




 文章介绍了LeNet-5模型的历史和基本结构,它是首个成功的卷积神经网络,用于手写数字识别。在PyTorch中定义并训练LeNet模型,包括数据预处理、模型构建、损失函数和优化器设置。文章还展示了训练和验证过程,以及绘制训练和验证的损失及准确率曲线。
文章介绍了LeNet-5模型的历史和基本结构,它是首个成功的卷积神经网络,用于手写数字识别。在PyTorch中定义并训练LeNet模型,包括数据预处理、模型构建、损失函数和优化器设置。文章还展示了训练和验证过程,以及绘制训练和验证的损失及准确率曲线。
目录
1.LeNet简介
1.1基本介绍
LeNet(LeNet-5)是历史上第一个成功应用于数字识别任务的卷积神经网络模型。由于其优秀的表现和先进的结构被广泛认可,成为深度学习的里程碑之一。LeNet由加拿大籍计算机科学家Yann LeCun在1998年提出,旨在解决手写数字识别问题。它是第一个能够通过卷积层和池化层实现特征提取和降维的卷积神经网络模型。LeNet-5模型的架构包含6层,包括2个卷积层、2个池化层和2个全连接层。LeNet-5的主要优点是它非常高效,具有一定的鲁棒性,并且在处理小尺寸图像时表现出色。今天,LeNet-5已经成为深度学习神经网络的开山鼻祖之一。
LeNet的设计目标是用于识别手写数字,特别是美国支票上的手写数字识别。它由一系列的卷积层和池化层组成,最后连接全连接层进行分类。LeNet的基本结构如下:
1. 输入层(Input Layer):接收输入图像数据。
2. 卷积层(Convolutional Layer):使用卷积核对输入图像进行卷积操作,提取图像特征。同时通过激活函数引入非线性。
3. 池化层(Pooling Layer):对卷积层的输出进行下采样,减小数据的空间维度,减少计算量,并保留重要的特征。
4. 全连接层(Fully Connected Layer):将池化层的输出展平,并连接到一个或多个全连接层,用于图像分类。
5. 输出层(Output Layer):进行最终的分类操作,输出预测结果。
LeNet的创新之处在于引入了卷积层和池化层,使得网络可以自动从原始图像数据中提取和学习特征。这种结构的设计在图像处理任务中非常有效,为后续深度学习模型的发展奠定了基础。
尽管LeNet的规模较小,但它在当时的手写数字识别任务中取得了很好的效果,并为后续更复杂的卷积神经网络的发展提供了启示。LeNet的设计思想和结构对现代深度学习中的卷积神经网络仍然具有重要的影响。
1.2网络结构
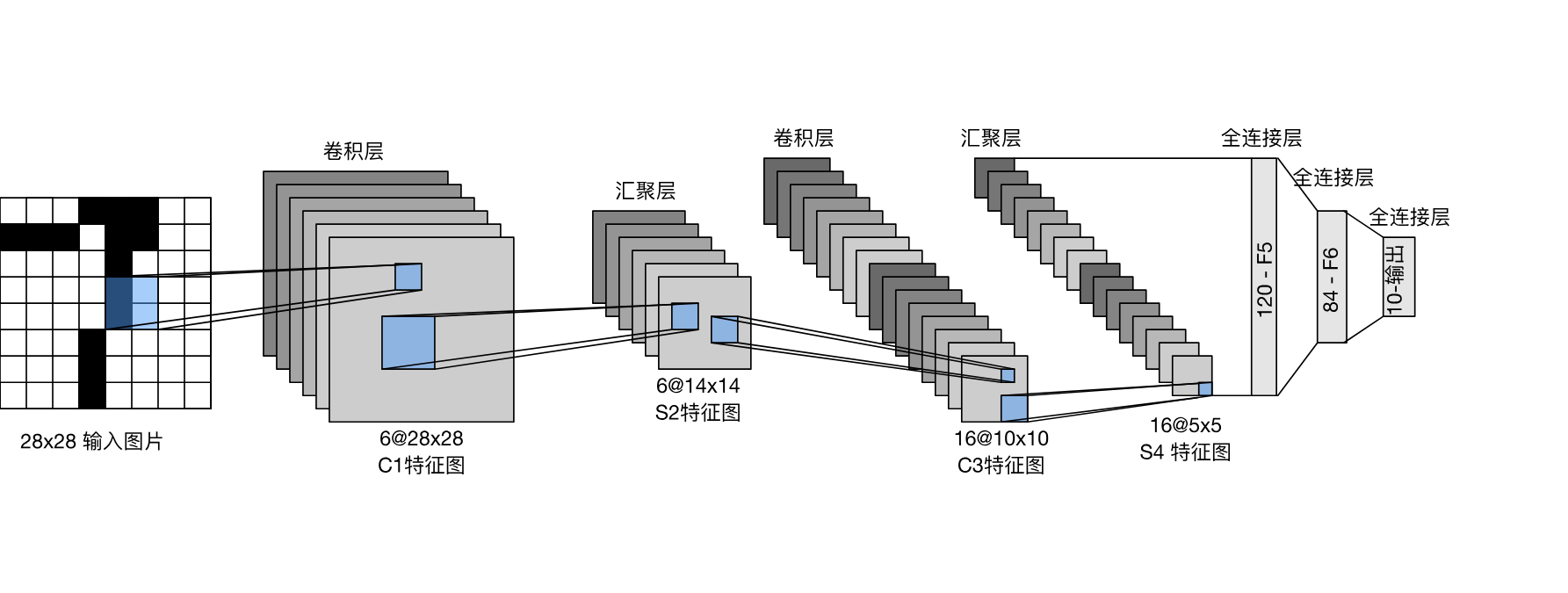
每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。请注意,虽然ReLU和最大汇聚层更有效,但它们在20世纪90年代还没有出现。每个卷积层使用5×5卷积核和一个sigmoid激活函数。这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。每个2×2池操作(步幅2)通过空间下采样将维数减少4倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。换言之,我们将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量。
2.LetNet在pytorch中的使用
定义了LeNet-5模型,包括特征提取层和分类器层。初始化LeNet-5模型,并定义损失函数和优化器。进行训练循环,包括训练和验证阶段。在每个迭代中计算训练和验证的损失和准确度。在训练循环结束后,进行测试阶段,计算测试的损失和准确度。打印出训练、验证和测试的损失和准确度。
2.1首先定义模型
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
# Define LeNet-5 model
class LeNet5(nn.Module):
def __init__(self, num_classes=10):
super(LeNet5, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU(inplace=True),
nn.Linear(120, 84),
nn.ReLU(inplace=True),
nn.Linear(84, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
2.2初始化数据集,初始化模型,同时训练数据。
# Set random seed for reproducibility
torch.manual_seed(42)
# Set device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load CIFAR-10 dataset
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_dataset = CIFAR10(root='./data', train=False, download=True, transform=transform)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
# Initialize LeNet-5 model
model = LeNet5().to(device)
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training loop
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
correct_predictions = 0
total_predictions = 0
# Training phase
model.train()
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_predictions += labels.size(0)
correct_predictions += (predicted == labels).sum().item()
train_loss = running_loss / len(train_loader)
train_accuracy = correct_predictions / total_predictions
# Validation phase
model.eval()
val_loss = 0.0
val_correct_predictions = 0
val_total_predictions = 0
with torch.no_grad():
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
val_total_predictions += labels.size(0)
val_correct_predictions += (predicted == labels).sum().item()
val_loss /= len(val_loader)
val_accuracy = val_correct_predictions / val_total_predictions
print(f"Epoch [{epoch + 1}/{num_epochs}], Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f}, "
f"Val Loss: {val_loss:.4f}, Val Accuracy: {val_accuracy:.4f}")
# Test phase
model.eval()
test_loss = 0.0
test_correct_predictions = 0
test_total_predictions = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
test_total_predictions += labels.size(0)
test_correct_predictions += (predicted == labels).sum().item()
test_loss /= len(test_loader)
test_accuracy = test_correct_predictions / test_total_predictions
print(f"Test Loss: {test_loss:.4f}, Test Accuracy: {test_accuracy:.4f}")
2.3 训练结果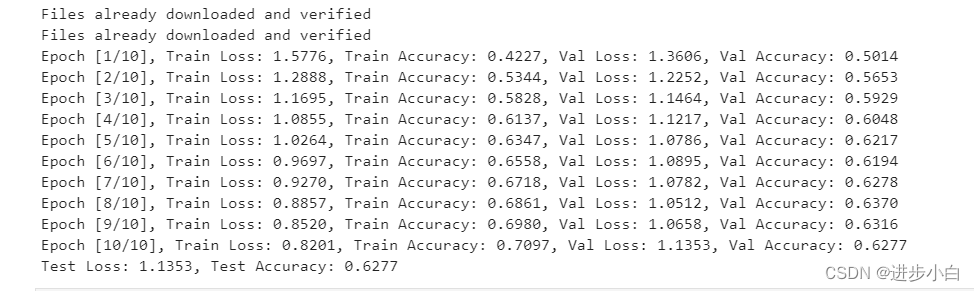
2.4绘制曲线
绘制Training accuracy Curve和Validation accuracy Curve
train_losses = []
train_accuracies = []
val_losses = []
val_accuracies = []
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
correct_predictions = 0
total_predictions = 0
# Training phase
# ...
train_loss = running_loss / len(train_loader)
train_accuracy = correct_predictions / (total_predictions + 1e-7) # Add a small epsilon value
# Validation phase
# ...
val_loss = val_loss / len(val_loader)
val_accuracy = val_correct_predictions / (val_total_predictions + 1e-7) # Add a small epsilon value
# Append accuracy and loss values to lists
train_losses.append(train_loss)
train_accuracies.append(train_accuracy)
val_losses.append(val_loss)
val_accuracies.append(val_accuracy)
# Print epoch results
# ...
# Test phase
# ...
test_loss = 0.0
test_correct_predictions = 0
test_total_predictions = 0
# Plotting the curves
plt.figure(figsize=(12, 4))
# Plot training and validation loss curves
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs + 1), train_losses, label='Training Loss')
plt.plot(range(1, num_epochs + 1), val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
# Plot training and validation accuracy curves
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs + 1), train_accuracies, label='Training Accuracy')
plt.plot(range(1, num_epochs + 1), val_accuracies, label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# Show the plot
plt.tight_layout()
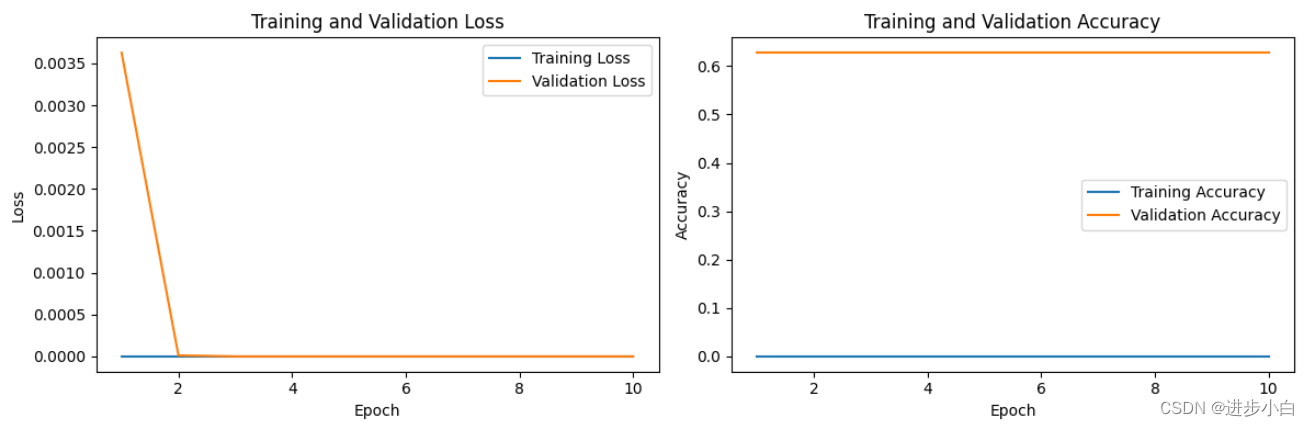
plt.show()运行结果



















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











