






 本文档介绍了如何通过Ambari在Hadoop 2.0以上版本中设置高可用性(HA)。步骤包括设置Nameservice ID,选择namenode节点,配置HDFS,执行相关命令如进入安全模式、保存命名空间,初始化共享编辑日志,以及使用ZooKeeper格式化和启动NameNode。
本文档介绍了如何通过Ambari在Hadoop 2.0以上版本中设置高可用性(HA)。步骤包括设置Nameservice ID,选择namenode节点,配置HDFS,执行相关命令如进入安全模式、保存命名空间,初始化共享编辑日志,以及使用ZooKeeper格式化和启动NameNode。
hadoop的ha操作流程,本操作是利用ambari完成,如果不是使用ambari,可以参考,要保证其中命令的执行顺序。如果是手动安装hadoop的ha时,可以参考以下执行的命令,但是要保证命令执行的顺序。
hadoop2.0以后的版本支持HA,如图安装HDFS的HA,保证节点在三个以上。
1. 安装流程从下图开始:

2. 点击后跳转到如下页面,输入Nameservice ID,要牢记ID,用于查看dfs:

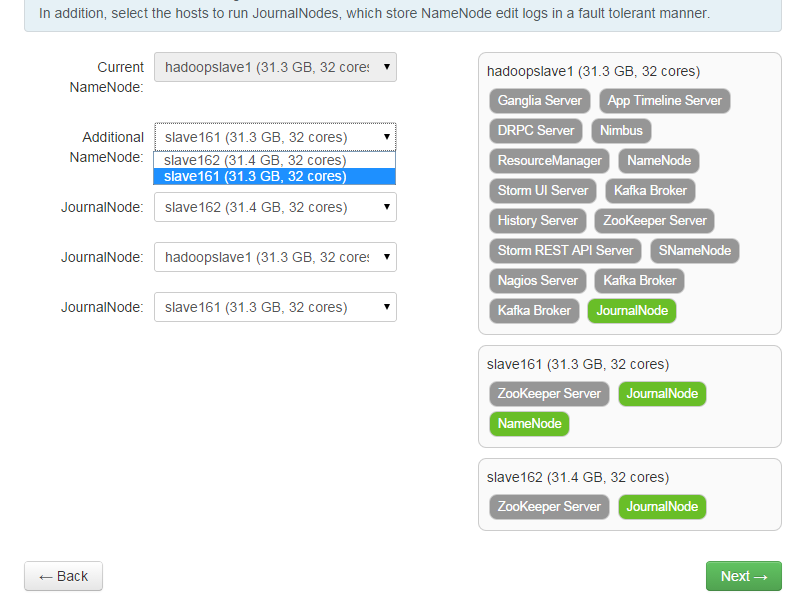
3. 选择要添加为namenode的节点,一般这些节点都是在hadoop集群节点(同时部署了ZooKeeper Server组件)中选取:
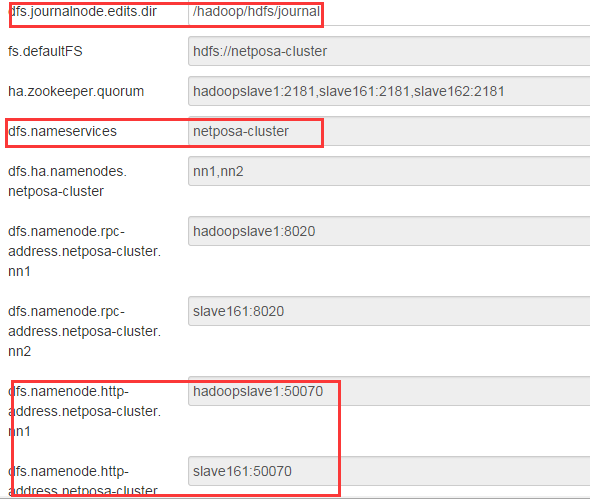
4. 点击Next后,页面显示了hdfs的配置,dfs.joutnalnode.edits.dir是文件的存放的路径,建议大于100G空间的额外挂载的磁盘上,如/hadoop/disk1。其他保持默认即可。
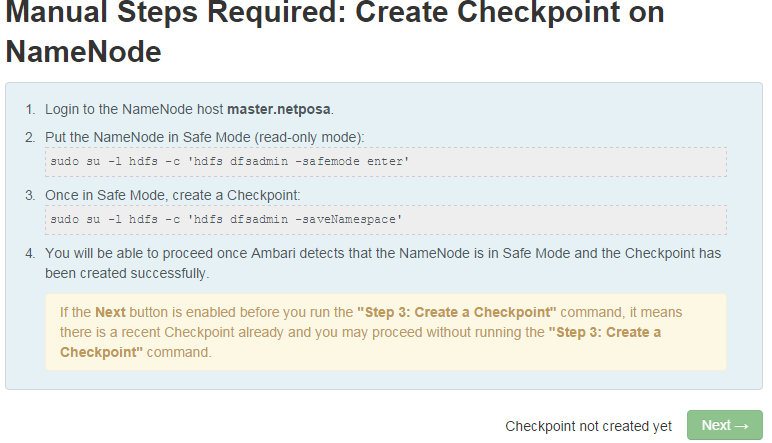
5. 如下页面是需要在namenode节点上进行操作的,保存namespace,按页面提示进行操作即可,其中naster.netposa表示NameNode节点:
登录NameNode节点(主机名为master.netposa),依次执行以下指令:
1) sudo su –l hdfs –c ‘hdfs dfsadmin –safemode enter’
2) sudo su –l hdfs –c ‘hdfs dfsadmin -saveNamespace’
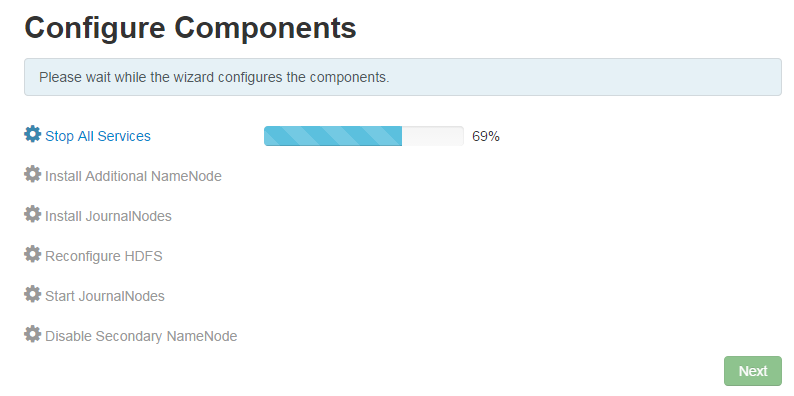
6. 执行结束后,点击Next跳转到如下页面,等待完成,时间稍微有点儿长:
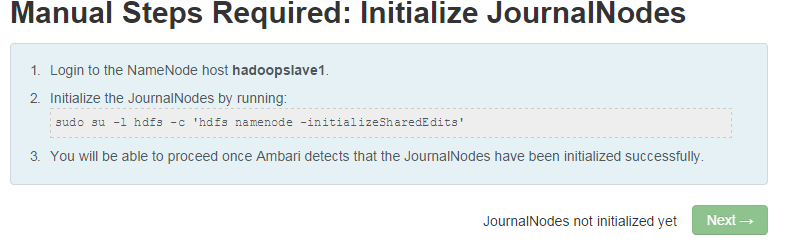
7. 跳转后登陆到原namenode节点,执行页面中的指令,其中hadoopslave1表示原NameNode节点(这个页面是在安装其他集群时截取的,可能有出入,正常的namenode host应该是master.netposa,页面没什么差别):
登录Namenode节点(主机名为hadoopslave1,本图在其他安装过程中截取,和上面不一样),依次执行以下指令:
1) sudo su –l hdfs –c ‘hdfs namenode -initializeSharedEdits’
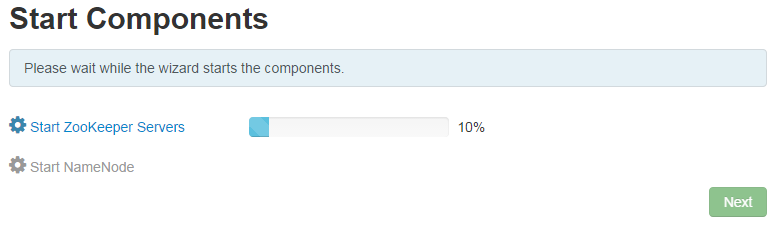
 8. 执行后可以点击Next,跳转到以下页面,等待ZooKeeper Servers和NameNode启动成功:
8. 执行后可以点击Next,跳转到以下页面,等待ZooKeeper Servers和NameNode启动成功:
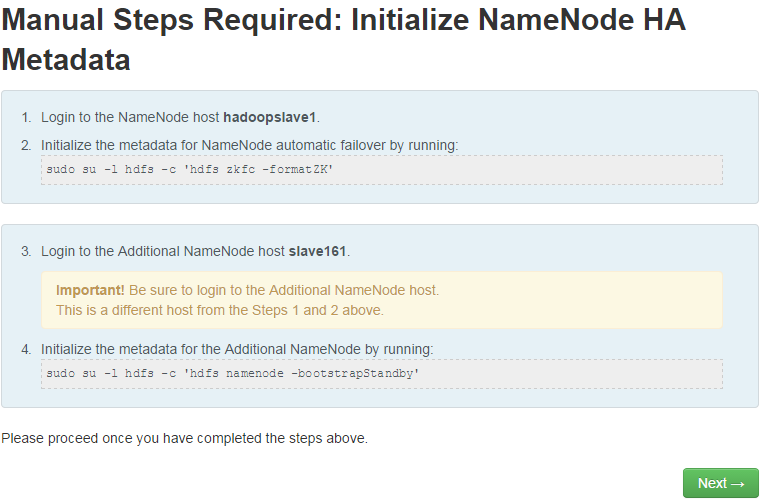
9. 点击“Next”后跳转到下图页面,其中hadoopslave1表示原NameNode节点,slave161表示新增加的NameNode(这个页面截取是在安装其他集群时的,正常情况下应该是master.netposa表示原NameNode节点,slave1.netposa表示新增加的NameNode)。
页面提示:
1)登录原NameNode节点(主机名为hadoopslave1,图在其他集群部署过程中截取的);
2)执行以下命令:
sudo su –l hdfs –c ‘hdfs zkfc -formatZK’
3)登录新增加的NameNode(主机名为slave161,本图在其他集群安装过程中截取)
4)执行以下命令:
sudo su –l hdfs –c ‘hdfs namenode -bootstrapStandby’
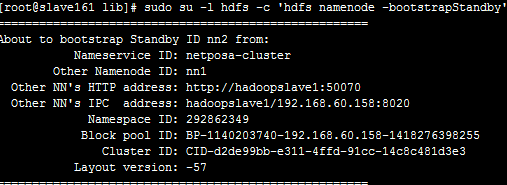
10. 其中新增加的namenode节点执行完后,终端打印出以下信息:
11. 完成后页面出现以下提示:
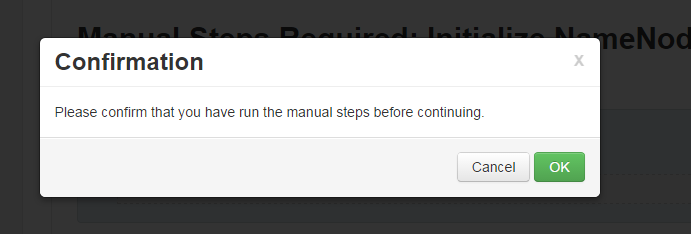
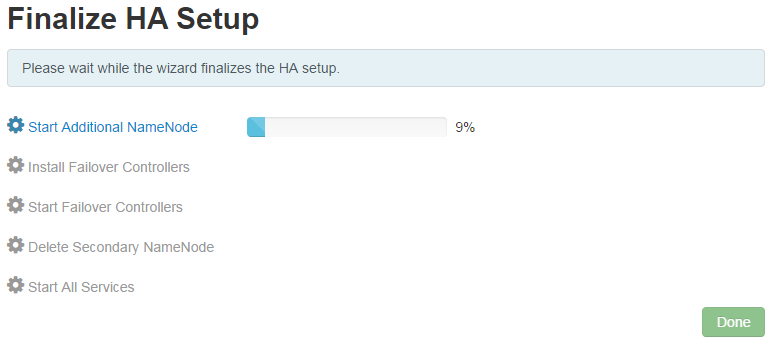
12. 如下页面执行完成后,整个hdfs的ha启动完成:

















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









