(fp, 'read'): ➊
raise TypeError('must provide a valid file object')
VOWELS_LETTERS = {'a', 'e', 'i', 'o', 'u'}
count = 0
for line in fp:
for char in line:
if char.lower() in VOWELS_LETTERS:
count += 1
return count
❶ 新增的校验语句
但不管怎样,在纯粹的鸭子类型编程风格下,不应该出现任何的 isinstance 类型判断语句。
假如你用其他静态类型的编程语言写过代码,肯定会觉得,这么搞真是太乱来了,这样的代码看上去就很不靠谱。但实话实说,鸭子类型编程风格确实有许多实打实的优点。
首先,鸭子类型不推荐做类型检查,因此编码者可以省去大量与之相关的烦琐工作。其次,鸭子类型只关注对象是否能完成某件事,而不对类型做强制要求,这大大提高了代码的灵活性。
举个例子,假如你把一个 StringIO 对象——一种实现了 read 操作的类文件(file-like)对象——传入上面的 count_vowels() 函数,会发现该函数仍然可以正常工作:
>>> from io import StringIO
>>> count_vowels(StringIO('Hello, world!'))
3
你甚至可以从零开始自己实现一个新类型:
class StringList:
"""用于保存多个字符串的数据类,实现了 read() 和可迭代接口"""
def __init__(self, strings):
self.strings = strings
def read(self):
return ''.join(self.strings)
def __iter__(self):
for s in self.strings:
yield s
虽然上面的 StringList 类和文件类型八竿子打不着,但是因为 count_vowels() 函数遵循了鸭子类型编程风格,而 StringList 恰好实现了它所需要的接口,因此 StringList 对象也可以完美适用于 count_vowels 函数:
>>> sl = StringList(['Hello', 'World'])
>>> count_vowels(sl)
3
不过,即便鸭子类型有以上种种好处,我们还是无法对它的缺点视而不见。
鸭子类型的局限性
鸭子类型的第一个缺点是:缺乏标准。在编写鸭子类型代码时,虽然我们不需要做严格的类型校验,但是仍然需要频繁判断对象是否支持某个行为,而这方面并没有统一的标准。
拿前面的文件类型校验来说,你可以选择调用 hasattr(fp, “read”),也可以选择调用 hasattr(fp, “readlines”),还可以直接写 try … except 的 EAFP 风格代码来直接进行操作。
看上去怎么做都行,但究竟哪种最好呢?
鸭子类型的另一个问题是:过于隐式。在鸭子类型编程风格下,对象的真实类型变得不再重要,取而代之的是对象所提供的接口(或者叫协议)变得非常重要。但问题是,鸭子类型里的所有接口和协议都是隐式的,它们全藏在代码和函数的注释中。
举个例子,通过阅读 count_vowels() 函数的代码,你可以知道:fp 文件对象需要提供 read 方法,也需要可迭代。但这些规则都是隐式的、片面的。这意味着你虽然通过读代码了解了大概,但是仍然无法回答这个问题:“究竟是哪些接口定义了文件对象?”。
在鸭子类型里,所有的接口和协议零碎地分布在代码的各个角落,最终虚拟地活在编码者的大脑中。
综合考虑了鸭子类型的种种特点后,你会发现,虽然这非常有效和实用,但有时也会让人觉得过于灵活、缺少规范。尤其是在规模较大的 Python 项目中,如果代码大量使用了鸭子类型,编码者就需要理解很多隐式的接口与规则,很容易不堪重负。
幸运的是,除了鸭子类型以外,Python 还为类型系统提供了许多有效的补充,比如类型注解与静态检查(mypy)、抽象类(abstract class)等。
在下一节,我们会看看抽象类为鸭子类型带来了什么改变。
9.1.4 抽象类
我在前一节提到,在鸭子类型编程风格中,编码者不应该关心对象的类型,只应该关心对象是否支持某些操作。这意味着,用于判断对象类型的 isinstance() 函数在鸭子世界里完全没有用武之地。
但是,自从抽象类出现以后,isinstance() 函数的地位发生了一些微妙的变化。在解释这个变化前,我们先看看 isinstance() 的典型工作模式是什么样的。
isinstance() 函数
假如有以下两个类:
class Validator:
"""校验器基类,校验不同种类的数据是否符合要求"""
def validate(self, value):
raise NotImplementedError
class NumberValidator(Validator):
"""校验输入值是否是合法数字"""
def validate(self, value):
...
Validator 是校验器基类,NumberValidator 是继承了 Valdiator 的校验器子类,如图 9-2 所示。

图 9-2 继承示意图
利用 isinstance() 函数,我们可以判断对象是否属于特定类型:
>>> isinstance(NumberValidator(), NumberValidator)
True
>>> isinstance('foo', Validator)
False
isinstance() 函数能理解类之间的继承关系,因此子类的实例同样可以通过基类的校验:
>>> isinstance(NumberValidator(), Validator)
True
使用 isinstance() 函数,我们可以严格校验对象是否属于某个类型。但问题是:鸭子类型只关心行为,不关心类型,所以 isinstance() 函数天生和鸭子类型的理念相背。不过,在 Python 2.6 版本推出了抽象类以后,事情出现了一些转折。
校验对象是否是 Iterable 类型
在解释抽象类对类型机制的影响前,我们先看看下面这个类:
class ThreeFactory:
"""在被迭代时不断返回 3
:param repeat: 重复次数
"""
def __init__(self, repeat):
self.repeat = repeat
def __iter__(self):
for _ in range(self.repeat):
yield 3
ThreeFactory 是个非常简单的类,它所做的,就是迭代时不断返回数字 3:
>>> obj = ThreeFactory(2) ➊
>>> for i in obj:
... print(i)
...
3
3
❶ 初始化一个会返回两次 3 的新对象
在 collections.abc 模块中,有许多和容器相关的抽象类,比如代表集合的 Set、代表序列的 Sequence 等,其中有一个最简单的抽象类:Iterable,它表示的是可迭代类型。假如你用 isinstance() 函数对上面的 ThreeFactory 实例做类型检查,会得到一个有趣的结果:
>>> from collections.abc import Iterable
>>> isinstance(ThreeFactory(2), Iterable)
True
虽然 ThreeFactory 没有继承 Iterable 类,但当我们用 isinstance() 检查它是否属于 Iterable 类型时,结果却是 True,这正是受了抽象类的特殊子类化机制的影响。
抽象类的子类化机制
在 Python 中,最常见的子类化方式是通过继承基类来创建子类,比如前面的 NumberValidator 就继承了 Validator 类。但抽象类作为一种特殊的基类,为我们提供了另一种更灵活的子类化机制。
为了演示这个机制,我把前面的 Validator 改造成了一个抽象类:
from abc import ABC
class Validator(ABC): ➊
"""校验器抽象类"""
@classmethod
def __subclasshook__(cls, C):
"""任何提供了 validate 方法的类,都被当作 Validator 的子类"""
if any("validate" in B.__dict__ for B in C.__mro__): ➋
return True
return NotImplemented
def validate(self, value):
raise NotImplementedError
❶ 要定义一个抽象类,你需要继承 ABC 类或使用 abc.ABCMeta 元类
❷ C.mro 代表 C 的类派生路线上的所有类(见 9.1.5 节)
上面代码的重点是 subclasshook 类方法。subclasshook 是抽象类的一个特殊方法,当你使用 isinstance 检查对象是否属于某个抽象类时,如果后者定义了这个方法,那么该方法就会被触发,然后:
实例所属类型会作为参数传入该方法(上面代码中的 C 参数);
如果方法返回了布尔值,该值表示实例类型是否属于抽象类的子类;
如果方法返回 NotImplemented,本次调用会被忽略,继续进行正常的子类判断逻辑。
在我编写的 Validator 类中,subclasshook 方法的逻辑是:所有实现了 validate 方法的类都是我的子类。
这意味着,下面这个和 Validator 没有继承关系的类,也被视作 Validator 的子类:
class StringValidator:
def validate(self, value):
...
print(isinstance(StringValidator(), Validator))
# 输出:True
图 9-3 展示了两者的关系。

图 9-3 StringValidator 实现了抽象类 Validator
通过 subclasshook 类方法,我们可以定制抽象类的子类判断逻辑。这种子类化形式只关心结构,不关心真实继承关系,所以常被称为“结构化子类”。
这也是之前的 ThreeFactory 类能通过 Iterable 类型校验的原因,因为 Iterable 抽象类对子类只有一个要求:实现了 iter 方法即可。
除了通过 subclasshook 类方法来定义动态的子类检查逻辑外,你还可以为抽象类手动注册新的子类。
比如,下面的 Foo 是一个没有实现任何方法的空类,但假如通过调用抽象类 Validator 的 register 方法,我们可以马上将它变成 Validator 的“子类”:
>>> class Foo:
... pass
...
>>> isinstance(Foo, Validator) ➊
False
>>> Validator.register(Foo) ➋
False
>>> isinstance(Foo(), Validator) ➌
True
>>> issubclass(Foo, Validator)
True
❶ 默认情况下,Foo 类和 Validator 类没有任何关系
❷ 调用 .register() 把 Foo 注册为 Validator 的子类
❸ 完成注册后,Foo 类的实例就能通过 Validator 的类型校验了
总结一下,抽象类通过 subclasshook 钩子和 .register() 方法,实现了一种比继承更灵活、更松散的子类化机制,并以此改变了 isinstance() 的行为。
有了抽象类以后,我们便可以使用 isinstance(obj, type) 来进行鸭子类型编程风格的类型校验了。只要待匹配类型 type 是抽象类,类型检查就符合鸭子类型编程风格——只校验行为,不校验类型。
抽象类的其他功能
除了更灵活的子类化机制外,抽象类还提供了一些其他功能。比如,利用 abc 模块的 @ abstractmethod 装饰器,你可以把某个方法标记为抽象方法。假如抽象类的子类在继承时,没有重写所有抽象方法,那么它就无法被正常实例化。
举个例子:
class Validator(ABC):
"""校验器抽象类"""
...
@abstractmethod ➊
def validate(self, value):
raise NotImplementedError
class InvalidValidator(Validator): ➋
❶ 把 validate 定义为抽象方法
❷ InvalidValidator 虽然继承了 Validator 抽象类,但没有重写 validate 方法
如果你尝试实例化 InvalidValidator,就会遇到下面的错误:
>>> obj = InvalidValidator()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't instantiate abstract class InvalidValidator with abstract methods validate
这个机制可以帮我们更好地控制子类的继承行为,强制要求其重写某些方法。
此外,虽然抽象类名为抽象,但它也可以像任何普通类一样提供已实现好的非抽象方法。比如 collections.abc 模块里的许多抽象类(如 Set、Mapping 等)像普通基类一样实现了一些公用方法,降低了子类的实现成本。
最后,我们总结一下鸭子类型和抽象类:
鸭子类型是一种编程风格,在这种风格下,代码只关心对象的行为,不关心对象的类型;
鸭子类型降低了类型校验的成本,让代码变得更灵活;
传统的鸭子类型里,各种对象接口和协议都是隐式的,没有统一的显式标准;
普通的 isinstance() 类型检查和鸭子类型的理念是相违背的;
抽象类是一种特殊的类,它可以通过钩子方法来定制动态的子类检查行为;
因为抽象类的定制子类化特性,isinstance() 也变得更灵活、更契合鸭子类型了;
使用 @abstractmethod 装饰器,抽象类可以强制要求子类在继承时重写特定方法;
除了抽象方法以外,抽象类也可以实现普通的基础方法,供子类继承使用;
在 collections.abc 模块中,有许多与容器相关的抽象类。
在第 10 章与第 11 章,你会看到更多有关鸭子类型和抽象类的代码示例。
9.1.5 多重继承与 MRO
许多编程语言在处理继承关系时,只允许子类继承一个父类,而 Python 里的一个类可以同时继承多个父类。这让我们的模型设计变得更灵活,但同时也带来一个新问题:“在复杂的继承关系下,如何确认子类的某个方法会用到哪个父类?”
以下面的代码为例:
class A:
def say(self):
print("I'm A")
class B(A):
pass
class C(A):
def say(self):
print("I'm C")
class D(B, C):
pass
D 同时继承 B 和 C 两个父类,而 B 和 C 都是 A 的子类。此时,如果你调用 D 实例的 say() 方法,究竟会输出 A 还是 C 的结果呢?答案是:
>>> D().say()
I'm C
在解决多重继承的方法优先级问题时,Python 使用了一种名为 MRO(method resolution order)的算法。该算法会遍历类的所有基类,并将它们按优先级从高到低排好序。
调用类的 mro() 方法,你可以看到按 MRO 算法排好序的基类列表:
>>> D.mro()
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
➊
❶ 这里面的 <class ‘object’> 是每个 Python 类的默认基类
图 9-4 展示了类的关系。
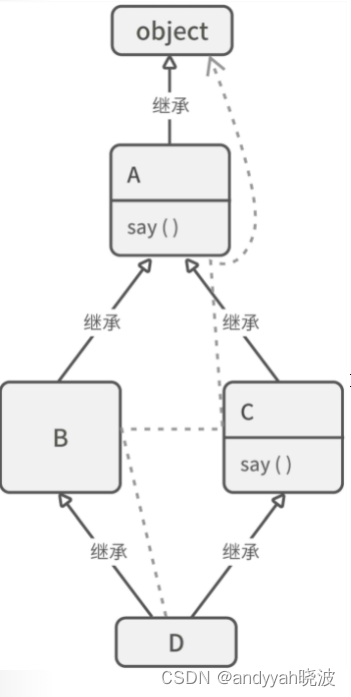
图 9-4 类关系示意图,带箭头的虚线代表 MRO 的解析顺序
当你调用子类的某个方法时,Python 会按照上面的 MRO 列表从前往后寻找这个方法,假如某个类实现了这个方法,就直接返回。这就是前面的 D().say() 定位到了 C 类的原因,因为在 D 的 MRO 列表中,C 排在 A 的前面。
MRO 与 super()
基于 MRO 算法的基类优先级列表,不光定义了类方法的找寻顺序,还影响了另一个常见的内置函数:super()。
在许多人的印象中,super() 是一个用来调用父类方法的工具函数。但这么说并不准确,super() 使用的其实不是当前类的父类,而是它在 MRO 链条里的上一个类。
举个例子:
class A:
def __init__(self):
print("I'm A")
super().__init__()
class B(A):
def __init__(self):
print("I'm B")
super().__init__()
class D1(B):
pass
在上面的单一继承关系下,实例化 D1 类的输出结果很直观:
>>> D1()
I'm B
I'm A
此时,super() 看上去就像是在调用父类的方法。但是,如果稍微调整一下继承关系,把 C 类加入继承关系链里:
...
class C(A):
def __init__(self):
print("I'm C")
super().__init__()
class D2(B, C): ➊
pass
❶ 让 D2 同时继承两个类
实例化 D2 类就会输出下面的结果:
>>> D2()
I'm B
I'm C ➊
I'm A
❶ C 类的 init 方法调用插在了 B 和 A 之间
当我在继承关系里加入 C 类后,B.init() 里的 super() 不会再直接找到 B 的父类 A,而是会定位到当前 MRO 链条里的下一个类,一个看上去和 B 毫不相关的类:C。
正如例子所示,当你在方法中调用 super() 时,其实无法确定它会定位到哪一个类。这是因为你永远不知道使用类的人,会把它加入什么样的 MRO 继承链条里。
总而言之,Python 里的多重继承是一个相当复杂的特性,尤其在配合 super() 时。
在实际项目里,你应该非常谨慎地对待多重继承,因为它很容易催生出一些复杂的继承关系,进而导致代码难以维护。假如你发现自己在实现某个功能时,必须使用多重继承,而且必须用 MRO 算法来精心设计方法间的覆盖关系,此时你应该停下来,喝口水,深吸一口气,重新思考一遍自己想要解决的问题。
以我的经验来看,许多所谓“精心设计”的多重继承代码,也许在写出来的当天编码者会觉得:自己用相当高明的手段解决了一个十分困难的问题。但在一个月后,当其他人需要修改这段代码时,很容易被复杂的继承关系绕晕。
大多数情况下,你需要的并不是多重继承,而也许只是一个更准确的抽象模型,在该模型下,最普通的继承关系就能完美解决问题。
9.1.6 其他知识
面向对象编程所涉及的内容相当多,这意味着,一章很难涵盖所有知识点。
在本节中,我挑选了两个平常较少用到的知识点进行简单介绍。如果你对其中的某个知识点感兴趣,可自行搜索更多资料。
Mixin 模式
顾名思义,Mixin 是一种把额外功能“混入”某个类的技术。有些编程语言(比如 Ruby)为 Mixin 模式提供了原生支持,而在 Python 中,我们可以用多重继承来实现 Mixin 模式。
要实现 Mixin 模式,你需要先定义一个 Mixin 类:
class InfoDumperMixin: ➊
"""Mixin:输出当前实例信息"""
def dump_info(self):
d = self.__dict__
print("Number of members: {}".format(len(d)))
print("Details:")
for key, value in d.items():
print(f' - {key}: {value}')
❶ Mixin 类名常以“Mixin”结尾,这算是一种不成文的约定
相比普通类,Mixin 类有一些鲜明的特征。
Mixin 类通常很简单,只实现一两个功能,所以很多时候为了实现某个复杂功能,一个类常常会同时混入多个 Mixin 类。另外,大多数 Mixin 类不能单独使用,它们只有在被混入其他类时才能发挥最大作用。
下面是一个使用 InfoDumperMixin 的例子:
class Person(InfoDumperMixin):
def __init__(self, name, age):
self.name = name
self.age = age
调用结果如下:
>>> p = Person('jack', 20)
>>> p.dump_info()
Number of members: 2
Details:
- name: jack
- age: 20
虽然 Python 中的 Mixin 模式基于多重继承实现,但令 Mixin 区别于普通多重继承的最大原因在于:Mixin 是一种有约束的多重继承。在 Mixin 模式下,虽然某个类会同时继承多个基类,但里面最多只会有一个基类表示真实的继承关系,剩下的都是用于混入功能的 Mixin 类。这条约束大大降低了多重继承的潜在危害性。
许多流行的 Web 开发框架使用了 Mixin 模式,比如 Django、DRF1 等。
不过,虽然 Mixin 是一种行之有效的编程模式,但不假思索地使用它仍然可能会带来麻烦。有时,人们使用 Mixin 模式的初衷,只是想对糟糕的模型设计做一些廉价的弥补,而这只会把原本糟糕的设计变得更糟。
假如你想使用 Mixin 模式,需要精心设计 Mixin 类的职责,让它们和普通类有所区分,这样才能让 Mixin 模式发挥最大的潜力。
元类
元类是 Python 中的一种特殊对象。元类控制着类的创建行为,就像普通类控制着实例的创建行为一样。
type 是 Python 中最基本的元类,利用 type,你根本不需要手动编写 class … : 代码来创建一个类——直接调用 type() 就行:
>>> Foo = type('Foo', (), {'bar': 3}) ➊
>>> Foo
<class '__main__.Foo'>
>>> Foo().bar
3
❶ 参数分别为 type(name, bases, attrs)
在调用 type() 创建类时,需要提供三个参数,它们的含义如下。
(1) name:str,需要创建的类名。
(2) bases:Tuple[Type],包含其他类的元组,代表类的所有基类。
(3) attrs:Dict[str, Any],包含所有类成员(属性、方法)的字典。
虽然 type 是最基本的元类,但在实际编程中使用它的场景其实比较少。更多情况下,我们会创建一个继承 type 的新元类,然后在里面定制一些与创建类有关的行为。
为了演示元类能做什么,代码清单 9-3 实现了一个简单的元类,它的主要功能是将类方法自动转换成属性对象。另外,该元类还会在创建实例时,为其增加一个代表创建时间的 created_at 属性。
代码清单 9-3 示例元类 AutoPropertyMeta
import time
import types
class AutoPropertyMeta(type): ➊
"""元类:
- 把所有类方法变成动态属性
- 为所有实例增加创建时间属性
"""
def __new__(cls, name, bases, attrs): ➋
for key, value in attrs.items():
if isinstance(value, types.FunctionType) and not key.startswith('_'):
attrs[key] = property(value) ➌
return super().__new__(cls, name, bases, attrs) ➍
def __call__(cls, *args, **kwargs): ➎
inst = super().__call__(*args, **kwargs)
inst.created_at = time.time()
return inst
❶ 元类通常会继承基础元类 type 对象
❷ 元类的 new 方法会在创建类时被调用
❸ 将非私有方法转换为属性对象
❹ 调用 type() 完成真正的类创建
❺ 元类的 call 方法,负责创建与初始化类实例
下面的 Cat 类使用了 AutoPropertyMeta 元类:
import random
class Cat(metaclass=AutoPropertyMeta):
def __init__(self, name):
self.name = name
def sound(self):
repeats = random.randrange(1, 10)
return ' '.join(['Meow'] * repeats)
效果如下:
>>> milo = Cat('milo')
>>> milo.sound ➊
'Meow Meow Meow Meow Meow Meow Meow'
>>> milo.created_at ➋
1615000104.0704262
❶ sound 原本是方法,但是被元类自动转换成了属性对象
❷ 读取由元类定义的创建时间
通过上面这个例子,你会发现元类的功能相当强大,它不光可以修改类,还能修改类的实例。同时它也相当复杂,比如在例子中,我只简单演示了元类的 new 和 call 方法,除此之外,元类其实还有用来准备类命名空间的 prepare 方法。
和 Python 里的其他功能相比,元类是个相当高级的语言特性。通常来说,除非要开发一些框架类工具,否则你在日常工作中根本不需要用到元类。
元类是一种深奥的“魔法”,99% 的用户不必为之操心。如果你在琢磨是否需要元类,那你肯定不需要(那些真正要使用元类的人确信自己的需求,而无须解释缘由)。
Metaclasses are deeper magic than 99% of users should ever worry about. If you wonder whether you need them, you don’t (the people who actually need them know with certainty that they need them, and don’t need an explanation about why).
——Tim Peters
但鲜有使用场景,不代表学习元类就没有意义。我认为了解元类的工作原理,对理解 Python 的面向对象模型大有裨益。
元类很少被使用的原因,除了应用场景少以外,还在于它其实有许多“替代品”,它们是:
(1) 类装饰器(见 8.2.2 节);
(2) init_subclass 钩子方法(见 9.3.1 节);
(3) 描述符(见 12.1.3 节)。
这些工具的功能虽然不如元类那么强大,但它们都比元类简单,更容易理解。日常编码时,它们可以覆盖元类的大部分使用场景。
1DRF 的全称为 Django REST Framework,是一个流行的 REST API 服务开发框架。
9.2 案例故事
我第一次接触面向对象概念,是在十几年前的大学 Java 课上。虽然现在我已经完全忘记了那堂课的内容,但我清楚记得当时用的教科书第一页里的一句话:“面向对象有三大基本特征:封装(encapsulation)、继承(inheritance)与多态(polymorphism)。”
虽然我在课堂上学到的“继承”,作为一个“基本特征”,似乎显得“人畜无害”、很好掌握,不过在之后的十几年编程生涯里,在写过和看过太多糟糕的代码后,我发现“继承”虽然是一个基本概念,但它同时也是面向对象设计中最容易做错的事情之一。有时候,继承带来的问题甚至远比好处多。
为什么这么说呢?假如你用 Google 搜索“inheritance is bad”(继承不好),会发现有多达 6400 万条搜索结果。许多新编程语言甚至完全取缔了继承。比如 2009 年发布的 Go 语言,虽然有一些面向对象语言的特征,但完全不支持继承。
作为曾经的三大面向对象基本特征,继承是怎么慢慢走到今天这一步的呢?我认为这和人们大量误用继承脱不了干系。
众所周知,继承为我们提供了一种强大的代码复用手段——只要继承某个父类,你就能使用它的所有属性和方法,获得它的所有能力。但强大同样也容易招致混乱,错误的继承关系很容易催生出一堆烂代码。
下面我们来看一个关于继承的故事。
继承是把双刃剑
小 R 是一名 Python 后端程序员,三个月前加入了一家移动互联网创业公司。公司的主要产品是一款手机游戏新闻 App——GameNews。在这款 App 里,用户可以浏览最新的游戏资讯,也可以通过评论和其他用户交流。
一个普通的工作日上午,小 R 在工位前坐下,拿出笔记本电脑,准备开始修复昨天没调完的 bug。这时,公司的运营组同事小 Y 走到他的桌前。
“R 哥,有件事儿你能不能帮一下忙?”小 Y 问道。
“什么事儿?”
“是这样的,GameNews 上线都好几个星期了,虽然能查到下载量还不错,但不知道有多少人在用。你能不能在后台加个功能,让我们能查到 GameNews 每天的活跃用户数啊?”
听完小 Y 的描述,小 R 心想,统计 UV 2 数本身不是什么难事儿,但公司现在刚起步,各种数据统计基建都没有,而且新功能需求又排得那么紧,怎么做这个统计最合适呢?
2Unique Visitor 的首字母缩写,表示访问网站的独立访客。对于如何统计独立访客,常见的算法是把每个注册用户算作一个独立访客,或者把每个 IP 地址算作一个独立访客。
看到小 R 眉头微皱,半天不说话,小 Y 怯生生地开口了。
“这个统计是不是特别麻烦?要是麻烦就——”
没等小 Y 说完,小 R 突然就想到了办法。GameNews 几周前刚上线时,小 R 将所有的 API 调用都记录了日志,全部按天保存在了服务器上。通过解析这些日志,他可以很轻松地计算出每天的 UV 数。
“不麻烦,包在我身上,明天上线!”小 R 打断了小 Y。
小 Y 走后,小 R 开始写起了代码。要基于日志来统计每天的 UV 数,程序至少需要做到这几件事:获取日志内容、解析日志、完成统计。
所幸这几件事都不算太难,没过多久,小 R 就写好了下面这个类,如代码清单 9-4 所示。
代码清单 9-4 统计某日 UV 数的类 UniqueVisitorAnalyzer
class UniqueVisitorAnalyzer:
"""统计某日 UV 数
:param date: 需要统计的日期
"""
def __init__(self, date):
self.date = date
def analyze(self):
"""通过解析与分析 API 访问日志,返回 UV 数
:return: UV 数
"""
for entry in self.get_log_entries():
... # 省略:根据 entry.user_id 统计 UV 数并返回结果
def get_log_entries(self):
"""获取当天所有日志记录"""
for line in self.read_log_lines():
yield self.parse_log(line)
def read_log_lines(self):
"""逐行获取访问日志"""
... # 省略:根据日志 self.date 读取日志文件并返回结果
def parse_log(self, line):
"""将纯文本格式的日志解析为结构化对象
:param line: 纯文本格式日志
:return: 结构化的日志条目 LogEntry 对象
"""
... # 省略:复杂的日志解析过程
return LogEntry(
time=...,
ip=...,
path=...,
user_agent=...,
user_id=...,
)
在代码中,UniqueVisitorAnalyzer 类接收日期作为唯一的实例化参数,然后通过 analyze() 方法完成统计。为了统计 UV 数,analyze() 方法需要先读取日志文件,然后解析日志文本,最终基于日志对象 LogEntry 里的 user_id 来计算结果。
经过简单的测试后,小 R 的代码在第二天准时上线,赢得了运营同事的好评。
新需求:统计最热门的 10 条评论
时间过去了一个月,其间 GameNews 的注册用户数增长了不少。
一天上午,小 Y 又来到小 R 的桌前,说道:“R 哥,最近用户发表的评论越来越多,你能不能搞个统计功能,把每天点赞数最多的 10 条评论找出来?这样可以方便我们搞点儿运营活动。”
小 R 接下这个需求后,心想:一个月前不是刚写了那个 UV 统计吗?新需求好像刚好能复用那些代码。于是他打开 IDE,找到自己一个月前写的 UniqueVisitorAnalyzer 类,只花了半分钟就确定了编码思路。
在 GameNews 提供的所有 API 中,评论点赞的 API 路径是有规律的:/comments/<COMMENT_ID>/up_votes/。要统计热门评论,小 R 只需要从每天的 API 访问日志里,把所有的评论和点赞请求找出来,然后通过统计路径里的 COMMENT_ID 就能达到目的。
所以,小 R 决定通过继承来复用 UniqueVisitorAnalyzer 类里的日志读取和解析逻辑,这样他只要写很少的代码就能完成需求。
只花了不到 10 分钟,小 R 就写出了下面的代码:
class Top10CommentsAnalyzer(UniqueVisitorAnalyzer):
"""获取某日点赞量最高的 10 条评论
:param date: 需要统计的日期
"""
limit = 10
def analyze(self):
"""通过解析与统计 API 访问日志,返回点赞量最高的评论
:return: 评论 ID 列表
"""
for entry in self.get_log_entries(): ➊
comment_id = self.extract_comment_id(entry.path)
... # 省略:统计过程与返回结果
def extract_comment_id(self, path):
"""
根据日志访问路径,获取评论 ID。
有效的评论点赞 API 路径格式:/comments/<ID>/up_votes/
:return: 仅当路径是评论点赞 API 时,返回 ID,否则返回 None
"""
matched_obj = re.match('/comments/(.*)/up_votes/', path)
return matched_obj and matched_obj.group(1)
❶ 此处的 get_log_entries() 是由父类提供的方法
基于继承提供的强大复用能力,Top10CommentsAnalyzer 自然而然地获得了父类的日志读取与解析能力,如图 9-5 所示。小 R 只写了不到 20 行代码,就实现了需求,自我感觉相当良好。
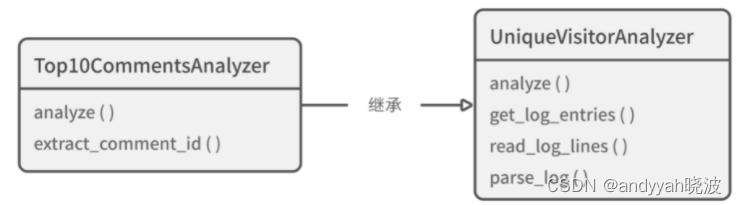
图 9-5 Top10CommentsAnalyzer 继承了 UniqueVisitorAnalyzer
上面的代码看似简单,一个月后却给小 R 带来了不小的麻烦。
修改 UV 逻辑
又过了一个月,小 R 的公司发展得越来越好,有许多新同事入职。一天,运营同事小 Y 又来找小 R。
“R 哥,还记得你两个月前写的那个 UV 统计吗?我们最近觉得,把所有用过 GameNew App 的人都当作活跃用户,其实挺不准的。”小 Y 手里端着一杯咖啡,慢慢说道:“你能不能改一下逻辑,只统计那些真正点开过新闻的用户?”
接到新需求后,小 R 心想:这个需求挺简单的,不如让两周前入职的同事小 V 负责。于是小 R 走到小 V 旁边,和他描述了一遍需求,并详细讲了一遍 UV 统计的代码。
小 V 是一名有经验的开发人员,他很快便明白了应该怎么下手。因为所有访问新闻的 API 路径都是同一种格式:/news//,所以他只要调整一下代码,过滤一遍日志,就能挑选出所有真正看过新闻的用户。
于是,小 V 在 UniqueVisitorAnalyzer 类上做了一点儿调整:
import re
class UniqueVisitorAnalyzer:
...
def get_log_entries(self):
"""获取当天所有日志记录"""
for line in self.read_log_lines():
entry = self.parse_log(line)
if not self.match_news_pattern(entry.path): ➊
continue
yield entry
def match_news_pattern(self, path):
"""判断 API 路径是不是在访问新闻
:param path: API 访问路径
:return: bool
"""
return re.match(r'^/news/[^/]*?/$', path)
❶ 新增日志过滤语句
小 V 在 UniqueVisitorAnalyzer 类上增加了一个方法:match_news_pattern,它负责判断 API 路径是不是访问新闻的路径格式。同时,小 V 在 get_log_entries 里也增加了条件判断——如果当前日志不是访问新闻,就跳过它。
通过上面的修改,小 V 很快实现了只统计“新闻阅读者”的需求。
把代码提交上去以后,小 V 邀请小 R 审查这段改动。小 R 检查后没发现什么问题,于是新代码很快就部署到了线上。
但是,很快就发生了一件所有人都意想不到的事情。
意料之外的 bug
第二天一上班,运营同事小 Y 一路小跑到小 R 身边,一边喘气一边说道:“R 哥,为啥今天 Top 10 评论数据是空的啊?一条评论都没有,赶紧帮看看是咋回事吧!”
小 R 一听觉得奇怪,说:“最近没人调整过那部分逻辑啊,怎么会出问题呢?”
“会不会和我们昨天上线的 UV 统计调整有关?”坐在旁边听到俩人对话的小 V 突然插了一句。
听到这句话,小 R 愣了几秒钟,然后一拍大腿。
“对对对,热门评论统计继承了 UV 统计的类,肯定是昨天的改动影响到了。我审查代码时完全忘记了这回事!”小 R 连忙说道。
于是小 R 打开统计热门评论的代码,很快就找到了问题的原因:
class Top10CommentsAnalyzer(UniqueVisitorAnalyzer):
def analyze(self):
# 当小 V 修改了父类 UniqueVisitorAnalyzer 的
# get_log_entries() 方法后,子类的 get_log_entries()
# 方法调用从此只能拿到路径属于"查看新闻"的日志条目
for entry in self.get_log_entries():
comment_id = self.extract_comment_id(entry.path)
...
def extract_comment_id(self, path):
# 因为输入源发生了变化,所以extract_comment_id() 永远匹配不到
# 任何点赞评论的路径了
matched_obj = re.match('/comments/(.*)/up_votes/', path)
return matched_obj and matched_obj.group(1)
问题产生的整个过程如图 9-6 所示。
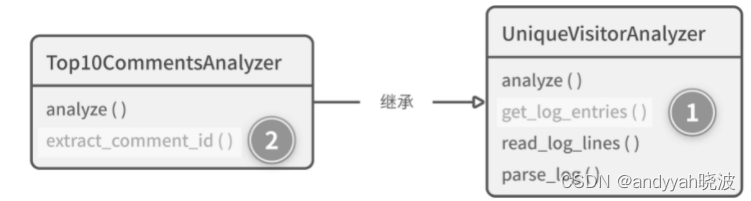
图 9-6 ①修改父类函数,②子类受到影响
从表面上看,这个 bug 似乎是由于两人的粗心大意造成的。小 Y 在写代码时,没有厘清继承关系就随意修改了父类逻辑。而小 R 在审查代码时,也没有仔细推演修改基类可能带来的后果。
但粗心大意只是表面原因。在开发软件时,我们不能指望程序员能够事事考虑得十全十美,永远记得自己写过的每一段代码逻辑,这根本就不现实。错误地使用了继承,才是导致这个 bug 的根本原因。
回顾继承,使用组合
我们回溯到一个月前小 R 接到“统计热门评论”需求的时候。当他发现新需求可以复用 UniqueVisitorAnalyzer 类里的部分方法时,几乎是马上就决定创建一个子类来实现新需求。
但继承是一种类与类之间紧密的耦合关系。让子类继承父类,虽然看上去毫无成本地获取了父类的全部能力,但同时也意味着,从此以后父类的所有改动都可能影响子类。继承关系越复杂,这种影响就越容易超出人们的控制范围。
正是因为继承的这种不可控性,才有了后面小 Y 调整 UV 统计逻辑却影响了热门评论统计的事情。
小 R 使用继承的初衷,是为了复用父类中的方法。但如果只是为了复用代码,其实没有必要使用继承。当小 R 发现新需求要用到 UniqueVisitorAnalyzer 类的“读取日志”“解析日志”行为时,他完全可以用组合(composition)的方式来解决复用问题。
要用组合来复用 UniqueVisitorAnalyzer 类,我们需要先分析这个类的职责与行为。在我看来,UniqueVisitorAnalyzer 类主要负责以下几件事。
读取日志:根据日期找到并读取日志文件。
解析日志:把文本日志信息解析并转换成 LogEntry。
统计日志:统计日志,计算 UV 数。
基于这些事情,我们可以对 UniqueVisitorAnalyzer 类进行拆分,把其中需要复用的两个行为创建为新的类:
class LogReader:
"""根据日期读取特定日志文件"""
def __init__(self, date):
self.date = date
def read_lines(self):
"""逐行获取访问日志"""
... # 省略:根据日志 self.date 读取日志文件并返回结果
class LogParser:
"""将文本日志解析为结构化对象"""
def parse(self, line):
"""将纯文本格式的日志解析为结构化对象
:param line: 纯文本格式的日志
:return: 结构化的日志条目 LogEntry 对象
"""
... # 省略:复杂的日志解析过程
return LogEntry(
time=...,
ip=...,
path=...,
user_agent=...,
user_id=...,
)
LogReader 和 LogParser 两个新类,分别对应 UniqueVisitorAnalyzer 类里的“读取日志”和“解析日志”行为。
相比之前把所有行为都放在 UniqueVisitorAnalyzer 类里的做法,新的代码其实体现了另一种面向对象建模方式——针对事物的行为建模,而不是对事物本身建模。
针对事物本身建模,代表你倾向于用类来重现真实世界里的模型,比如 UniqueVisitorAnalyzer 类就代表“UV 统计”这个需求,如果它要完成“读取日志”“解析日志”这些事情,那就把这些事情作为类方法来实现。而针对事物的行为建模,代表你倾向于用类来重现真实事物的行为与特征,比如用 LogReader 来代表日志读取行为,用 LogParser 来代表日志解析行为。
在多数情况下,基于事物的行为来建模,可以孵化出更好、更灵活的模型设计。
基于新的类和模型,UniqueVisitorAnalyzer 类可以修改为下面这样:
class UniqueVisitorAnalyzer:
"""统计某日的 UV 数"""
def __init__(self, date):
self.date = date
self.log_reader = LogReader(self.date)
self.log_parser = LogParser()
def analyze(self):
"""通过解析与分析 API 访问日志,返回 UV 数
:return: UV 数
"""
for entry in self.get_log_entries():
... # 省略:根据 entry.user_id 统计 UV 数并返回结果
def get_log_entries(self):
"""获取当天所有日志记录"""
for line in self.log_reader.read_lines():
entry = self.log_parser.parse(line)
if not self.match_news_pattern(entry.path):
continue
yield entry
...
虽然这份代码看上去和旧代码相差不大,但如果小 R 拿着这份代码,接到统计热门评论的需求后,他会发现,根本不需要继承 UniqueVisitorAnalyzer 类来实现新需求,只需要利用组合实现下面这样的类就行:
class Top10CommentsAnalyzer:
"""获取某日点赞量最高的 10 条评论"""
limit = 10
def __init__(self, date):
self.log_reader = LogReader(self.date)
self.log_parser = LogParser()
...
def get_log_entries(self):
for line in self.log_reader.read_lines():
entry = self.log_parser.parse(line)
yield entry
使用组合之后的类关系如图 9-7 所示。
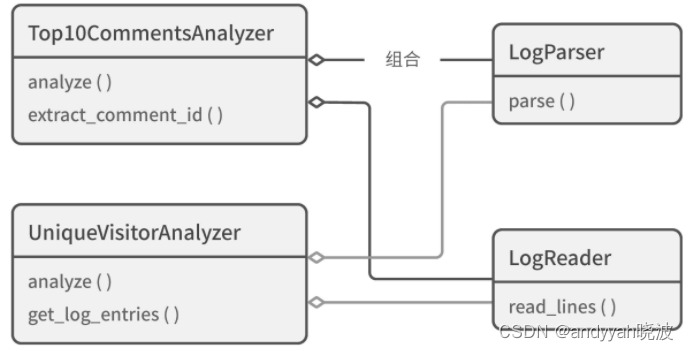
图 9-7 使用组合后的类关系图
新类同样复用了旧代码,但继承关系不见了。没有了继承,后续的 bug 也就根本不会出现。
总结
故事的最后,小 R 与小 V 在一番讨论后,最终选择用上面的结构重构“UV 统计”与“热门评论统计”两个类,用组合替代了继承,解除了它们之间的继承关系。
那么,这个故事告诉了我们什么道理呢?
在编写面向对象代码时,许多人常常把继承当成一种廉价的代码复用手段,当他们看到新需求可以复用某个类的方法时,就会直接创建一个继承该类的子类,快速达到复用目的。但这种简单粗暴的做法忽视了继承的复杂性,容易在未来惹来麻烦。
继承是一种极为紧密的耦合关系。为了避免继承惹来麻烦,每当你想创建新的继承关系时,应该试着问自己几个问题。
我要让 B 类继承 A 类,但 B 和 A 真的代表同一种东西吗?如果它俩不是同类,为什么要继承?
即使 B 和 A 是同类,那它们真的需要用继承来表明类型关系吗?要知道,Python 是鸭子类型的,你不用继承也能实现多态。
如果继承只是为了让 B 类复用 A 类的几个方法,那么用组合来替代继承会不会更好?
假如小 R 在编写代码时,问了自己上面这些问题,那么他就会发现“UV 统计”和“热门评论统计”根本就不是同类,因为它俩连产出的结果类型都不一样,一个返回用户数(int),一个返回评论列表(List[int])。它俩只是碰巧需要共享几个行为而已。
同样是复用代码,组合产生的耦合关系比继承松散得多。如果组合可以达到复用目的,并且能够很好表达事物间的联系,那么常常是更好的选择。这也是人们常说“多用组合,少用继承”的原因。
但这并不代表我们应该完全弃用继承。继承所提供的强大复用能力,仍然是组合所无法替代的。许多设计模式(比如模板方法模式——template method pattern)都是依托继承来实现的。
对待继承,我们应当十分谨慎。每当你想使用继承时,请一定多多对比其他方案、权衡各方利弊,只有当继承能精准契合你的需求时,它才不容易在未来带来麻烦。
从另一种角度看这个故事
在小 R 的这个故事里,我主要以“继承可能导致 bug ”作为论据,分析了继承的优缺点。
在下一章里,你会了解到一些重要的面向对象设计原则,当你理解了“单一职责”“里式替换”原则后,可以重新读一遍这个故事,也许会有不一样的体会。
9.3 编程建议
9.3.1 使用 init_subclass 替代元类
在前面介绍元类时,我提到强大的元类有许多替代工具,它们比元类更简单,可以涵盖元类的部分使用场景。init_subclass 方法就是其中一员。
init_subclass 是类的一个特殊钩子方法,它的主要功能是在类派生出子类时,触发额外的操作。假如某个类实现了这个钩子方法,那么当其他类继承该类时,钩子方法就会被触发。
我用 8.2.2 节中的例子来演示如何使用 init_subclass。在那个例子中,我通过类装饰器实现了自动注册 Validator 子类的功能。其实,这个需求完全可以用 init_subclass 钩子方法来实现。
在下面的代码里,我定义了一个有子类化钩子方法的 Validator 类:
class Validator:
"""校验器基类:统一注册所有校验器类,方便后续使用"""
_validators = {}
def __init_subclass__(cls, **kwargs):
print('{} registered, extra kwargs: {}'.format(cls.__name__, kwargs))
Validator._validators[cls.__name__] = cls
接下来,再定义一些继承了 Validator 的子类:
class StringValidator(Validator, foo='bar'): ➊
name = 'string'
class IntegerValidator(Validator):
name = 'int'
print(Validator._validators)
❶ 子类化时可以提供额外的参数
执行结果如下:
StringValidator registered, extra kwargs: {'foo': 'bar'} ➊
IntegerValidator registered, extra kwargs: {}
{'StringValidator': <class '__main__.StringValidator'>, 'IntegerValidator': <class '__main__.IntegerValidator'>}
➋
❶ 父类的钩子方法被触发,完成子类注册并打印参数
❷ 完成注册
通过上面的例子,你会发现 init_subclass 非常适合在这种需要触达所有子类的场景中使用。而且同元类相比,钩子方法只要求使用者了解继承,不用掌握更高深的元类相关知识,门槛低了不少。它和类装饰器一样,都可以有效替代元类。
9.3.2 在分支中寻找多态的应用时机
多态(polymorphism)是面向对象编程的基本概念之一。它表示同一个方法调用,在运行时会因为对象类型的不同,产生不同效果。比如 animal.bark() 这段代码,在 animal 是 Cat 类型时会发出“喵喵”叫,在 animal 是 Dog 类型时则发出“汪汪”叫。
多态很好理解,当我们看到设计合理的多态代码时,很轻松就能明白代码的意图。但面向对象编程的新手有时会处在一种状态:理解多态,却不知道何时该创建多态。
举个例子,下面的 FancyLogger 是一个记录日志的类:
class FancyLogger:
"""日志类:支持向文件、Redis、ES 等服务输出日志"""
_redis_max_length = 1024
def __init__(self, output_type=OutputType.FILE):
self.output_type = output_type
...
def log(self, message):
"""打印日志"""
if self.output_type == OutputType.FILE:
...
elif self.output_type == OutputType.REDIS:
...
elif self.output_type == OutputType.ES:
...
else:
raise TypeError('output type invalid')
def pre_process(self, message):
"""预处理日志"""
# Redis 对日志最大长度有限制,需要进行裁剪
if self.output_type == OutputType.REDIS:
return message[: self._redis_max_length]
FancyLogger 类接收一个实例化参数:output_type,代表当前的日志输出类型。当输出类型不同时,log() 和 pre_process() 方法会做不同的事情。
上面这段代码就是一个典型的应该使用多态的例子。
FancyLogger 类在日志输出类型不同时,需要有不同的行为。因此,我们完全可以为“输出日志”行为建模一个新的类型:LogWriter,然后把每个类型的不同逻辑封装到各自的 Writer 类中。
对于现有的三种类型,我们可以创建下面的 Writer 类:
class FileWriter:
def write(self, message):
...
class RedisWriter:
max_length = 1024
def write(self, message):
message = self._pre_process(message)
...
def _pre_process(self, message):
# Redis 对日志最大长度有限制,需要进行裁剪
return message[: self.max_length]
class EsWriter: ➊
def write(self, message):
...
❶ 注意:这些 Writer 类都没有继承任何基类,这是因为在 Python 中多态并不需要使用继承。如果你觉得这样不好,也可以选择创建一个 LogWriter 抽象基类
基于这些不同的 Writer 类,FancyLogger 可以简化成下面这样:
class FancyLogger:
"""日志类:支持向文件、Redis、ES 等服务输出日志"""
def __init__(self, output_writer=None):
self._writer = output_writer or FileWriter()
...
def log(self, message):
self._writer.write(message)
新代码利用多态特性,完全消除了原来的条件判断语句。另外你会发现,新代码的扩展性也远比旧代码好。
假如你想增加一种新的输出类型。在旧代码中,你需要分别修改 FancyLogger 类的 log()、pre_process() 等多个方法,在里面增加新的类型判断逻辑。而在新代码中,你只要增加一个新的 Writer 类即可,多态会帮你搞定剩下的事情。
当你深入思考多态时,会发现它是一种思维的杠杆,是一种“以少胜多”的过程。
比起把所有的分支和可能性,一股脑儿地塞进程序员的脑子里,多态思想驱使我们更积极地寻找有效的抽象,以此隔离各个模块,让它们之间通过规范的接口来通信。模块因此变得更容易扩展,代码也变得更好理解了。
找到使用多态的时机
当你发现自己的代码出现以下特征时:
有许多 if/else 判断,并且这些判断语句的条件都非常类似;
有许多针对类型的 isinstance() 判断逻辑。
你应该问自己一个问题:代码是不是缺少了某种抽象?如果增加这个抽象,这些分布在各处的条件分支,是不是可以用多态来表现?如果答案是肯定的,那就去找到那个抽象吧!
9.3.3 有序组织你的类方法
在编写类时,有一个常被忽略的细节:类方法的组织顺序。这个细节很小,并不影响代码的正确性,和程序的执行效率也没有任何关系。但如果你在写代码时忽视了它,就会让整个类变得十分难懂。
举个例子,下面这个类的方法组织顺序就很糟糕:
class UserServiceClient:
"""请求用户服务的 Client 模块"""
def __init__(self, service_host, user_token): ...
def __str__(self):
return f'UserServiceClient: {self.service_host}'
def get_user_profile(self, user_id):
"""获取用户资料"""
def request(self, params, headers, response_type):
"""发送请求"""
@staticmethod
def _parse_username(username):
"""解析用户名"""
def _filter_posts(self, posts):
"""过滤无效的用户文章"""
def get_user_posts(self, user_id):
"""获取用户所有文章"""
@classmethod
def initialize_from_request(self, request):
"""从当前请求初始化一个 UserServiceClient 对象"""
当从上而下阅读 UserServiceClient 类时,你的思维会不断地来回跳跃,很难搞明白它所提供的主要接口究竟是什么。
在组织类方法时,我们应该关注使用者的诉求,把他们最想知道的内容放在前面,把他们不那么关心的内容放在后面。下面是一些关于组织方法顺序的建议。
作为惯例,init 实例化方法应该总是放在类的最前面,new 方法同理。
公有方法应该放在类的前面,因为它们是其他模块调用类的入口,是类的门面,也是所有人最关心的内容。以 _ 开头的私有方法,大部分是类自身的实现细节,应该放在靠后的位置。
至于类方法、静态方法和属性对象,你不必将它们区分对待,直接参考公有 / 私有的思路即可。比如,大部分类方法是公有的,所有它们通常会比较靠前。而静态方法常常是内部使用的私有方法,所以常放在靠后的位置。
以 __ 开头的魔法方法比较特殊,我通常会按照方法的重要程度来决定它们的位置。比如一个迭代器类的 iter 方法应该放在非常靠前的位置,因为它是构成类接口的重要方法。
最后一点,当你从上往下阅读类时,所有方法的抽象级别应该是不断降低的,就好像阅读一篇新闻一样,第一段是新闻的概要,之后才会描述细节。
基于上面这些原则,我重新组织了 UserServiceClient 类:
class UserServiceClient:
"""请求用户服务的 Client 模块"""
def __init__(self, service_host, user_token): ...
@classmethod
def initialize_from_request(self, request): ➊
"""从当前请求初始化一个 UserServiceClient 对象"""
def get_user_profile(self, user_id):
"""获取用户资料"""
def get_user_posts(self, user_id):
"""获取用户所有文章"""
def request(self, params, headers, response_type): ➋
"""发送请求"""
def _filter_posts(self, posts): ➌
"""过滤无效的用户文章"""
@staticmethod
def _parse_username(username):
"""解析用户名"""
def __str__(self): ➍
return f'UserServiceClient: {self.service_host}'
❶ initialize_from_request 是类对外提供的 API,所以放在靠前的位置
❷ request 方法比其他两个公开方法的抽象级别要低,所以放在它们后面
❸ 私有方法靠后放置
❹ str 魔法方法对于当前类来说不是很重要,可以放在靠后的位置
如何组织类方法,其实是件很主观的事情,你完全可以不理会我说的这套原则,而使用自己的方式。但是,无论你选择哪种原则来组织类方法,请一定保证该原则应用到了所有类上,不然代码看上去会很不统一,非常奇怪。
9.3.4 函数搭配,干活不累
和那些严格的面向对象语言不同,在 Python 中,“面向对象”不必特别纯粹,你不必严格套用经典的 23 种设计模式,开口“抽象工厂”,闭口“命令模式”,只通过类来实现所有功能。在写代码时,如果你在原有的面向对象代码上,撒上一点儿函数作为调味品,就会发生奇妙的化学反应。
比如在 8.1.5 节中,我们就试过用函数搭配装饰器类,来实现有参数装饰器。
除此之外,用函数搭配面向对象代码还能实现许多其他功能。
用函数降低 API 使用成本
在 Python 社区中,有一个非常著名的第三方 HTTP 工具包:requests,它简单易用、功能强大,是开发者最爱的工具之一。requests 成功的原因有很多,但我认为其中最重要的一个,就是它提供了一套非常简洁易用的 API。
使用 requests 请求某个网址,只要写两行代码即可:
import requests
r = requests.get('https://example.com', auth=('user', 'pass'))
显而易见,这套让 requests 引以为傲的简洁 API 是基于函数来实现的。在 requests 包的 init 模块中,定义了许多常用的 API 函数,比如 get()、post()、request() 等。
但重点在于,虽然这些 API 都是普通函数,但 requests 内部完全是基于面向对象思想编写的。拿 requests.request() 函数来说,它的内部实现其实是这样的:
# 来自 requests.api 模块
from request import sessions
def request(method, url, **kwargs):
with sessions.Session() as session: ➊
return session.request(method=method, url=url, **kwargs)
❶ 实例化一个 Session 上下文对象,完成请求
假如 requests 包的作者删掉这个函数,让用户直接使用 sessions.Session() 对象,行不行?当然可以。但在使用者看来,显然调用函数比实例化 Session() 对象要讨喜得多。
在 Python 中,像上面这种用函数搭配面向对象的代码非常多见,它有点儿像设计模式中的外观模式(facade pattern)。在该模式中,函数作为一种简化 API 的工具,封装了复杂的面向对象功能,大大降低了使用成本。
实现“预绑定方法模式”
假设你在开发一个程序,它的所有配置项都保存在一个特定文件中。在项目启动时,程序需要从配置文件中读取所有配置项,然后将其加载进内存供其他模块使用。
由于程序执行时只需要一个全局的配置对象,因此你觉得这个场景非常适合使用经典设计模式:单例模式(singleton pattern)。
下面的代码就应用了单例模式的配置类 AppConfig:
class AppConfig:
"""程序配置类,使用单例模式"""
_instance = None
def __new__(cls):
if cls._instance is None:
inst = super().__new__(cls)
# 省略:从外部配置文件读取配置
...
cls._instance = inst
return cls._instance
def get_database(self):
"""读取数据库配置"""
...
def reload(self):
"""重新读取配置文件,刷新配置"""
...
在 Python 中,实现单例模式的方式有很多,而上面这种最为常见,它通过重写类的 new 方法来接管实例创建行为。当 new 方法被重写后,类的每次实例化返回的不再是新实例,而是同一个已经初始化的旧实例 cls._instance:
>>> c1 = AppConfig()
>>> c2 = AppConfig()
>>> c1 is c2 ➊
True
❶ 测试单例模式,调用 AppConfig() 总是会产生同一个对象
基于上面的设计,如果其他人想读取数据库配置,代码需要这样写:
from project.config import AppConfig
db_conf = AppConfig().get_database()
# 重新加载配置
AppConfig().reload()
虽然在处理这种全局配置对象时,单例模式是一种行之有效的解决方案,但在 Python 中,其实有一种更简单的做法——预绑定方法模式。
预绑定方法模式(prebound method pattern)是一种将对象方法绑定为函数的模式。要实现该模式,第一步就是完全删掉 AppConfig 里的单例设计模式。因为在 Python 里,实现单例压根儿不用这么麻烦,我们有一个随手可得的单例对象——模块(module)。
当你在 Python 中执行 import 语句导入模块时,无论 import 执行了多少次,每个被导入的模块在内存中只会存在一份(保存在 sys.modules 中)。因此,要实现单例模式,只需在模块里创建一个全局对象即可:
class AppConfig:
"""程序配置类,使用单例模式"""
def __init__(self): ➊
# 省略:从外部配置文件读取配置
...
_config = AppConfig() ➋
❶ 完全删掉单例模式的相关代码,只实现 init 方法
❷ _config 就是我们的“单例 AppConfig 对象”,它以下划线开头命名,表明自己是一个私有全局变量,以免其他人直接操作
下一步,为了给其他模块提供好用的 API,我们需要将单例对象 _config 的公有方法绑定到 config 模块上:
# file: project/config.py
_config = Config()
get_database_conf = _config.get_database
reload_config = _config.reload
之后,其他模块就可以像调用普通函数一样操作应用配置对象了:
from project.config import get_databse_conf
db_conf = get_databse_conf()
reload_config()
通过“预绑定方法模式”,我们既避免了复杂的单例设计模式,又有了更易使用的函数 API,可谓一举两得。
9.4 总结
在本章中,我们学习了许多与面向对象编程有关的知识。
Python 是一门面向对象的编程语言,它为面向对象编程提供了非常全面的支持。但和其他编程语言相比,Python 中的面向对象有许多细微区别。比如,Python 并没有严格的私有成员,大多数时候,我们只要给变量加上下划线 _ 前缀,意思意思就够了。
和许多静态类型语言不同,在 Python 中,我们遵循“鸭子类型”编程风格,极少对变量进行严格的类型检查。“鸭子类型”是一种非常实用的编程风格,但也有缺乏标准、过于隐式的缺点。为了部分弥补这些缺点,我们可以用抽象类来实现更灵活的子类化检查。
在创建类时,你除了可以定义普通方法外,还可以通过 @classmethod、@property 等装饰器定义许多特殊对象,这些对象在各自的适宜场景下可以发挥重要作用。
在 Python 中,一个类可以同时继承多个基类,Mixin 模式正是依赖这种技术实现的。但多重继承非常复杂、容易搞砸,使用时请务必当心。
本章讲述了一个和继承有关的案例故事。虽然继承是面向对象的基本特征之一,但它也很容易被误用。你应该学会判断何时该使用继承,何时该用组合代替继承。
在下一章里,我们会通过一些实际案例,继续深入探索一些经典的面向对象设计原则。
以下是本章要点知识总结。
(1) 语言基础知识
类与实例的数据,都保存在一个名为 dict 的字典属性中
灵活利用 dict 属性,能帮你做到常规做法难以完成的一些事情
使用 @classmethod 可以定义类方法,类方法常用作工厂方法
使用 @staticmethod 可以定义静态方法,静态方法不依赖实例状态,是一种无状态方法
使用 @property 可以定义动态属性对象,该属性对象的获取、设置和删除行为都支持自定义
(2) 面向对象高级特性
Python 使用 MRO 算法来确定多重继承时的方法优先级
super() 函数获取的并不是当前类的父类,而是当前 MRO 链条里的下一个类
Mixin 是一种基于多重继承的有效编程模式,用好 Mixin 需要精心的设计
元类的功能相当强大,但同时也相当复杂,除非开发一些框架类工具,否则你极少需要使用元类
元类有许多更简单的替代品,比如类装饰器、子类化钩子方法等
通过定义 init_subclass 钩子方法,你可以在某个类被继承时执行自定义逻辑
(3) 鸭子类型与抽象类
鸭鸭“鸭子类型”是 Python 语言最为鲜明的特点之一,在该风格下,一般不做任何严格的类型检查
虽然“鸭子类型”非常实用,但是它有两个明显的缺点——缺乏标准和过于隐式
抽象类提供了一种更灵活的子类化机制,我们可以通过定义抽象类来改变 isinstance() 的行为
通过 @abstractmethod 装饰器,你可以要求抽象类的子类必须实现某个方法
(4) 面向对象设计
继承提供了相当强大的代码复用机制,但同时也带来了非常紧密的耦合关系
错误使用继承容易导致代码失控
对事物的行为而不是事物本身建模,更容易孵化出好的面向对象设计
在创建继承关系时应当谨慎。用组合来替代继承有时是更好的做法
(5) 函数与面向对象的配合
Python 里的面向对象不必特别纯粹,假如用函数打一点儿配合,你可以设计出更好的代码
可以像 requests 模块一样,用函数为自己的面向对象模块实现一些更易用的 API
在 Python 中,我们极少会应用真正的“单例模式”,大多数情况下,一个简单的模块级全局对象就够了
使用“预绑定方法模式”,你可以快速为普通实例包装出类似普通函数的 API
(6) 代码编写细节
Python 的成员私有协议并不严格,如果你想标示某个属性为私有,使用单下划线前缀就够了
编写类时,类方法排序应该遵循某种特殊规则,把读者最关心的内容摆在最前面
多态是面向对象编程里的基本概念,同时也是最强大的思维工具之一
多态可能的介入时机:许多类似的条件分支判断、许多针对类型的 isinstance() 判断


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









