






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

作者:庞子奇
https://zhuanlan.zhihu.com/p/31163075390
语言领域的自回归(AR)模型看似一统江湖,但是视觉领域还没有范式让大家的“Scaling Law”可以跨越更多任务、更多应用。前几天Gemini和GPT发布的图像编辑功能验证了视觉自回归的潜力,但是它距离语言领域的“GPT时刻 ”到底还有多远?
我相信,我们CVPR 2025刚刚中稿的文章RandAR展示了视觉“GPT时刻”的一个新探索——自回归AR模型需要能“看”、“理解”、“生成”任意位置和顺序的图像Token才可以实现GPT在语言领域一样的泛化性,而这也是创造更强的视觉模型的基础。在此也特别感谢这篇论文的合作者张天远 和满运泽。
RandAR: Decoder-only Autoregressive Visual Generation in Random Orders
主页:https://rand-ar.github.io/
代码:github.com/ziqipang/RandAR
论文:https://arxiv.org/abs/2412.01827
1. 引子
1.1 什么是GPT成功的本质?
从去年开始,我和合作者一直在思考:如何在计算机视觉领域复刻GPT在语言模型中的成功?我相信,这也是现在几乎每一位研究计算机视觉、研究多模态的研究者都在思考的问题。
所以在开始讨论视觉领域的“GPT时刻”之前,我们不妨分析一下语言模型领域的“GPT时刻“本质是什么?
Next-token Prediction,即Auto-Regressive (AR) 范式,提供了把所有文本任务、文本应用统一在一起的Formulation。
结合Decoder-only结构,Next-token Prediction使得大规模训练对Infra友好、可以非常高效。
正因为第一点”统一的Formulation",我们可以收集海量数据,最终得到一个能够Zero-shot泛化的大模型。
所以说,GPT在语言领域的成功 —— 不只是 next-token prediction。
1.2 为什么现在的Vision模型距离“GPT时刻”差在哪里?
在视觉模型中模仿GPT的配方,即 "Decoder-only" + "Next-token Prediction",从去年年中的时候就开始了一些探索,代表作有:LLaMAGen,Chamelon,Transfusion,Show-O,Emu3,当然也有DeepSeek的Janus,他们集中在让Image Tokens (也包括文本Token) 也按照Next-token Prediction的范式进行学习。好的,那它们距离GPT时刻的距离还在哪里?只是单纯的数据、模型还没有增加到足够的Scale,还是他们仍然有本质的缺陷?
我们回顾之前提到的三个GPT时刻的本质:
"Next-token Prediction提供了统一的Formulation": 这些模型没有做到这一点,我们下面会分析为什么。
"Decoder-only + Next-token Prediction对Scaling Up非常友好": 对Scaling Up的支持,这些模型因为遵循了Next-token Prediction + Decode-only,所以都可以做到。
"通过海量数据,zero-shot泛化到多种场景": 从个人的观察来看,这些模型大部分能力还是专注于处理一些in-domain的场景,所以暂时还没完全体现出zero-shot泛化。
那么是什么限制了这些模型复刻GPT范式的成功呢?当我们按照一维的顺序做Next-token Prediction,势必要把二维的Image Tokens转化成一维的序列,而之前的方法在这里采用了一个提前规定好的顺序——Raster-Order,也就是从图片的左上角开始一行一行地生成Image Tokens。
这种做法最大的限制是这样训练出来的模型:
无法按照任意顺序处理Image Tokens,所以很显然,他们面对editing任务或者针对图片特定区域Perception的任务会很挣扎。因此,这样的Next-token Prediction很难成为"把所有任务统一在一起的Formulation"——也就是违背了上面GPT成功的第一个条件。
无法Zero-shot泛化,也正是因为生成顺序的限制,这样的模型很难未经训练直接泛化到新的场景上,比如说新的图片分辨率(resolution)、提取图片的Representation。也就违背了上面的第三个条件。
所以说,如果按照固定顺序去做next-token prediction的模型,某种程度上得了GPT的“形”,但是距离实现GPT在语言领域的成功还有很长的路要走。
1.3 我们的Insight:任意顺序是关键
上述的模型,它们最主要的限制就是“只用一种方式做二维图像到一维序列的映射”——所以解决这些问题的关键在于——如何让GPT模型可以处理任意的二维图像顺序。这也是我们的RandAR的起点:
让一个和GPT相同的Decoder-only Transformer可以按照Random-order生成图像
RandAR可以Zero-shot泛化到新的场景上,包括但不限于一些全新的角度——Parallel Decoding (next set-of-token)、生成更高分辨率图片,而且它还可以直接做Generative Model的另一面——Representation Learning。

所以,我们希望RandAR可以指向一个全新的"视觉领域GPT"的路径。
2. RandAR:如何用任意顺序生成图片
RandAR的方法非常简单:既然我们想要让模型可以生成任意顺序的图像Token,那么我们需要把顺序用某种方式“告诉”模型。我们用一种特殊的Token,叫做"Position Instruction Tokens ",代表下一个需要生成的Image Token在哪个位置,来指导模型生成Image Tokens。
Method部分到此结束,其实非常简单。
(如果你不需要算法细节,可以节省时间,通过目录直接跳过这部分去结尾—我们对视觉AR模型终局的想象)
3. 重头戏:RandAR和它的Zero-shot能力们
说了这么久“GPT时刻”,我们在这个Paper里面把刷点放在非常次要的位置,而是花了大量的时间在——任意顺序(Random-Order)真的可以带来大量的Zero-shot新能力吗?
(如果你日不需要算法细节,可以节省时间,通过左侧目录直接跳过这部分直接去结尾我们对视觉AR模型终局的想象)
3.1 Parallel Decoding —— Next Set-of Tokens Prediction
Autoregressive模型的一个缺陷(相比于Diffusion Models)在于它的速度——对于图像生成,它的延迟(Latency)主要取决于采样的步数。所以我们做的第一件事情就是——我们的模型是否可以Zero-shot泛化做到Parallel Decoding?我们非常看重"zero-shot",因为在LLM里面Parallel Decoding一般都是需要做一些Fine-tuning实现的。我们的实现非常简单——每一步同时生成多个来自随机位置的Token即可。这样的方式可以直接提速2.5倍,而不会带来任何的FID降低。
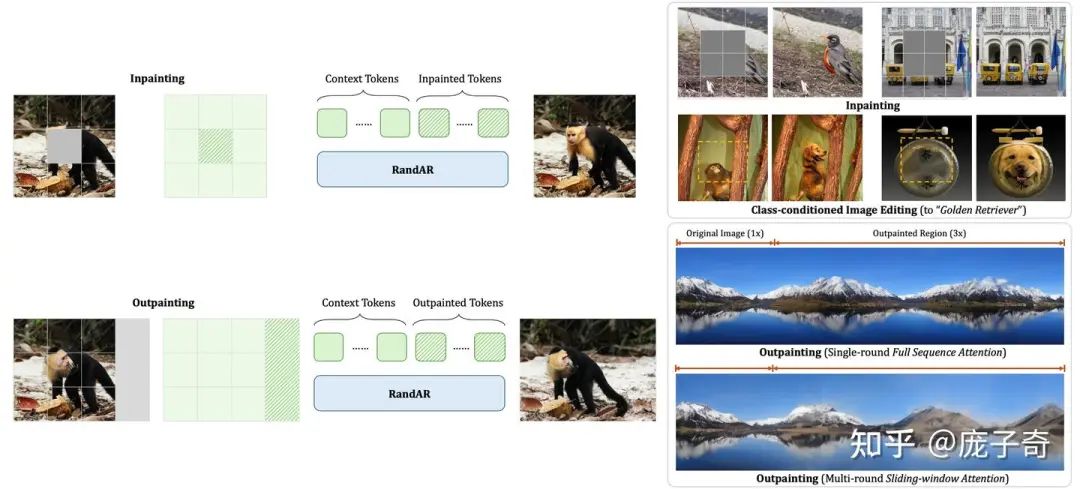
3.2 图像编辑、Inpainting、Outpainting
这两种能力是老生常谈了。因为可以处理任意顺序,我们的RandAR可以解决这两种应用。方法很简单:把所有已知的上下文(Context Tokens)放在一开始,然后让模型去生成新的Tokens。
3.3 Zero-shot放大分辨率
我们花了大力气做了这样一件事情——如果模型是在256x256的图片上训练的,那么它的参数是否可以直接生成更大分辨率,例如512x512的图片?在这里,我们特殊强调要求图片必须展示一个unified object,而不是通过Outpainting可以实现。我们因为可以控制生成顺序,所以提出了两步走的方法:
第一步先找对应低分辨率的Token生成,得到全局结构
第二步再去填充高分辨率的Token,得到高频细节

3.4 统一Encoding (Representation Learning)
最后一个问题,也是个人以为的视觉领域"Autoregressive Generation"的Open Problem:在视觉领域,Representation是泛化到下游任务的基础(比如说CLIP和DINO),那么如何统一理解(Encoding)与生成(Decoding)?这个问题对于语言处理领域可能重要性稍微低一些,但是对于视觉领域根本关系到"GPT"时刻。
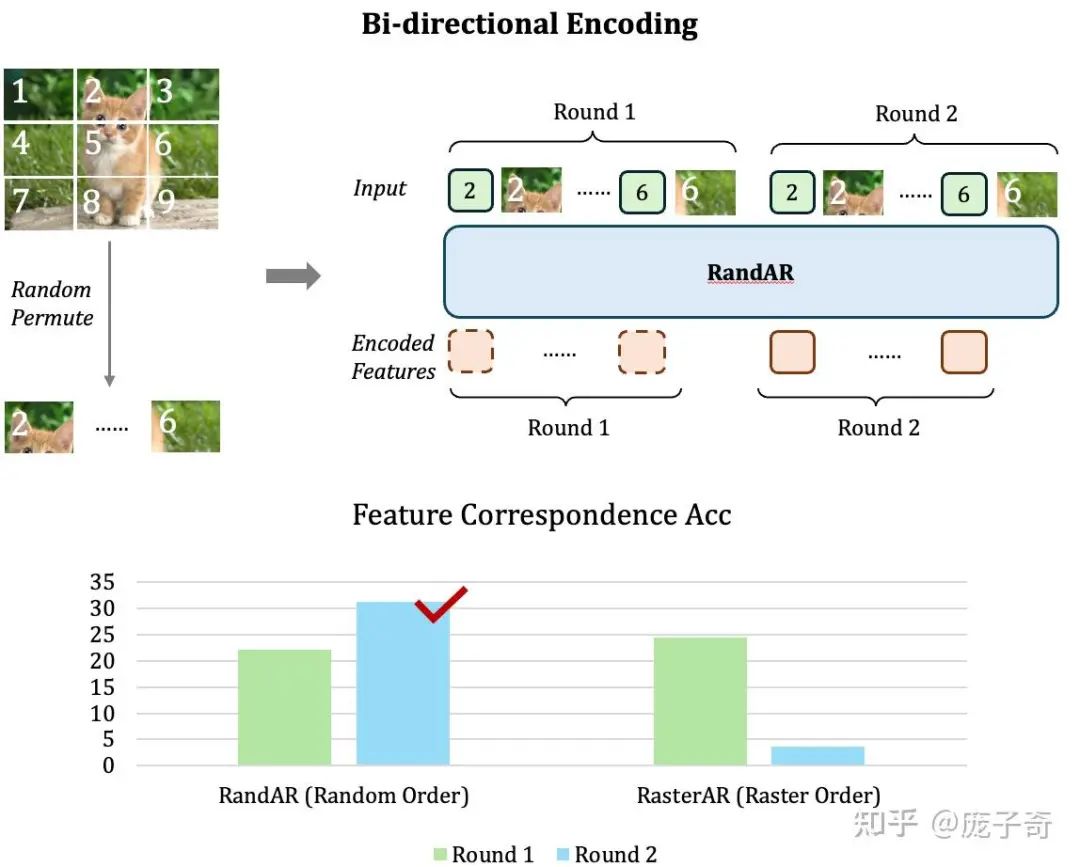
这个问题对于Decoder-only的GPT结构模型会更难一些——因为Decoder-only模型采用的是Causal Attention,也就意味着在序列中靠前的Token没有办法”看见“在后面的Token,那它的Representation就只能代表很少的一部分信息。最极端的例子就是——第一个图片Token只有它自己Patch的信息,根本无法知道图片的其它位置。
一个直接的解决办法就是——把图像Token序列再输入一遍,然后我们只取第二轮序列的Representation (如下图),这样每个图片Token都可以得到完整的图片信息了。从对比中可以看到,
使用了Random-order的模型可以直接泛化到这种提取Representation的方式(柱状图左侧),
但是按照Raster-order训练的模型却会直接崩掉(柱状图右侧)。
看到这个结果的时候我们其实很开心——因为这是第一次我们看到一个Decoder-only的模型用单向(Uni-directional) Attention可以实现Encoder模型用双向(Bi-directional) Attention做到的功能。
3.5 总结
回到文章的最开始——我们希望这里的多种Zero-shot能力证明——处理随机顺序的能力是让自回归模型 能够解锁视觉"GPT时刻"的重要部分。
4. 一些分析和反思
(如果你不需要算法细节,可以节省时间,直接跳过这部分去结尾—我们对视觉AR模型终局的想象)
4.1 模型是怎么记住N!个顺序的

4.2 生成时候的顺序
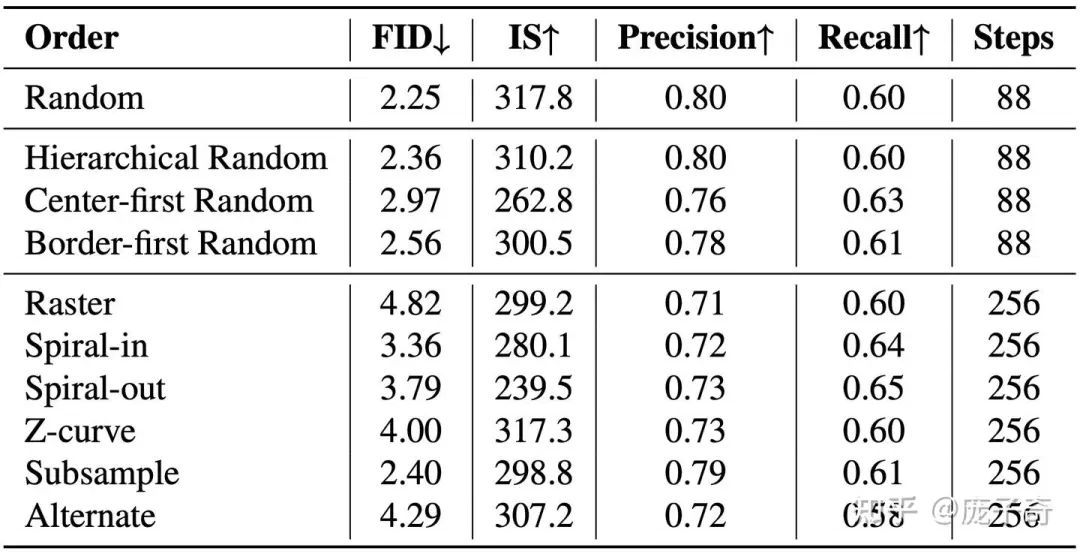
RandAR可以按照任意的顺序生成图片,但是会不会有哪种顺序更好呢?我们试验了一些人类直观上比较合理的顺序,可以看到还是随机的顺序生成图片的FID是最好的。这里我们的猜测是:(1) 随机的顺序可以更好地结合来自图片不同位置的上下文,比如说从下表中我们可以发现,那些让图像在生成早起Token更分散的顺序可以得到更好的效果;(2) 随机的顺序增强了图像生成的多样性。
4.3 遗憾
在研究RandAR的过程中,我们一直尝试找到一个最优的顺序,或者像Mask AR一样,通过一些信息熵之类的指标找到最优的采样顺序,可惜一直没有成功。
另外受制于计算资源,我们没有办法把RandAR推广到Text-to-image或者视频生成领域。我们希望这种让模型更好理解时空位置的训练方式可以在更大的数据上爆发Scaling Law。
最后,我们还有诸多Zero-shot能力没有精力完全尝试或者实验成功,也许因为RandAR模型主要是在ImageNet上训练的,例如RandAR是否可以直接生成可控位置的多物体图片。
期待会有朋友继续探索,实现这些遗憾!
5. 广结善缘:社区里的其他相关研究
(如果你不需要算法细节,可以节省时间,直接跳过这部分到结尾—我们对视觉AR模型终局的想象)
5.1 基于Encoder-Decoder的Mask AR
对我们的RandAR启发最大的工作是去年年中Kaiming He和Tianhong Li实现的MAR,最主要的区别是MAR研究的是Encoder-Decoder结构,而我们主要关心Decoder-only,也就是和GPT相同结构的模型。另外一个核心的Insight,即为什么我们会对Decoder-only的方式有信心,在于Encoder-Decoder的Masked AR在训练的过程中需要手工规定一些Masking Ratio,这些”Human Priors“某种程度上也许会让模型的Scalability被限制。
5.2 其它方式的AR生成
另外一些相关的AR为了解决从2D图像序列到1D Token序列都需要一些额外的设计——例如VAR设计的按照从低到高的分辨率去生成图像Token。但是这些设计从某种程度上也都需要人类的先验知识,而我们则希望RandAR可以尝试一种完全不需要人工先验的结构。
5.3 随机顺序的视觉AR生成
和我们同期的工作是来自字节跳动的RAR,他们证明了通过Random Order的训练模型可以得到更好的生成质量——这其实和我们一样,验证了"任意顺序"对于视觉模型的重要性。RAR在生成质量上达到了SOTA,我们和它的不同在于:RAR在做生成的时候仍然要回到单一的Raster-Order,而我们更注重在生成的时候可以按照任意顺序并支持大量的Zero-shot Capability。
5.3 视觉AR中的Parallel Decoding
关于生成顺序对于Parallel Decoding的重要性,和我们非常相关的是两个同期工作:(1) PAR研究了如何指定生成的顺序可以支持Parallel Decoding;(2) SAR 研究了如何小幅度修改Decoder-only结构可以让自回归模型能够实现Parallel Decoding。
5.4 RandAR的后续工作
最后,我们也很高兴看到我们的文章已经启发了一些后续工作。ARPG很好地解决了RandAR里面需要额外Position Instruction Token带来的问题并且拓展了更多的应用,例如ControlNet。
6. 对Gemini和GPT4o图片编辑的一些猜测 & AR的未来
6.1 Gemini和GPT4o图片编辑
最近Gemini和GPT4o都公开了自己的in-context图像编辑的功能 (比如下面的例子)。它们的设计大概率沿用了多模态AR的思想,就是让语言模型可以合成一些图像Token、或者Diffusion模型的一些Conditional Input。
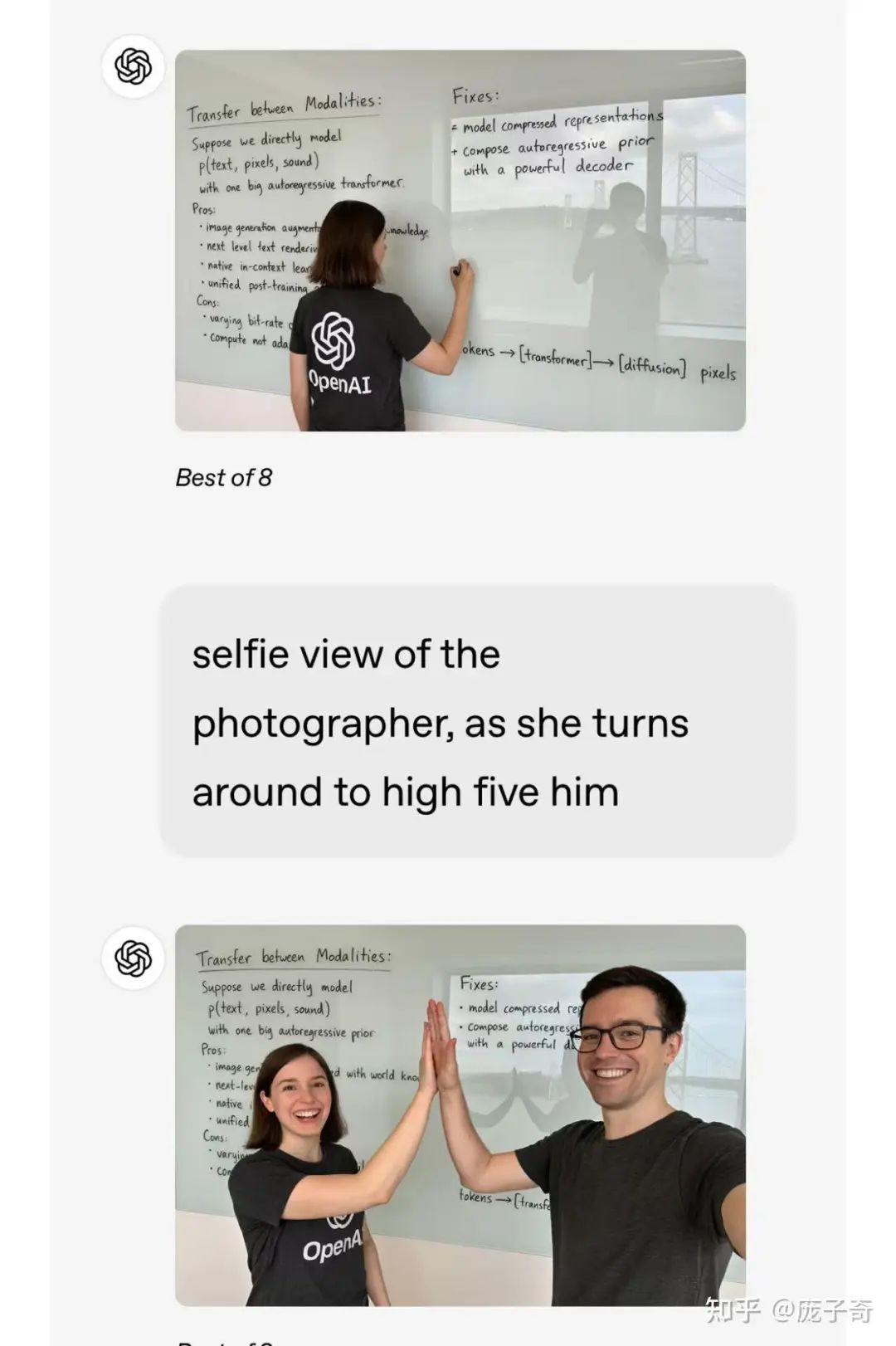
事实上,实现这样的图像编辑,也许并不一定需要直接应用上面讲述的"随机顺序"能力,我们可以想象一种最"浪费"的实现方式:哪怕我们只需要修改图片的一个小部分,我们还是让模型去训练按照Raster-Order或者Multi-resolution的方式重新生成每一个Patch。
这种“浪费Token”的方式除了对效率的不友好,另外一个限制其实在于Token学习效率的降低——如果绝大多数Token都在学习如何重复之前图片的内容,模型在真正需要Reasoning的Token上获得的信号实际上就被降低了。
那么这就引向了我们对于视觉AR终局的想象:
6.2 视觉自回归模型(AR)的终局
视觉AR的终局,必然要让模型可以
- 统一"生成"
(图像编辑、图像生成...)与"判别"(多模态QA、图像分割、深度估计...)
- 处理“任意”位置、“任意”顺序、“任意”指令
而我个人认为,视觉AR的最终范式,在于它要有"Action" (动作) 的能力,因为视觉最终服务的是和物理世界进行交互。我希望可以借助一句"百年孤独"里的话说明"Action"的意义:
世界新生伊始,许多事物还没有名字,提到的时候尚需用手指指点点。
因此,一个真正全能的视觉AR模型,需要设计一套通用的Action,让生成 (Generation)、理解 (Perception)、推理 (Reasoning)可以在同一个Token序列中被采样。事实上,当我今天看到很多Vision-Language Model的论文增加了一些Special Token,例如图像分割的<SEG>,我都会把它看成是迈向"通用Action"的中间一步。而我们研究的随机顺序,特别是Position Instruction Tokens,实际上就给予了模型“指指点点”的能力。对于一些其它的模型,比如说推理模型中的<think>、感知细节模型的Visual Chain-of-thought,本质上都是为AR模型加上了一些“动作”(Action) Token。
我自己的愿景是未来会有一个统一的Transformer,它的参数可以直接应用到多种模态、多种任务,也就是实现一个终极的自回归AR模型。我之前的探索也验证了这条路线的潜力(ICLR 2024,用LLM的参数处理视觉任务)。
我期待着下一代的视觉模型不再是用眼睛"看书",而是也可以用手"揉面"——它有一双"手",可以随心所欲地把面压缩、放大、改变形状,变成我们真正想要的面包和点心。
最后期待在今年的CVPR见到各位朋友!欢迎邮件、微信、私信交流!
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群 CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人! ▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









