



 本文介绍了如何使用Python的xml.etree.ElementTree库处理XML,包括元素的基本概念、如何锁定和查找元素,以及文件的读取、树结构遍历和属性操作。
本文介绍了如何使用Python的xml.etree.ElementTree库处理XML,包括元素的基本概念、如何锁定和查找元素,以及文件的读取、树结构遍历和属性操作。
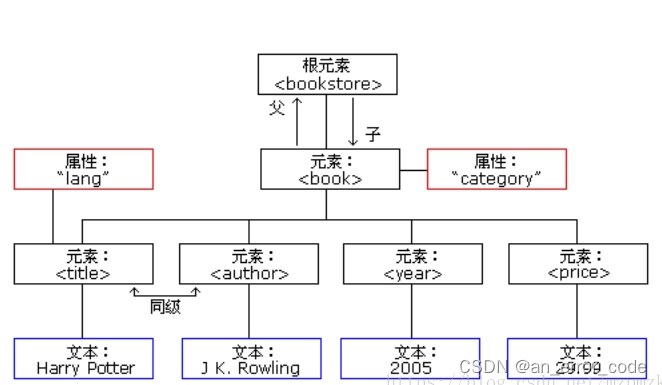
要点1:Xml简单结构下,数据类型是元素element:元素对应标签、属性、文本等(如图)。
要点2:通过引入python中的 xml.etree.ElementTree,可锁定、查找、操作元素element。
要点3:Xml文件为树结构,可通过索引嵌套遍历,也可通过迭代器遍历。
import xml.etree.ElementTree as ET
from tkinter import filedialog
file_path = filedialog.askopenfilename() # 自行选取路径,这里是方便使用,也可在下方直接输入路径
"""
ET 有两个类 -- ElementTree 将整个XML文档表示为一个树, Element 表示该树中的单个节点。
与整个文档的交互(读写文件)通常在 ElementTree 级别完成。
与单个 XML 元素及其子元素的交互是在 Element 级别完成的。
"""
# 读取文件作为以行为单位的字符串列表
# open_file = open(file_path) # file_xml为.xml格式文件
# read_file = open_file.readlines() # 读入所有行数据
# print(type(read_file))
# 读取文件,获取树对象
tree = ET.parse(file_path)
root = tree.getroot()
# print(root.tag) # root对应的标签名
# print(root.attrib) # root的属性
# print(root[0][0].tag) # root第一个子树的第一个子树的tag
# print(root.get('name'))# 获取root的属性name的值
# print(list(root.iter())) # 获取所有tag的list
# 遍历root下的子节点
# for child in root:
# print(child.tag, child.attrib)
# 遍历root第一个子树的第一个字数下的子节点
# for child in root[0][0]:
# print(child.tag, child.attrib)
# 迭代(递归遍历)root下所有的标签对象
for Tag_X in root.iter():
# 打印对象及相关信息
print("对象:", Tag_X)
print("对象标签:", Tag_X.tag, "对象属性:", Tag_X.attrib, "对象属性值:", Tag_X.get('XXX'))
# 筛选对象
if Tag_X.tag == "XXX":
print(Tag_X.tag, Tag_X.attrib, Tag_X.get(''))
参考网址:xml.etree.ElementTree --- ElementTree XML API — Python 3.11.5 文档


















 2万+
2万+



 到【灌水乐园】发言
到【灌水乐园】发言







