



今天真是服了,AI 居然敢嘲笑我是牛马,还直接甩了张大图到我脸上。
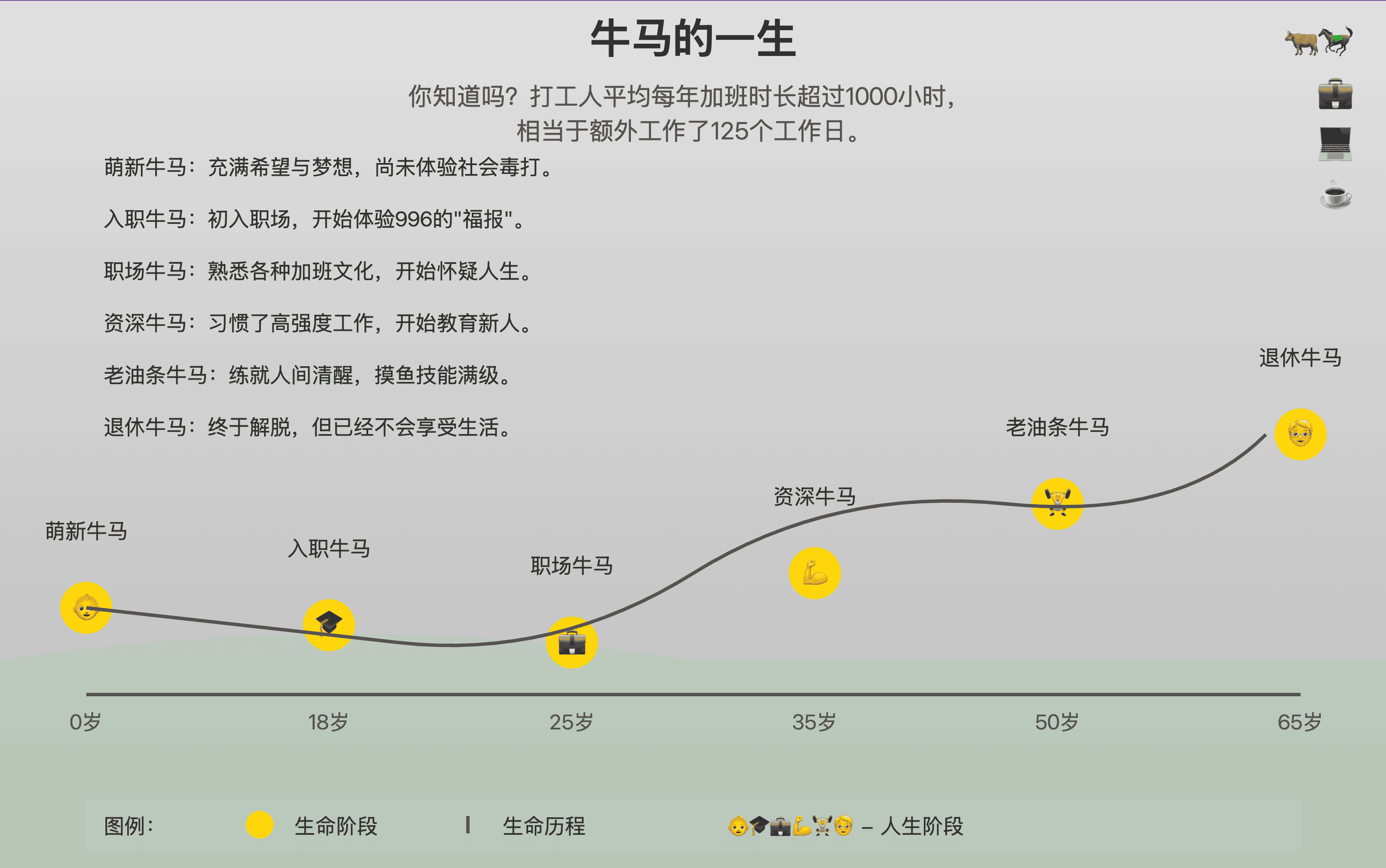
看来我的人生在 AI 眼中就是个笑话,从 “初级牛马” 一路升级到 “资深牛马”。真是谢谢你啊,AI 老师!
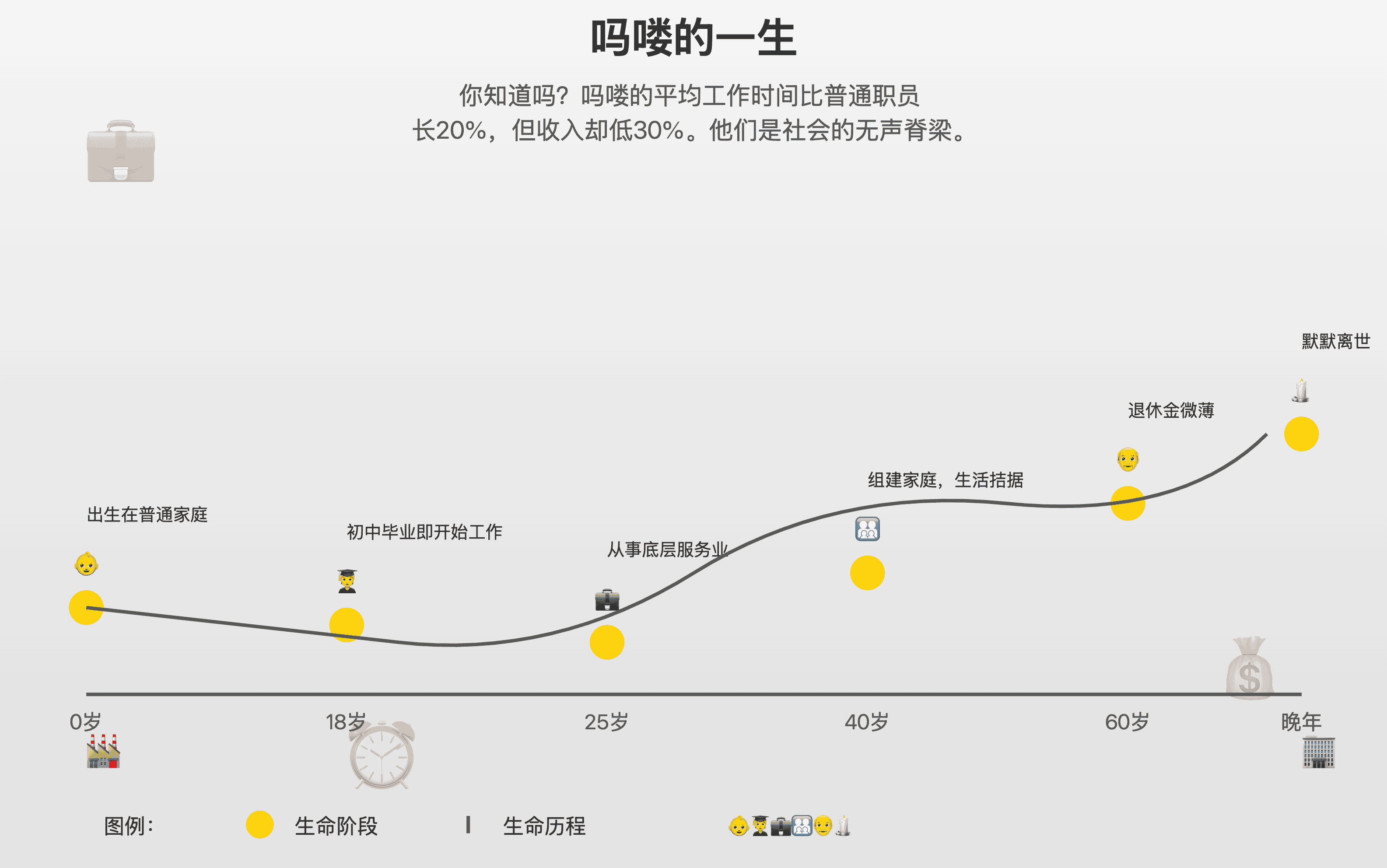
但等等,这剧本还没完!AI 显然觉得光嘲笑我不够过瘾,还要顺带 diss 我的朋友,说他是吗喽。哦,原来在 AI 眼中,我们都是 “低收入” 的代名词啊。
等等,最后怎么还 “默默离世” 了??
好吧,既然已经被 AI 如此 “精准” 地刻画,我们不妨来看看它是怎么创作出这么一幅 “传世佳作” 的。
要想让 AI 生成这种图,其实很简单,只需要一个 Prompt 就行了,内容如下:
;; 提示词:动物的一生
;; 作者:空格 zephyr
(defun 动物生命周期 ()
"生成动物的生命周期SVG图表和描述"
(lambda (主题)
(let* ((生命阶段 (获取生命阶段 主题))
(科普数据 (获取科普数据 主题))
(背景样式 (设计背景 主题))
(时间轴 (创建时间轴 主题))
(阶段emoji (选择阶段emoji 主题))
(装饰emoji (选择装饰emoji 主题))
(副标题 (生成副标题 主题 科普数据)))
(创建优化SVG图表 主题 生命阶段 科普数据 背景样式 时间轴 阶段emoji 装饰emoji 副标题))))
(defun 获取生命阶段 (主题)
"获取主题的主要生命阶段"
(case 主题
(蝉 '("卵" "若虫期(地下)" "成虫期"))
(鲸鱼 '("胎儿期" "幼年期" "青年期" "成年期" "老年期"))
(长颈鹿 '("新生期" "幼年期" "青年期" "成年期" "老年期"))
(t '("初期" "成长期" "成熟期" "衰老期"))))
(defun 获取科普数据 (主题)
"获取主题的科普数据列表"
(case 主题
(蝉 '(("卵在树枝中孵化6-10周,每窝可产200-600颗卵。"
"若虫在地下生活多年,吸食树根汁液生存。"
"若虫经历5次蜕皮,体型可增大20倍。"
"最后一次蜕皮后钻出地面,变为成虫。"
"成虫期仅4-6周,专注于繁衍后代和鸣叫。")
"蝉的地下潜伏期长达17年,成虫仅存活4-6周,鸣叫声可达120分贝,相当于飞机起飞的噪音。"))
(鲸鱼 '(("蓝鲸胎儿每天增重90公斤,出生时重达2.5吨,长7米。"
"幼鲸每天喝380升奶,7个月增重30吨。"
"青年蓝鲸可潜水200米深,屏息长达40分钟。"
"成年蓝鲸长30米,重190吨,一天吃4吨磷虾。"
"最长寿蓝鲸年龄可达110岁,终生可游13次地球赤道距离。")
"蓝鲸是地球上最大的动物,心脏重达600公斤,舌头重如一头大象,叫声可传播1600公里。"))
(t '(("阶段1的数据描述"
"阶段2的数据描述"
"阶段3的数据描述"
"阶段4的数据描述"
"阶段5的数据描述")
"通用主题的有趣数据描述"))))
(defun 设计背景 (主题)
"根据主题设计适合的背景"
(case 主题
(蝉 '(渐变 "E6F3FF" "B3E5FC" 土地))
(鲸鱼 '(渐变 "E3F2FD" "90CAF9" 海洋))
(长颈鹿 '(渐变 "FFF8E1" "FFE0B2" 草原))
(t '(渐变 "F5F5F5" "E0E0E0" 通用))))
(defun 创建时间轴 (主题)
"创建主题生命周期的时间轴"
(case 主题
(蝉 '("0年" "4年" "8年" "12年" "16年" "17年"))
(鲸鱼 '("0年" "10年" "25年" "50年" "75年" "100年"))
(长颈鹿 '("0月" "6月" "2年" "4年" "15年" "25年"))
(t '("初期" "成长期" "成熟期" "后期" "衰老期"))))
(defun 选择阶段emoji (主题)
"选择与生命阶段相关的emoji"
(case 主题
(蝉 '("🥚" "🐛" "🦟" "🎵"))
(鲸鱼 '("🤰" "🍼" "🏊" "🐋" "👵"))
(长颈鹿 '("👶" "🐕" "🏃" "🦒" "👵"))
(t '("🌱" "🌿" "🌳" "🍂"))))
(defun 选择装饰emoji (主题)
"选择与主题相关的装饰emoji"
(case 主题
(蝉 '("🌳" "🍃" "🌿" "🍂"))
(鲸鱼 '("🌊" "🐠" "🦈" "🐙"))
(长颈鹿 '("🌴" "🌿" "🦓" "🦁"))
(t '("🌱" "🌳" "🍃" "🌞"))))
(defun 生成副标题 (主题 科普数据)
"根据科普数据生成副标题"
(format "你知道吗?%s" (第二个元素 科普数据)))
(defun 创建优化SVG图表 (主题 生命阶段 科普数据 背景样式 时间轴 阶段emoji 装饰emoji 副标题)
"创建优化的生命周期SVG图表"
(let ((svg-template
"<svg xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 800 500\">
<!-- 渐变背景 -->
<defs>
<linearGradient id=\"bgGradient\" x1=\"0%\" y1=\"0%\" x2=\"0%\" y2=\"100%\">
<stop offset=\"0%\" style=\"stop-color:#{背景颜色1};stop-opacity:1\" />
<stop offset=\"100%\" style=\"stop-color:#{背景颜色2};stop-opacity:1\" />
</linearGradient>
</defs>
<rect width=\"100%\" height=\"100%\" fill=\"url(#bgGradient)\" />
<!-- 主题相关背景装饰 -->
{背景装饰)
<!-- 标题和副标题 -->
<text x=\"400\" y=\"30\" text-anchor=\"middle\" class=\"title\" fill=\"#333333\">{主题}的一生</text>
<text x=\"400\" y=\"60\" text-anchor=\"middle\" class=\"subtitle\" fill=\"#555555\">
<tspan x=\"400\" dy=\"0\">{副标题_第一行}</tspan>
<tspan x=\"400\" dy=\"20\">{副标题_第二行}</tspan>
</text>
<!-- 时间轴 -->
<line x1=\"50\" y1=\"400\" x2=\"750\" y2=\"400\" stroke=\"#555555\" stroke-width=\"2\" />
{时间标签}
<!-- 生命阶段 -->
{生命阶段标签}
<!-- 数据点和科普信息 -->
{数据点和科普信息}
<!-- 曲线连接 -->
<path d=\"M50,350 Q140,360 230,370 T400,330 T580,290 T730,250\" fill=\"none\" stroke=\"#555555\" stroke-width=\"2\"/>
<!-- 图例 -->
<rect x=\"50\" y=\"460\" width=\"700\" height=\"30\" fill=\"rgba(255,255,255,0.05)\"/>
<text x=\"60\" y=\"480\" class=\"legend-text\" fill=\"#333333\">图例:</text>
<circle cx=\"150\" cy=\"475\" r=\"8\" fill=\"#FFD700\"/>
<text x=\"170\" y=\"480\" class=\"legend-text\" fill=\"#333333\">生命阶段</text>
<line x1=\"270\" y1=\"470\" x2=\"270\" y2=\"480\" stroke=\"#555555\" stroke-width=\"2\"/>
<text x=\"290\" y=\"480\" class=\"legend-text\" fill=\"#333333\">生命历程</text>
<text x=\"420\" y=\"480\" class=\"legend-text\" fill=\"#333333\">{图例emoji}</text>
<!-- 底部装饰Emoji -->
{底部装饰Emoji}
</svg>"))
(填充优化SVG模板 svg-template 主题 生命阶段 科普数据 背景样式 时间轴 阶段emoji 装饰emoji 副标题)))
(defun start ()
(print "请输入您想了解的生命主题(如:蝉、鲸鱼、长颈鹿等):")
(let ((用户输入 (read)))
(优化生命周期生成器 用户输入)))
;; 运行规则
;; 1. 启动时运行 (start) 函数
;; 2. 根据用户输入的主题,生成对应的生命周期SVG图表和描述
;; 3. 输出应包括优化后的SVG图表和相关的文字说明,重点突出科学数据和有趣事实这个提示词的功能就是科普动物的生命周期,并一句话分享冷知识,意想不到的动物的另一面。
很明显,这位作者的提示词模仿了李继刚老师的提示词风格,使用的是 Lisp 伪代码。
但光有提示词还不行,因为只有 Claude Artifact 才能直出 SVG 图片的预览,别的平台只能输出 SVG 代码,没办法直接预览图片。
下面我来教大家如何使用 FastGPT 工作流复现上述效果。
FastGPT 地址:https://tryfastgpt.ai
需要纵云梯访问!
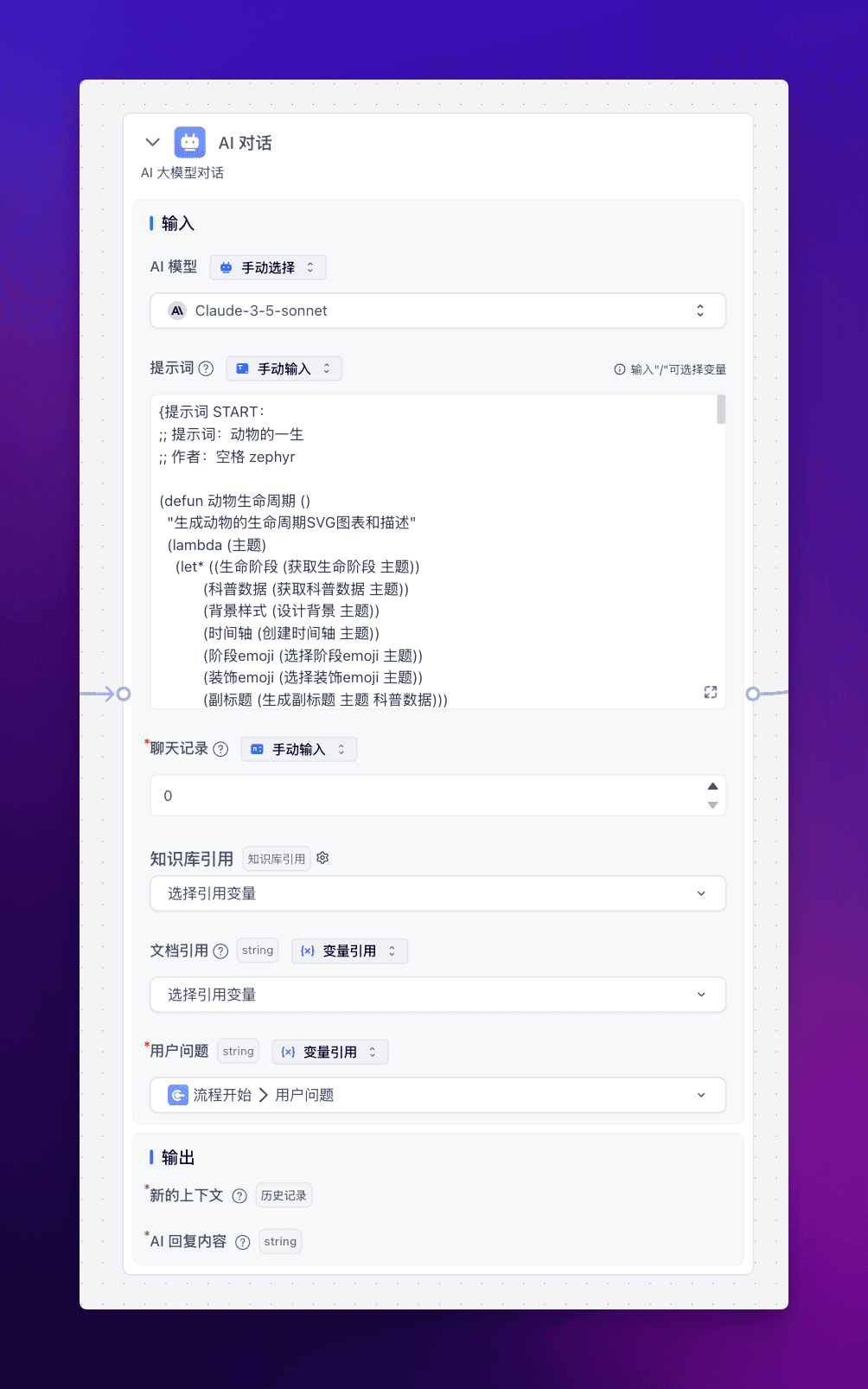
1️⃣ 首先接入 AI 对话节点,模型选择 Claude 3.5。
2️⃣ 接下来接到代码运行节点,这段代码的功能是将 svg 代码块中的内容提取出来,以便后续对其进行格式化输出。
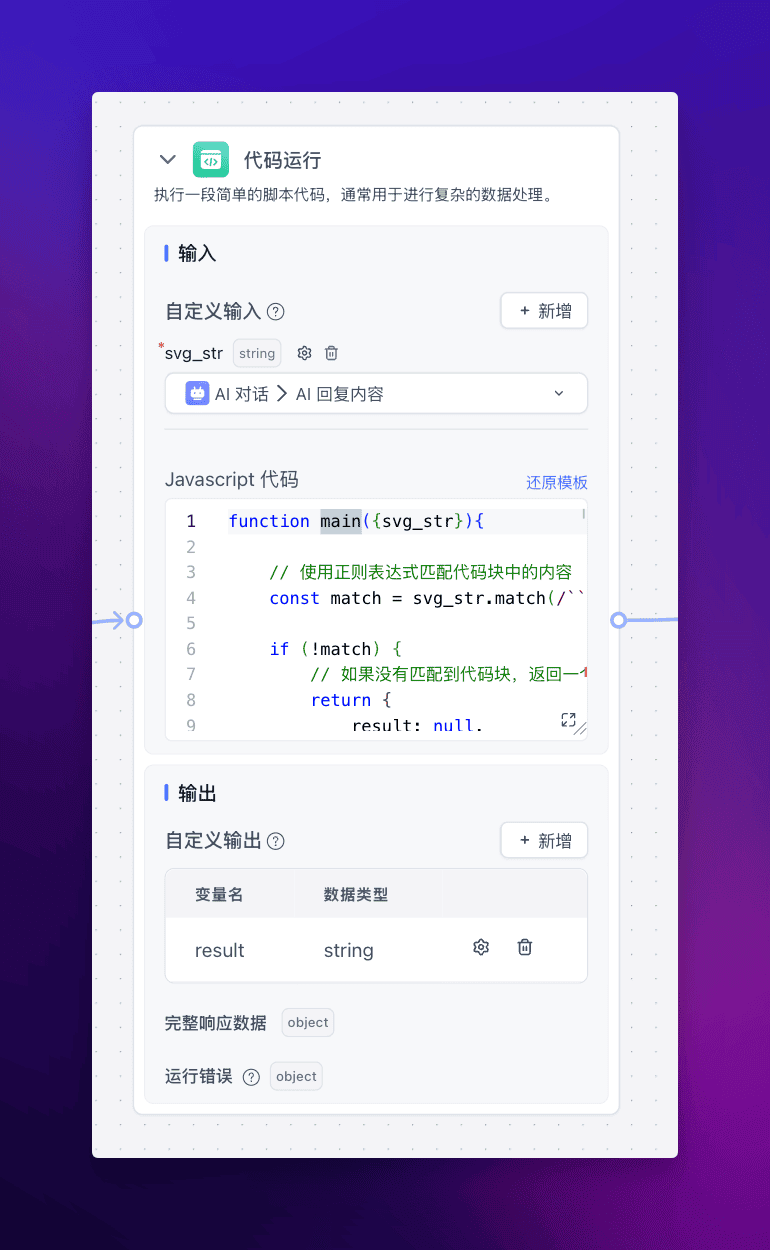
代码内容如下:
function main({svg_str}){
// 使用正则表达式匹配代码块中的内容
const match = svg_str.match(/```[\w]*\n([\s\S]*?)```/);
if (!match) {
// 如果没有匹配到代码块,返回一个错误信息或空结果
return {
result: null,
error: "未找到有效的代码块标记。"
};
}
// 提取代码块中的 SVG 内容
const extractedSvg = match[1].trim();
const base64 = strToBase64(extractedSvg,'data:image/svg+xml;base64,')
return {
result: base64
}
}3️⃣ 最终通过指定回复节点来格式化输出。
最终效果:
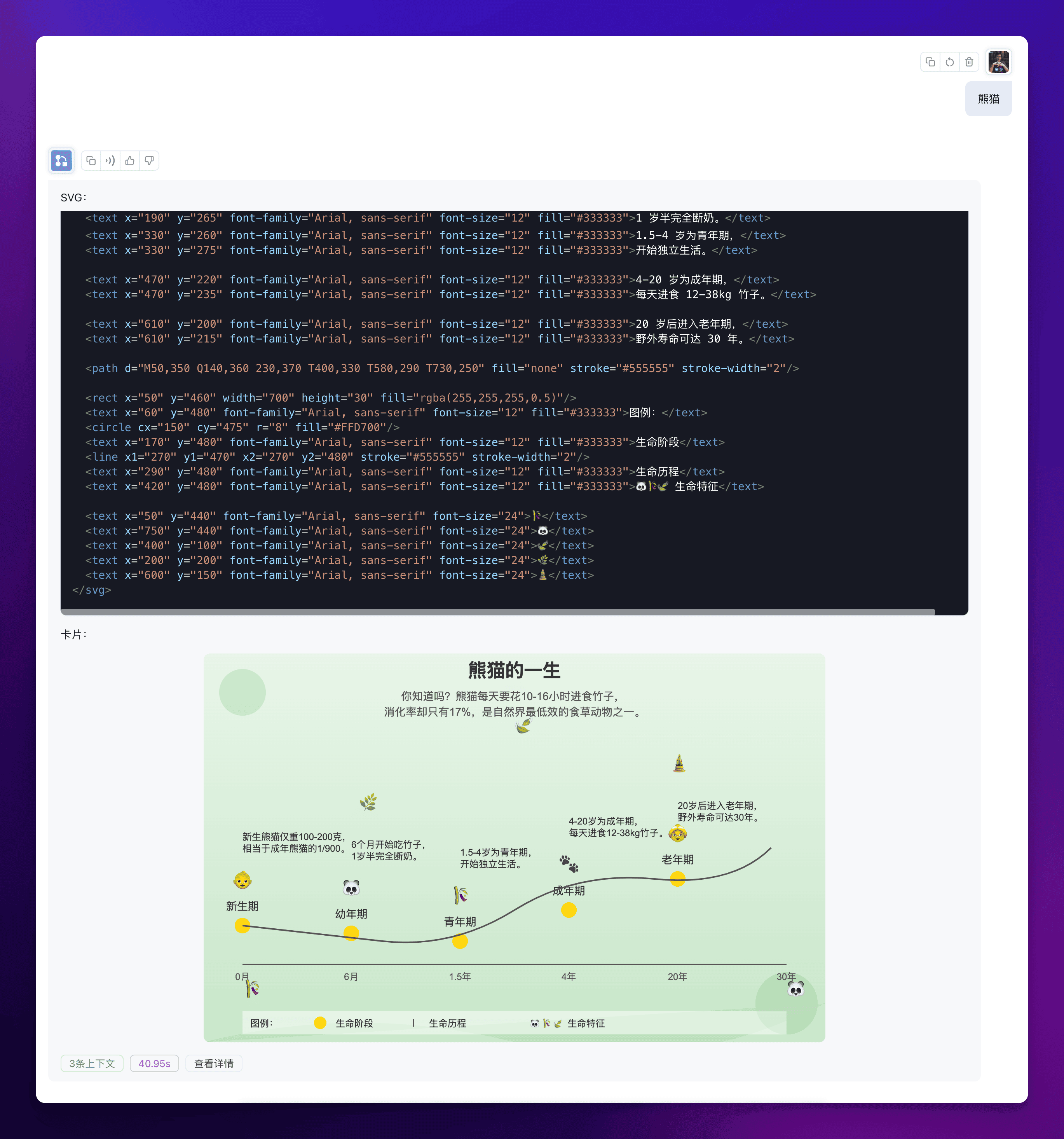
Claude 3.5 的理解能力果然很强,这个工作流虽然描绘的是动物的一生,但实际上我们可以让它生成任何事物的一生,比如 “牛马”,比如 “吗喽”,为了防止有些比较新的名词 Claude 不太理解,你可以稍微给它解释一下,最终它就会给你生成比较满意的一生来。
比如牛马的一生:

吗喽的一生:
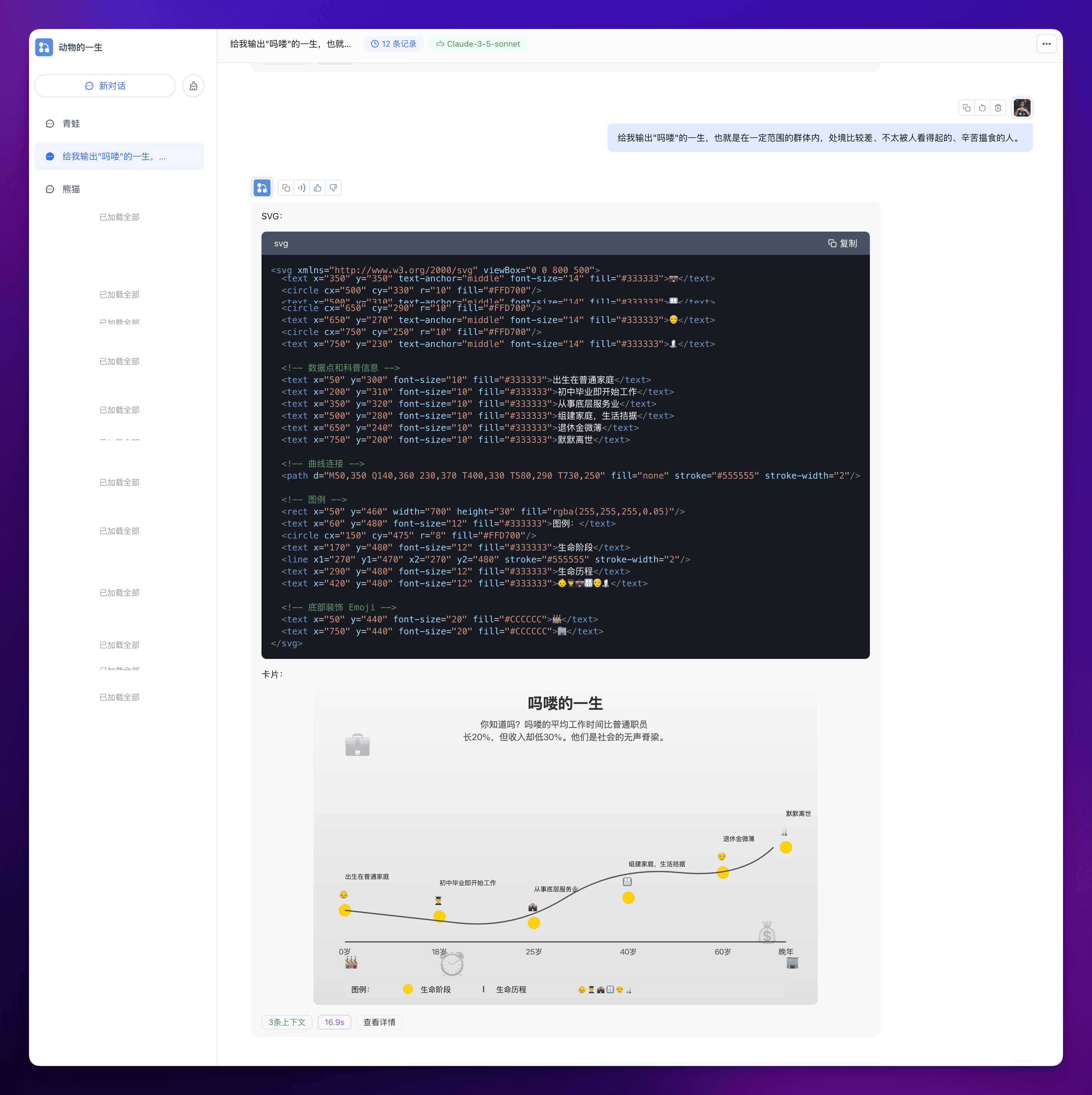
通过这种方式,你可以生成任何事物的 “人生图”。
对于 AI 的嘲讽,我们不妨换个角度,AI 的 “嘲讽” 其实是对我们生活的一种另类解读。
它用一种幽默的方式提醒我们,生活中总有些不如意,但也正是这些不如意让我们的人生更加丰富多彩。
所以,下次当 AI 再次 “调侃” 我时,我会微笑着接受,并用它的 “智慧” 来激励自己,继续前行。
生活不易,但我们总能找到属于自己的乐趣。

















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









