







 本文详述了对某电商平台销售数据的分析过程,包括数据概览、数据处理(如重复值、缺失值和异常值处理)以及数据分析(如双轴图、饼图、柱状图和RFM模型)。在数据处理阶段,通过处理重复值、计算时间差、填充缺失值和丢弃不重要列来改善数据质量。在数据分析部分,利用多种图表揭示销售额、用户增长和用户行为等信息。
本文详述了对某电商平台销售数据的分析过程,包括数据概览、数据处理(如重复值、缺失值和异常值处理)以及数据分析(如双轴图、饼图、柱状图和RFM模型)。在数据处理阶段,通过处理重复值、计算时间差、填充缺失值和丢弃不重要列来改善数据质量。在数据分析部分,利用多种图表揭示销售额、用户增长和用户行为等信息。
如题,本次案例分析某电商平台的销售数据。本次案例的特点是,数据量比较大,原始数据存在比较多的问题,所以数据处理的过程比较典型。
还是按照原先的数据分析流程,概览数据-->数据处理-->数据分析
概览数据
概览数据重点关注,数据的标识问题,了解数据字段,大概观察下数据的问题。
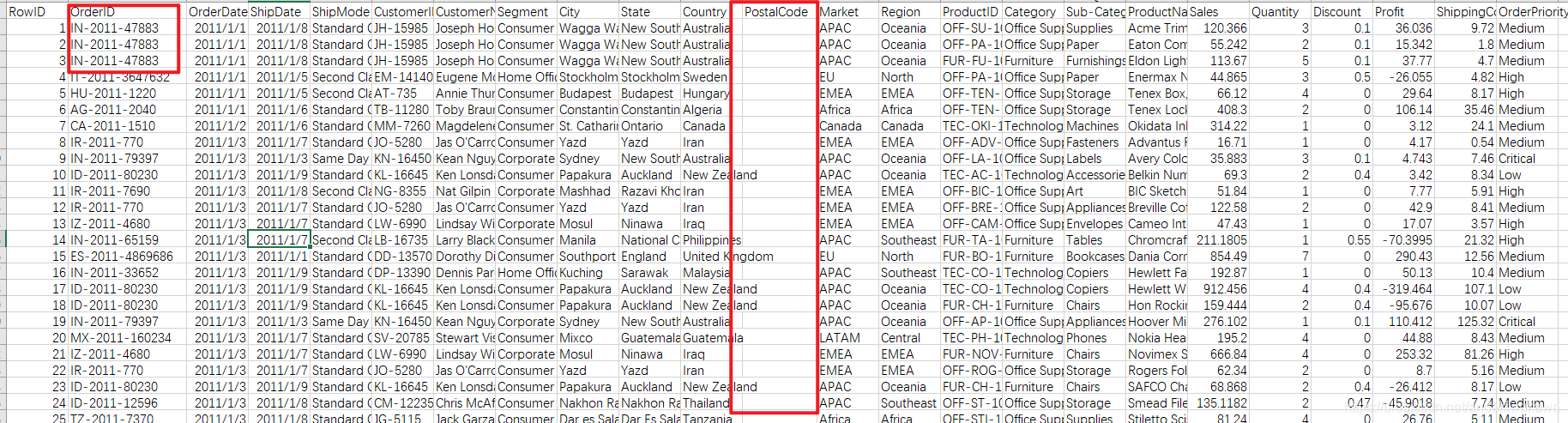
1.数据的标识有订单标识和row_id, 订单标识有重复的问题,业务原因是一个订单买了三件商品,数据就给展开了。其中row_id是数据的唯一标识。
2.数据字段主要描述国际贸易的电商交易,其字段含义。。。
3.postalcode存在大量空值,需要处理
数据处理
脏数据的理解和处理
我们知道数据按照数据来源不同可以分为,一方数据,二方数据,三方数据。通常情况下,一方数据和二方数据脏数据会相对偏少,使用起来也比较方便。
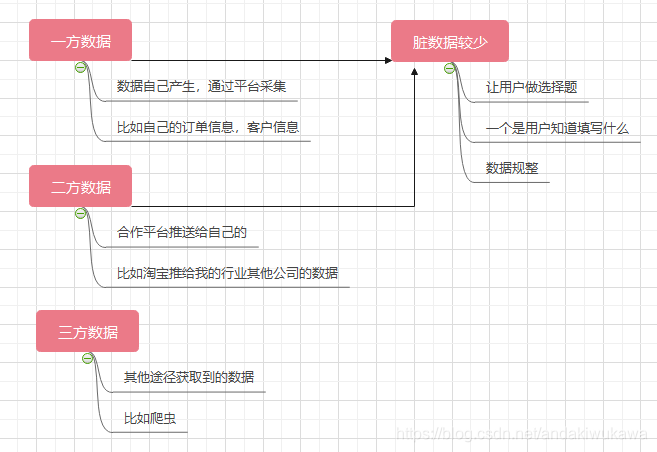
我们之前提到过脏数据可以分为三类,异常值,缺失值,重复值。分类不同处理方式不同。
| 脏数据类型 | 优先处理方式 | 次级处理方式 |
| 异常值 | 修正 | 删除 |
| 缺失值 | 补充 | 删除 |
| 重复值 | 删除 |
下面这个图也可以更清晰的理解:总之就是重要的数据不要自己补,会影响数据真实性,不重要的数据缺失就缺吧。

数据处理流程
数据处理流程可以细分为:读取数据-->提取业务数据-->数据清洗-->数据规整,其中提取业务数据和数据清洗是结合着一起做的。以下是实例。
读取数据51101 rows × 24 columns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv('dataset.csv',encoding='ISO-8859-1')
data
data.shape整个数据清洗的流程一般情况下是
先处理 重复值(标识),同步处理异常值,空值,处理完成后再次处理重复值
这么做的原因是,在处理异常值和空值的时候可能会涉及到用整列数据计算填补,重复值的存在导致无法填补。
处理类型:重复值处理,标识数据
处理重复值--->找出唯一标识--->去重
data.shape
data.RowID.unique().size
data[data.RowID.duplicated()]
data.drop(index=data[data.RowID.duplicated()].index,inplace=True)
data.info处理类型:计算时间数据,计算判断脏数据,Series类型转换
根据业务判断我们需要通过 发货时间shipdata 减去 下单时间orderdata 提取 物流时间interval。且这两个数据存在脏数据,有的发货时间比订单时间还要早。
先将两列数据都转换成日期格式
两者相减计算成秒数,提取脏数据
处理脏数据
将相减结果作为新的数据项
data['ShipDate']=pd.to_datetime(data['ShipDate'])
data['OrderDate']=pd.to_datetime(data['OrderDate'])
data['interval']=(data['ShipDate']-data['OrderDate']).dt.total_seconds()
data[data['interval']<0]
data.drop(index=data[data['interval']<0].index,inplace=True)
data
data['interval']=(data['ShipDate']-data['Orde 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









