




ovs中断驱动
1.数据包到达网卡 → 2. 网卡触发硬件中断通知CPU → 3. CPU 暂停当前任务,执行中断处理程序(ISR)→ 4. ISR 将数据包从网卡缓冲区DMA复制到内核内存(sk_buff) → 5. 唤醒协议栈处理线程(如软中断 softirq)→ 6. 协议栈处理数据包 → 7. 数据传递到上层应用。
ovs-dpdk
DPDK 是一个用户态的数据平面开发工具包,通过绕过 Linux 内核网络栈,直接访问网卡硬件,显著提高数据包处理性能。
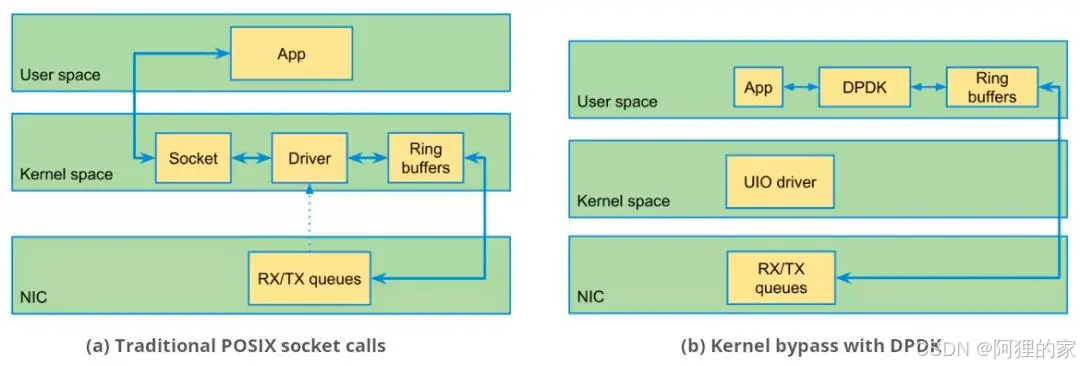
传统的处理是中断驱动的,当数据包到达时,硬件网卡(NIC)会中断内核。引入中断处理、上下文切换和数据拷贝额外开销(CPU)。
- DPDK 绕过内核通过pmd线程在用户态直接访问网卡缓冲区,避免数据拷贝。
- PMD 线程主动轮询队列替代中断驱动,避免中断处理、上下文切换和数据拷贝额外开销。
- 独占 CPU 核可以确保 PMD 线程持续检查队列,及时处理数据包,
- 使用大页内存提高 CPU 缓存命中率,提升内存访问性能。
- 支持多队列,可以将数据包分发到多个CPU核心上并行处理,充分利用多核处理器的能力。
- 硬件加速主机测的网络数据流卸载到硬件网卡提升转发性能并降低主机侧CPU占用率。
pmd进程
pmd 进程主要用于多核环境下,通过轮询模式高效地处理数据包。
ovs-vswitchd里。在添加dpdk端口或者ovs启动(已添加dpdk端口)的时候,会触发创建pmd_thread_main线程。通过pmd_thread_setaffinity_cpu设置线程绑定的lcore,然后通过for循环各个端口,执行dp_netdev_process_rxq_port处理端口的数据包:
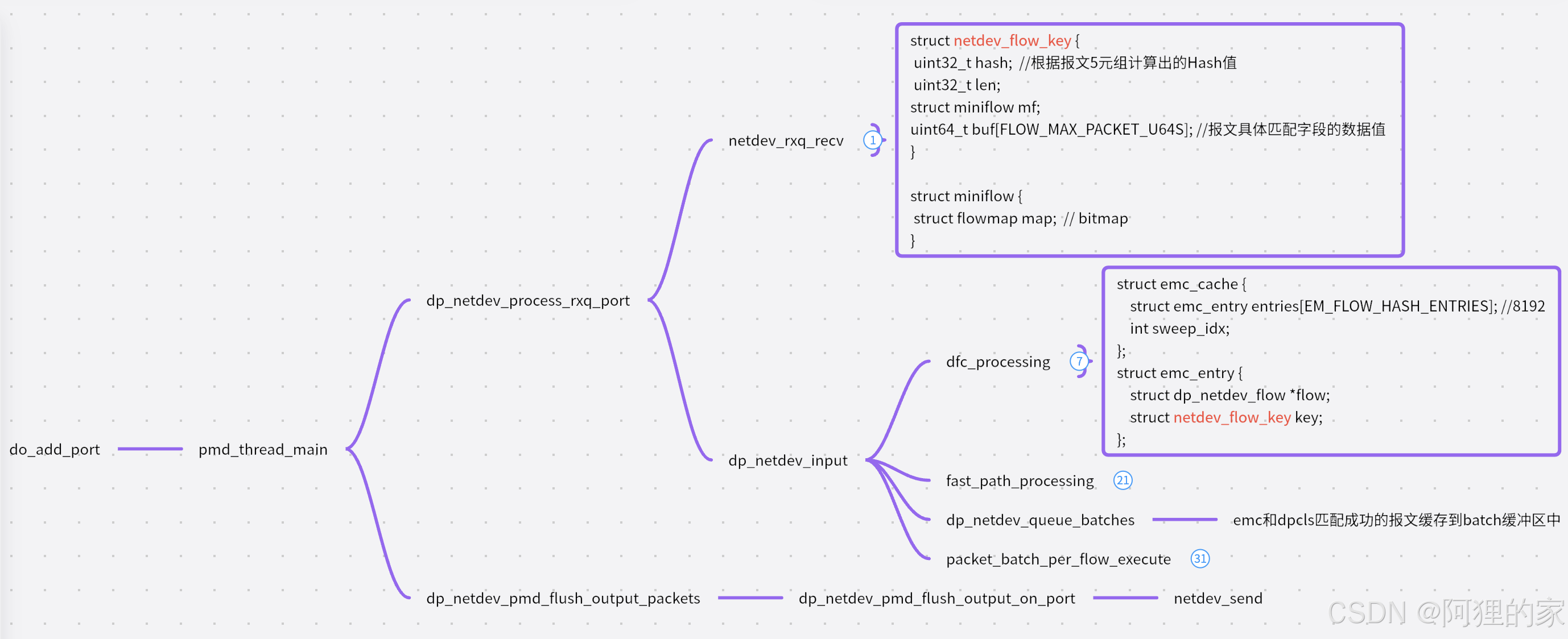
ovs选路fastpath和slowpath
fastpath:通过ovs datapath直接转发的路径称为fast-path。
slowpath:通过ovs-vswitchd查找OpenFlow实现转发的路径称为slow-path。
OVS的设计思路就是通过slow-path和fast-path的配合使用,完成网络数据的高效转发。当一个网络连接的第一个网络数据包(首包)被发出时,OVS内核模块会先收到这个数据包。但是内核还不知道如何处理这个包,因为所有的OpenFlow都存在ovs-vswitchd,默认将这个包上送到ovs-vswitchd。ovs-vswitchd通过OpenFlow的pipeline,处理完数据包送回给OVS内核模块,同时,ovs-vswitchd还会生成一条datapath一起送到OVS内核模块。后续同一个网络连接的数据包可以直接走fastpath。
优点:内核模块不用关心OpenFlow的变化,不用考虑OpenVSwitch的代码更新。
TSS算法
在ovs/ovs-dpdk三级查询时多次用到TSS算法进行流表查找,TSS也就是元组空间搜索算法的核心思想是,把所有规则按照每个字段的前缀长度进行组合,并划分为不同的元组中,然后在这些元组集合中进行哈希查找。
ovs应用:源目ip的子网掩码mask,将相同mask分为一个元组,每个元组对应一个桶,也就是subtable可将多条流表规则划分到n个桶,最多查找n次。
优点:流的添加删除比较频繁,TSS支持高效的、常数时间的表项更新。
优化:OVS给每个元组加了一个命中次数,命中次数越多,元组这个链表越靠前,这样就可以减少了查表次数。
ovs三级匹配
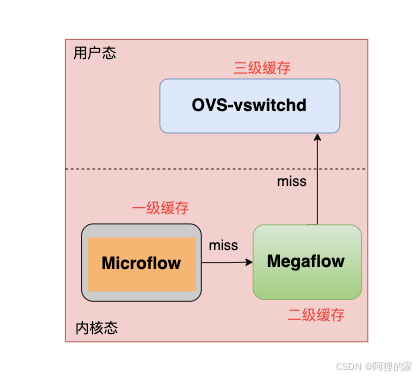
当一个网络连接的第一个网络数据包(首包)被发出时,OVS内核模块会先收到这个数据包。但是内核还不知道如何处理这个包,因为所有的OpenFlow都存在ovs-vswitchd,默认将这个包上送到ovs-vswitchd。ovs-vswitchd通过OpenFlow的pipeline,处理完数据包送回给OVS内核模块,同时,ovs-vswitchd还会生成一条datapath一起送到OVS内核模块。后续同一个网络连接的数据包可以直接走ovs内核。

Microflow精确匹配
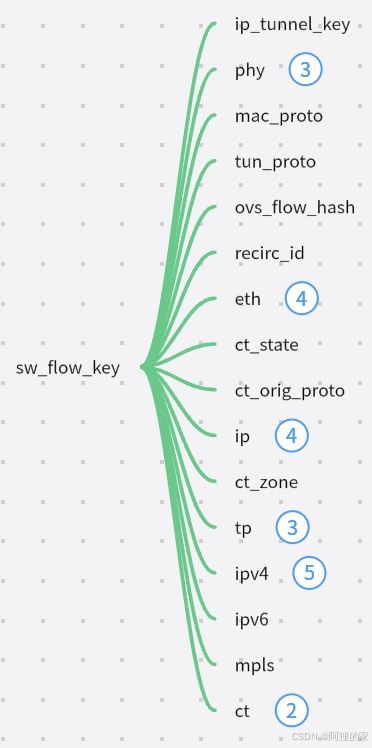
基于报文信息提取到sw_flow_key结构体,基于报文hash得到skb_hash,根据skb_hash在Microflow缓存里查找,Microflow里维护的是每条链接粒度的状态,只需要一个hashtable,因为这里只有一种match,时间复杂度是O(1),Microflow Cache的value不是流表的action,而是一个索引值,指向的是mask_index索引,需要继续在Megaflow里查找。
Megaflow模糊匹配

若在microflow里查找到映射关系对应的mask_index索引,再通过mask_index索引定位到mask,若未在microflow里找到mask_index索引需遍历所有mask,将mask与数据包与操作后在hash表中查找bucket,在bucket里遍历链表找到匹配的rule规则,若匹配到rule会增加Microflowcache的记录后继的包可直接转发,如果在Megaflow还是没有找到,那么就要上送ovs-vswitchd,继续查找OpenFlow pipeline。
OpenFlow流表匹配

handler线程只对原生ovs生效,从内核upcall的消息进行处理。ovs+dpdk下,handler线程也存在,但是一直处于堵塞状态,实际上什么也没干。ovs+dpdk下的慢速路径的处理直接由收包线程pmd线程执行。
ovs-vswitchd根据传进来的数据包遍历subtables,根据hash值找到bucket,在bucket里遍历链表找到rule,需要注意的是查找过程中优化了分段查找和前缀树查找,具体可以参考openflow流表,若在openflow里查找不到,默认上送controller。
ovs-dpdk三级匹配
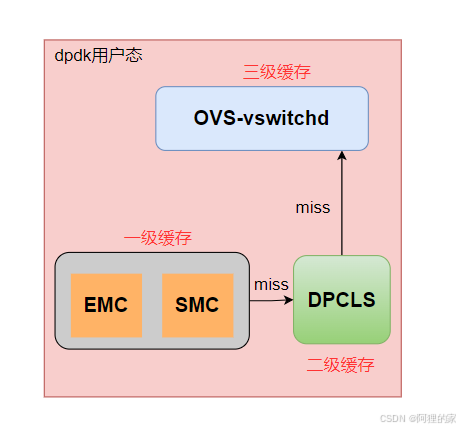
miniflow:dpdk网卡接收到的报文通常都包含几百字节大小,且在匹配流表的过程中只是使用部分字段。ovs-dpdk中专门设计了一个数据结构来缓存报文中需要匹配的字段信息,以此来提高匹配的效率。
优点:①节省内存。
②如果只想遍历flow中的非0字段时,使用miniflow找到对应的非0字段,可以节省时间。
EMC一级查找

报文提取:从dpdk网卡接收到报文,将报文的信息进行压缩,存储在netdev_flow_key结构中的miniflow和buf中。压缩完之后,根据报文的五元组计算hash值存储在netdev_flow_key结构中的hash中。
EMC查找:根据上一步计算出的key.hash值,在emc-cache里根据key查找emc_entry,只有当满足:
1)emc_entry中的key.hash与计算出的hash值相等。
2)emc_entry.flow->dead为false,表明该流表项仍然保活着。dpcls删除表项的过程中会设置。
3)key.mf和emc_entry.key.mf完全相同。代表匹配成功返回emc_entry.flow执行后续action。
对于emc查找不匹配的报文继续dpcls查找。
dpcls二级查找

dpcls查找:根据收报文的端口in_port值计算出一个hash值in_port_hash,遍历bucket若hashs[i]和in_port_hash值相等则认为找到合适的bucket。遍历该bucket中的node链表查找合适的dpcls结构。查找的条件是通过比较dpcls结构中的in_port值和收报文的in_port值,相等则认为查找成功。
subtable查找:
①:计算报文的netdev_flow_key,记为pkt_key
②:遍历dpcls_subtable,将pkt_key和dpcls_subtable.mask与操作后hash记为subtable_hash
③:遍历dpcls_subtable.rules找到bucket的hash值与subtable_hash相同的bucket
④:遍历bucket的node链表,若pkt_key和dpcls_rule.flow相同,匹配成功
对于dpcls查找匹配成功的报文要将具体的流表信息添加到EMC缓存中。
对于dpcls查找不匹配的报文,根据pkt_key.mf和pkt_key.buf恢复后放到match.flow里上送到ovs-vswitchd查找openflow。
更新emc_entry:若找到了合适的emc_entry。则将报文对应的netdev_dev_flow key信息存储到该表项中。而对于这个表项,原有的emc_entry.flow有可能还有指向一条旧的流表,需要将这条流表的引用计数减1,如果减1后达到0,则释放该流表空间。同时更新emc_entry.flow重新指向新的流表。
OpenFlow三级查找

将之前的miniflow恢复,上送到ovs-vswitchd里查询openflow流表,具体参考openflow流表。
若查询到rule需插入dpcls和emc一二级缓存,若在openflow里查找不到,默认上送controller。
若开启硬件卸载功能,则将数据包放入offload队列,等待hw_offload进程处理。
ovs-dpdk硬件卸载
硬件卸载是一种技术,它允许将网络数据包的处理任务从CPU转移到专门的硬件上,以此来提高性能并减少CPU的负载。
ovs内核态并没有被分配太多内存,所以内核态能够保存的流表项很少,所以需要配合硬件卸载提高流表查询性能。
ovs开启offload功能后,在openflow三级查找时ovs-vswitchd会将数据包放入offload队列,hw_offload进程会读取队列中的数据,调用通过rte_flow接口将flow规则下发至硬件时并不影响原有将flow下发至dpcls,后续数据包到达时最先在硬件里查找并且转发。

rte_flow用于配置网络接口卡上的硬件流分类和动作规则。这些规则可以直接在NIC硬件上执行,从而加速数据包的处理,减少CPU的负载。rule流规则由匹配模式和动作列表组成。匹配模式定义了数据包的特征,而动作列表定义了当数据包匹配时应执行的操作。
匹配模式(Pattern):匹配模式是一个或多个匹配项的列表,每个匹配项指定了数据包头部中的一个或多个字段,如以太网类型、IP协议类型、源/目的IP地址、源/目的端口等。
动作(Action):动作定义了当数据包匹配流规则时应执行的操作,如转发到特定的队列、丢弃、修改数据包内容、增加/删除VLAN标签等。
ovs pipeline刷新
给ovs添加网桥后,ovs-vswitchd进程就会自动生成若干个handler和revalidator线程,可以手动配置handler和revalidator个数,若未配置根据cpu数来定。revalidators 等于cpu个数除4后加1,handlers 等于cpu个数减去revalidators 个数。
- megaflow创建后默认10s没有流量经过就会被删除。
- 已经下发了一条megaflow流表,10s内将其对应的openflow流表删除,则这条megaflow流表也要立即被删除。
- 已经下发了一条megaflow流表,10s内修改其对应openflow流表的action后,则这条megaflow流表的action也要相应改变。
- 流表数最多不超过20w条,若超过该条数,默认刷新时间由10s变为100ms。
revalidator线程用于megaflow流表的超时删除,响应openflow流表的改动,还有就是周期获取datapath流表的统计信息,确认流表是否被使用。

ovs重启
OVS流表在重启后不会自动保存,需要手动保存和恢复。之前设置的流表都会丢失。为了避免这种情况,有两种方法可以保存和恢复流表:
- 使用控制器重新下发流表:通过控制器重新下发流表可以确保流表的准确性,但需要依赖外部控制器。
- 使用ovs-ofctl工具手动保存和恢复流表:可以使用ovs-ofctl工具在重启前导出流表ovs-ofctl dump-flows,重启后再通过ovs-ofctl add-flow命令重新添加导出的流表。

















 2015
2015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









