




 gMLP是一种新的网络架构,由谷歌大脑提出,它仅基于带门控的MLP,无需自注意力,却在视觉和语言任务上展现出与Transformer相当的性能。研究发现,gMLP在某些情况下甚至超越了ResMLP、MLP-Mixer等,且在视觉Transformer任务中精度可比肩DeiT。此外,gMLP在大规模模型中也能有效扩展,表现出与Transformer相似的缩放能力。
gMLP是一种新的网络架构,由谷歌大脑提出,它仅基于带门控的MLP,无需自注意力,却在视觉和语言任务上展现出与Transformer相当的性能。研究发现,gMLP在某些情况下甚至超越了ResMLP、MLP-Mixer等,且在视觉Transformer任务中精度可比肩DeiT。此外,gMLP在大规模模型中也能有效扩展,表现出与Transformer相似的缩放能力。
研究表明:自注意力对于视觉Transformer并不重要,因为gMLP可以达到相同的精度,性能优于ResMLP、MLP-Mixer等网络,可比肩DeiT等,在视觉和语言任务中通吃!可媲美Transformer!
注1:文末附【视觉Transformer】交流群
注2:整理不易,欢迎点赞,支持分享!
想看更多CVPR 2021论文和开源项目可以点击:
gMLP
Pay Attention to MLPs

- 作者单位:谷歌大脑(Quoc V. Le)
- 论文下载链接:https://arxiv.org/abs/2105.08050
Transformers已成为深度学习中最重要的架构创新之一,并在过去几年中实现了许多突破。在这里,我们提出了一个简单的,无需注意力的网络体系结构gMLP,该体系结构仅基于带有gating的MLP,并显示了它在语言和视觉应用中的性能可与Transformer媲美。
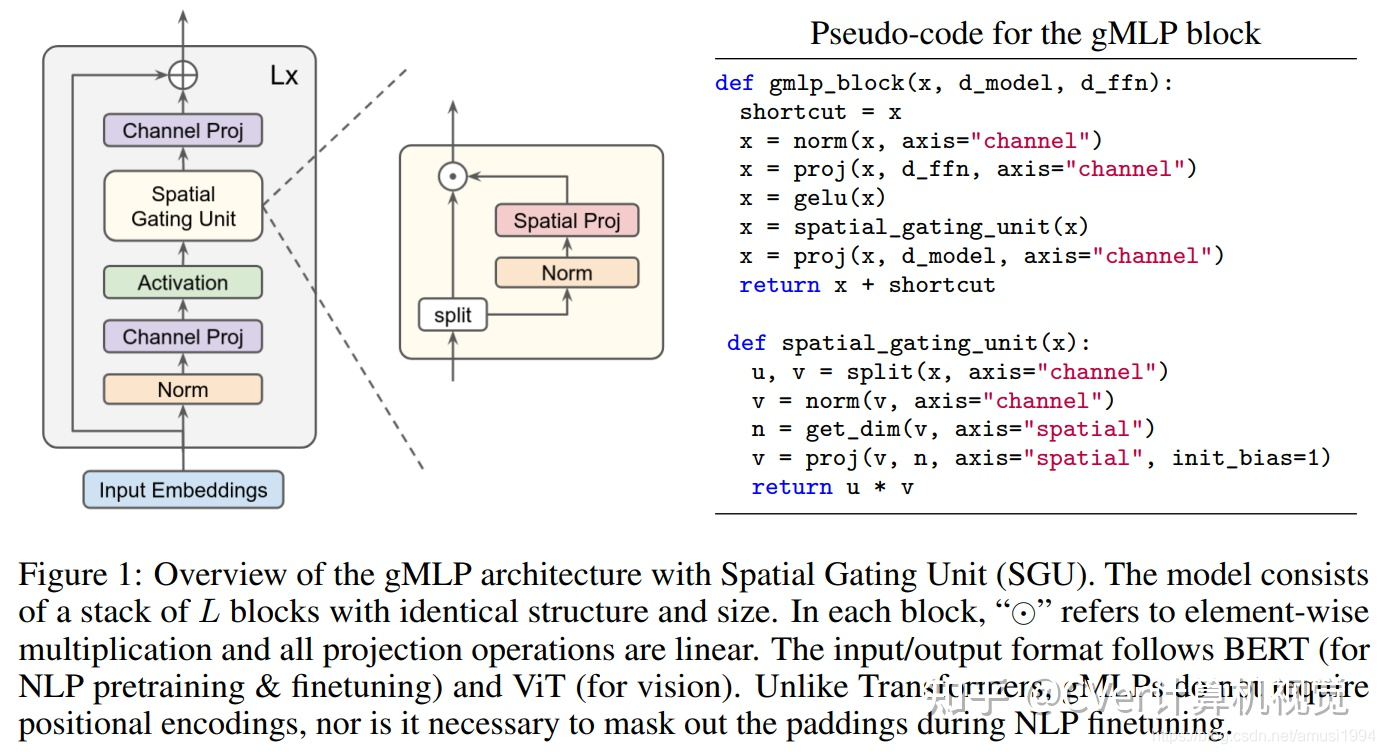
gMLP细节(建议去看原文):

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 330
330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









