




温馨提示:文末有 优快云 平台官方提供的学长 QQ 名片 :)
1. 项目简介
随着金融服务市场的日益饱和以及金融科技公司的崛起,银行面临着前所未有的客户流失挑战。基于机器学习的银行客户流失预测分析系统旨在通过深入分析客户数据,识别出可能流失的高风险客户群体,并为银行提供针对性的挽留策略建议。系统采用Flask后端、Bootstrap前端,结合SQLite数据库存储数据。关键技术包括数据预处理(缺失值检测、特征编码)、多种机器学习模型(随机森林、XGBoost等)训练与评估,以及可视化分析(客户分布、特征相关性等)。系统功能涵盖用户管理、多维数据分析及流失预测,帮助银行制定精准挽留策略,提升客户留存率。
系统演示视频详见B站:基于机器学习的银行客户流失预测分析系统
2. 关键技术点
(1)后端技术栈
- 数据库 :SQLite 关系数据库,轻量级且高效
- Web框架 :Flask,Python轻量级Web开发框架
- 数据库ORM :SQLAlchemy,提供强大的数据库交互能力
- 机器学习 :scikit-learn、XGBoost等主流算法库
(2)前端技术栈
- 基础技术 :HTML5、CSS3、JavaScript
- UI框架 :Bootstrap 5,确保响应式设计
- 交互增强 :jQuery,提升用户体验
- 图表可视化 :Chart.js,实现数据可视化
(3)数据分析技术
- 数据处理 :pandas、numpy进行高效数据分析
- 可视化 :matplotlib、seaborn生成专业图表
- 机器学习 :随机森林、XGBoost等多种算法模型
3. 银行客户流失预测建模
3.1 数据读取
# 加载数据
df = pd.read_csv('bank_churn_data.csv')
# 显示数据基本信息
print("数据集形状:", df.shape)
print("\n数据集前5行:")
df.head()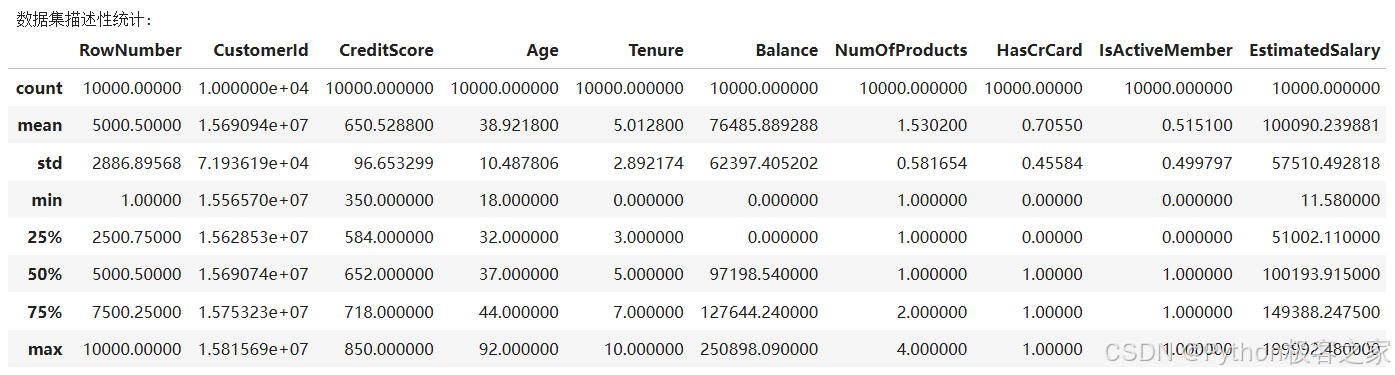
3.2 缺失值、重复值检测
# 检查缺失值
print("缺失值统计:")
missing_values = df.isnull().sum()
print(missing_values[missing_values > 0])
if missing_values.sum() == 0:
print("数据集中没有缺失值")
# 检查重复值
print(f"\n重复行数量: {df.duplicated().sum()}")
3.3 数据可视化分析
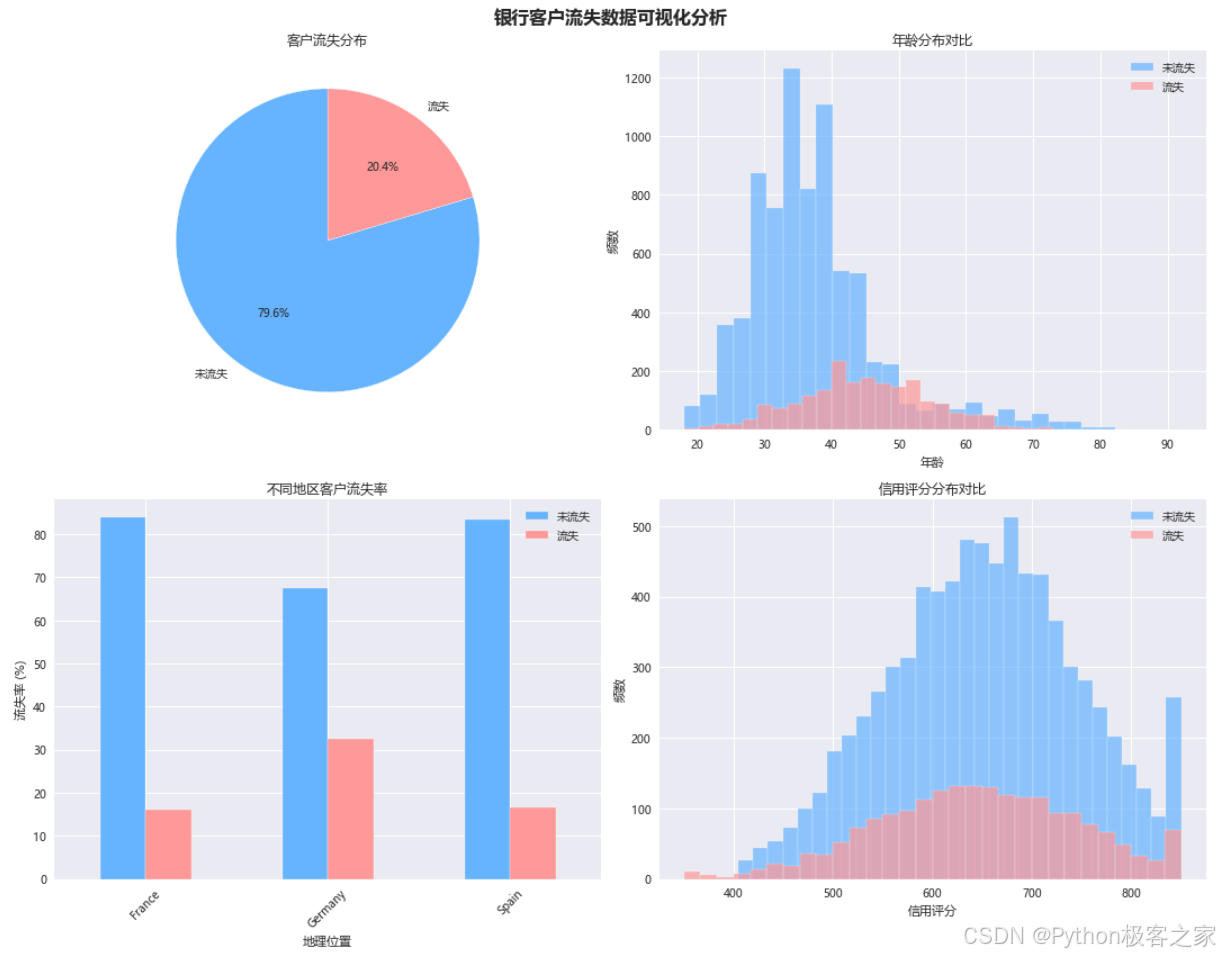
3.3.1 客户流失分布、年龄分布、地理位置与流失关系、信用评分
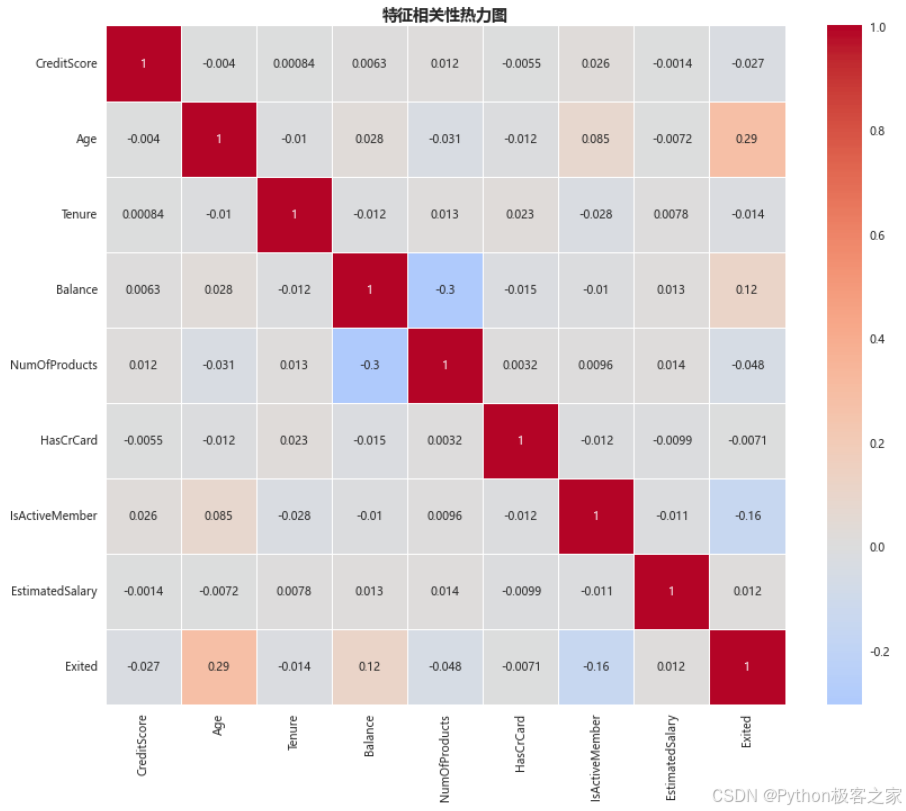
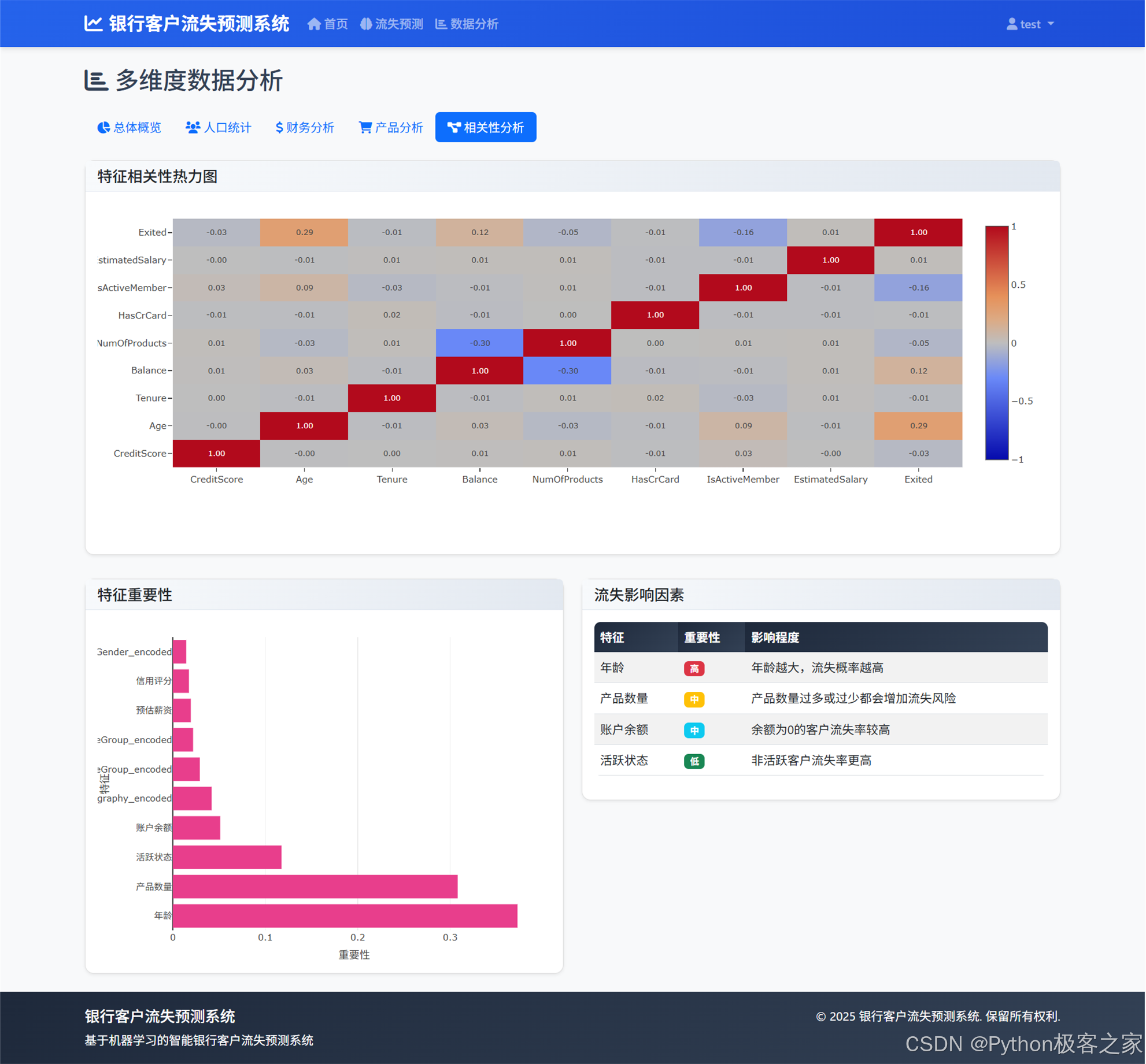
3.3.2 相关性热力图
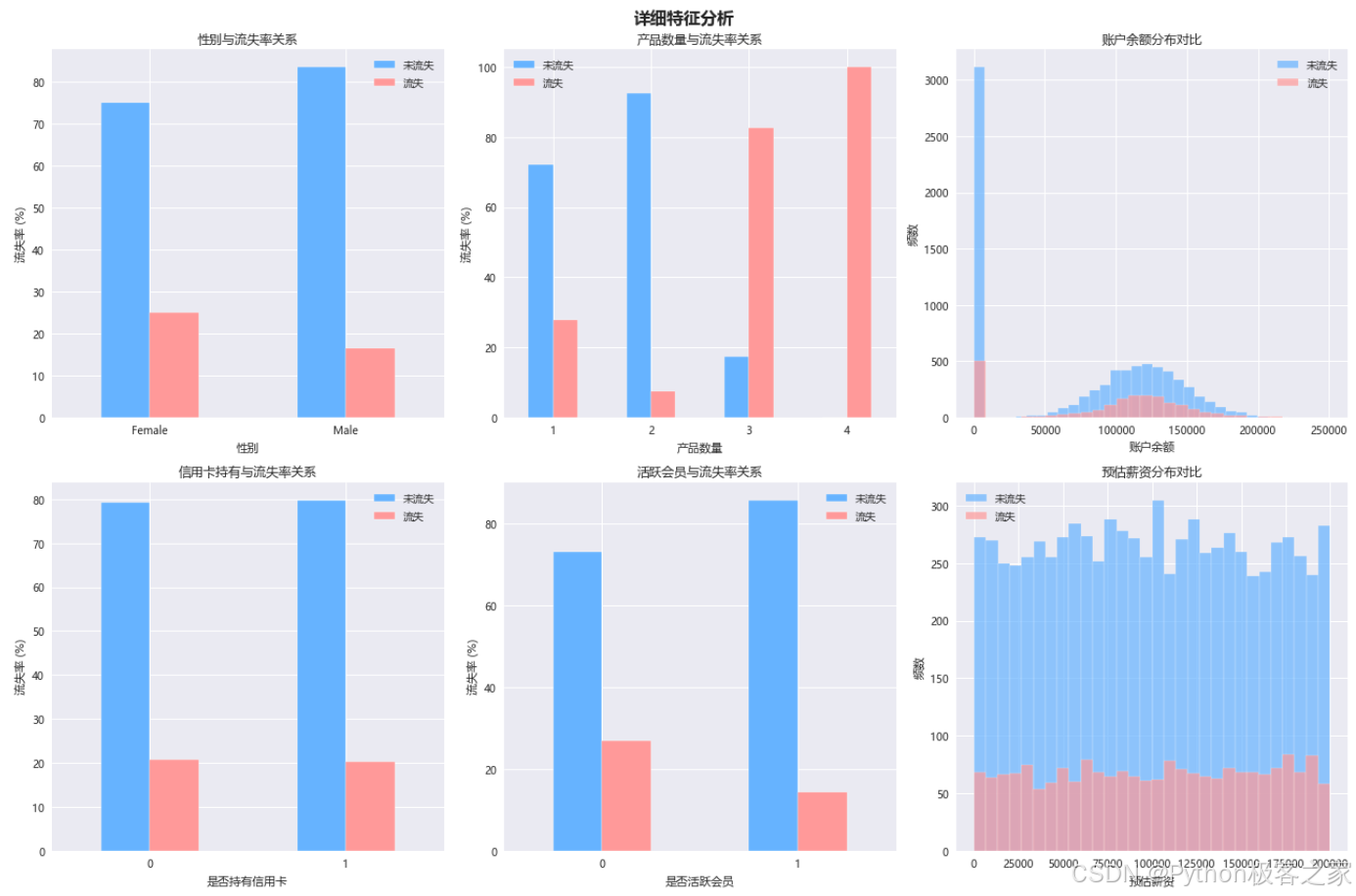
3.3.3 性别与流失、产品数量与流失、账户余额分布、是否持有信用卡与流失、是否活跃会员与流失、预估薪资分布
3.4 特征工程
# 对分类变量进行编码
# 地理位置编码
geography_encoder = LabelEncoder()
df_processed['Geography_encoded'] = geography_encoder.fit_transform(df_processed['Geography'])
......
# 性别编码
gender_encoder = LabelEncoder()
df_processed['Gender_encoded'] = gender_encoder.fit_transform(df_processed['Gender'])
# 创建新的特征
# 年龄分组
......
# 数据分割和标准化
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
print("训练集形状:", X_train.shape, y_train.shape)
print("测试集形状:", X_test.shape, y_test.shape)
# 检查训练集和测试集中的类别分布
print("\n训练集中的类别分布:")
print(y_train.value_counts(normalize=True))
print("\n测试集中的类别分布:")
print(y_test.value_counts(normalize=True))3.5 机器学习模型构建和训练
# 训练和评估每个模型
for name, model in models.items():
print(f"训练 {name}...")
# 对于逻辑回归使用标准化数据,其他模型使用原始数据
if name == 'Logistic Regression':
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
y_pred_proba = model.predict_proba(X_test_scaled)[:, 1]
else:
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
......
# 存储结果
model_results[name] = {
'model': model,
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1': f1,
'auc': auc,
'y_pred': y_pred,
'y_pred_proba': y_pred_proba
}
print(f" 准确率: {accuracy:.4f}")
print(f" 精确率: {precision:.4f}")
print(f" 召回率: {recall:.4f}")
print(f" F1分数: {f1:.4f}")
print(f" AUC: {auc:.4f}")
print("-" * 50)3.6 模型评估和比较
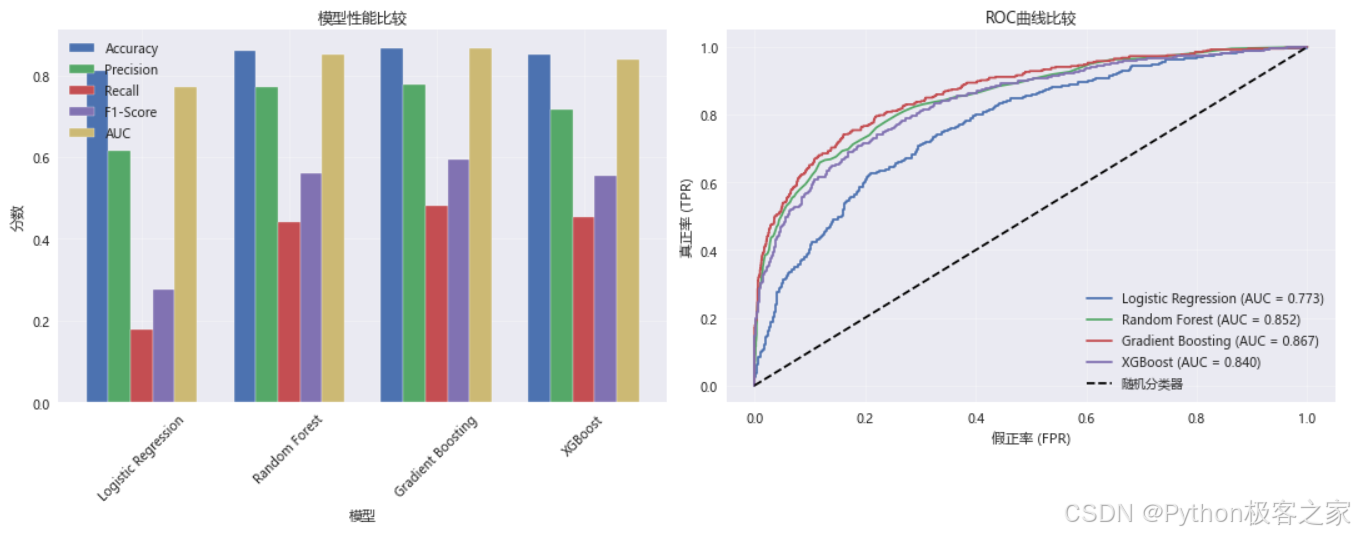
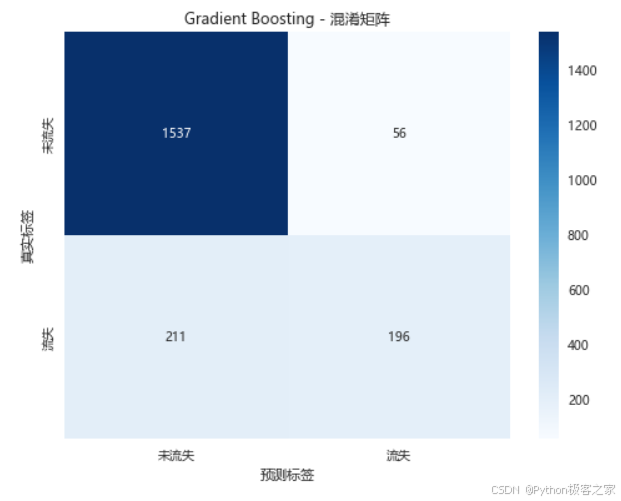
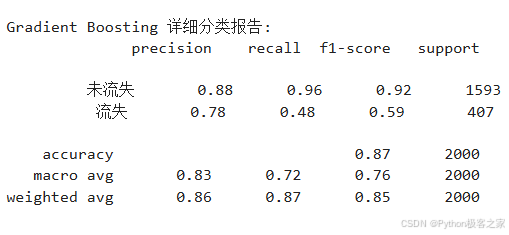
3.7 特征重要性分析
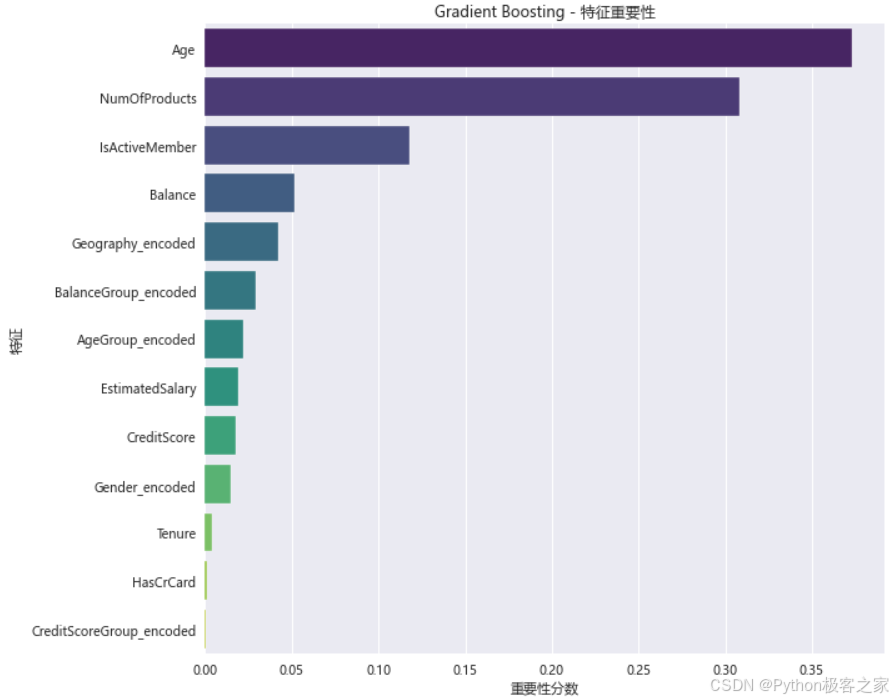
4. 银行客户流失预测系统
4.1 首页
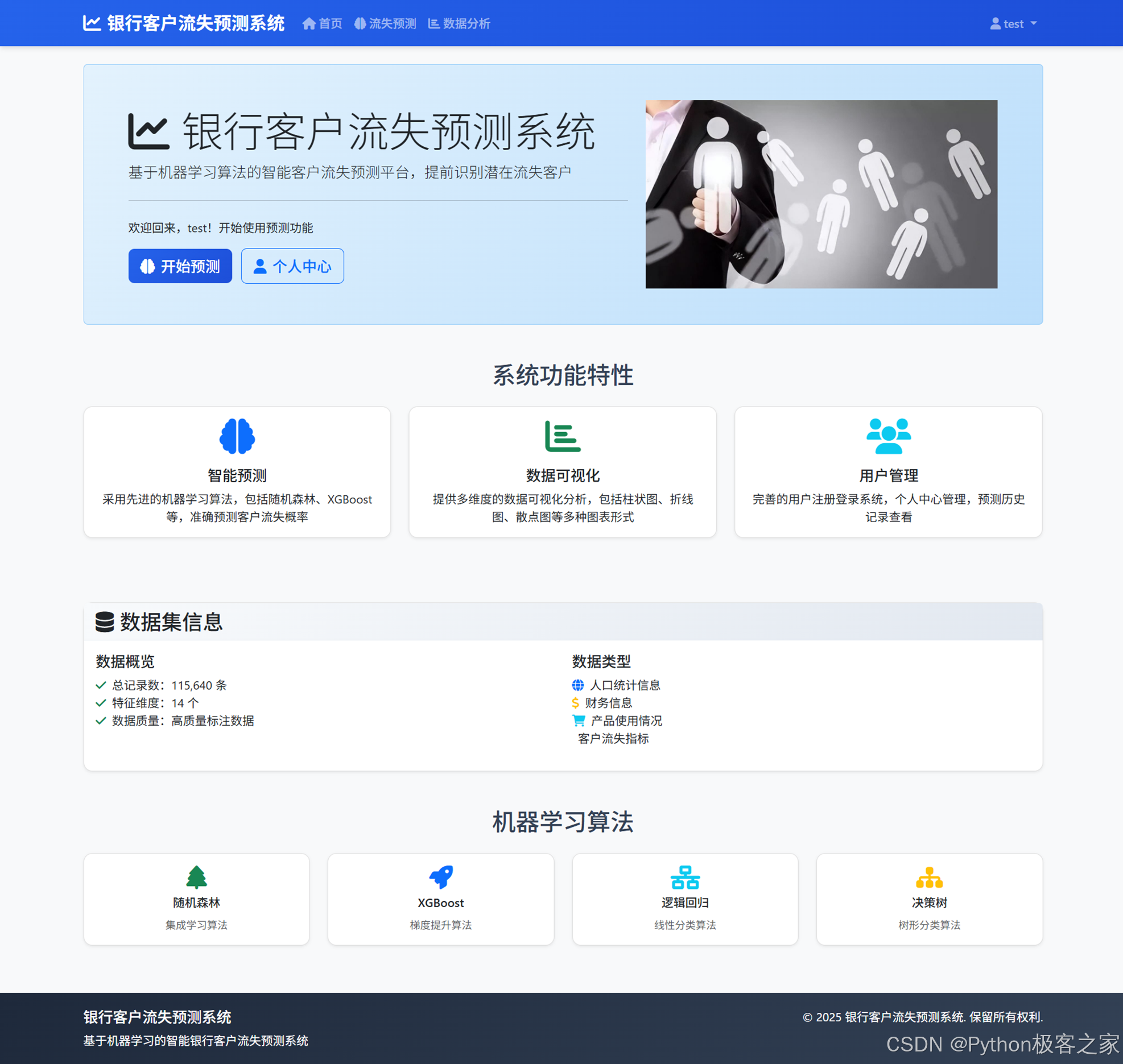
4.2 用户注册登录
4.2.1 用户注册
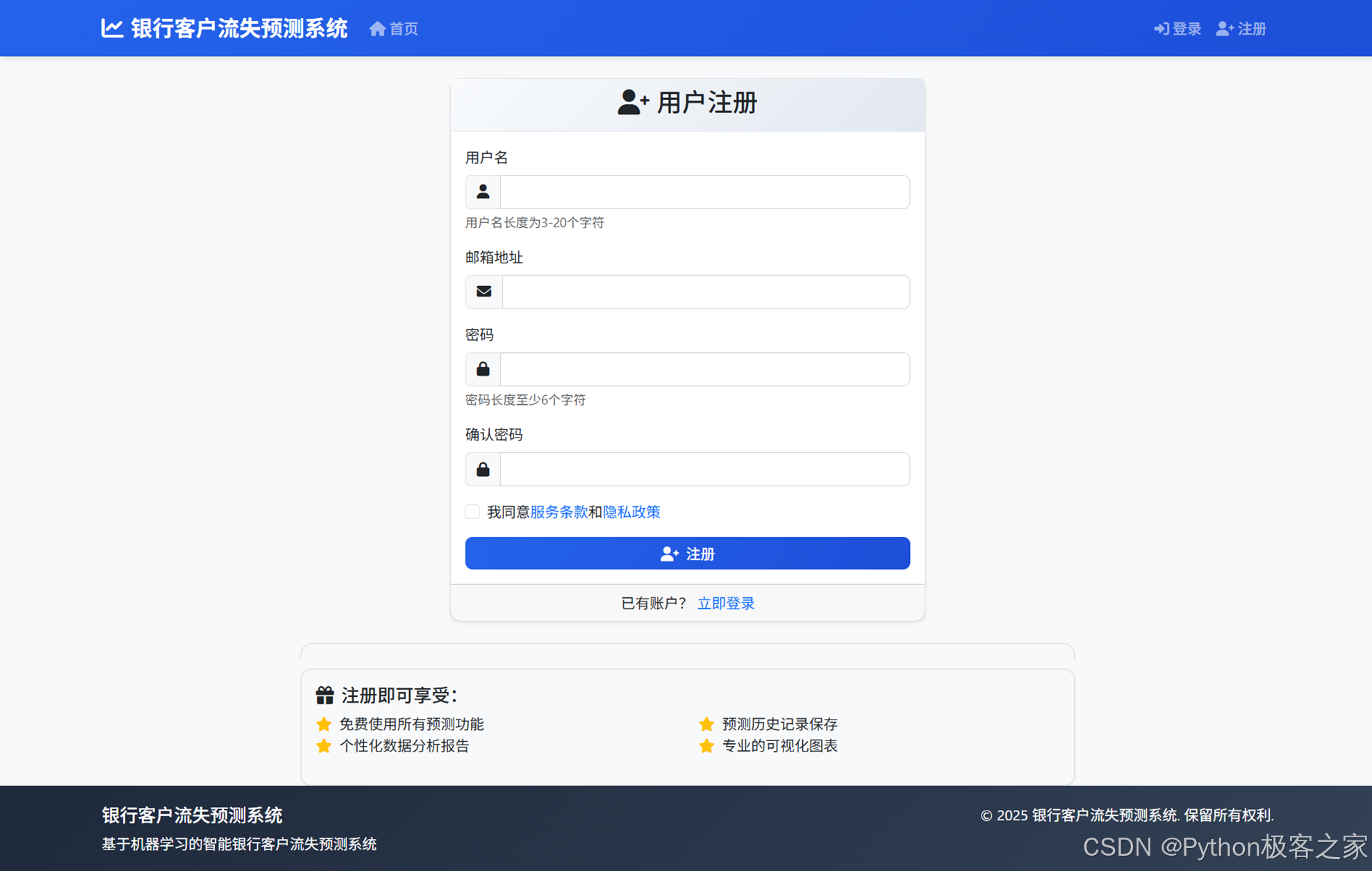
4.2.2 用户登录
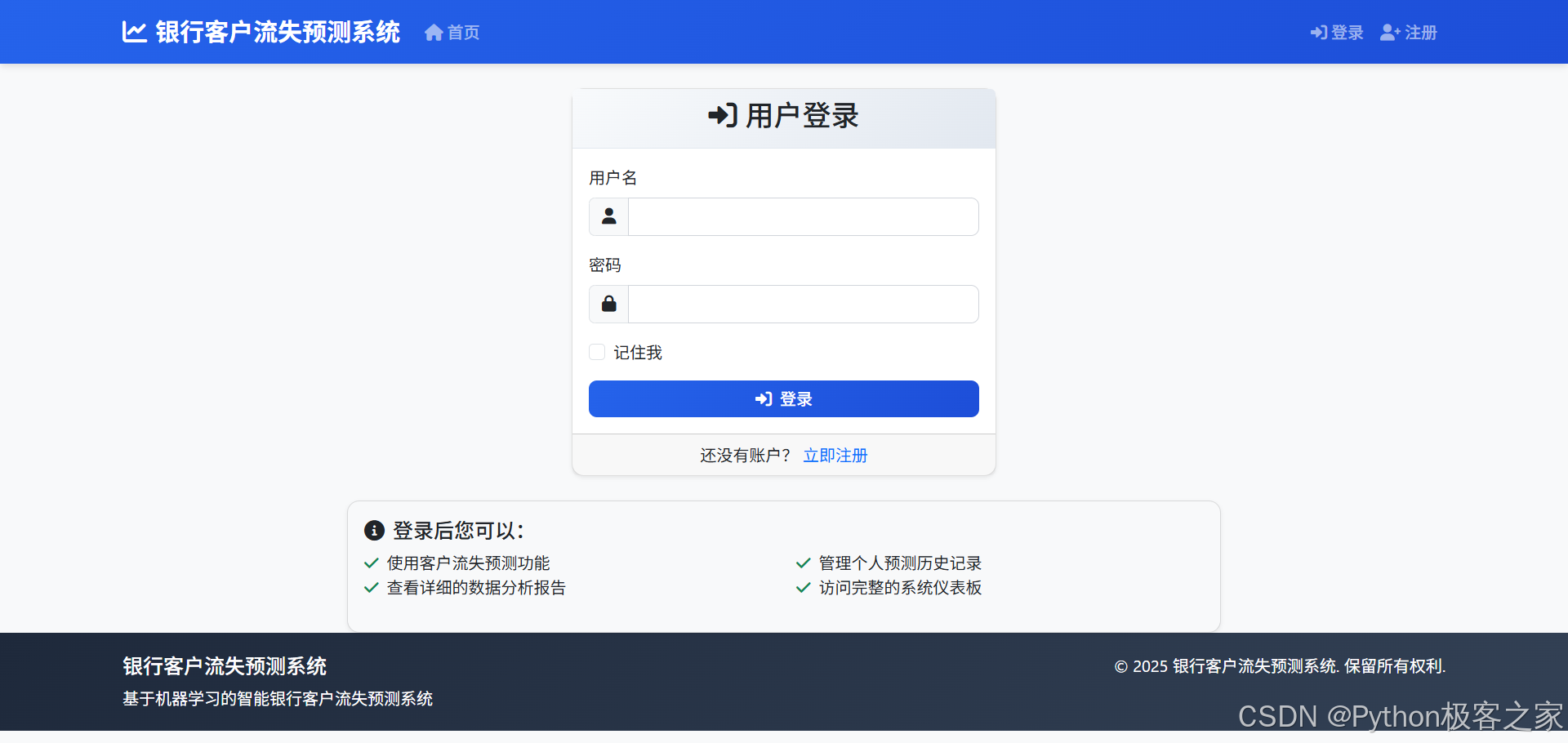
4.2.3 个人中心
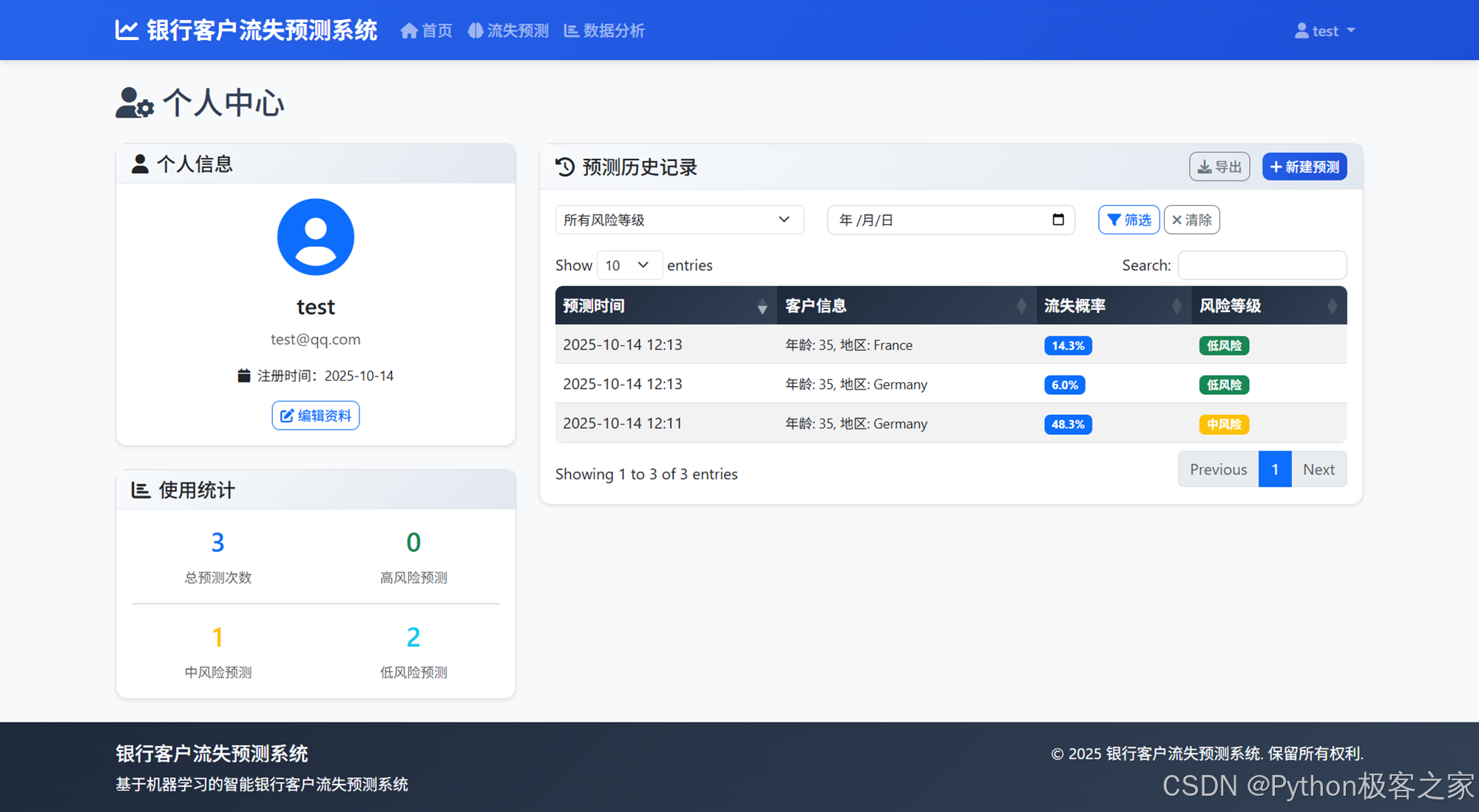
4.3 多维度数据分析
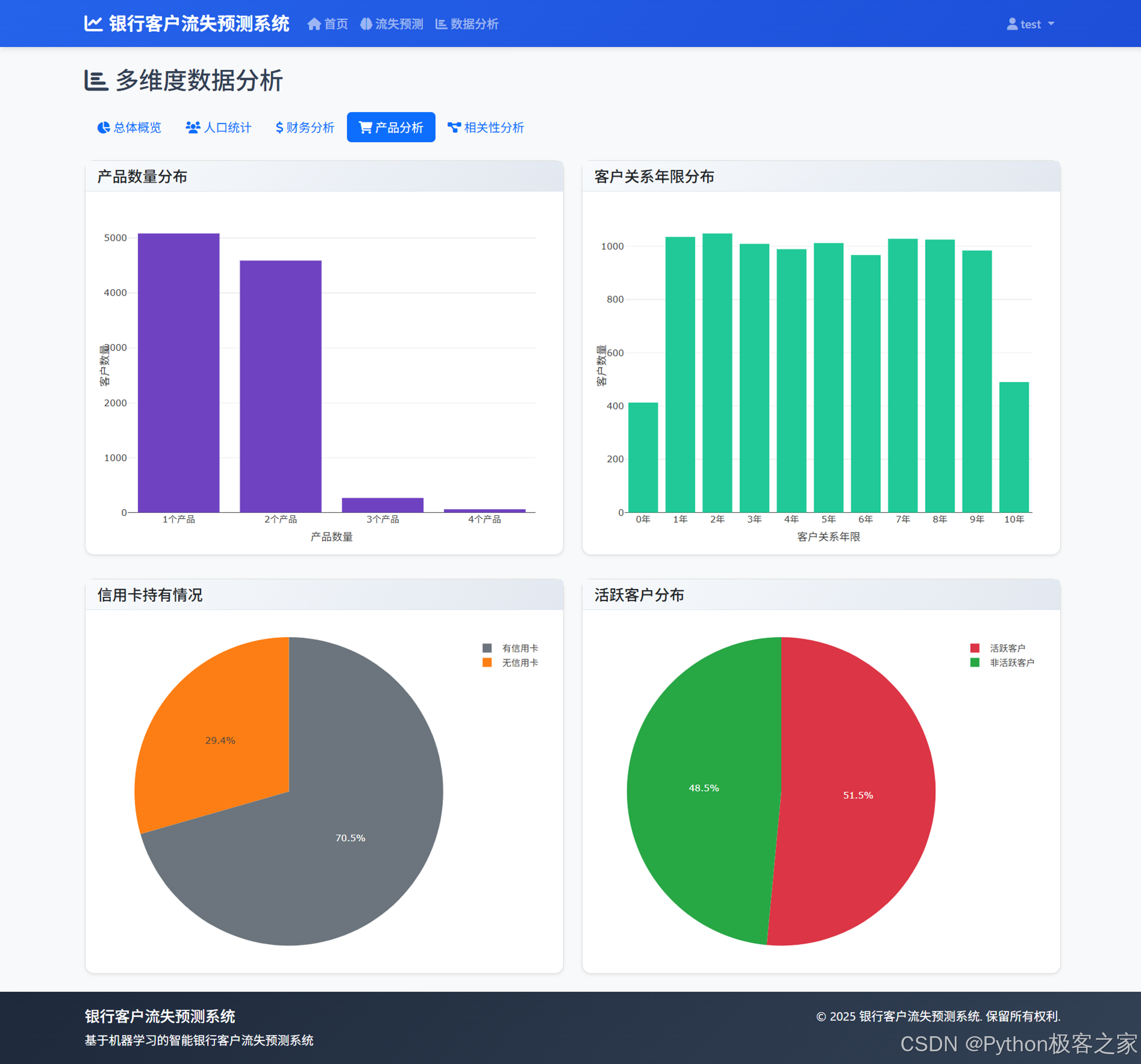
4.3.1 客户流失分布、性别分布、关键指标趋势
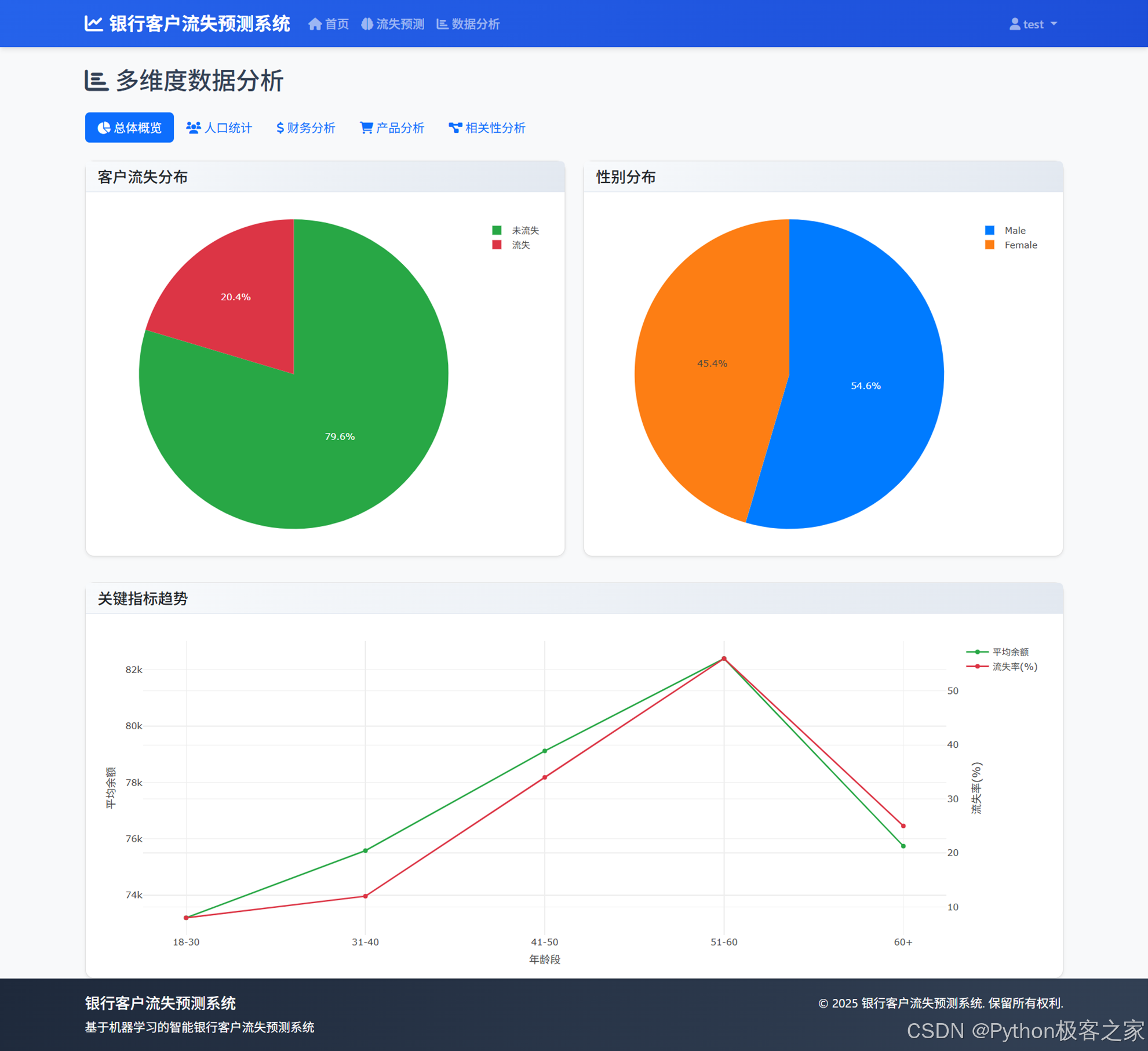
4.3.2 年龄分布与流失率、地区分布、性别与地区交叉分析
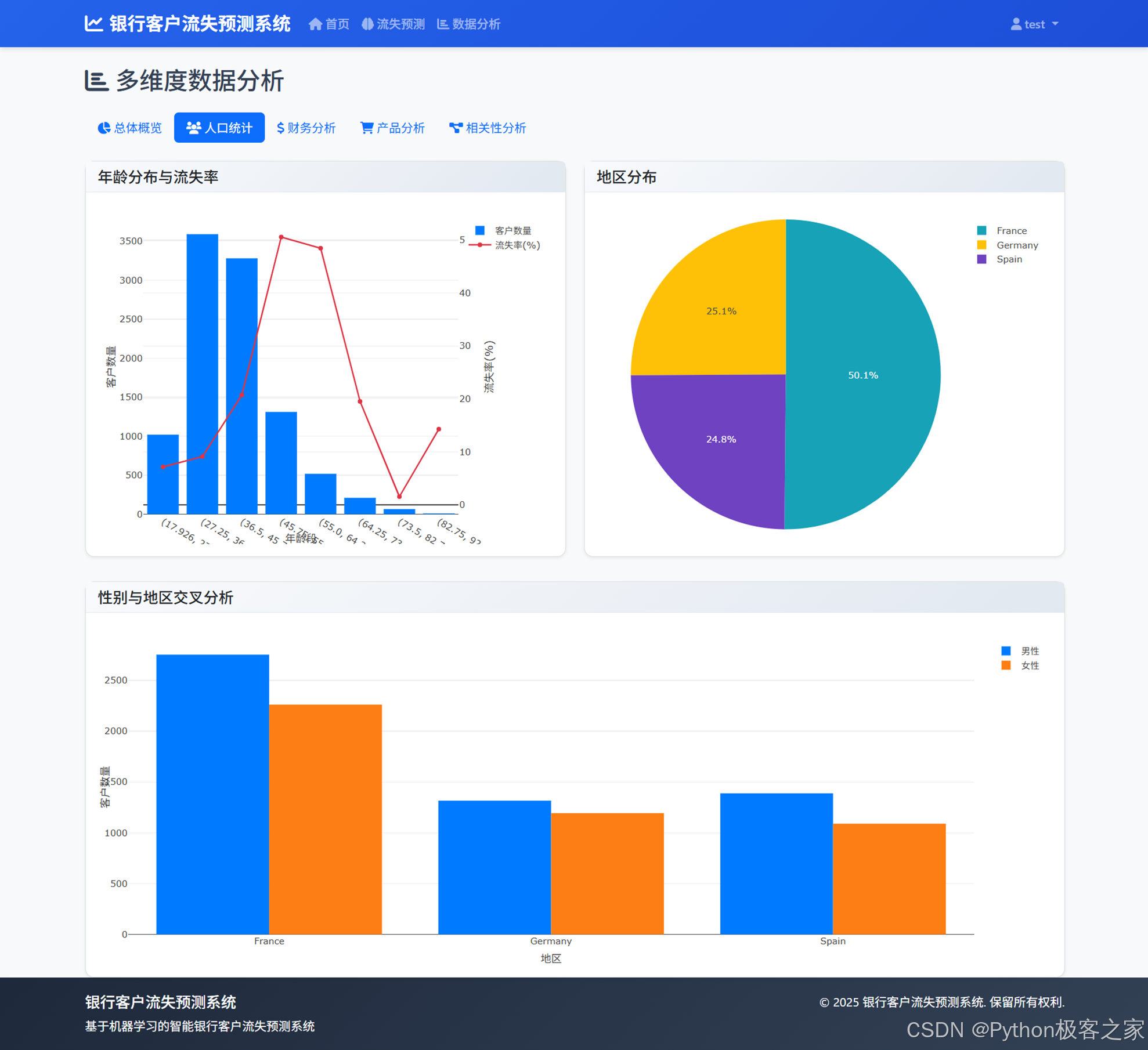
4.3.3 账户余额分布、薪资分布、信用评分与流失关系、余额与薪资散点图
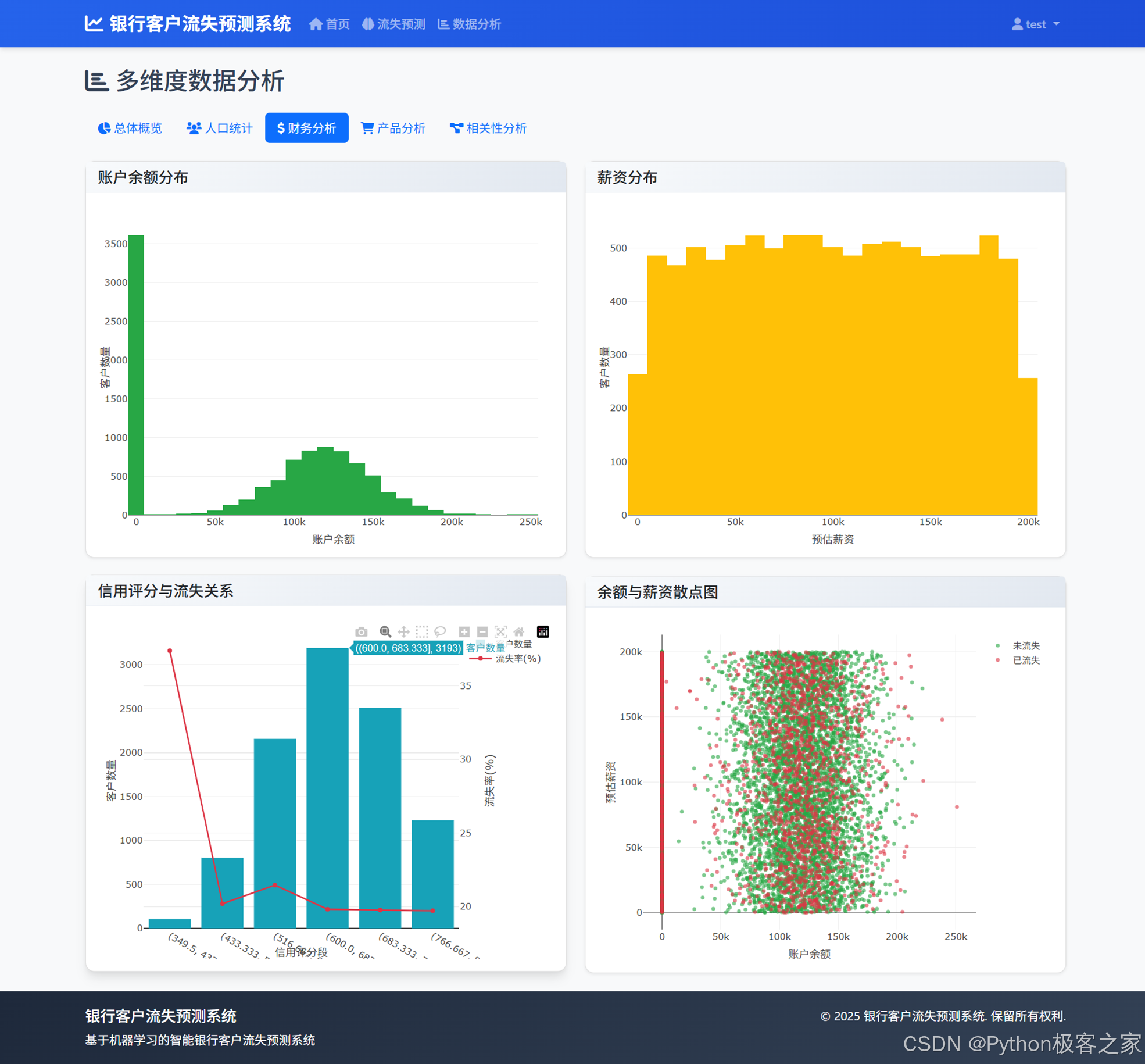
4.3.4 产品数量分布、客户关系年限分布、信用卡持有情况、活跃客户分布
4.3.5 特征相关性热力图、特征重要性
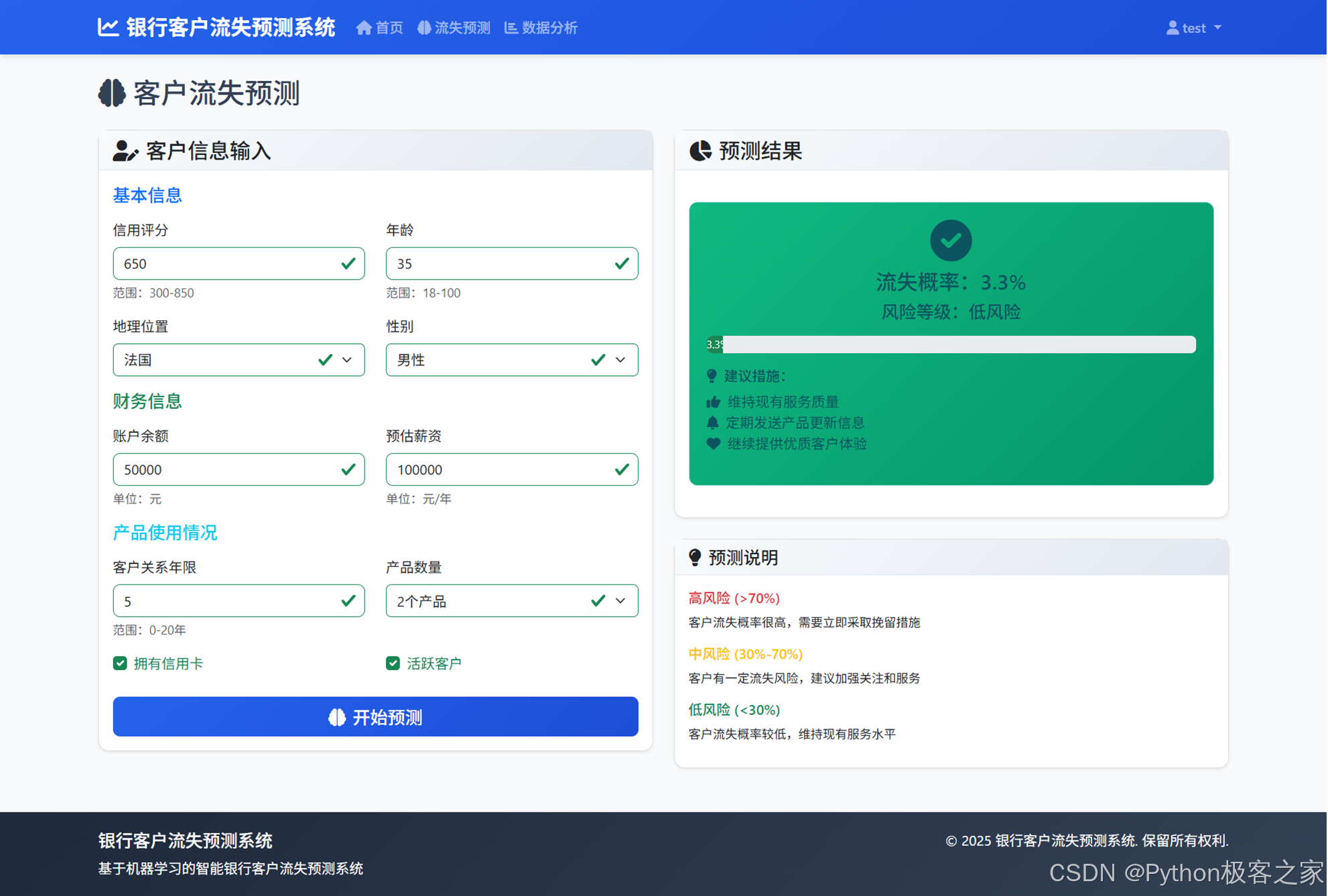
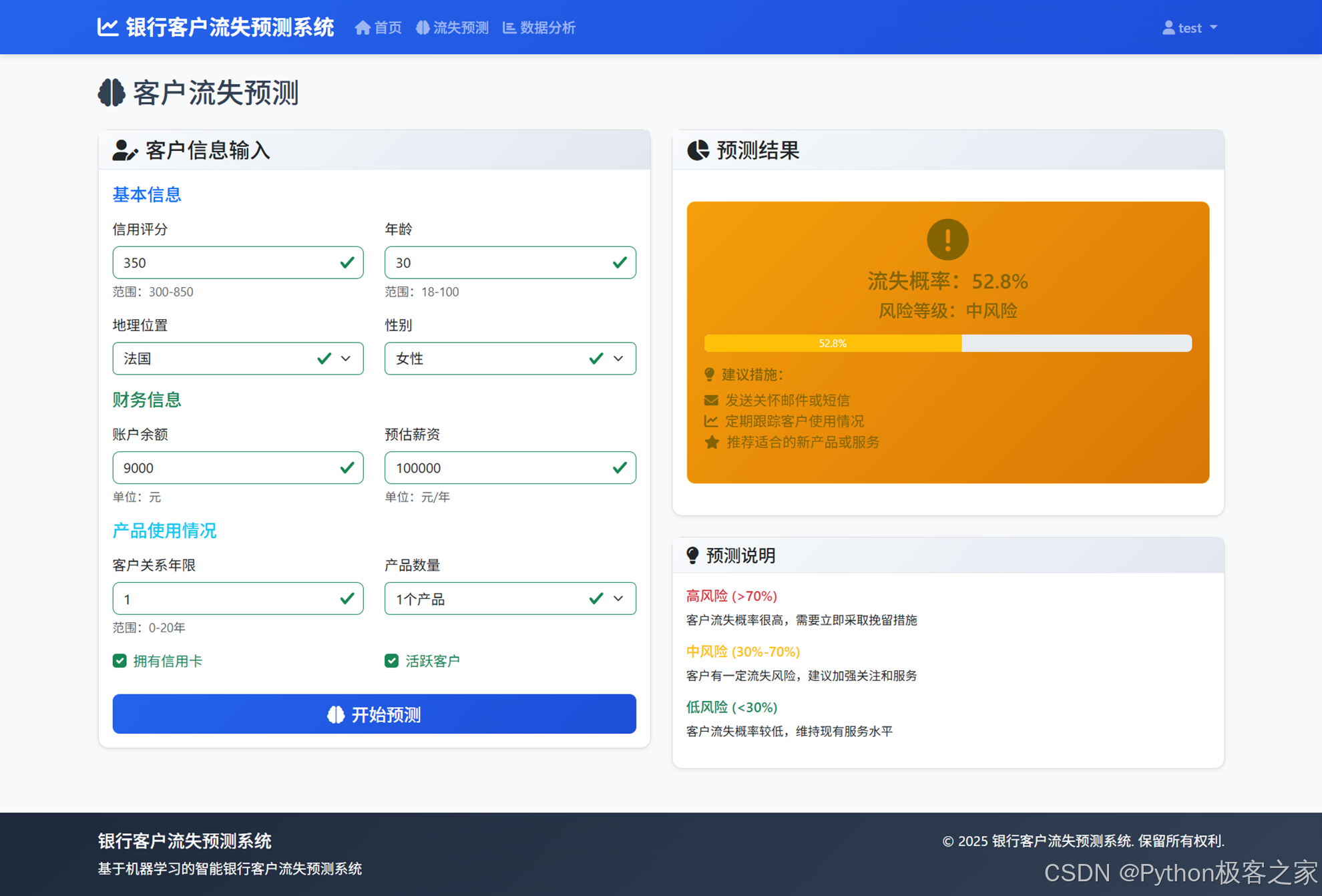
4.4 银行客户流失预测
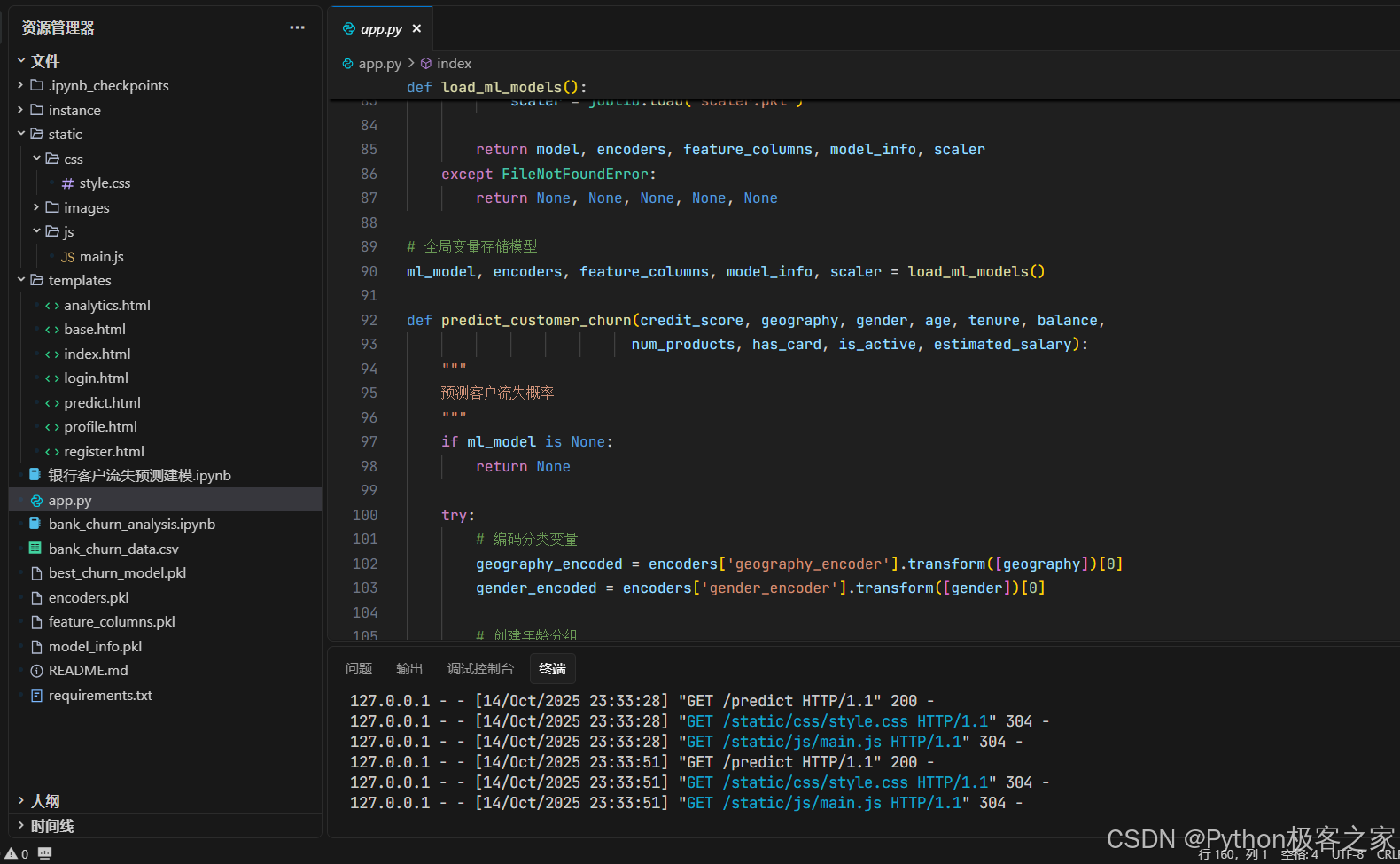
5. 代码框架
6. 总结
本项目基于机器学习构建银行客户流失预测系统,通过分析客户数据识别高风险流失客户。系统采用Flask后端、Bootstrap前端,结合SQLite数据库存储数据。关键技术包括数据预处理(缺失值检测、特征编码)、多种机器学习模型(随机森林、XGBoost等)训练与评估,以及可视化分析(客户分布、特征相关性等)。系统功能涵盖用户管理、多维数据分析及流失预测,帮助银行制定精准挽留策略,提升客户留存率。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 优快云 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:





















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











