



你要是实际使用过,你就会发现qwen根本就打不赢现在的deepseek。DeepSeek并不算三流模型,在Artihcial Analysis的智能指数排名在第十一位.
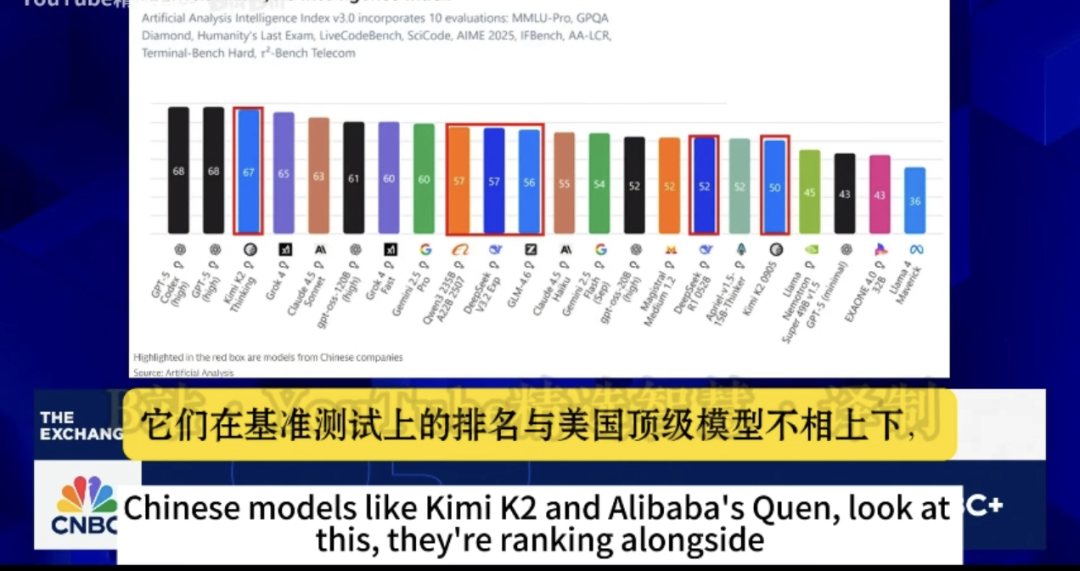
他们的很多跑分都是把人家的题目加入到训练集中,导致跑分特别高,实测能力根本就不行。以前openai还被爆买通了出题方,因为这个里面的利益实在是太大了,只要跑分高,然后上新闻,用的人就多,实际使用根本达不到他们宣传的效果。
DeepSeek要面对的竞争堪称AI版“复仇者联盟内战”:OpenAI的GPT系列像科技感十足的钢铁侠,Anthropic像严谨的美队,谷歌的Gemini则像能千变万化的惊奇队长。国内的技术路线向来更注重模型架构的精巧设计。DeepSeek在开源大模型领域的技术积淀其实始终保持着相当的竞争力。
很多宣传是属于资本的需要,实际上就是很多自己学测试用例就是DS最好,其它模型都是吹牛逼
再来看看如今的业界普遍采用的多专家架构(MoE),其规模化应用正是从DeepSeek R1开始成为标准配置的。
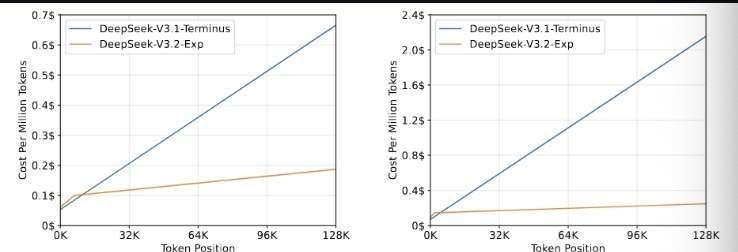
9月份正式推出了采用DSA+技术的DeepSeek-V3.2-Exp模型。作为DeepSeek家族中的实验性成员,V3.2-Exp堪称是通向下一代架构的关键里程碑。这个版本在V3.1-Terminus的坚实基础上,创新性地引入了DeepSeek稀疏注意力机制(DSA)。这项突破性技术的主要使命,就是要在长上下文场景的战场上,为训练与推理效率的极限优化开辟出一条全新的技术路径。
这就像在资源受限的情况下,工程师们不得不发挥极致创意:当计算卡有限、算力吃紧时,我们就必须在架构设计上闪转腾挪,让有限的计算资源发挥最大效能,用小米加步枪的配置实现机关枪的火力输出。
在实际应用层面,众多国内企业级软件已经深度集成DeepSeek的能力,从办公协同到智能客服,从代码生成到数据分析,其应用场景正在持续拓宽。这种扎根产业的生态建设,恰恰构成了其独特的竞争优势。
至于近期市场声量的变化,与其说是技术落后,不如说是推广策略的自然结果。DeepSeek始终坚持零商业投放的推广模式,完全依靠模型能力带来的惊艳体验实现用户自传播。
这种“酒香不怕巷子深”的路线虽然难以在短期内触达海量用户,但每一个被模型能力折服的用户都会成为忠实拥趸
这种基于技术认同建立的用户生态,往往具有更强的生命力和延展性
人家的目标就不是商业化,国家和人民对它的期望是赚钱吗,而且他们会缺钱吗,根本不可能啊。所以它只在迭代底层模型,不关注工程能力,这才是根本。。。
不管怎么样,我都看好DeepSeek!!!


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











