







 这是一篇关于2020年秋季招聘期间,作者接受小米公司机器学习算法面试的经验分享。面试过程中,面试官询问了逻辑回归的损失函数、过拟合与欠拟合的判断及解决方案,以及L1和L2正则化的概念和作用。面试体验良好,面试官表现专业且幽默。
这是一篇关于2020年秋季招聘期间,作者接受小米公司机器学习算法面试的经验分享。面试过程中,面试官询问了逻辑回归的损失函数、过拟合与欠拟合的判断及解决方案,以及L1和L2正则化的概念和作用。面试体验良好,面试官表现专业且幽默。
铺垫
时间:周四下午2点
形式:牛客远程面试
面试体验:总共面试一小时多,总体给人的感觉就是:准时、认真、耐心、温和、还很幽默,最后还和我说你如果经常刷脉脉怎么还敢投我们公司,自黑了一把(为什么我每次都觉得碰到特别好的呢,哈哈哈)
问题&答案
-
介绍两段项目经历,面试官有很多奇怪的地方,对我提出了疑问,不过都是小事情。
-
LR的损失函数是什么,怎么写,远程面试让我把公式念出来(有点难)
极大似然函数:
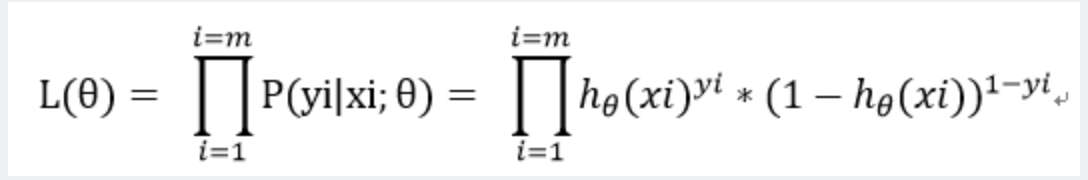
-
过拟合和欠拟合如何判断?有什么解决办法吗?
-
当训练集和测试集的误差收敛但却很高时,为高偏差。
反映到学习曲线上,训练集和验证集的准确率都很低,很可能是欠拟合。
我们可以增加模型参数,比如,构建更多的特征,减小正则项。
此时通过增加数据量是不起作用的(反向思考如何判断模型过拟合还是欠拟合)。 -
当训练集和测试集的误差之间有大的差距时,为高方差。
当训练集的准确率比其他独立数据集上的测试结果的准确率要高时,一般都是过拟合。
反映到学习曲线上,训练集和验证集的准确率相差太多,应该是过拟合。
我们可以增大训练集,降低模型复杂度,增大正则项,或者通过特征选择减少特征数。
-
-
L1正则和L2正则介绍一下,然后为什么二者能产生这样的效果?你画的这个图中为什么这个矩形要这么画呢?
- L1正则是参数的绝对值之和,使一部分参数变为0,可以起到特征筛选的作用;
- L2正则是参数的平方和(注意⚠️:L2范数是参数的平方和再开根号),使参数变为很小的值。
- 为什么会产生这样的作用:

- 注意矩形和正则项系数的关系
正则项系数lambda越小,这个矩形区域越大,这时欠拟合时,应该把lambda调小;
正则项系数lambda越大,这个矩形区域越小,这时过拟合时,应该把lambda调大。
- 注意矩形和正则项系数的关系
-
算法题:求出数组中的K个最小数字
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









