




最近有个项目需要做视觉自动化处理的工具,最后选用的软件为python,刚好这个机会进行系统学习。短时间学习,需要快速开发,所以记录要点步骤,防止忘记。
链接:
开源 python 应用 开发(一)python、pip、pyAutogui、python opencv安装-优快云博客
开源 python 应用 开发(二)基于pyautogui、open cv 视觉识别的工具自动化-优快云博客
开源 python 应用 开发(三)python语法介绍-优快云博客
开源 python 应用 开发(四)python文件和系统综合应用-优快云博客
开源 python 应用 开发(五)python opencv之目标检测-优快云博客
开源 python 应用 开发(十一)AI应用--百度智能云ASR短语音转文本-优快云博客
开源 python 应用 开发(十二)AI应用--百度智能云Agent聊天-优快云博客
开源 python 应用 开发(十三)AI应用--百度智能云TTS语音合成-优快云博客
推荐链接:
开源 Arkts 鸿蒙应用 开发(一)工程文件分析-优快云博客
开源 Arkts 鸿蒙应用 开发(二)封装库.har制作和应用-优快云博客
开源 Arkts 鸿蒙应用 开发(三)Arkts的介绍-优快云博客
开源 Arkts 鸿蒙应用 开发(四)布局和常用控件-优快云博客
开源 Arkts 鸿蒙应用 开发(五)控件组成和复杂控件-优快云博客
推荐链接:
开源 java android app 开发(一)开发环境的搭建-优快云博客
开源 java android app 开发(二)工程文件结构-优快云博客
开源 java android app 开发(三)GUI界面布局和常用组件-优快云博客
开源 java android app 开发(四)GUI界面重要组件-优快云博客
开源 java android app 开发(五)文件和数据库存储-优快云博客
开源 java android app 开发(六)多媒体使用-优快云博客
开源 java android app 开发(七)通讯之Tcp和Http-优快云博客
开源 java android app 开发(八)通讯之Mqtt和Ble-优快云博客
开源 java android app 开发(九)后台之线程和服务-优快云博客
开源 java android app 开发(十)广播机制-优快云博客
开源 java android app 开发(十一)调试、发布-优快云博客
开源 java android app 开发(十二)封库.aar-优快云博客
推荐链接:
开源C# .net mvc 开发(一)WEB搭建_c#部署web程序-优快云博客
开源 C# .net mvc 开发(二)网站快速搭建_c#网站开发-优快云博客
开源 C# .net mvc 开发(三)WEB内外网访问(VS发布、IIS配置网站、花生壳外网穿刺访问)_c# mvc 域名下不可訪問內網,內網下可以訪問域名-优快云博客
开源 C# .net mvc 开发(四)工程结构、页面提交以及显示_c#工程结构-优快云博客
开源 C# .net mvc 开发(五)常用代码快速开发_c# mvc开发-优快云博客
本章节内容如下:实现了一个网站登录和页面抓取的功能,主要使用了 requests 和beautifulsoup4 库。
一、引用库的安装
首先安装requests 和beautifulsoup4 库
cmd命令行安装requests
pip install requests -i https://mirrors.aliyun.com/pypi/simple/cmd命令行安装beautifulsoup4
pip install beautifulsoup4 -i https://mirrors.aliyun.com/pypi/simple/用vscode终端安装效果如下,cmd安装效果和这个类似
二、爬虫代码解析
2.1 源码
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class WebsiteLogin:
def __init__(self, base_url):
self.base_url = base_url
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
})
def find_hidden_inputs(self, html):
"""查找表单中的隐藏字段"""
soup = BeautifulSoup(html, 'html.parser')
hidden_inputs = {}
for input_tag in soup.find_all('input', type='hidden'):
hidden_inputs[input_tag.get('name')] = input_tag.get('value', '')
return hidden_inputs
def login(self, login_url, username, password, extra_data=None):
"""登录网站"""
# 获取登录页面
try:
login_page = self.session.get(urljoin(self.base_url, login_url))
login_page.raise_for_status()
except requests.RequestException as e:
print(f"访问登录页面失败: {e}")
return False
# 获取隐藏字段
hidden_inputs = self.find_hidden_inputs(login_page.text)
# 准备登录数据
login_data = {
'inputName': username,
'inputPwd': password,
**hidden_inputs
}
# 添加额外的表单数据
if extra_data:
login_data.update(extra_data)
# 提交登录表单
try:
response = self.session.post(
urljoin(self.base_url, login_url),
data=login_data,
headers={'Referer': urljoin(self.base_url, login_url)}
)
response.raise_for_status()
except requests.RequestException as e:
print(f"提交登录表单失败: {e}")
return False
# 验证登录是否成功(根据实际网站调整)
#if 'logout' not in response.text.lower() and 'sign out' not in response.text.lower():
# print("登录失败,请检查凭据")
# return False
if 'login' in response.url.lower():
return False
print("登录成功!")
return True
def get_page(self, page_url):
"""获取指定页面的内容"""
try:
response = self.session.get(urljoin(self.base_url, page_url))
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"获取页面失败: {e}")
return None
# 使用示例
if __name__ == "__main__":
# 配置信息
config = {
'base_url': 'http://xxx.com',
'login_url': '',
'username': 'xxx',
'password': 'xxx',
'target_page': '/xxx/xxx'
}
# 创建登录实例
web_login = WebsiteLogin(config['base_url'])
# 尝试登录
if web_login.login(config['login_url'], config['username'], config['password']):
# 登录成功后获取目标页面
target_content = web_login.get_page(config['target_page'])
if target_content:
print(f"成功获取目标页面内容,长度: {len(target_content)}")
# 保存内容
with open('target_page.html', 'w', encoding='utf-8') as f:
f.write(target_content)
else:
print("未能获取目标页面内容")
else:
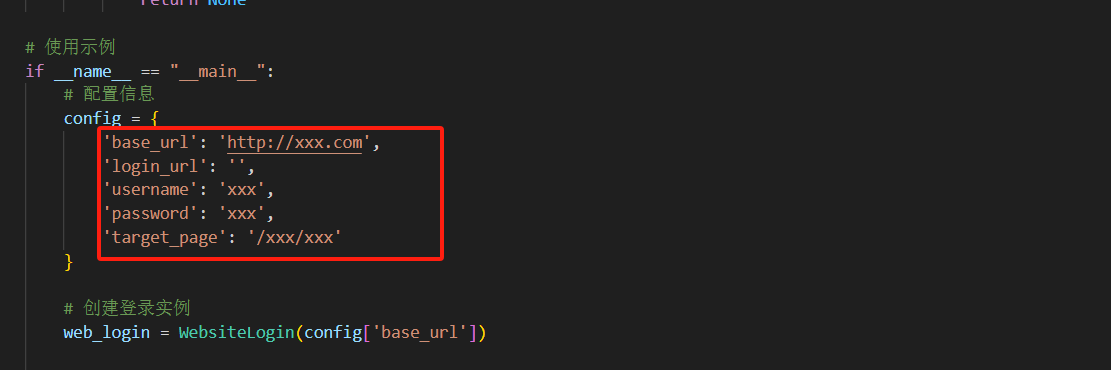
print("登录失败,程序终止")2.2 核心参数,主要有config配置信息,信息有web登录页面链接地址,目标跳转页面链接地址,用户名,用户密码。
config参数如下图
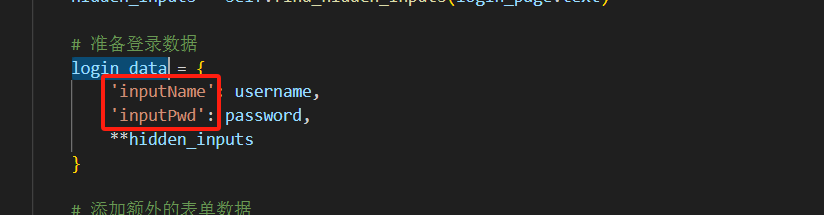
2.3 login_data数据,数据里有登录的字段,包含提交页面的用户名的字段,密码字段。
login_data数据如下图
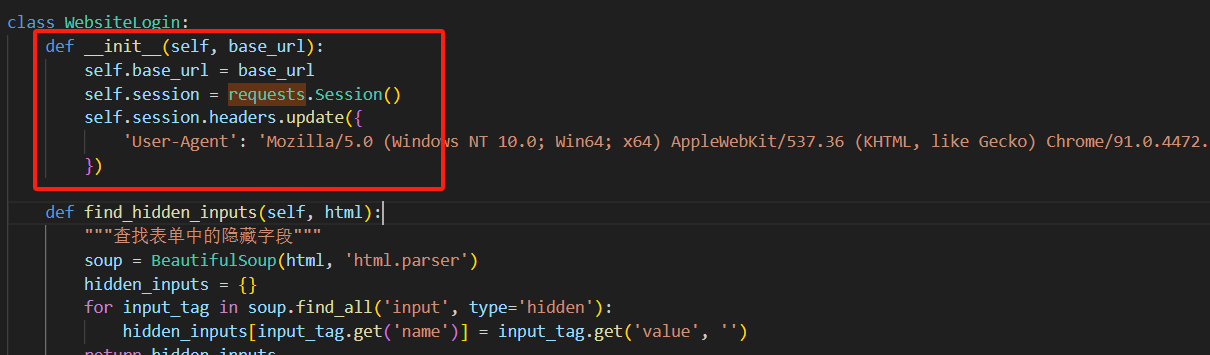
2.4 requests.Session()会自动管理 Cookies,无需手动处理登录后的会话状态。
requests.Session如下图
2.5 登录成功则将跳转页面保存为target_page.html
代码位置如下
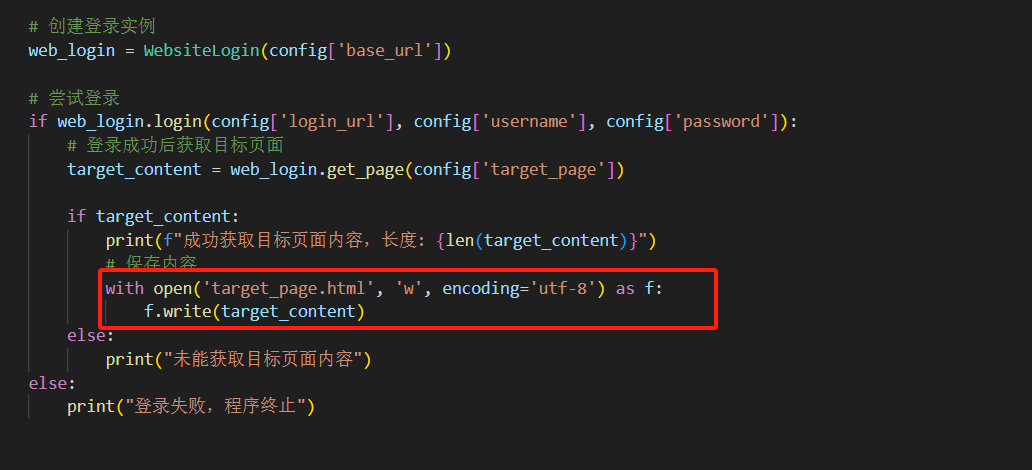
三.运行效果
3.1 登录成功后,跳转到指定页面,把指定页面保存为target_page.html文件。
运行效果图
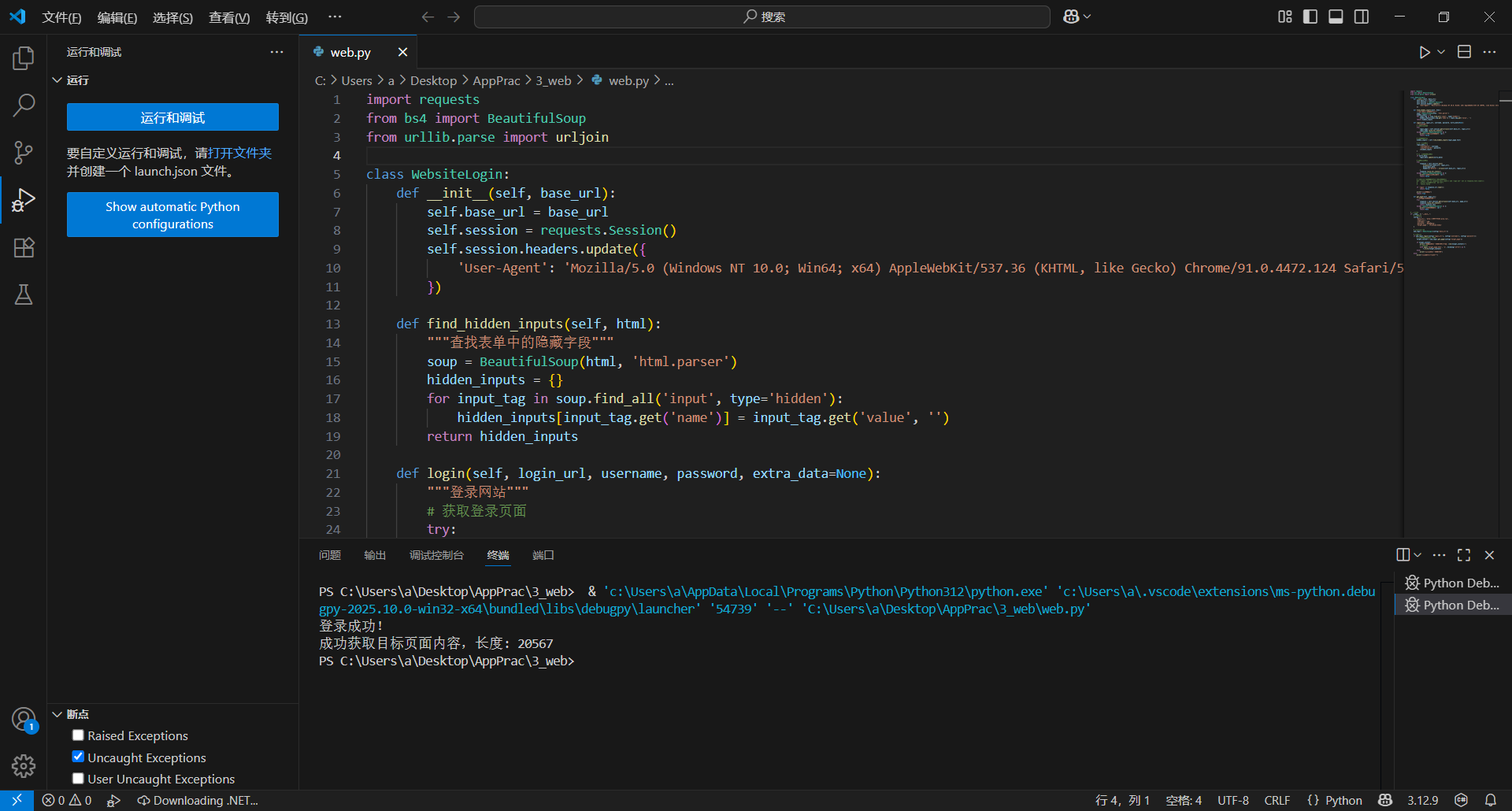


















 1956
1956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









