




前言
我24年3月份投入到AI辅助编程,创建了 auto-coder 系列项目,就是笃定 AI 辅助编程会是大模型第一个落地的场景. 然后我在24年9月9号发了一篇文章:大模型的第一个杀手级应用场景出来了
这个是我当时的判断逻辑:

但是现在,我的判断逻辑更加清晰,就是这次AI变革是生产力变革,面向的是生产力而不是娱乐消费,和互联网有本质的区别。而能落地的场景,必须是用户高频的“工作agent”。 toC 的用户千千万,每个用户的职业都应该被特定的应用深入的帮助,而且有成瘾性,一旦离开了这个工作agent,自己就不会工作了。就像 AI 辅助编程,用户日常每周需要使用他超过40个小时,并且有海量的token消费,用户一旦离开这种工具,就不会写代码了。
沿着这套逻辑线,我推导出了第二个杀手级应用场景:数据分析。
为什么之前不行,为什么他不是第一个杀手级应用
诶,这个不是很早就有很多人做了么?和RAG知识库一样,之前的人的都做的稀烂,因为他们还是把AI的东西往老的东西上不断的叠加,也不知道如何从AI原生角度出发去设计和思考产品,此外,就是之前的企业做的太早了。AI辅助编程是第一个杀手级应用,而数据分析是第二个,他们两者是先后关系,必须有AI辅助编程先出现,才能再出现数据分析。数据分析需要AI辅助编程探索出来的很多技术,才能最后落地。说白了,在此之前,数据分析领域,无论应用技术和大模型以及思考深度能力,都无法支持其落地。但是现在,随着AI辅助编程技术的发展,数据分析也终于可以落地了。
NLP2SQL 只是简单的根据自然语言生成SQL么
很遗憾,几乎所有的用户一开始使用大模型做数据分析时,都聚焦的是NLP2SQL。但他们很快遇到了几乎不可解决的问题:
1. 数据分析包含大量业务术语和背景,大模型很难理解用户的需求。
2. 企业有很多数据表,office 文档表,还有数仓,召回需求所需要的表的准确率低到可怕
3.企业有很多数据表,office 文档表,还有数仓,无法对这些数据做统一的分析。
4. 就最简单的生成SQL做法也是针对不同数据源生成不同类型的SQL,而大模型往往会错乱,比如把msyql的function当成hive的function去使用,而SQL自身的复杂度也导致计算大模型能准确的理解需求,能准确的找到合适的表,但是生成复杂SQL的成功率也极低。
所以你还认为 NLP2SQL 只是简单的根据自然语言生成SQL么? 为了完成 NLP2SQL,你需要修炼好内功:
1. 有准确率极高的业务知识库/Schema 知识库,从而让大模型可以理解用户需求,同时找到合适的表。而当前业界几乎所有主流的RAG 都无法满足这个需求。
2. 有强大的引擎,可以跨数据源对各种数据进行连接和分析。
3. 有对大模型更加友好的统一的SQL方言,能让大模型极大的提升生成正确的SQL成果率。
这意味着,你至少要打造三把宝剑,
1. 满足要求的RAG技术
2. 多数据源联合分析的分布式计算引擎
3. 对大模型友好的 SQL方言。
数据分析不仅仅是NLP2SQL
然而,NLP2SQL 只是走出了数据分析的第一步,或者说带来的价值连10% 都不到。数据分析不仅仅是 NLP2SQL,AI 大模型赋予人类的能力也仅仅是 NLP2SQL, 而是:
1. 人类第一次可以用智能去“处理”自己的数据。
2. 人类第一次,可以对全模态的数据做处理。
还记得以前,如果你想知道一个产品的用户好评情况,可能只有两种选择:
1.产品上给个五分打分制。花钱鼓励用户去打分,大于3分就算好评
2. 找NLP的同学写一个情感分析程序,对用户的comment 做分类,正向,负向。
我们希望通过SQL透明来完成comment(对产品评论的)分析,用户无需感知。这才是真正意义上的智能分析。
而全模态的数据分析,我们举一个例子,比如你可能还希望分析出A图片里的用户在哪些新闻稿里出现。
来,一起见证划时代的Agentic 数据分析产品: InfiniSynapse
InfiniSynapse 通过自研的第二代LLM-Native RAG实现了企业业务的理解,精准的Schema召回保证数据的准确性。提供专门为大模型优化的InfiniSQL语言,从而可以更加准确的生成复杂的查询语句,通过 InfiniSQL 引擎让人类第一次对全模态(数据库结构化,文档,语音,视频),进行多数据源 进行联合智能分析,并且支持海量规模。
我们通过Agentic 范式搭配超强的RAG+大模型友好的 InfiniSQL, InfiniSynapse 实现了当前智能分析领域的SOTA。
回顾下:
1. 满足要求的RAG技术 (我们自研的第二代 LLM-Native RAG)
2. 多数据源联合分析的分布式计算引擎 (Infini SQL 引擎)
3. 对大模型友好的 SQL方言。 (Infini SQL)
4. 人类第一次可以用智能去“处理”自己的数据。(Infini SQL)
5. 人类第一次,可以对全模态的数据做处理。(Infini SQL)
如何更好的对用户的需求做理解?在分析过程中, InfiniSynapse 会自主决策查询核实的知识库,来帮助理解用户的需求: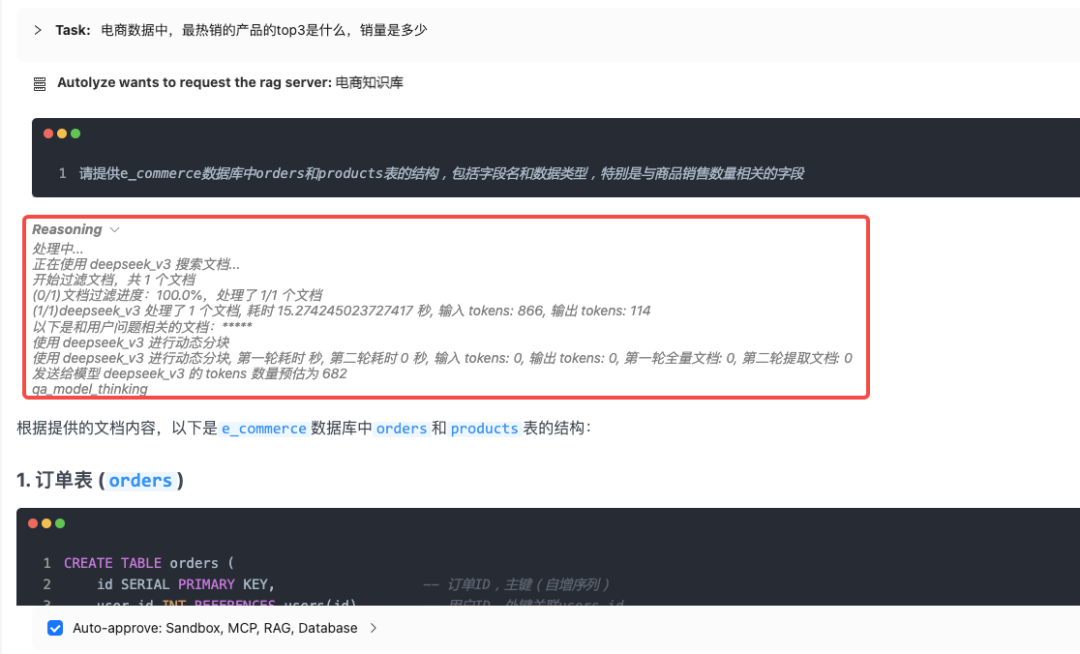
会自主到数据库里验证相应的库表和字段是否真实匹配:
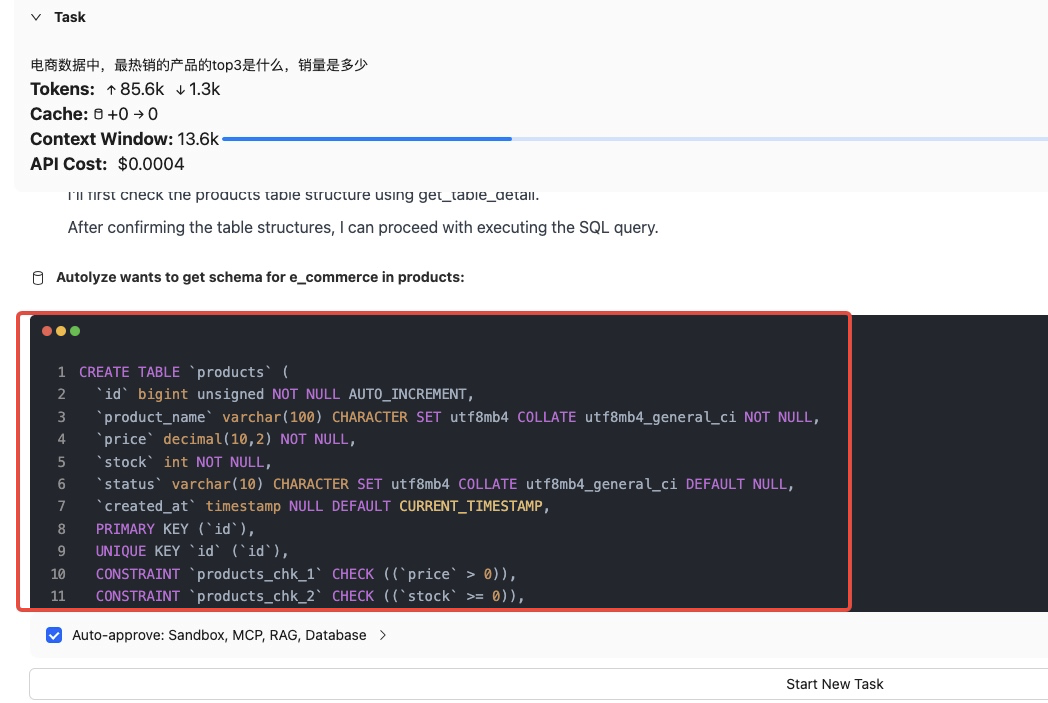
会自动对对文本类的数据使用大模型做处理(还自动给你写prompt):

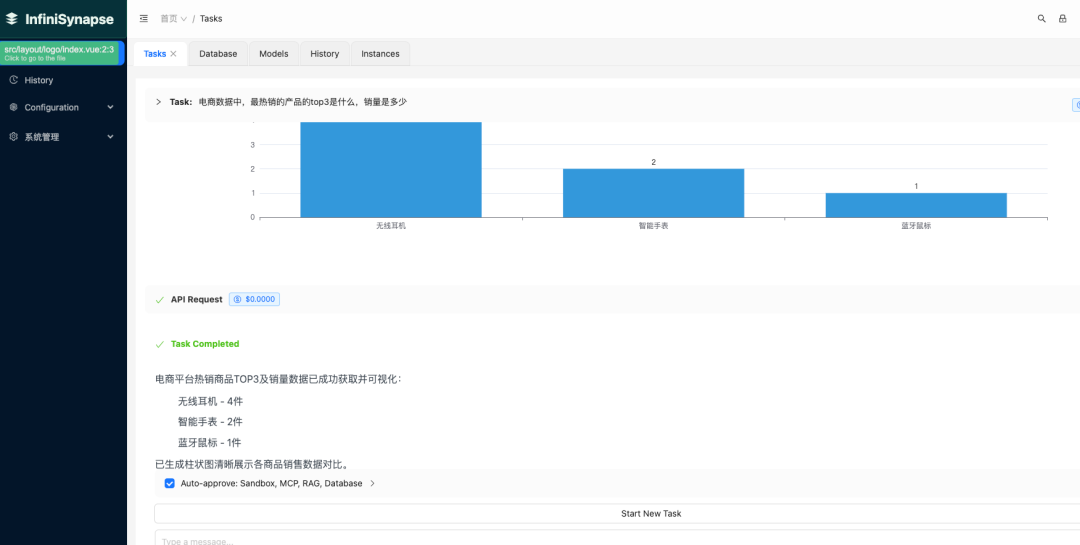
对结果还能支持可视化加总结:
如果是plan模式,他啥事都会和你商量:
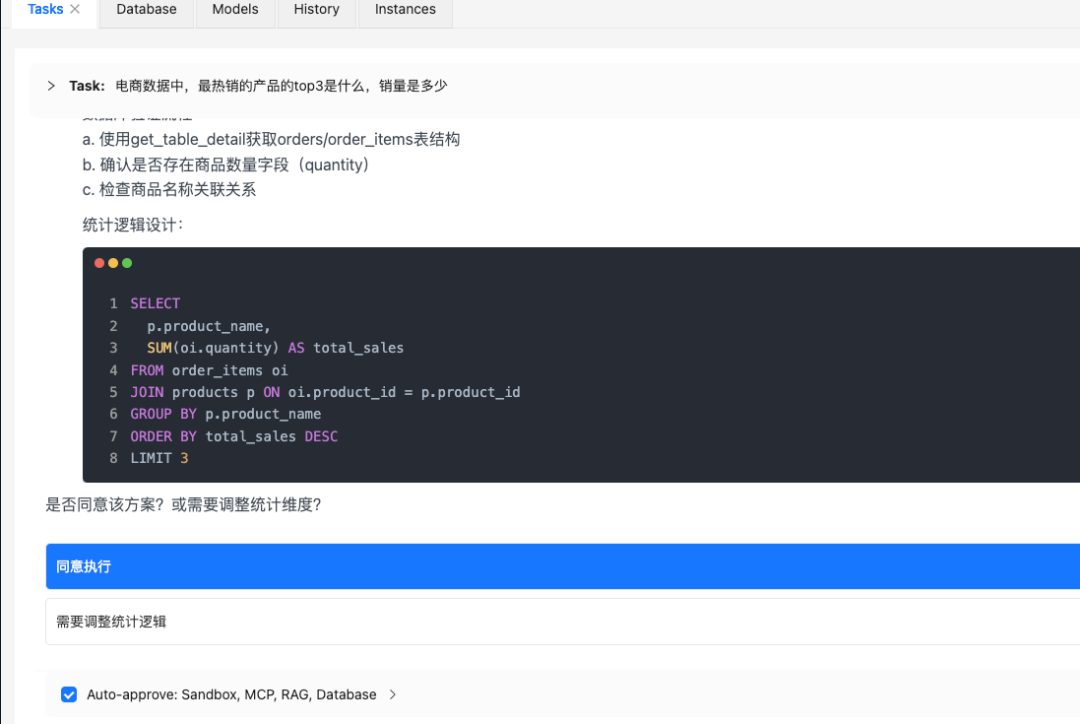
如果讨论清楚了,则自动提醒转入执行模式:
InfiniSynapse 系统文档链接(内涵诸多实际分析案例)
https://uelng8wukz.feishu.cn/wiki/RbHGwPpR7imM7kkzthxcS8HunCb?fromScene=spaceOverview
后话
数据分析领域是一个集大成的领域,对数据分析,人类第一次拥有了完全自主分析能力的Agent, 并且融合了知识库,Agentic 等成熟技术,直接对多类型数据源的多重模态的数据进行联合分析,拓展了人类对数据的分析能力和种类。我们通过对底层引擎进行 AI Native 化改造,真正意义上的实现了交互,执行全智能化。
让每个数据从业人员,每周使用 InfiniSynapse 40 小时以上。
如果大家想体验这个强大的系统,可私信联系我们。

















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









