



目录
1.reactor核心思想
- 使用一个单线程或少量线程来监听多个输入源(如网络连接)。
- 当某个输入源就绪(例如有数据可读),系统会通知对应的处理器进行处理。
- 避免为每个连接创建一个线程,从而节省资源并提高效率。
例子:
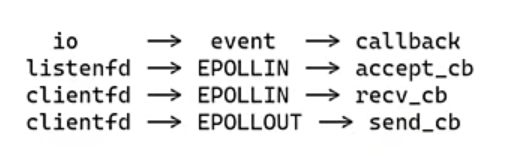
从例子可以知道不同的io可以对应相同的event,所以我们可以从之前对io的管理转换为对事件的管理。
1.1reactor主要分为两点:
1.event与callback的匹配。
2.每个io与之对应的参数。
优势:不同事件做不同处理、I/O 解耦、事件与业务分离
1.2事件与处理逻辑解耦:
在epoll 用法中,事件处理逻辑(比如 accept 建立新连接、recv 接收数据、send 发送数据)与 epoll 核心事件循环紧密耦合在同一个 main 函数里 —— 当 epoll 检测到 EPOLLIN 事件时,必须在循环内部通过硬编码判断:触发事件的是监听套接字(此时执行 accept),还是已连接的客户端套接字(此时执行 recv),所有逻辑混杂在一起,可读性和可维护性极差。
而 reactor 模式通过一个 struct conn 结构体,对每个连接的关键信息进行统一封装:既包含连接对应的文件描述符(fd)、数据读写所需的缓冲区,也包含与该连接绑定的回调函数(如 recv_callback 接收回调、send_callback 发送回调等)。核心思路是将 “事件类型” 与 “对应的业务处理逻辑” 提前绑定,epoll 的事件循环只需专注于 “检测事件” 这一核心职责:当某个事件触发时,无需在循环中硬编码判断逻辑,直接根据事件类型(如 EPOLLIN、EPOLLOUT),调用该连接 struct conn 中预设的回调函数即可。
这种设计彻底实现了 “事件触发” 与 “业务处理” 的解耦:事件循环只负责事件的监听和分发,不关心具体的业务逻辑;而业务处理逻辑(accept、recv、send 等)被封装在独立的回调函数中,与事件循环分离,代码结构更清晰、扩展性更强。
1.3状态管理更清晰
在原始 epoll 用法中,客户端连接的缓冲区(buffer)大多是临时变量—— 要么在事件循环里临时定义,要么在 recv/send 这类处理函数中局部声明。这种设计的核心缺陷是连接状态完全无法持久化,本质上是把 “连接的 IO 状态” 和 “单次事件处理的生命周期” 绑在了一起,完全没考虑 IO 操作的 “非原子性”。
要知道,网络 IO 本身就存在不确定性:比如发送数据时,内核发送缓冲区可能突然满了,一次 send 调用根本发不完所有数据;接收数据时,也可能因为网络分片、数据未完全到达等原因,一次 recv 只能拿到 “半包” 数据。但临时 buffer 的生命周期只限于当前代码块 —— 事件循环走完一轮、处理函数执行结束,临时 buffer 就会被系统回收,里面未发完的半包数据、未拼接完整的半包消息,都会直接丢失。这不仅导致数据传输异常,更让粘包、半包处理变成 “不可能完成的任务”—— 连基础的中间状态都存不住,后续根本没法拼接完整消息、重试发送剩余数据。
而 reactor 模式的核心优势,在于它为每个连接建立了 “专属状态容器”—— 通过 struct conn 结构体,把连接的 “身份标识(fd)、IO 缓冲区、状态元数据” 打包成一个整体,让状态和连接的生命周期强绑定:只要连接没断开,struct conn 就不会被释放,里面的读缓冲区(rbuffer)、写缓冲区(wbuffer)以及对应的已用长度(rlength、wlength),就能一直保持有效,实现了状态的 “持久化”。
这种设计背后,其实是对 “网络 IO 本质” 的深刻理解 —— 网络 IO 不是 “一次调用就能完成” 的原子操作,而是 “多次事件触发 + 逐步完成” 的过程,必须有持续的状态存储来衔接这些碎片化的步骤。具体来说:
- 处理半包接收时:第一次 recv 拿到部分数据,直接存入该连接的 rbuffer 并更新 rlength,后续再次触发 EPOLLIN 事件时,新接收的数据会追加到 rbuffer 末尾,直到凑够完整消息再进行业务处理 —— 这相当于给每个连接配了一个 “专属消息暂存区”,不用再担心中间数据丢失;
- 处理半包发送时:一次 send 没发完的数据,会留在 wbuffer 中,通过 wlength 记录剩余长度,之后只需要监听 EPOLLOUT 事件(内核发送缓冲区空闲时触发),就能从 wbuffer 中读取剩余数据继续发送,直到全部发完 —— 这相当于给每个连接配了一个 “发送等待队列”,避免了数据丢失和重复发送。
除此之外,这种状态管理方式还让代码逻辑更 “可控”:每个连接的 IO 状态(比如当前读了多少数据、还有多少数据没发)都集中在 struct conn 里,不用再通过全局变量、临时参数传递来追踪状态,排查问题时也能直接定位到具体连接的缓冲区数据,大大降低了复杂场景的调试难度。
1.4代码判断细节
if(events[i].events & EPOLLIN){
conn_list[connfd].r_action.recv_callback(connfd);
}
if(events[i].events & EPOLLOUT){
conn_list[connfd].send_callback(connfd);
}
为什么这段是两个if而不是elseif呢?
因为同一个fd在同一时间可能既有可读事件也有可写事件,两种事件都需要判断。
2..整个reactor工作流程:
1. 初始化:注册监听,绑定行为
- 创建监听套接字(
sockfd),绑定端口并开始监听。 - 初始化
epoll实例(epfd),作为事件多路复用的核心。 - 将监听套接字加入 epoll,关注
EPOLLIN事件(有新连接到来)。 - 关键一步:为该 socket 绑定回调函数
accept_cb—— 即“一旦可读,就执行 accept”。
2. 事件循环:统一分发,按需响应
- 调用
epoll_wait()阻塞等待,直到任意 fd 上有事件就绪。 - 遍历返回的就绪事件列表,获取每个触发事件的
fd和事件类型(EPOLLIN/EPOLLOUT)。 - 根据
fd找到对应的连接对象(如conn_list[fd]),调用其预设的回调:- 若是监听
fd+EPOLLIN→ 执行accept_cb - 若是客户端
fd+EPOLLIN→ 执行recv_cb - 若是客户端
fd+EPOLLOUT→ 执行send_cb
- 若是监听
3. 动态调整:状态驱动,灵活切换
- 在处理完一次操作后,通过
set_event(fd, new_events, 0)修改 epoll 关注的事件:recv_cb读取请求后 → 改为监听EPOLLOUT,准备发送响应;send_cb发送完成或出错后 → 改回监听EPOLLIN,继续等待下一次请求;
- 使用
EPOLL_CTL_MOD实现事件的实时更新,确保只在合适时机被唤醒。

















 1663
1663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









