







 本文分享了作者在度小满金融、阿里巴巴、海康威视和百度等公司的实习面试经历,详细记录了面试流程、问题及个人感受,为求职者提供实战参考。
本文分享了作者在度小满金融、阿里巴巴、海康威视和百度等公司的实习面试经历,详细记录了面试流程、问题及个人感受,为求职者提供实战参考。
这次找实习,目的很单纯,就是拿到offer,如果拿不到算法offer,我差不多就去做前端了,哭哭~
很多同学都已经找到了,而我还在路上,总是慢人一步,3月底才迎来第一场面试
未来可期,大家别急,offer会有的!!!
度小满金融 凉
度小满这次终于有自己的总部了,我感觉环境还挺棒的,还有班车食堂巴拉巴拉的福利,最重要的是背靠百度!
专门在我们学校南洋大酒店举办的现场面试,诚意满满,算法岗面试的人不多,大概也就是个20左右,一共两面,两面结束之后就回去等结果了,七天之后,也就是下周二,看看能不能开奖吧!
一面
一面感觉真的没问什么技术问题,面试官直接查看我带去的简历,还问我伯克利是不是王力宏毕业的那个学校,有点幽默细菌。之后就是无聊无趣消磨时间的自我介绍。然后面试官主动问我这三段是实习经历你选一段给我讲讲,然后我就开始讲,面试官提出了“特征覆盖率”还有“时间穿越”的疑惑,都是我以前没想到的点。后来就问我写在简历上的技能哪个不能问,哈哈哈太逗了,最后问了我python和mysql中多表查询的问题,就放我走了。
python中__init__.py文件的作用是什么?
https://www.cnblogs.com/cindy-cindy/p/8258518.html
可以使文件夹变成一个模块。
二面
1. 讲一讲你在京东金融所做项目,特意问了下文本处理这块的具体实现。
2. word2vec原理了解吗?
3. GBDT和XBG了解吗?把GBDT讲解一下吧。
4. SVM了解吗?可以推导吗?给了我一张白纸。
5. 数据结构算法题可以吗?给了我一张白纸,让我做leetcode:subsets。
6. 因为面试官是风控这块的,就给我了一个应用场景,让我分析怎么构建一个模型,去监控异常,回答的时候太激动反而忘记了数据分析这一块。
总结
这是我的第一次现场面试,还是有点紧张的,一直担心会不会有手撕代码题,没想到还真有,没想到还不算难,一般会问到的话也就是个premium难度的吧,太难太复杂的我感觉也不会考到。再者说来就是逻辑有点混乱,很没有顺序,这也是我需要在克服的,等着吧,今天都周五,下周二还会远吗。
阿里巴巴(钉钉事业部)(电话面40分钟)凉
问题
- 自我介绍(家乡、教育经历、实习项目经历)
- 研究生实验室研究方向,我的毕业论文方向,我说是自学的,他问我怎么学的
- JDJR实习的项目,他会问很详细的实现细节,还会问你现在回望,有哪些优化方法
- word2Vec原理(这个英文发音每个人差别好大,我连蒙带猜终于明白了他说的是什么)
- word2vec是词向量的求解模型,输入:大量已分好词的文本,输出:用一个稠密向量表示每一个词
- word2Vec就是简化的神经网络模型:

我们为每个词获取的稠密向量,其实就是隐藏层的输出单元,或者说是从输入层到隐藏层的权重 - 训练word2Vec模型:损失函数:交叉熵(与LR对比),优化方法:SGD
https://www.jianshu.com/p/b779f8219f74
https://blog.youkuaiyun.com/mylove0414/article/details/61616617
- TF-IDF原理

- 平时使用什么语言
- 让我问问题
总结
这是我2019的第一场面试,没想到就是阿里,之前三家挂了我的简历,分别是菊厂、虎牙、海康,可能简历写的太不走心了吧,连个面试机会都没有,很难过~还好有阿里爸爸,阿里给我打电话的时候还是很激动的,他会询问合适的时间,争取了一点准备时间,我感觉面试都不难,但是总怕阿里的玄学面试,都不招人了,还要疯狂内推面试,我看牛客上很多人面的很好,最后就没然后了,感觉很可惜,静候佳音吧!
给大家一个建议吧,一定要把你用过的、写在简历上的所有东西都弄明白,面试官问的真的越来越细了!!!
2019年情况竟然这么糟糕,难过!!
海康威视(电话面40分钟)凉
距离面试已经过去半个月了吧,凉凉了~
说来奇怪,明明投了之后显示已经淘汰,但是还是在某个无聊的中午接到了面试通知,一脸懵逼,并且我觉得面的挺好之后,也是没了下文,官方信息还是这个样子:

哭哭惹,要不要给我个准确消息啊,就让我这么在简历池里飘着,还有那个华为也是,同学都要去签约了,我还是没收到笔试通知!!!!
问题
- 自我介绍(我感觉我在说,面试官在神游)
- 既然你面试的是算法工程师,那你能不能介绍一种你熟悉的算法(之前看过面经,海康就喜欢问这个,做了一点准备)
我从算法原理、算法流程和优缺点介绍了集成学习中的随机森林,他在面试中会随时打断你让你回答问题,问的问题如下:-
你刚才提到随机森林中的树是CART树,它既能做回归又可以做分类,那么它是如何实现的呢?
常用的是分类树,就不再赘述了,重点关注回归树:
当CART是回归树时,采用样本的最小方差作为节点分裂的依据,构建流程如下:

-
随机森林为什么能提高准确率呢?
多个由Bagging集成学习技术训练得到的决策树,当输入待分类的样本时,最终的分类结果由多个决策树的输出结果投票决定,随机森林克服了决策树过拟合问题,对噪声和异常值有较好的容忍性,对高维数据分类问题具有良好的可扩展性和并行性。 -
RF中决策树的特征划分有哪几种标准?信息增益比的提出解决了什么问题?
- ID3: 信息增益;C4.5: 信息增益比;CART:基尼系数;
- https://www.jianshu.com/p/268c4095dbdc
解决了信息增益倾向于选择取值较多的数据,容易造成过拟合的问题。
-
你刚才提到集成学习,那集成学习中AdaBoost和GDBT的区别是什么呢?二者的损失函数又是什么呢?
- 区别:
- AdaBoost 是通过提升错分数据点的权重来定位模型的不足,而Gradient Boosting是通过计算负梯度来定位模型的不足;
- GBDT中树是回归树,AdaBoost可以是回归树,也可以是分类树。
- 参考 https://www.cnblogs.com/pinard/p/6140514.html
二者损失函数:Adaboost是指数损失函数,GBDT情况较为复杂:分类:指数损失函数和对数损失函数;回归:平方损失函数和绝对值损失函数。
- 区别:
-
LGB你了解吗?它是如何处理类别型特征的呢?XGB呢,能直接处理类别型特征吗?
- lgb原理巴拉巴拉介绍一下,注意它的各种新特性和xgb的区别

- lgb可以直接处理类别型特征,需要在训练参数前,指定哪些是类别特征

- lgb原理巴拉巴拉介绍一下,注意它的各种新特性和xgb的区别
-
如果使用one-hot对特征进行变换,那对树模型会有什么影响吗?会造成过拟合吗?
会造成过拟合,和维度灾难类似吧,有不同意见欢迎评论区指出
-
- 特征生成的方式?特征衍生、特征筛选、特征降维的区别是什么?特征降维中PCA是选择k个特征还是直接生成k个特征来进行降维呢?
- 特征生成方式:参考 https://blog.youkuaiyun.com/cymy001/article/details/79169862
- 时间戳处理 ;
- one-hot类别型特征,注意label-encode会带来的问题;
- 数值型特征转化为类别型特征:分箱/分区,要理解带来的优势;
- 数值缩放,归一化等等;
- 特征筛选,参考我之前的总结吧:

- 特征降维理解PCA即可
- 这一个问题主要是考察特征选择和特征降维的区别:参考 https://www.cnblogs.com/nolonely/p/6552509.html
假设原始特征K维,经过PCA之后,特征变为k维,此时这k维特征是新生成的,不是直接从K维中选取出来的。
- 特征生成方式:参考 https://blog.youkuaiyun.com/cymy001/article/details/79169862
- 数据结构:堆是怎么样的数据结构?
堆就是用数组实现的二叉树。
分为大根堆和小根堆,大根堆中父节点的值比他每一个子节点都要大,小根堆则相反。 - 聚类算法中KMeans源码看过吗?KMeans可以直接处理类别型特征吗?
- 为什么大家都喜欢看源码呢??我肯定没看过啊!
- 不可以吧,只有lgb可以直接处理,KMeans需要one-hot一下
- SQL:有那些年聚合函数?COUNT(1)和COUNT(*)有什么区别吗?
- 聚合函数:
COUNT:统计行数量 SUM:获取单个列的合计值 AVG:计算某个列的平均值 MAX:计算列的最大值 MIN:计算列的最小值 ``` - 在没有条件的时候二者没有什么差别,其他情况见下图:

- 聚合函数:
总结
全程没有讲项目,全程在问基础问题,真的要求基础功扎实,我试图往比赛、项目上面引,但是面试官让我长话短说= =。后来面试官给我介绍说,他们主要还是看学习能力,还有知识面的广度,建议我还是在深入的学习一下(我每次都喜欢问建议哈哈哈)。整体面试感觉还是很轻松的,90%都答上来了,没答上来的我确实也没用过,所以等消息吧,现在真的是神仙打架,面试情况并不能决定你肯定能留下来,说不定还有三篇顶会的那种大牛呢,哈哈哈~
百度
笔试
百度还是一如既往的中规中矩,笔试难度中上,有选择、简答、开放和编程题目,我编程题目写的不好,8%+0%的通过率实在是丢人,我觉得笔试的编程题目和平时剑指和leetcode上的差别还是蛮大的,特别需要考虑时间复杂度,有时候本地IDE写着都OK,提交以后就通过率小小,查来查去,查不明白,还是很心痛的,平时可以适当练习一下,以往的笔试题目,体会一下。
面试
很开心百度给我面试的机会,百度的这个招聘节点还是卡的很准的,13-14北京地区现场面试,20-21其他地方远程面试,一共三面,我是三面都是技术面,每一面都有手撕代码,没有公式推导,问的原理很细,基础扎实,原理都懂这是最基本的要求。二面是我面的最垃圾的,真的是全程怼到无语,面试完直接躺床上不想动了,开始怀疑人生。分享一段令人自闭的对话:
(开场)
面试官:你会深度学习吗?深度学习的优化算法有那些?
我:面试官你好,我面机器学习的,深度学习不太会,仅限于了解。
(A few moments later…)
面试官:你的专业是软件工程,那你一定会C++喽?我们来用C++写道题。
我:我本科是学电子的,不会C++,抱歉啊,我可以用python或者java写吗?
面试官:那你本科用什么语言写东西啊?
我:我本科不怎么写代码。。。(话还没讲完)
面试官:用汉字写啊???
(A few moments later…)
面试官:GDBT中这个G是什么意思?
我:梯度啊
面试官:Bagging中bag是什么意思啊
我:书包啊,真的是第一反应,不要怀疑。。。
面试官:不说话(也不告诉我答案,好生气!)
由于是五个小时连续的三面,很多问题我都搞混了,记不清了,就一起呈现了!!!
-
lgb如何给出特征重要性排序, lgb的histogram算法,优点有哪些?lgb如何进行特征并行、数据并行?
需要好好看文档:http://lightgbm.apachecn.org/#/docs/4- 特征权重(weight)指的是在所有树中,某特征被用来分裂节点的次数;一个特征对分裂点性能度量(gini或者其他)的提升越大(越靠近根节点)其权重越大,该特征被越多提升树选择来进行分裂,该特征越重要,最终将一个特征在所有提升树中的结果进行加权求和然后求平均即可。
- histogram算法:将连续特征分段为离散的桶来加速训练并减少内存的使用。
优点:
1. 减少分割增益的计算(O(#bins)次);
2. 通过直方图相减来进一步加速;
3. 减少内存的使用;
4. 减少并行学习通信的代价。

- 特征并行:不再垂直划分数据,即每个线程都持有全部数据。流程如下:
- 每个线程都在本地数据集上寻找最佳划分点:{特征,阈值};
- 本地进行各个划分的通信,整合并得到最佳划分;
- 执行最佳划分。
- 数据并行:
- 水平划分数据;
- 线程以本地数据构建本地直方图;
- 使用分散规约的方式对不同线程中的不同特征进行整合;
- 线程从本地整合直方图中寻找最佳划分并同步到全局的最佳划分中去,执行此划分。
-
jieba分词的三种模式和原理
- 三种模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 分词原理:
jieba分词主要是基于统计词典,构造一个前缀词典;然后利用前缀词典对输入句子进行切分,得到所有的切分可能,根据切分位置,构造一个有向无环图;通过动态规划算法,计算得到最大概率路径,也就得到了最终的切分形式。
- 三种模式:
-
word2vec优化训练过程的两种方法
系统学习word2vec还是推荐刘建平老师:
https://www.cnblogs.com/pinard/p/7160330.html
https://blog.youkuaiyun.com/qq_35290785/article/details/89406868- 负采样(negative sampling)
将语料中的一个词串的中心词替换为别的词,构造预料D中不存在的词串作为副样本。此种策略下,优化目标变为:较大化正样本的概率,同时最小化副样本的概率。 - 层序softmax(hierarchical softmax)
是一种对输出层进行优化的策略。原始模型的输出层利用softmax计算概率值,层序softmax改为了利用Huffman树计算概率值。一开始我们可以用以词表中的全部词作为叶子节点,词频作为节点的权,构建Huffman树,作为输出。从根节点出发,到达指定叶子节点的路径是概率值。Hierarchical Softmax正是利用这条路径来计算指定词的概率,而非用softmax来计算。
- 负采样(negative sampling)
-
深度学习的优化方法
https://www.cnblogs.com/GeekDanny/p/9655597.html- SGD&BGD&Mini-BGD
- SGD:算法每读入一个数据就立刻计算损失函数的梯度来更新参数。
- BGD:算法在读取整个数据集后累加来计算损失函数的梯度。
- Mini-BGD:小批量数据进行梯度下降。
- Momentum:更新方向的时候保留之前的方向,增加稳定性还有摆脱局部最优的能力。若当前梯度方向和历史梯度方向一致,则会增强这个梯度的方向,若不一致,则梯度会衰减。
- Adagrad:自适应梯度算法,是一种改进的SGD。能够在训练中自动调整学习率,出现频率较低的参数,使用较大的学习率更新,反之亦然。
- Adam(adaptive moment estimation):利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
- SGD&BGD&Mini-BGD
-
哪些算法可以使用梯度下降法进行求解
分类树、KNN和KMeans不用,其他都需要。
一般线性回归,LR,SVM,神经网络都要使用。 -
GBDT中G是什么含义?如何计算梯度?
- GBDT全称:Gradient Boosting Decision Tree;
- 梯度计算:损失函数对参数求偏导。
-
ROC曲线的含义,与AUC的关系
- ROC曲线的含义:受试者工作曲线,横轴为假正例率,纵轴为真正例率;
- AUC为ROC曲线下面积,表示一个正例、一个负例,预测为正的概率值比预测为负的概率还要大的可能性。
-
如何判断过拟合?
过拟合和欠拟合情况下,学习曲线会有不同形状:
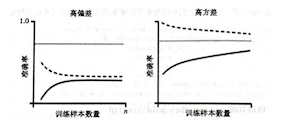
过拟合:随着训练样本的增加,训练集得分和样本集得分还是相差很大;
欠拟合:随着训练样本的增加,训练集和验证集得分收敛,收敛值很接近。 -
偏差和方差的理解
- 偏差:是指预测值和真实值之间的差,偏差越大,预测和真实值之间的差别越大,衡量模型的预测能力。
- 方差:描述预测值的变化范围和离散程度,方差越大,表示预测值的分布越零散,对象是多个模型,使用不同的训练数据训练出的模型差别有多大。
-
Bagging中Bag的含义是什么?
B:Bootstrap,随机有放回的取样;
AG:Aggregating,聚合。 -
代码题:由有序数组构建BST
package qiuzhaoprepare;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
public class Array2BST {
public static void main(String[] args) {
int[]arr={1,2,3,4,5,6};
Array2BST s=new Array2BST();
s.inOrder(s.sortedArrayToBST(arr));
}
public TreeNode buildTree(int[] num,int low,int high){
if(low>high)
return null;
int mid = (low+high+1)/2;
TreeNode node = new TreeNode(num[mid]);
node.left = buildTree(num,low,mid-1);
node.right = buildTree(num,mid+1,high);
return node;
}
public TreeNode sortedArrayToBST(int[] num) {
if(num == null || num.length == 0)
return null;
return buildTree(num,0,num.length-1);
}
public void inOrder(TreeNode root){
if(root!=null){
inOrder(root.left);
System.out.println(root.val);
inOrder(root.right);
}
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









