



基于树莓派和Python的家居安全语音识别系统
1. 引言
有多种技术可用于家庭自动化。在这些技术中,本系统将采用说话人识别。该系统会检查说话人提供的音频输入是否与系统数据库中已注册的样本相匹配,并据此允许或拒绝访问。
该系统适用于无法使用其他生物特征扫描(如人脸识别、虹膜或指纹识别)的场景。为实现实时识别,系统部署在树莓派平台[2],上——这是由树莓派基金会开发的一款紧凑且经济实惠的单板计算机。我们使用的是树莓派3B型号,它比其前代产品速度更快、性能更强。树莓派运行基于Linux内核的操作系统Raspbian。Python是一种开源编程语言,用于实现系统的算法[ 5 ]。
说话人识别主要有两种技术:说话人验证或认证和说话人辨认。
当说话人声称自己是某一特定身份时,使用其语音进行验证以确认该声明,这一过程称为验证。另一方面,辨认用于确定未知说话人的身份。我们的系统将采用说话人验证。
说话人识别系统包含两个阶段:训练和测试。训练阶段包括通过特征提取从录制的说话人语音中提取模板。测试阶段则包括将一个语句与系统数据库中已有的语音模板进行比较。
2. 系统需求
由于犯罪率不断上升,人们对可靠且准确的安全系统的需求日益增长。现有的已投入使用系统通常通过有线网络或传感器实现。
我们提出的系统可替代这些高度依赖有线连接的系统。通过使用说话人识别技术,我们旨在减少身体障碍者所需付出的努力和不便,因为该系统减少了用户与系统之间的交互需求。我们提出的系统适用于其他生物特征识别技术存在局限性的环境。
3. 描述
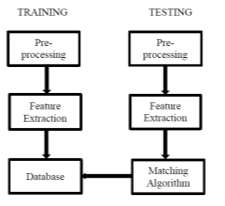
所提出系统的框图如下面的图1所示。

系统包括两个阶段:训练阶段和测试阶段。训练阶段包含预处理、特征提取和数据库生成。测试阶段包含相同的预处理和特征提取技术,并将通过匹配算法将测试阶段的输入音频信号与数据库中的模板进行比较。
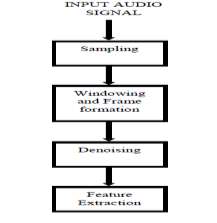
预处理模块(如图2所示)包括采样、加窗与帧形成以及去噪。预处理有助于提高后续特征提取和匹配阶段的效率和准确性,从而提升整个系统的性能。

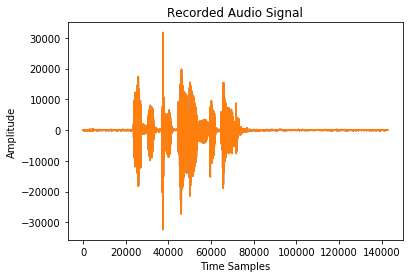
输入到系统中的输入音频信号如图3所示。
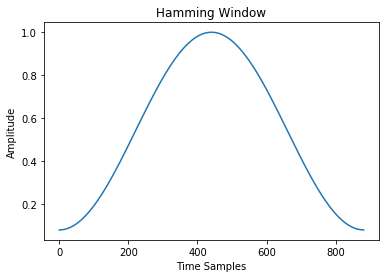
连续时间输入音频信号将被采样和量化,以使其在性质上变为离散的。窗函数(如图4所示)将对信号进行缩放。在将输入划分为一系列部分信号后,将其与汉明窗相乘(如图5所示),以将其打包成帧。
输入信号可能受到麦克风相关噪声、环境和电气噪声的影响而受损。通过去噪和语音增强来减少噪声,从而提高语音信号的质量。去噪的挑战在于消除外部噪声的同时不破坏语音输入中的低强度分量。这些去噪后的样本将被送入特征提取模块。
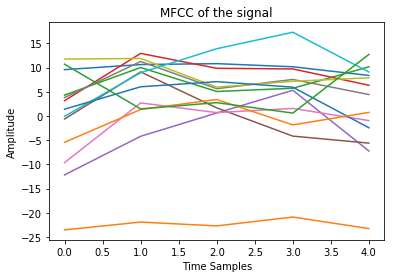
特征提取是从加窗并增强的信号中提取描述性特征。由于语音具有独特性和个体性,每个语音样本的特征将是独特的,从而可以识别说话人。理想情况下,在此过程中显著成分将被强调,而其他所有信息将被抑制。可以使用多种特征提取技术,如梅尔频率倒谱系数(MFCC)、线性预测编码(LPC)、共振峰、基音[1]等。在这些技术中,我们的设计采用MFCC分析[4]。提取出的特征模板存储在数据库中。音频输入某一段的MFCC系数如图6所示。
3.1. 树莓派
树莓派3B型号由多个功能模块组成,如图7所示。其中系统将使用电源、SD卡插槽、USB端口和液晶显示器接口[ 2 ]。
4. 系统开发
系统的结构细节如图8所示。
麦克风为系统提供音频输入。片上计算机实现算法[3]。SD卡作为系统的数据和指令存储。输出部分由液晶显示器组成,显示是否允许用户访问。
5. 结论
该系统采用树莓派设计用于说话人识别,是家庭安防系统的原型。基于说话人识别的家庭安防系统尚未像其他生物特征安全系统那样广泛应用。该系统不仅可用于身体障碍者,还能简化我们生活的基本功能。由于采用了MFCC分析,系统的准确性和效率更优。该系统具有低成本、易于操作和用户友好的特点。
通过结合物联网(IoT)等其他先进技术,该系统可适应其他动态环境。


















 1387
1387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









