






面试官:如何决定使用 HashMap 还是 TreeMap?
一、核心区别:一张图看清本质
在做出选择前,我们必须理解它们的根本差异:
| 特性 | HashMap | TreeMap |
|---|---|---|
| 数据结构 | 数组 + 链表/红黑树(JDK8+) | 红黑树(一种自平衡的二叉搜索树) |
| 排序性 | 无序,不保证元素的顺序(但遍历顺序在一次执行中一致) | 有序,根据键的自然顺序或Comparator进行排序 |
| 时间复杂度 | 平均 O(1) 的 get() 和 put() | 平均 O(log n) 的 get() 和 put() |
| 键(Key)要求 | 要求键正确实现 hashCode() 和 equals() | 要求键实现 Comparable 接口,或在构造时传入Comparator |
| 是否允许null键 | 允许一个null键 | 不允许(除非提供了支持null的比较器) |
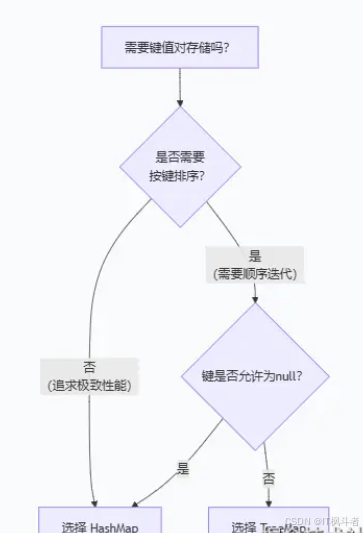
二、决策流程图:三步做出最佳选择
面对具体场景,你可以遵循以下决策路径:
三、场景化深入分析:为什么这么选?
1. 何时毫不犹豫选择 HashMap?
这是绝大多数场景下的默认选择。当你需要最快的访问速度,且不关心元素的顺序时,HashMap是你的不二之臣。
- 场景示例:
- 缓存(Cache):例如存储用户ID到用户信息的映射。我们通过ID快速查找,完全不需要数据排序。
- 快速去重:利用HashMap键的唯一性,将一个列表放入HashMap的键中即可去重,效率极高。
- 会话管理:Web服务器中,用SessionID作为键来查找对应的用户会话对象。
- 代码佐证:
// 缓存用户信息 Map<Long, User> userCache = new HashMap<>(); User user = userCache.get(userId); // O(1)时间复杂度,速度极快
2. 何时必须选择 TreeMap?
当你需要一个始终处于有序状态的映射时,TreeMap是唯一的内置选择。
- 场景示例:
- 需要按范围查找:例如,查找成绩在80分到90分之间的所有学生。
- 需要顺序迭代:例如,需要一个按股票代码排序的股票价格列表,并需要频繁地按顺序遍历。
- 需要获取相邻键:例如,在字典应用中,查找一个词的下一个或上一个词。
- 代码佐证:
// 记录股票价格,并需要按代码排序
Map<String, Double> stockPrices = new TreeMap<>();
stockPrices.put("AAPL", 150.0);
stockPrices.put("GOOGL", 2750.0);
stockPrices.put("MSFT", 305.0);
// 遍历时,顺序是 "AAPL" -> "GOOGL" -> "MSFT"(字母顺序)
for (String symbol : stockPrices.keySet()) {
System.out.println(symbol + ": " + stockPrices.get(symbol));
}
// 范围查找:获取代码在 "A" 到 "G" 之间的所有股票(不包括G)
Map<String, Double> subMap = ((TreeMap<String, Double>) stockPrices).subMap("A", "G");
System.out.println(subMap); // 输出: {AAPL=150.0}
四、高级考量与面试加分项
仅仅知道区别还不够,在面试中展现更深层次的思考能让你脱颖而出。
- 内存开销
HashMap需要维护一个数组,可能存在一定的空间浪费(负载因子控制)。TreeMap需要为每个节点维护额外的左右指针和颜色标记,单个节点开销更大。- 结论:通常对于同样数量的数据,
TreeMap的内存占用会稍高于HashMap。
- 性能瓶颈与哈希碰撞
- 在
HashMap中,如果hashCode()实现得很差,导致大量哈希碰撞,会退化成链表(O(n))或虽然转为红黑树但性能依然下降。这是一个重要的调优点。 TreeMap的 O(log n) 性能非常稳定,不会出现性能骤降的情况。
- 在
- “用HashMap也可以手动排序,为什么用TreeMap?”
这是面试官可能的一个追问。答案是:效率与优雅。
如果你总是需要排序后再使用,每次修改后手动调用Collections.sort()的成本是 O(n log n)。而TreeMap在每次插入/删除时维持有序的成本是 O(log n),对于频繁更新的数据集,TreeMap的持续有序在总成本上要低得多,而且代码更清晰。



















 3888
3888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











