




 该项目从阿里云天池获取幸福感数据,通过数据清洗、可视化和分析,探究影响幸福感的因素。研究发现,受教育程度、社会公平感、社会经济地位与幸福感正相关,而经济状况不佳和经常沮丧与幸福感负相关。使用Python进行数据处理和模型构建,应用逻辑回归算法进行预测。
该项目从阿里云天池获取幸福感数据,通过数据清洗、可视化和分析,探究影响幸福感的因素。研究发现,受教育程度、社会公平感、社会经济地位与幸福感正相关,而经济状况不佳和经常沮丧与幸福感负相关。使用Python进行数据处理和模型构建,应用逻辑回归算法进行预测。
目录
- 提出问题(Business Understanding )
- 理解数据(Data Understanding)
- 采集数据
- 导入数据
- 查看数据集信息
- 数据清洗(Data Preparation )
- 缺失值处理
- 时间格式处理
- 体重数据的处理
- 虚拟变量
- 数据分析与数据可视化
- 构建模型(Modeling)
- 模型评估(Evaluation)
- 提交结果
1.提出问题
幸福感是一个古老而深刻的话题,是人类世代追求的方向。与幸福感相关的因素成千上万、因人而异,大如国计民生,小如路边烤红薯,都会对幸福感产生影响。这些错综复杂的因素中,我们能找到其中的共性,一窥幸福感的要义吗?
在社会科学领域,幸福感的研究占有重要的位置。这个涉及了哲学、心理学、社会学、经济学等多方学科的话题复杂而有趣;同时与大家生活息息相关,每个人对幸福感都有自己的衡量标准。如果能发现影响幸福感的共性,生活中是不是将多一些乐趣;如果能找到影响幸福感的政策因素,便能优化资源配置来提升国民的幸福感。
我们研究的问题是:影响幸福感的因素有什么?什么样的人幸福感更强?
2.理解数据
理解数据分为三部分:
1)采集数据:这一部分,根据研究问题,采集数据;
2)导入数据:将需要分析的数据从excel文件,csv文件或者数据库中,导入到Python的数据结构中;
3)查看数据集信息,理解变量的含义。
2.1 采集数据
点击下载阿里云天池幸福感数据
数据来源:数据来自中国人民大学中国调查与数据中心主持之《中国综合社会调查(CGSS)》项目。感谢此机构及其人员提供数据协助。中国综合社会调查为多阶分层抽样的截面面访调查。
考虑到变量个数较多,部分变量间关系复杂,使用精简版数据进行研究,abbr文件为变量精简版数据。
2.2导入数据
#导入数据包
import pandas as pd
import numpy as np
#调整显示范围,显示更多的列
pd.options.display.max_rows = 10
pd.options.display.max_columns = 45
#导入训练数据集
train = pd.read_csv('./happiness_train_abbr.csv')
#导入测试数据集
test = pd.read_csv('./happiness_test_abbr.csv')
#查看数据有多少行,多少列
print(train.shape, test.shape)
(8000, 42) (2968, 41)
训练数据集有8000行数据,42列;测试数据集有2968行数据,41列。
#合并数据集,方便同时对两个数据集进行清洗
full = train.append(test, ignore_index = True, sort=False)
print (full.shape)
(10968, 42)
合并后又10968行,42列。
2.3 查看数据集信息
#查看数据信息
full.head(5)
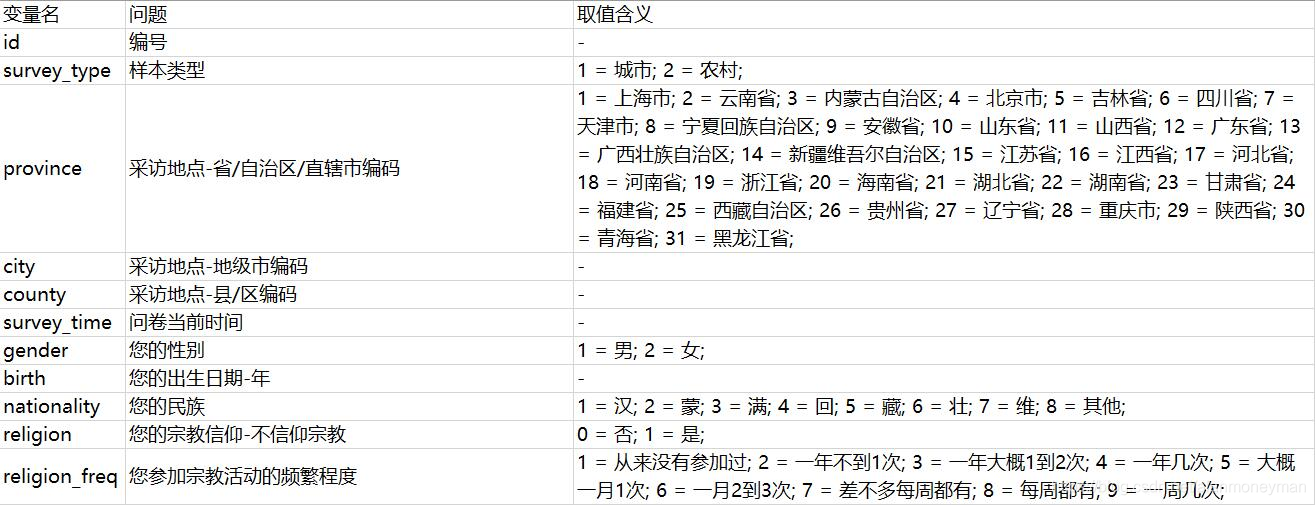
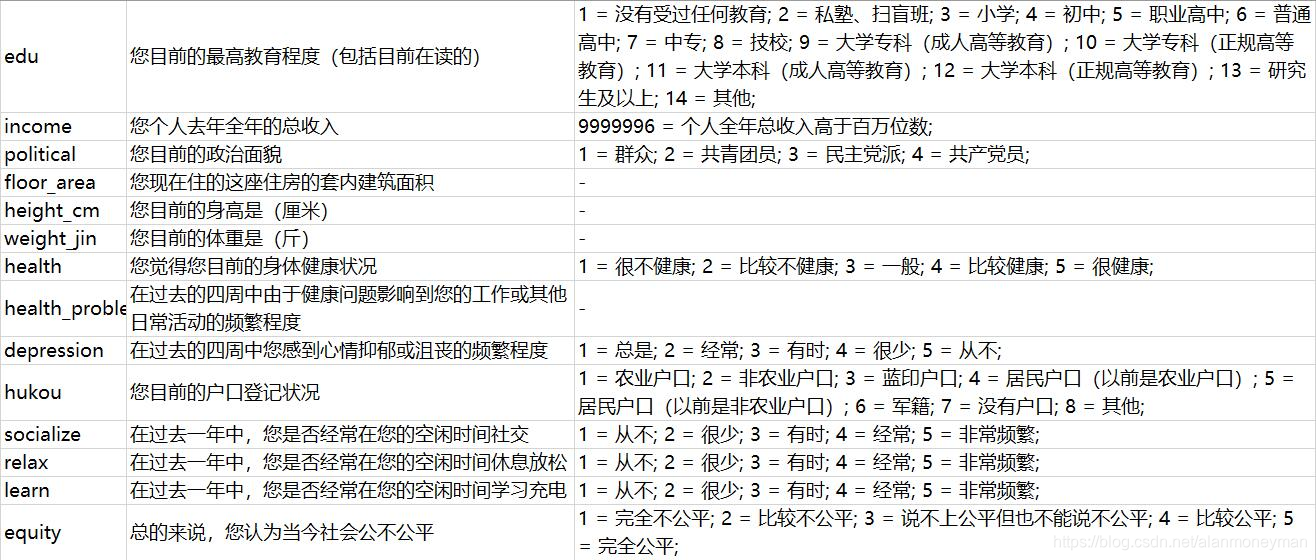
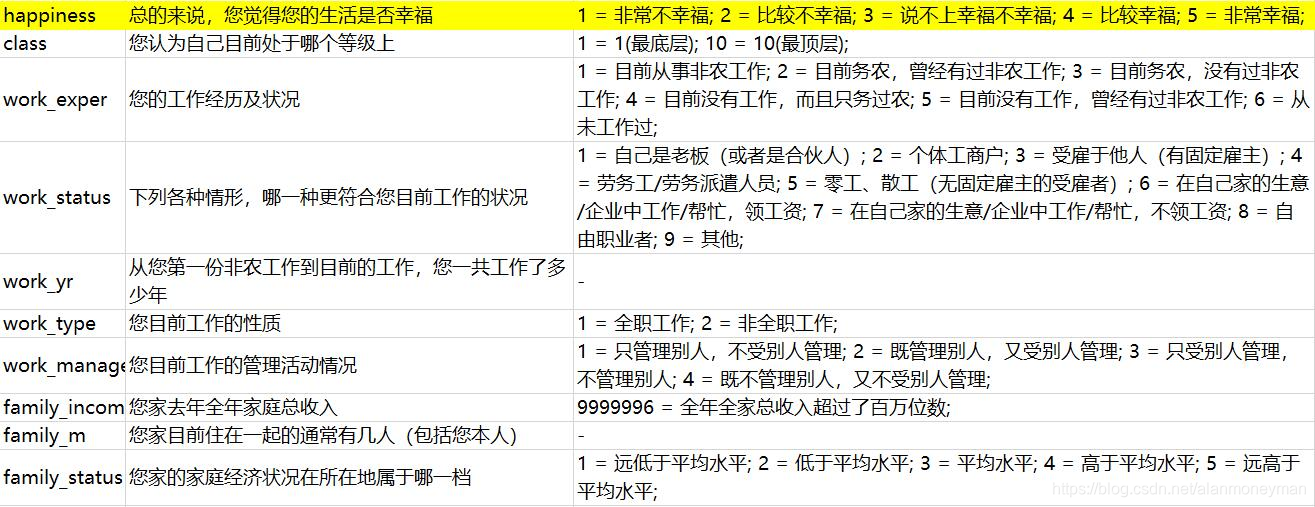
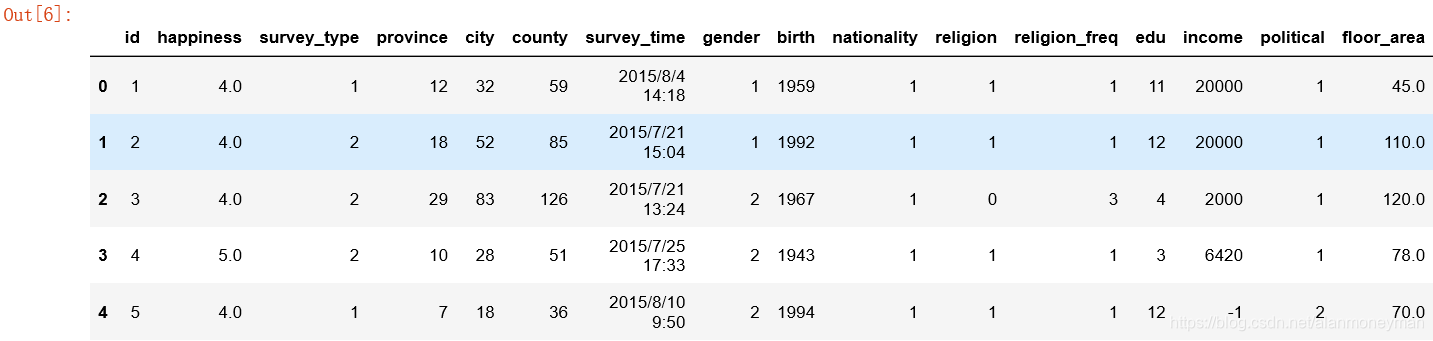 对照题目中的解释,了解每一列的意义。
对照题目中的解释,了解每一列的意义。

#查看每一列的数据类型,和数据总数
full.info()

根据结果,一共有10968行数据,其中survey_time是字符串型数据,其他都是数值型数据。在这些数值型数据中,有很多是实际上是分类数据,原数据集通过对其编码变成了数值型数据。对于分类型数据,将进行One-hot编码后再分析。
family_income有1条数据缺失。work_status, work_yr, work_type, work_manage, 这4列的数据缺失非常大。
3.数据清洗(Data Preparation)
缺失值的处理
虽然数据集中有很多字段都是没有空值的,但是其中有一些包含特殊意义的值,比如-1表示不适用,-2表示不知道,-3是拒绝回答,-8是无法回答。将这些值和空值进行处理。依据情况用均值,出现频率最高的值,或者表示中间态度的选项替代。
#列名class为Python保留字,要改名,不然在操作中很可能报错
full.rename(columns={
'class': 'Class'}, inplace=True)
#列nationality为-8的值,将其替换为8表示其他。
full['nationality'] = full.nationality.replace(-8, 8)
#列religion和religion_freq为-8的值,将其替换为最频繁出现的值1。
full['religion'] = full.religion.replace(-8, 1)
full['religion_freq'] = full.religion_freq.replace(-8, 1)
#列religion和religion_freq为-8的值,将其替换为最频繁出现的值1。
full['religion'] = full.religion.replace(-8, 1)
full['religion_freq'] = full.religion_freq.replace(-8, 1)
#将income列为-1,-2,-3的值,先替换为空值,再用平均值替换
full['income'] = full.income.replace([-1, -2, -3], np.nan)
full['income'] = full.income.replace(np.nan, full['income'].mean())
#列nationality为-8的值,将其替换为最频繁出现的值1。
full['political'] = full.political.replace(-8, 1)
#列health,health_problem为-8的值,将其替换为3,表示一般。
full['health'] = full.health.replace(-8, 3)
full['health_problem'] = full.health_problem.replace(-8, 3)
#列depression为-8的值,将其替换为3,表示一般。
full['depression'] = full.depression.replace(-8, 3)
#列socialize,relax,learn为-8的值,将其替换为3,表示有时。
full['socialize'] = full.socialize.replace(-8, 3)
full['relax'] = full.relax.replace(-8, 3)
full['learn'] = full.learn.replace(-8, 3)
#列equity为-8的值,将其替换为3,表示中间态度。
full['equity'] = full.equity.replace(-8, 3)
#列class为-8的值,将其替换为最频繁出现的5。
full['Class'] = full.Class.replace(-8, 5)
#将family_income列为-1,-2,-3的值,先替换为空值,再用平均值替换
full['family_income'] = full.family_income.replace([-1, -2, -3], np.nan)
full['family_income'] = full.family_income.replace(np.nan, full['family_income'].mean())
#将family_m列为-1,-2,-3的值,替换为1
full['family_m'] = full.family_m.replace([-1, -2, -3], 1)
#列family_status为-8的值,将其替换为3,表示平均水平
full['family_status'] = full.family_status.replace(-8, 3)
#将house列为-1,-2,-3的值,替换为0
full['house'] = full.house.replace([-1, -2, -3], 0)
#将car列为-8的值,替换为最频繁出现的2
full['car'] = full.car.replace(-8, 2)
#将status_peer,status_3_before,view列为-8的值,替换为差不多(一般)
full['status_peer'] = full.status_peer.replace(-8, 2)
full['status_3_before'] = full.status_3_before.replace(-8, 2)
full['view'] = full.view.replace(-8, 3)
#inc_ability缺失值过多,将inc_ability列为-8的值,替换为0
full['inc_ability'] = full.inc_ability.replace(-8, 0)
#将happiness列为-8的值,替换为3 "说不上幸福不幸福"
full['happiness'] = full.happiness.replace(-8, 3)
时间格式处理
#survey_time转换成时间格式的数据
full['survey_datetime'] = pd.to_datetime(
full.survey_time,
format='%Y/%m/%d %H:%M')
#计算受访者的年龄,所有问卷都是2015年填写的,所以 2015-birth 就是年龄
full['age'] = 2015 - full['birth']
体重数据的处理
数据集中包含了受访者的身高与体重。只凭体重的名义数值是不能够判断一个人的胖瘦程度的。国际上常用BMI指数衡量人的胖瘦和健康程度,我们可以将数据集中的体重转换为BMI指数再做分析。
BMI计算公式:体重(kg)/身高(m)的平方
#计算BMI指数,注意数据集中的身高单位是cm,体重的单位是斤(500g)
full['bmi'] = (full['weight_jin'] /2) / (full['height_cm'] / 100) ** 2
虚拟变量
对于分类数据,用One-hot编码,产生虚拟变量(dummy variables),都用0-1表示。
#survey_type分为2类,0=农村,1=城市
full['survey_type'] = full.survey_type.replace(2, 0)
#gender分为2类,0=女,1=男
full['gender'] = full.gender.replace(2, 0)
#民族nationality
nationalityDf  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









