







 本文详细指导如何配置本地环境,包括使用virtualenv创建Python环境并安装依赖。深入解析NLP中的关键概念,如信息抽取、自动文摘、语音识别、Transformer模型,以及传统与深度学习方法的对比。涵盖自然语言处理任务如文本分类、序列标注、问答和生成,以及Transformer模型的发展与应用实例。
本文详细指导如何配置本地环境,包括使用virtualenv创建Python环境并安装依赖。深入解析NLP中的关键概念,如信息抽取、自动文摘、语音识别、Transformer模型,以及传统与深度学习方法的对比。涵盖自然语言处理任务如文本分类、序列标注、问答和生成,以及Transformer模型的发展与应用实例。
1 环境配置
1.1 下载项目文件
直接点击Download ZIP即可下载全部内容。
解压后示意图:

1.2 配置本项目本地运行环境
1.2.1 本地Typora打开项目文件夹
使用软件Typora打开Markdown文件,对文件进行预览:
1.2.2 本地环境配置(以Win10版本cmd为例)
1.win+R打开cmd,用于安装一个新的python环境和相应的python依赖包,通过virtualenv软件安装python环境到venv文件夹下(virtualenv用于在一台机器上创建多个独立的python运行环境):
virtualenv -p python3 venv[外链图片转存中…(img-R7mlB7Vx-1631723302038)]
3.激活python环境(win10版本不需要source):
conda activate venv
如果没有环境的话就先创建环境:
conda create -n venv python=3.8
4.激活python环境后的Terminal最左边会显示(venv)。最后,安装依赖包:
pip install -r requirements.txt

2 NLP与Transformers
2.1 自然语言处理(Natural Language Processing, NLP)
自然语言处理(Natural Language Processing, NLP)是一种重要的人工智能技术。自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面。
2.2关键概念和技术
2.2.1 信息抽取(IE)
信息抽取是将嵌入在文本中的非结构化信息提取并转换为结构化数据的过程,从自然语言构成的语料中提取出命名实体之间的关系,是一种基于命名实体识别更深层次的研究。信息抽取的主要过程有三步:首先对非结构化的数据进行自动化处理,其次是针对性的抽取文本信息,最后对抽取的信息进行结构化表示。信息抽取最基本的工作是命名实体识别,而核心在于对实体关系的抽取。
2.2.2 自动文摘
自动文摘是利用计算机按照某一规则自动地对文本信息进行提取、集合成简短摘要的一种信息压缩技术,旨在实现两个目标:首先使语言的简短,其次要保留重要信息。
2.2.3 语音识别技术
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术,也就是让机器听懂人类的语音,其目标是将人类语音中的词汇内容转化为计算机可读的数据。要做到这些,首先必须将连续的讲话分解为词、音素等单位,还需要建立一套理解语义的规则。语音识别技术从流程上讲有前端降噪、语音切割分帧、特征提取、状态匹配几个部分。而其框架可分成声学模型、语言模型和解码三个部分。
2.2.4 Transformer 模型
Transformer 模型在2017 年,由Google 团队中首次提出。Transformer 是一种基于注意力机制来加速深度学习算法的模型,模型由一组编码器和一组解码器组成,编码器负责处理任意长度的输入并生成其表达,解码器负责把新表达转换为目的词。Transformer 模型利用注意力机制获取所有其他单词之间的关系,生成每个单词的新表示。Transformer 的优点是注意力机制能够在不考虑单词位置的情况下,直接捕捉句子中所有单词之间的关系。模型抛弃之前传统的encoder-decoder 模型必须结合RNN 或者CNN的固有模式,使用全Attention 的结构代替了LSTM,减少计算量和提高并行效率的同时不损害最终的实验结果。但是此模型也存在缺陷。首先此模型计算量太大,其次还存在位置信息利用不明显的问题,无法捕获长距离的信息。
2.2.5 基于传统机器学习的自然语言处理技术
自然语言处理可将处理任务进行分类,形成多个子任务,传统的机械学习方法可利用SVM(支持向量机模型)、
Markov(马尔科夫模型)、CRF(条件随机场模型)等方法对自然语言中多个子任务进行处理,进一步提高处理结果的精度。
但是,从实际应用效果上来看,仍存在着以下不足:
(1)传统机器学习训练模型的性能过于依赖训练集的质量,需要人工标注训练集,降低了训练效率。
(2)传统机器学习模型中的训练集在不同领域应用会出现差异较大的应用效果,削弱了训练的适用性,暴露出学习方法单一的弊端。若想让训练数据集适用于多个不同领域,则要耗费大量人力资源进行人工标注。
(3)在处理更高阶、更抽象的自然语言时,机器学习无法人工标注出来这些自然语言特征,使得传统机器学习只能学习预先制定的规则,而不能学规则之外的复杂语言特征。
2.2.6 基于深度学习的自然语言处理技术
深度学习是机器学习的一大分支,在自然语言处理中需应用深度学习模型,如卷积神经网络、循环神经网络等,通过对生成的词向量进行学习,以完成自然语言分类、理解的过程。与传统的机器学习相比,基于深度学习的自然语言处理技术具备以下优势:
(1)深度学习能够以词或句子的向量化为前提,不断学习语言特征,掌握更高层次、更加抽象的语言特征,满足大量特征工程的自然语言处理要求。
(2)深度学习无需专家人工定义训练集,可通过神经网络自动学习高层次特征。
2.3 学习资料
2.3.1 自然语言与深度学习的课程
CS224n: 基于深度学习的自然语言处理
Stanford CS 224N | Natural Language Processing with Deep Learning
2.3.2 自然语言处理的书籍
语音和语言处理(第三版)
Speech and Language Processing

2.4 常见的NLP任务
2.4.1 文本分类
(1)简介
1、描述:给定文档p(可能含有标题t),将文档分类为n个类别中的一个或多个
2、应用场景:常见的有垃圾邮件识别,情感分析,关系分类,事件分类等等
3、类型:根据文本长度可以分为:长文本分类,短文本分类;根据标签类别的个数,可以分为二分类,多分类,多标签分类
(2)文本分类任务大致可以分为以下三步:
1、文本预处理:分词、去停用词、归一等等
2、文本表示:将文本表示成向量(计算机可以理解)
3、分类模型构建:分类,svm,textcnn等等
(3)文本预处理
1、分词:一般而言,所有的NLP任务基本上都会做分词,因为词是一个最小的语义单元
2、去停用词:很多词对于分类任务没有效果,所以可以提前去掉,目前一些通用的停用词词典大概有2000个词,主要包括一些副词、形容词以及连接词
3、归一化:把一些数字全部归一为"DIGIT",时间归一为“TIME",url链接归一化"URL",虽然不同的数字代表不同含义,但在很多分类任务而言,其实都一样,这可以减少词典大小,当然也看具体任务,可以自己找些规则出来
4、词性标注:在文本比较短的情况下,单纯的文本信息太少,这种情况下一般会把词性也作为特征输入分类器
2.4.2 序列标注
对文本序列中的token、字或者词进行分类。序列标注的的输入是一个序列,他的输出也是一个序列。一个典型的例子就是词性标注(pos tagging)。在日常中用的词有的是名词,有的是动词,但是动词中还有专有名词,非专有名词等。
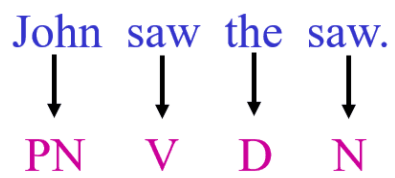
词性标注(pos tagging)对后续的句法分析和词义消歧有用,甚至可以用来抽取一段文字中的关键词。这个过程不是仅仅通过查表的方法就可以得到的,还需要理解整个句子的含义。

2.4.3 问答任务——抽取式问答和多选问答
1、抽取式问答根据问题从一段给定的文本中找到答案,答案必须是给定文本的一小段文字。举例:问题“小学要读多久?”和一段文本“小学教育一般是六年制。”,则答案是“六年”。
2、多选式问答,从多个选项中选出一个正确答案。举例:“以下哪个模型结构在问答中效果最好?“和4个选项”A、MLP,B、cnn,C、lstm,D、transformer“,则答案选项是D。
2.4.4 生成任务——语言模型、机器翻译和摘要生成
根据已有的一段文字生成一个字通常叫做语言模型,根据一大段文字生成一小段总结性文字通常叫做摘要生成,将源语言比如中文句子翻译成目标语言比如英语通常叫做机器翻译。如摘要,对话生成,标题生成,代码生成等。
2.5 Transformer的兴起
2017年,Attention Is All You Need论文首次提出了Transformer模型结构并在机器翻译任务上取得了The State of the Art(SOTA, 最好)的效果。2018年,BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding使用Transformer模型结构进行大规模语言模型(language model)预训练(Pre-train),再在多个NLP下游(downstream)任务中进行微调(Finetune),一举刷新了各大NLP任务的榜单最高分,轰动一时。2019年-2021年,研究人员将Transformer这种模型结构和预训练+微调这种训练方式相结合,提出了一系列Transformer模型结构、训练方式的改进(比如transformer-xl,XLnet,Roberta等等)。
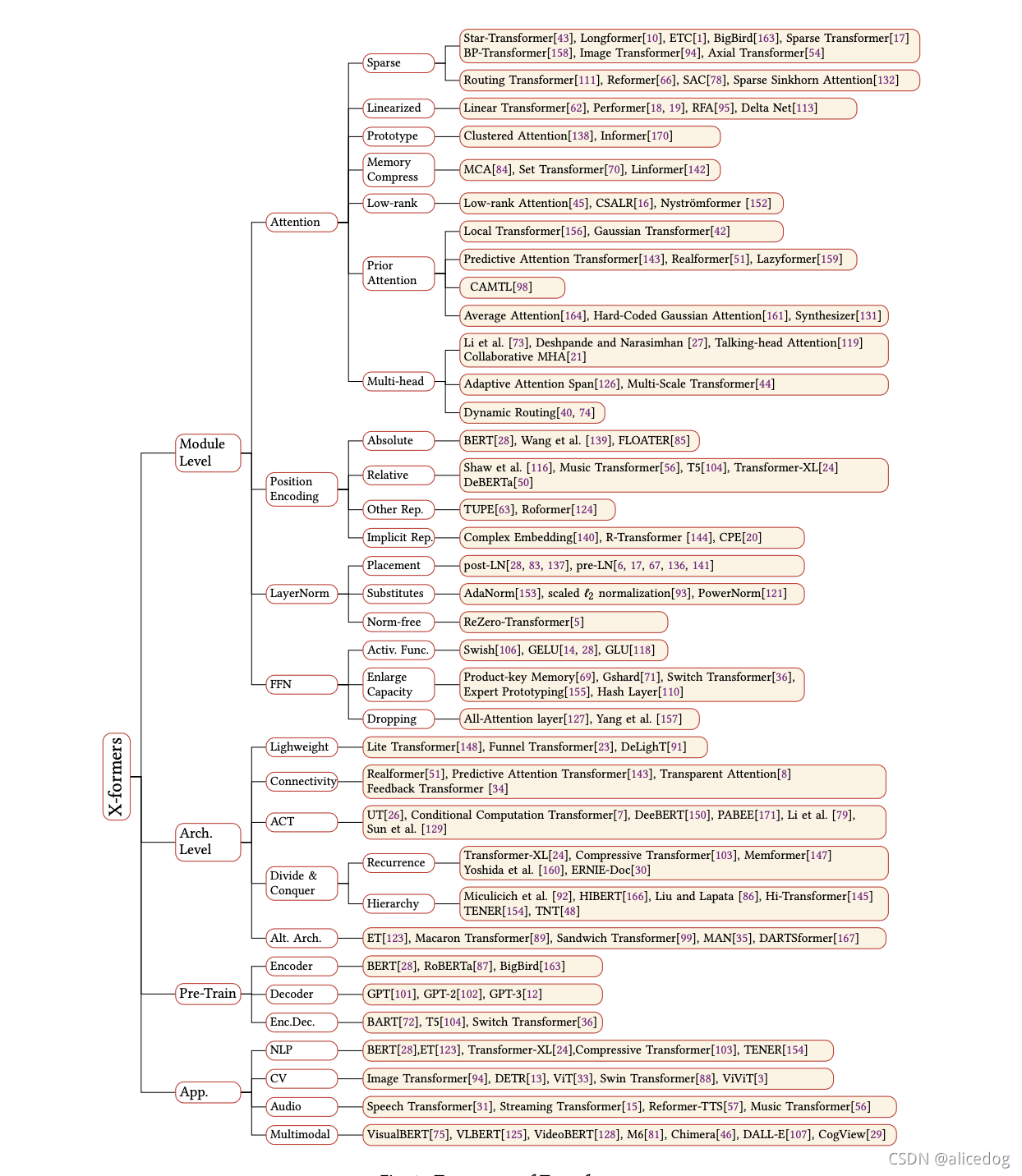
图:各类Transformer改进,来源:A Survey of Transformers
另外,由于Transformer优异的模型结构,使得其参数量可以非常庞大从而容纳更多的信息,因此Transformer模型的能力随着预训练不断提升,随着近几年计算能力的提升,越来越大的预训练模型以及效果越来越好的Transformers不断涌现,简单的统计可以从下图看出:
尽管各类Transformer的研究非常多,总体上经典和流行的Transformer模型都可以通过HuggingFace/Transformers, 48.9k Star获得和免费使用,为初学者、研究人员提供了巨大的帮助。
可以通过huggingface/transformers代码库进行相关学习:
NLP中的预训练+微调的训练方式推荐阅读:
2021年如何科学的“微调”预训练模型?
以及


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









