







 本文分享了使用Python和BeautifulSoup库爬取优快云网站文章的详细过程,包括环境配置、代码实现及排序输出,适合初学者实践。
本文分享了使用Python和BeautifulSoup库爬取优快云网站文章的详细过程,包括环境配置、代码实现及排序输出,适合初学者实践。
从基础开始制作简单的python爬虫
本学期python课要求我们自己制作一个爬虫文件,能够爬取网页上的内容.在一番思考,并且考虑到自己的学习情况之后,我决定制作爬取知乎网页回答的爬虫,但是在经过很多次失败之后,我发现知乎大概有反爬虫机制,并且是动态网页,需要用到json等知识,在失败很多次之后,我又退而求其次,决定制作爬取优快云网站的爬虫,并且在之后勉强完成.
环境配置:
我们选用方便好用的pycharm,也有人选择使用python自带的idle,这个我感觉不怎么好用,所以推荐pycharm.
Pycharm的安装教程:
https://blog.youkuaiyun.com/pdcfighting/article/details/80297499
使用库:
没有的库使用pip进行下载就可以了
requests库,来爬取网页信息
beautifulsoup库来将爬取信息解析
re和time将信息key(排序用)值精确查找
制作思路:
- 通过指定url连接爬取网页(优快云查找请求就是在q=后面加上查找字符串)
url="https://so.youkuaiyun.com/so/search/s.do?p="+str(page)+"&q="+question+"&t=blog&domain=&o=&s=&u=&l=&f=&rbg=0"
- 将爬取到的网页信息使用beautifulsoup解析后,写入到txt文件
def getmessage(soup):
#soup的find_all下列函数的意思是寻找所有class为"search-list-con"的div的内容
datas=soup.find_all("div",{"class":"search-list-con"})
for data in datas:
messages=data.find_all("dl",{"class":"search-list J_search"})
#分条进行解析
for message in messages:
singleMessage = []
if message.find("span",{"class":"author"})==None:
continue
singleMessage.append(message.find("div",{"class":"limit_width"}).text.replace('\n', '').replace('\xa0-\xa0优快云博客',''))
singleMessage.append(message.find("span",{"class":"author"}).text.replace('作者:','').split())
singleMessage.append(message.find("span",{"class":"date"}).text.split())
singleMessage.append(message.find("span",{"class":"link"}).text.split())
singleMessage.append(message.find("span",{"class":"down fr"}).text.split())
for i in range(len(singleMessage)):
#写入txt文件
f.write(str(singleMessage[i]))
f.write('\n')
- 重新读取txt文件将其内容通过特定Key函数进行排序
def SortRead(item):
key=re.findall("\d+次阅读",item)[0].replace('次阅读','')
return int(key)
def SortDate(item):
key=re.findall("日期:\d+-\d+-\d+",item)[0].replace('日期:','')
t = time.mktime(time.strptime(key, '%Y-%m-%d'))
return t
#重新读取的每一条item都是这样的
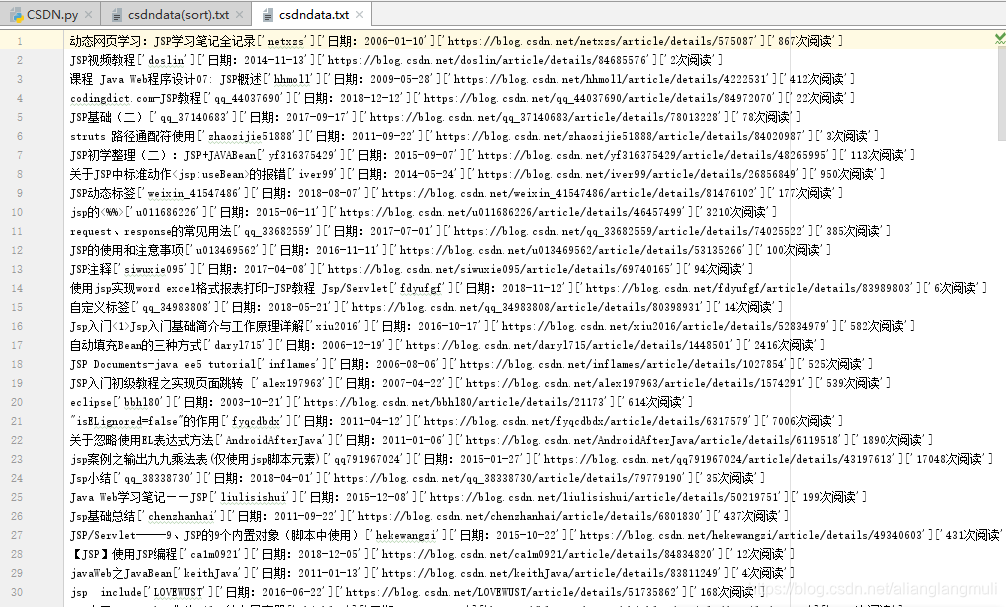
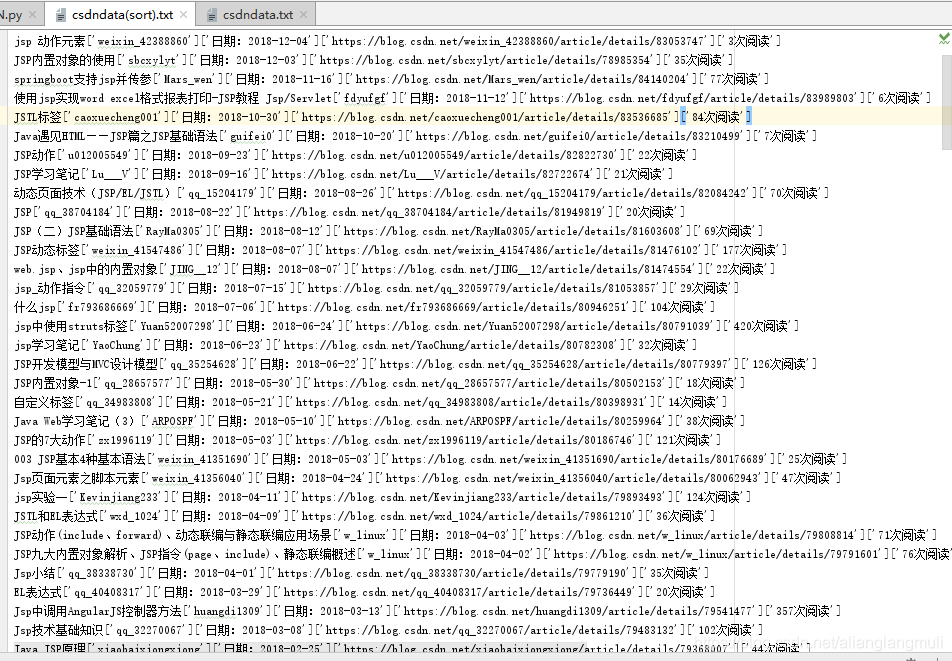
#Qt安装与helloworld程序['u013752202']['日期:2015-05-13']['https://blog.youkuaiyun.com/u013752202/article/details/45695033']['673次阅读']
#所以我使用re通过正则表达式将想要的"673次阅读"或"2015-05-13"找出来
#再将其转化为能作为key值排序的值
#673直接转化为int就可以了,日期通过使用time库的函数,也能成功转换
- 输出排名前20的问题
with open("csdndata(sort).txt", "w",encoding='utf-8') as f2:
for item in sorted(list,key=SortDate,reverse=True):
f2.writelines(item)
if i<20:
print(item)
i=i+1
f2.close()
print("以上排名前20回答:")
原理很简单只是在排序过后输出前20条好了
5. 将排序结束后的内容储存到另一个文件
其实在上条的代码中也已经写入了
完整代码:
import requests
from bs4 import BeautifulSoup
import re
import time
f = open('csdndata.txt','w',encoding='utf-8')
def gethtmltext(url):
try:
read=requests.get(url,timeout=30)
read.raise_for_status()
read.encoding="utf-8"
return read.text
except:
print("error")
return ""
def getmessage(soup):
datas=soup.find_all("div",{"class":"search-list-con"})
for data in datas:
messages=data.find_all("dl",{"class":"search-list J_search"})
for message in messages:
singleMessage = []
if message.find("span",{"class":"author"})==None:
continue
singleMessage.append(message.find("div",{"class":"limit_width"}).text.replace('\n', '').replace('\xa0-\xa0优快云博客',''))
singleMessage.append(message.find("span",{"class":"author"}).text.replace('作者:','').split())
singleMessage.append(message.find("span",{"class":"date"}).text.split())
singleMessage.append(message.find("span",{"class":"link"}).text.split())
singleMessage.append(message.find("span",{"class":"down fr"}).text.split())
for i in range(len(singleMessage)):
f.write(str(singleMessage[i]))
f.write('\n')
def SortRead(item):
key=re.findall("\d+次阅读",item)[0].replace('次阅读','')
# print(int(key))
return int(key)
def SortDate(item):
key=re.findall("日期:\d+-\d+-\d+",item)[0].replace('日期:','')
t = time.mktime(time.strptime(key, '%Y-%m-%d'))
return t
def main():
question=input("请输入要搜索的问题: ")
sortway=input("按日期排序按1,按阅读量排序按2:")
print("请等待...")
for page in range(1,21):
url="https://so.youkuaiyun.com/so/search/s.do?p="\
+str(page)+"&q="\
+question+\
"&t=blog&domain=&o=&s=&u=&l=&f=&rbg=0"
html=gethtmltext(url)
soup = BeautifulSoup(html, "html.parser")
getmessage(soup)
f.close()
if sortway=='1':
list = []
i=0
with open('csdndata.txt', 'r',encoding='utf-8') as f2:
for line in f2:
list.append(line)
with open("csdndata(sort).txt", "w",encoding='utf-8') as f2:
for item in sorted(list,key=SortDate,reverse=True):
f2.writelines(item)
if i<20:
print(item)
i=i+1
f2.close()
print("以上排名前20回答:")
if sortway=='2':
list = []
i=0
with open('csdndata.txt', 'r',encoding='utf-8') as f2:
for line in f2:
list.append(line)
with open("csdndata(sort).txt", "w",encoding='utf-8') as f2:
for item in sorted(list,key=SortRead,reverse=True):
f2.writelines(item)
if i<20:
print(item)
i=i+1
f2.close()
print("以上排名前20回答:")
main()
效果图



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









