







 本文详细介绍了Python爬虫中requests库的使用,包括安装、基本GET和POST请求、响应处理、请求头设置、文件上传、Cookie管理、Session会话维持、SSL证书验证、超时设置和身份认证等高级用法,通过实例代码展示了每个功能的实现步骤,帮助读者深入理解和应用requests库。
本文详细介绍了Python爬虫中requests库的使用,包括安装、基本GET和POST请求、响应处理、请求头设置、文件上传、Cookie管理、Session会话维持、SSL证书验证、超时设置和身份认证等高级用法,通过实例代码展示了每个功能的实现步骤,帮助读者深入理解和应用requests库。
一步一步学爬虫(2)基本库的使用之requests
2.2 requests的使用
2.2.1 准备工作
- requests库的安装
pip3 install requests
2.2.2 实例引入
import requests
r = requests.get('https://www.baidu.com')
print(type(r))
print(r.status_code)
print(type(r.text))
print(r.text[:100])
print(r.cookies)
- 运行结果如下:
<class 'requests.models.Response'>
200
<class 'str'>
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charse
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
- 这里调用了get方法实现了与urlopen方法相同的操作,返回一个Response对象,并将其存放在变量r中,然后,分别输出了响应的类型、状态码,响应体的类型、内容、以及cookie。
2.2.3 get请求
基本实例
import requests
r = requests.get('https://www.httpbin.org/get')
print(r.text)
- 运行结果为:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-63a6d04f-03ed36847c320a0f32b96d81"
},
"origin": "39.69.199.58",
"url": "https://www.httpbin.org/get"
}
- 以上结果包含请求头、IP、URL等信息。
- 额外加信息,两种方式,一是如下方法:
https://www.httpbin.org/get?name=germey&age=25
还有就是:import requests data = { 'name':'germey', 'age':25 } r = requests.get('https://www.httpbin.org/get',params=data) print(r.text) - 结果就是:
{ "args": { "age": "25", "name": "germey" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "www.httpbin.org", "User-Agent": "python-requests/2.28.1", "X-Amzn-Trace-Id": "Root=1-63a6d158-7e47854b18da5e1747e50cad" }, "origin": "39.69.199.58", "url": "https://www.httpbin.org/get?name=germey&age=25" } - 显然第二种方法,容易操作,不用我们自己构造URL了。
- 返回的类型是str类型,但却是特殊的JSON格式,所以可以直接调用json方法。
import requests r = requests.get('https://www.httpbin.org/get') print(type(r.text)) print(r.json()) print(type(r.json))
从结果看,调用json方法将结果转化为了字典类型。<class 'str'> {'args': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'www.httpbin.org', 'User-Agent': 'python-requests/2.28.1', 'X-Amzn-Trace-Id': 'Root=1-63a6d315-4af0b6be1b0e2ceb155f7fb2'}, 'origin': '39.69.199.58', 'url': 'https://www.httpbin.org/get'} <class 'method'>
抓取网页
import requests
import re
r = requests.get('https://ssr1.scrape.center')
pattern = re.compile('<h2.*?>(.*?)</h2>',re.S)
titles = re.findall(pattern,r.text)
print(titles)
-
运行结果:
[‘霸王别姬 - Farewell My Concubine’, ‘这个杀手不太冷 - Léon’, ‘肖申克的救赎 - The Shawshank Redemption’, ‘泰坦尼克号 - Titanic’, ‘罗马假日 - Roman Holiday’, ‘唐伯虎点秋香 - Flirting Scholar’, ‘乱世佳人 - Gone with the Wind’, ‘喜剧之王 - The King of Comedy’, ‘楚门的世界 - The Truman Show’, ‘狮子王 - The Lion King’]
抓取二进制数据
import requests
r = requests.get('https://scrape.center/favicon.ico')
print(r.text)
print(r.content)
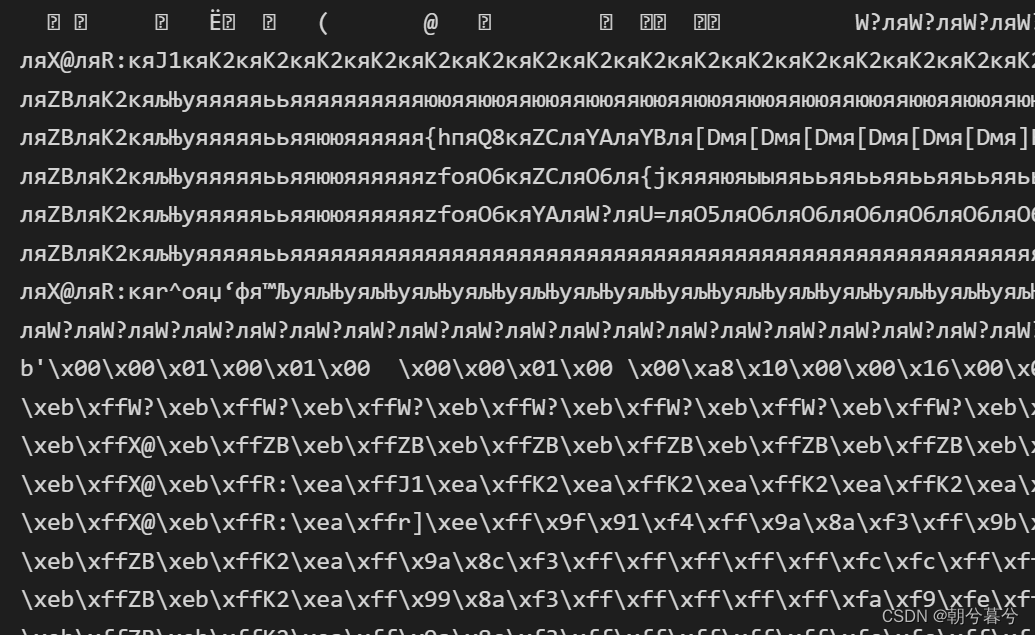
- 上面是运行结果。r.text中出现了乱码,r.content的前面带有一个b,代表是bytes类型的数据。
- 然后把信息保存起来。
import requests
r = requests.get('https://scrape.center/favicon.ico')
with open("favicon.ico",'wb') as f:
f.write(r.content)
- 得到了一个图标。这里用了 open 方法,它的第一个参数是文件名称,第二个参数代表以二进制写的形式打开,可以向文件里写入二进制数据。
运行结束之后,可以发现在文件夹中出现了名为 favicon.ico 的图标,如图所示。

添加请求头headers
-
我们知道,在发起一个 HTTP 请求的时候,会有一个请求头 Request Headers,那么这个怎么来设置呢?
-
很简单,我们使用 headers 参数就可以完成了。
-
在刚才的实例中,实际上我们是没有设置 Request Headers 信息的,如果不设置,某些网站会发现这不是一个正常的浏览器发起的请求,网站可能会返回异常的结果,导致网页抓取失败。
-
要添加 Headers 信息,比如我们这里想添加一个 User-Agent 字段,我们可以这么来写:
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











